

Dieser aus Sicht der Anwendungsentwicklung durchaus nachvollziehbare Schritt hin zu Microservices und Cloud-Native-Anwendungen stellt aber gewisse Herausforderungen an die Analyse von Daten. Das beruht unter anderem darauf, dass das Idealbild der Daten für die Analyse seit den Tagen des Enterprise Data Warehouse eine einheitliche, konsolidierte Sicht auf alle Daten eines Unternehmens ist. So birgt die höhere Anzahl an Datenquellen in einer Microservices-Architektur natürlich das Risiko von Inkonsistenzen zwischen den Datenquellen, oder die nichtrelationalen Datenformate erfordern eine aufwendige Aufbereitung für die Analyse.
In diesem Artikel soll zum einen dargestellt werden, wie die verschiedenen Herausforderungen, die sich durch eine Cloud-Native-Anwendungsarchitektur ergeben, gelöst werden können. Dazu wird gezeigt, wie eine „Analytics-freundliche“ Microservices-Architektur aussehen soll und welche Anpassungen auf der Analytics-Seite dafür notwendig sind. Darüber hinaus wird auch betrachtet, welche neuen Chancen sich beim Einbinden von Cloud-Native-Datenquellen für Analytics ergeben.
Cloud-Native-Anwendungen werden als eine Menge von Microservices erstellt, die gekapselt in Containern laufen. Ein Microservice ist kein Layer innerhalb einer monolithischen Anwendung, sondern stellt eine in sich geschlossene Funktionalität mit klaren Schnittstellen dar. In einer Microservices-Architektur können die einzelnen Services unabhängig voneinander entwickelt werden. So führt diese Architektur zu einer flexibleren Entwicklung mit Unterstützung für eine agile Arbeitsweise, hilft Fehler zu isolieren und ermöglicht es außerdem, einzelne Funktionen zu skalieren, was Vorteile bei der Ressourcen- und Kostenoptimierung bringt.
Die Kapselung der Microservices erzwingt quasi eine eigene Datenhaltung, wodurch die Daten für Analysen nicht so leicht zugänglich sind. Es gibt natürlich noch weitere Charakteristiken von Cloud-Native-Anwendungen, die hier aber nicht näher betrachtet werden sollen, da der Fokus auf Analytics für Cloud-Native-Anwendungen liegt.
Datenhaltung für Cloud- Native-Anwendungen
Neben der Kapselung der Datenhaltung für jeden einzelnen Microservice gibt es weitere Ziele für die Datenhaltung bei Cloud-Native-Anwendungen: Das wichtigste Ziel, das die Datenhaltung von zustandslosen Microservices unterscheidet, ist die Persistenz. Während ein zustandsloser Microservice durch das mehrfache Starten von Containern einfach skaliert werden kann, ist das bei der inhärent zustandsbehafteten Datenhaltung nicht so einfach. Nichtsdestoweniger ist aber Skalierbarkeit ein wichtiges Ziel. Auch die Verfügbarkeit der Daten muss durch entsprechende Redundanz sichergestellt werden. Die Datenhaltung soll eine entsprechende Flexibilität mitbringen, sodass agil auf Änderungen der Anforderungen reagiert werden kann. Abbildung 1 zeigt die typische Microservices-Architektur einer Cloud-Native-Anwendung.
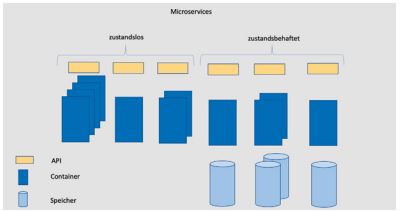
Abb. 1: Microservices-Architektur
Da Microservices genau einen Dienst zur Verfügung stellen, liegt es zunächst nahe, eine genau darauf abgestimmte Datenhaltung zu verwenden: etwa eine Graph-Datenbank, wenn der Microservice Beziehungen zwischen Entitäten verwaltet, oder eine Zeitreihen-Datenbank, wenn Zeitreihen verwaltet werden. Das kann dazu führen, dass eine Vielzahl unterschiedlicher Datenbankarten in einer Cloud-Native-Anwendung vorkommt: neben den beiden eben angesprochenen Datenbankarten und relationalen Systemen beispielsweise auch dokumentenorientierte Data Stores, Column Family Stores oder Key Value Stores.
Daraus ergeben sich einige Herausforderungen für die Datenhaltung. Wie stellt man die Konsistenz der Daten sicher, wenn die Daten über mehrere Microservices verteilt sind? Eine Alternative zu verteilten Transaktionen in den Datenbanken ist das SAGA-Entwurfsmuster (System für Automatisierte Geowissenschaftliche Analysen [Wik20a]), bei dem für jede Operation auf der Datenbank eine entsprechende Kompensationsfunktion zur Verfügung gestellt werden muss, um die Operation gegebenenfalls wieder rückgängig zu machen. Auch die Konsistenz innerhalb eines Microservice erfordert eine Abwägung zwischen der zu gewinnenden oder der zu verlierenden Verfügbarkeit der Daten (siehe CAP-Theorem [Bou00; GiL12]).
Ein beliebtes Entwurfsmuster für Microservices ist das „Command-Query-Responsibility-Segregation“-Entwurfsmuster [Wik20b], das die Trennung von Lesen und Schreiben der Daten vorsieht. Wenn es aber eigene Services für das Schreiben und das Lesen von Daten gibt, wie stellt man die Synchronisation der Datenbestände der verschiedenen Microservices sicher? Dies erfolgt üblicherweise durch Replikation oder datenstromverarbeitende Software.
Daneben sind natürlich auch die traditionellen Probleme eines Analysesystems wie durchgängige Metadaten, tragfähige Berechtigungskonzepte und die Einhaltung von Datenschutzbestimmungen, wie etwa wenn die Löschung von persönlichen Informationen gefordert wird, zu lösen. Dabei steigt teilweise die Komplexität dieser Probleme durch die höhere Anzahl und größere Vielfalt der Datenquellen in einer Microservices-Welt.
Analytics
Fast alle Unternehmen nutzen Analytics zur Steuerung ihres Geschäfts. Wesentlich für alle Arten von Analytics ist der Zugang zu Daten aus der Vergangenheit. Diese liegen meist direkt in den operativen Systemen, in denen sie entstehen. Möglichst viele oder sogar alle Daten sollten in die Analyse einbezogen werden. Die Qualität der Daten spielt für die Güte der Analyseergebnisse eine große Rolle. Daher ist vor allem für das Reporting die Konsolidierung von Daten in einem Data Warehouse, dem Single Point of Truth, üblich [Inm92]. Abbildung 2 zeigt eine typische Data-Warehouse-Architektur.
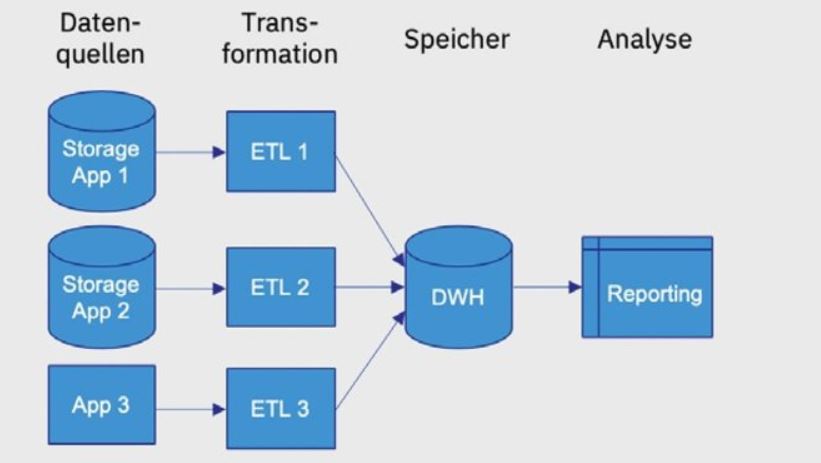
Abb. 2: Typische DataWarehouse-Architektur
Der Zugriff auf die Daten und insbesondere deren Konsolidierung stellt Unternehmen vor große Herausforderungen. Für ein Data Warehouse ist eine umfassende Implementierung mittels ETL-Werkzeugen häufig anzutreffen: Daten werden aus dem Storage Layer der operativen Systeme abgegriffen oder über spezielle APIs zur Verfügung gestellt (zum Beispiel bei ERP- oder CRM-Systemen). Die unterschiedlichen Konzepte in den Quellen und die für die Analyse notwendige Historisierung der Daten führt zu hohen Aufwänden.
Deren Komplexität hat zu neueren Formen der Datensammlung in Data Lakes geführt. Data Lakes bieten eine größere Flexibilität bei der Speicherung der Daten, wodurch die ETL-Prozesse schlanker gestaltet werden können. Wie in Abbildung 3 zu sehen ist, können Analysen auf den Daten bereits vor dem ETL-Prozess durchgeführt werden. Die Ansprüche an die Qualität sollten für einen Data Lake daher niedriger sein als bei einem Data Warehouse. Allerdings ist das Risiko, bei einem Data Lake den Überblick über die gespeicherten Daten zu verlieren, meist hoch [Inm16], weshalb die Erfassung von Metadaten eine wesentlich höhere Bedeutung hat.
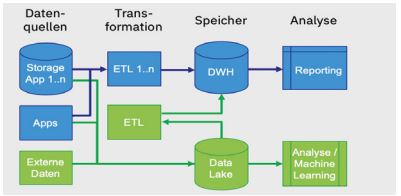
Abb. 3: Kombinierte Data-Warehouse- und Data-Lake-Architektur
Auch die Datenvirtualisierung, bei der die Daten an ihrem ursprünglichen Ort verbleiben und nur virtuell zusammengefasst werden und somit ein logischer Data Lake oder ein logisches Data Warehouse entstehen, ist eine Möglichkeit, die Daten für Analysen verfügbar zu machen.
Mit höherer Flexibilität steigen jedoch auch die Anforderungen an die Sicherheitskonzepte. Fachlich definierte Berechtigungen haben nicht zuletzt wegen der DSGVO eine hohe Priorität und müssen bei mehrstufigen, verteilten Architekturen von Anfang an mit berücksichtigt werden.
Welche Form der Datenhaltung oder des Datenzugriffs für die Analyse auch gewählt wird, effiziente Analyseverfahren müssen in jedem Fall zur Verfügung stehen. Für alle Bereiche haben sich parallele und In-Memory-Verfahren sowie Architekturen durchgesetzt, die die Analyse möglichst nah bei den Daten ausführen.
Mögliche Konflikte zwischen Analytics und Cloud-Native-Anwendungen
Die Sammlung der Daten für die Analyse war schon bei monolithischen Anwendungen nicht einfach. Bei Microservices-Architekturen ist sie jedoch durch die gekapselte Speicherung der Daten noch mal schwieriger geworden.
Die Anzahl und die Heterogenität der Datenquellen steigt: Daten sind nicht mehr aus wenigen Datenbanken zu kopieren, sondern müssen aus den Datenhaltungen der einzelnen Microservices zusammengesucht und abgeglichen werden. Die technologische Vielfalt bringt zusätzliche Probleme mit sich. Statt weniger, hoch standardisierter relationaler Datenbanken verteilen sich die Daten über unterschiedlichste Datenhaltungssysteme.
Damit erhöht sich die Komplexität für übergreifende analytische Systeme, da mehr ETL-Prozesse entwickelt und der Ablauf dieser deutlich höheren Anzahl von ETL-Prozessen permanent koordiniert werden muss (n Quellsysteme statt einem Quellsystem bei einem Monolithen). Änderungen an den Datenquellen sind bei Microservices zwar einfacher zu realisieren, können deshalb häufiger durchgeführt werden und erlauben damit agileres Arbeiten. Für ein analytisches System bedeutet dies aber zunächst eine zusätzliche Schwierigkeit, da es diese Änderungen mitbekommen und aufgreifen muss. Die Wichtigkeit eines Metadatenmanagements nimmt noch mal deutlich zu.
Chancen für Analytics durch Cloud-Native-Anwendungen
Die Microservices-Architektur von Cloud-Native-Anwendungen und die dabei verwendeten Entwurfsmuster wie „Command-Query-Responsibility-Segregation“ vereinfachen es, logische Data Lakes oder logische Data Warehouses mit Hilfe von Datenvirtualisierung zu erstellen. Logische Data Lakes oder logische Data Warehouses haben mehrere Vorteile: Sie vermeiden die sonst notwendige zusätzliche redundante Speicherung der Daten, können die Rechenressourcen der Quellsysteme nutzen und sind insbesondere für agiles Arbeiten besser geeignet, da nicht zuerst ETL-Prozesse entwickelt werden müssen, wenn neue Datenquellen eingebunden werden sollen. Auch die regelmäßige Verzögerung beim Zugriff auf neu angefallene Datensätze durch den Laufzeit-Overhead der ETL-Prozesse entfällt.
Der Ansatz eines logischen Data Warehouse mit Hilfe von Datenvirtualisierung hat aber auch einen Nachteil: So belastet die Datenvirtualisierung für alle abgesetzten Abfragen (wenn nicht Optimierungen wie Caching vorgenommen werden) die Quellsysteme, da dort für die Ausführung der analytischen Abfragen zusätzliche Ressourcen benötigt werden (CPU, Hauptspeicher, IOs).
Hier kann die Microservices-Architektur helfen: Die dort geforderte Skalierbarkeit kann genutzt werden, um zusätzliche Ressourcen für die analytischen Abfragen einfach zur Verfügung zu stellen. Da analytische Abfragen typischerweise nur Lesezugriff benötigen, hilft hier das „Command-Query-Responsibility-Segregation“-Entwurfsmuster, da nur die Microservices, die Lesezugriff zur Verfügung stellen, skaliert werden müssen.
Ein weiterer Vorteil ist die Möglichkeit zur Nutzung der Fähigkeiten von Spezialdatenbanken der Microservices. Wenn ein Microservice etwa eine Graph- oder eine Zeitreihen-Datenbank nutzt, können diese speziellen Fähigkeiten auch für analytische Abfragen gewinnbringend genutzt werden, wenn man diese Datenquellen mit Datenvirtualisierung einbindet. Die Datenvirtualisierung kreiert damit eine logische Multi-Model-Datenbank.
Wird die Analyse der Daten bei der Entwicklung der Microservices berücksichtigt, können speziell optimierte Verfahren (zum Beispiel spaltenbasierte Speicherung) leichter genutzt und außerdem hohe Aufwände für das ETL verhindert werden.
Lösungsansätze für Analytics mit Cloud-Native-Anwendungen
Um die Datensammlung für analytische Anforderungen möglichst einfach zu gestalten, empfiehlt es sich, die Schnittstellen für den Abgriff der relevanten Daten gleich in die Entwicklung mit einzuplanen. Noch einfacher wird es, wenn alle Änderungen an den Daten über Nachrichten (zum Beispiel mittels Kafka, RabbitMQ oder Flink [SaG17]) auf kontinuierliche Weise zur Verfügung gestellt werden. Dies erlaubt sowohl eine Analyse von historischen Daten als auch eine Realtime-Analyse, ohne die Daten zuerst aus den verschiedenen Quellen zusammenstellen zu müssen.
Abbildung 4 zeigt, wie eine solche Architektur aussehen könnte. Die Daten fließen von den Quellen zuerst in eine Messaging-Schicht. Dorthin gelangen sie entweder über das Abholen aus den Quellen (Pull) oder über ein aktives Versenden durch die Quellen (Push). Die Daten aus dem Storage Layer einer Anwendung müssen meist zuerst durch einen ETL-Prozess laufen, um aus Daten-Transaktionen wieder Business-Transaktionen zu erhalten. Diese Architektur ermöglicht es auf effiziente Art, eine Lambda-Architektur zu implementieren [RRS18].
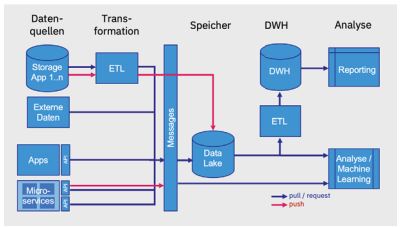
Abb. 4: Architektur mit Pull- und Push-Varianten
Eine verbreitete Push-Methode aus einem Storage Layer heraus ist die Replikation. Dabei werden Änderungen an den Daten zeitnah gesendet. Auch diese Methode erfordert ETL, um aus den Daten-Änderungen Business-Änderungen zu erhalten.
Wie oben schon angesprochen, bietet sich mit Cloud-Native-Anwendungen die Möglichkeit, effiziente logische Data Lakes zu schaffen. Daten werden dann nicht, wie in Abbildung 4 dargestellt, mit ETL-Prozessen in den Data Lake bzw. das Data Warehouse kopiert, sondern bei Abfragen direkt aus den Quellen geholt. Dies erlaubt ein agileres Vorgehen, Daten sind aktueller und sie müssen im Data Lake nicht redundant gespeichert werden. Der traditionelle Nachteil von Datenvirtualisierung, der negative Performance-Einfluss auf die operativen Systeme bei analytischen Abfragen, kann in einer Cloud-Native-Architektur durch das Skalieren der Microservices ausgeglichen werden.
Wenn die Datenvirtualisierung auf die den Microservices zugrunde liegenden Data Stores nicht direkt zugreifen kann oder soll, die Virtualisierung aber die REST APIs der Microservices nicht unterstützt, können stattdessen Ansätze wie in [IBM20] für Big SQL beschrieben als Lösung zum Einbinden von Microservices gewählt werden, um REST APIs in ein analysefreundliches Format abzubilden. Abbildung 5 veranschaulicht, wie Datenvirtualisierung für die Analyse in einer Microservices-Landschaft verwendet werden kann.
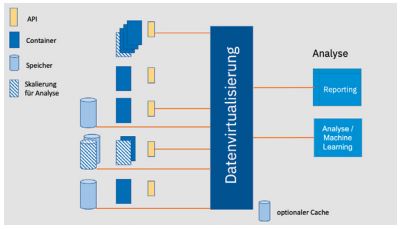
Abb. 5: Analyse in einer Microservices-Landschaft mit Hilfe von Datenvirtualisierung
Eine andere Möglichkeit, das Analyse-Problem anzugehen, besteht darin, die Datenhaltung der Microservices so zu gestalten, dass sie eine Microservice-übergreifende Analyse direkt erlaubt. Die Datenhaltung wird dann logisch, aber nicht physikalisch getrennt. Eine Multi-Model Database erlaubt die Nutzung des für jeden Microservice optimierten Datenmodells und ermöglicht gleichzeitig auf einfache Art performante analytische Abfragen über den konsolidierten Datenbestand [SlW19; hier findet man auch Beispiele für Multi-Model Databases].
Diese engere Koppelung der Microservices kann natürlich bezüglich anderer Aspekte Fragen aufwerfen, etwa wie ein separates Skalieren einzelner Microservices oder unterschiedliche Verfügbarkeitsanforderungen für unterschiedliche Microservices zu realisieren sind. Wie eine Multi-Model Database auf diese Art genutzt werden kann, zeigt Abbildung 6.
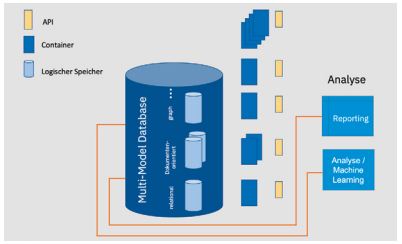
Abb. 6: Nutzung einer Multi-Model Database zur Analyse in einer Microservices-Landschaft
Zusammenfassung
Cloud-Native-Anwendungen bringen für die Analyse von Daten sowohl neue Probleme als auch neue Möglichkeiten mit sich. Welche der sich daraus ergebenden oben vorgestellten Lösungsmöglichkeiten man wählt, hängt von den eigenen analytischen Anforderungen und Nebenbedingungen ab. Während Data Warehouses über etablierte Architekturen und reife Werkzeuge verfügen, ist die Technologie für virtuelle und nachrichtenbasierte Architekturen noch relativ neu. Zudem können neue Entwicklungen und Trends zu höheren Aufwänden bei der Implementierung führen. Tabelle 1 stellt die vorgestellten Methoden und Architekturen noch mal einander gegenüber.
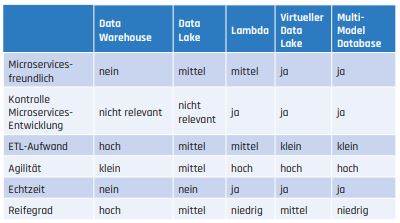
Tab. 1: Vergleich der vorgestellten Methoden und Architekturen
Weitere Informationen
[Bou00]
Bouwer, E.: Towards Robust Distributed Systems (Invited Talk). Principles of distributed computing. Portland/Oregon, Juli 2000
[GiL12]
Gilbert, S. / Lynch, N.: Perspectives on the CAP Theorem. In: IEEE Computer, Ausgabe 45, 2012, S. 30–36, 10.1109/MC.2011.389
[IBM20]
EXECSPARK table function,
https://www.ibm.com/support/knowledgecenter/en/SSCRJT_7.0.0/com.ibm.swg.im.bigsql.commsql.doc/doc/biga_execspark.html, abgerufen am 16.7.2020
[Inm92]
Inmon, B.: Building the Data Warehouse. Wiley 1992
[Inm16]
Inmon, B.: Data Lake Architecture. Designing the Data Lake and Avoiding the Garbage Dump. Technics Publications 2016
[Lan12]
van der Lans, R.: Data Virtualization for Business Intelligence Systems: Revolutionizing Data Integration for Data Warehouses. Morgan Kaufmann 2012
[RRS18]
Raj, P. / Raman, A. / Subramanian, H.: Architectural Patterns. Big data architecture patterns. Packt Publishing 2018
[SaG17]
Saxena, S. / Gupta, S.: Practical Real-time Data Processing and Analytics. Packt Publishing 2017
[SlW19]
Slomka, S. / Weininger, A.: Multi-Model Databases – Die Datenbanksysteme der Zukunft für analytische Anwendungen. In: BI-Spektrum, Ausgabe 4, 2019
[Wik20a]
Wikipedia: SAGA-Entwurfsmuster.
https://de.wikipedia.org/wiki/Saga_(Entwurfsmuster), abgerufen am 19.9.2020
[Wik20b]
Wikipedia: Command-Query-Responsibility-Segregation.
https://de.wikipedia.org/wiki/Command-Query-Responsibility-Segregation, abgerufen am 19.9.2020








