

Dieser Artikel zeigt auf, wie Deep Learning, ein Teilbereich der Künstlichen Intelligenz (KI), eingesetzt werden kann, um die Qualitätskontrolleur*innen am Fließband mit einem Vision-System zu unterstützen. Mit Deep Learning sind aber nicht nur visuell ambitionierte Kontrollen möglich. Es erlaubt auch, flexibel auf kurzfristig auftretende neue Anforderungen und Marktsituationen zu reagieren und so die Wettbewerbsfähigkeit von Unternehmen zu steigern.
Das Ziel einer industriellen Produktion ist meist, möglichst einheitliche und standardisierte Produkte zu produzieren. Denn wer will schon eine Schraubenpackung mit lauter verschiedenen Schrauben oder ein Auto, das ein paar Zentimeter breiter ist als alle anderen des gleichen Modells? In der Lebensmittelindustrie hingegen kommt man manchmal nicht darum herum, uneinheitliche Produkte zu haben.
So ist es zum Beispiel der Fall beim Fleisch. Wird im industriellen Stil geschlachtet, dann werden die einzelnen Stücke des Tiers sortiert. Im Anschluss müssen die Stücke kategorisiert werden, also zum Beispiel die Kotelett-Stücke als solche im System erfasst werden. Für einen Menschen ist eine solche Klassifizierung mehr oder weniger einfach möglich. Für ein Vision-System, das einfachen Regeln folgt, ist diese Aufgabe nicht zu bewältigen. Die Fleischstücke sind in ihrer Anordnung, ihrer Größe und ihrem Aussehen sehr unterschiedlich. Dies ist daher ein guter Use-Case für eine intelligente Bildverarbeitung mit Deep Learning.
Fehler in verschiedenen Variationen
Produktionsfehler können immer mal auftauchen, sei es bei einem Kratzer im Lack eines Autoteils, einem unregelmäßigen Überzug einer Schokoladenglasur oder einem fehlerhaften Webmuster eines Stoffes. Sind die Fehler immer im gleichen Ausmaß vorhanden und immer an der gleichen Stelle, können Regeln definiert werden, welche die Fehler im Bild erkennen können. In solchen Fällen ist ein Deep-Learning-Ansatz nicht nötig. Sind hingegen die Fehler zufällig angeordnet oder tauchen in zufälliger Form auf, ist ein Inspektionssystem, das maschinell lernt, sinnvoll.
Ein Potenzial für Qualitätskontrollen mit Deep Learning hat grundsätzlich jeder Inspektionsprozess, der heute noch manuell ausgeführt wird, wo ein herkömmliches Machine-Vision-System nicht zielführend ist.
Die Maschine soll die Regeln definieren
Herkömmliche Vision-System-Methoden beruhen nicht darauf, dass sich das System über die Zeit an die Daten anpasst. Es sind starr vorgegebene Regeln, die implementiert werden, um das Bild zu verarbeiten und so eine Klassifizierung vorzunehmen.
Abbildung 1 und 2 zeigen den Unterschied zwischen dem klassischen Machine-Vision- und dem Deep-Learning-Ansatz auf. Im klassischen oder auch regelbasierten Ansatz schreiben Programmierer Regeln, die aus Bildern oder anderen unstrukturierten Daten (Textdateien, Präsentationen, Videos, Audiodaten, aufgezeichnete Sprache) strukturierte Daten in Form von Tabellen oder Informationen erstellen, die direkt für die Verarbeitung mit Computern geeignet sind (vgl. Abbildung 1).
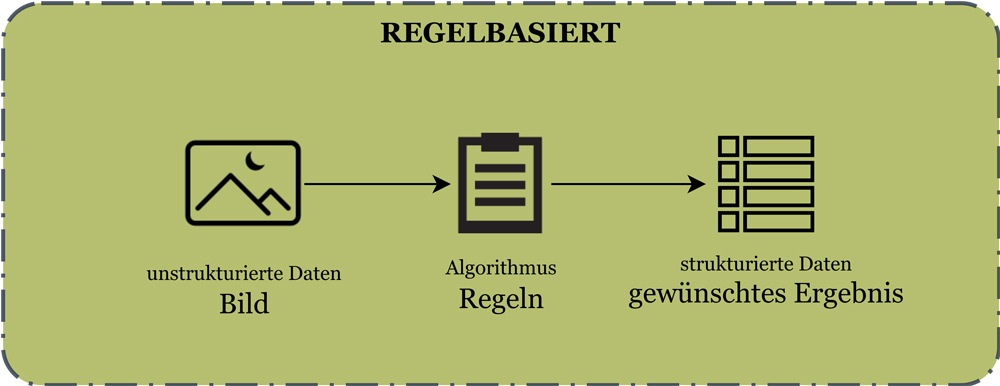
Abb. 1: Grafik zur Verdeutlichung des regelbasierten Ansatzes (ohne Deep Learning)
Ist die Implementierung von Regeln für die Lösung des Vision-Problems nicht möglich oder nur mit sehr großem Aufwand erreichbar, sollte ein Deep-Learning-Ansatz gewählt werden. So treten an die Stelle von implementierten Regeln trainierte Regeln. Damit dies funktionieren kann, müssen Datensätze vorliegen, die den Bezug zwischen den Bildern und den gewünschten Ergebnissen aufzeigen. Durch das Aufstellen von Meta-Regeln wird dann bestimmt, wie aus den Bilder-Ergebnis-Paaren Muster erkannt und damit Regeln definiert werden (vgl. Abbildung 2). Das Entwickeln solcher Lösungen bedarf Data-Science-Fähigkeiten wie etwa der mathematischen Modellierung und Datenkompetenzen.
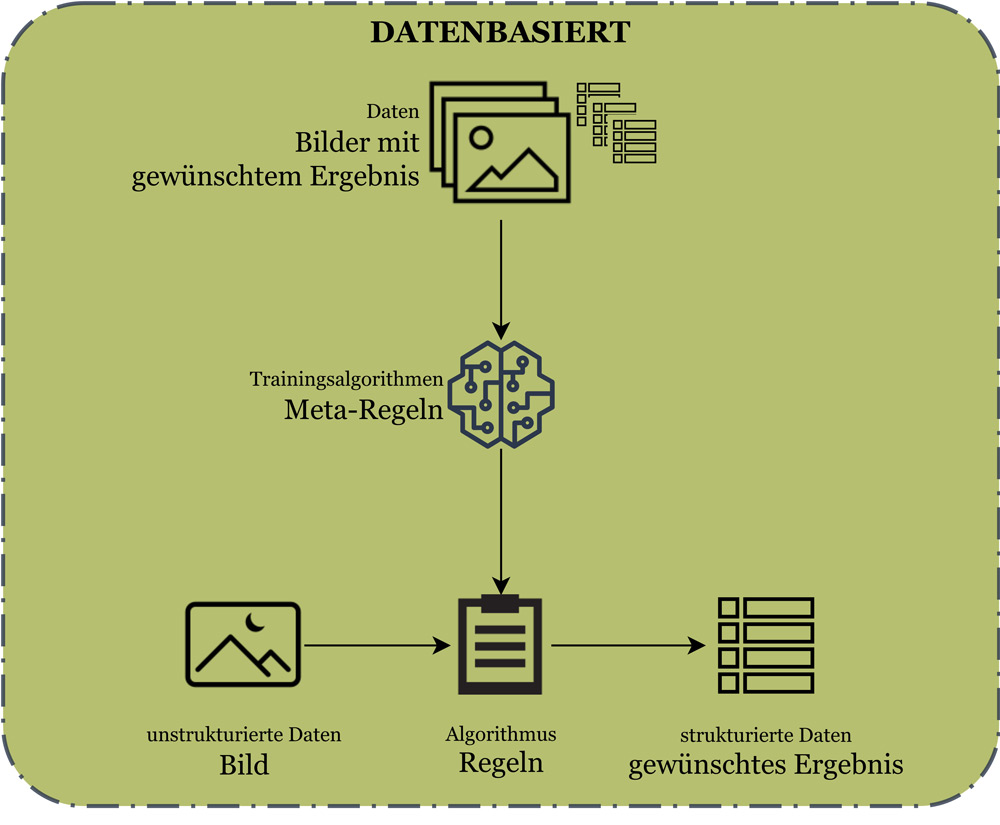
Abb. 2: Grafik zur Verdeutlichung des datenbasierten Ansatzes (mit Deep Learning)
Der große Vorteil ist, dass ein solches System bei Änderungen in den hergestellten Produkten nicht neu implementiert werden muss. Im Gegensatz zu den hartkodierten Regeln stellen Meta-Regeln nur das Grundgerüst für den Lernprozess dar. Innerhalb dieses Gerüsts können sich die Regeln über die Zeit bei regelmäßigem Training stark ändern. Dazu werden die neu gesammelten Daten genutzt, um das System auf allfällig geänderte Gegebenheiten zu trainieren. Dieses Training kann vollautomatisch durchgeführt werden, sodass es auch ohne menschlichen Eingriff für die Qualitätskontrolle der geänderten Produkte benutzt werden kann.
Der Prozess der intelligenten Bildverarbeitung
Der Prozess der Bildverarbeitung mit Deep Learning gliedert sich in sieben Teile. Viele davon ähneln dem herkömmlichen Machine Vision ohne Deep Learning (vgl. [Hec16]). Daher werden hier vor allem die Unterschiede hervorgehoben. In den Abbildungen 3 und 4 wird eine mögliche Architektur eines Vision-Systems mit Deep Learning aufgezeigt.
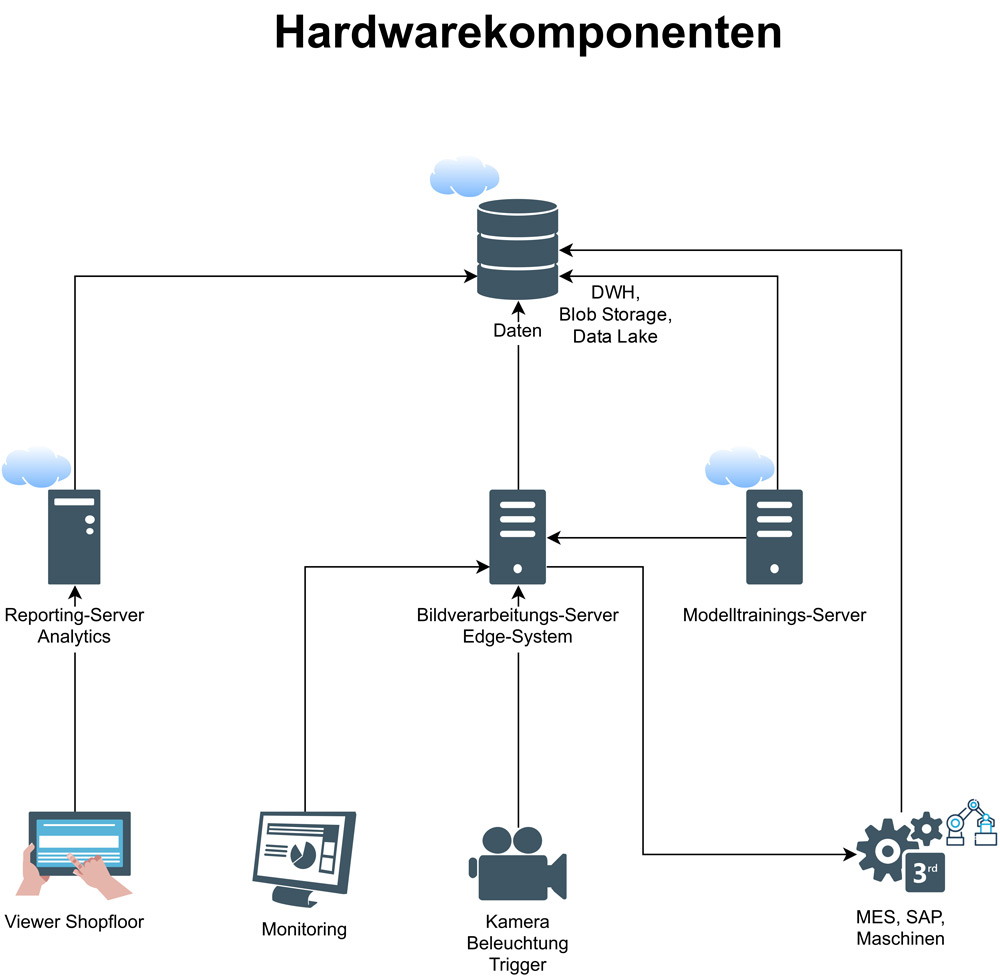
Abb. 3: Hardwarekomponenten eines Vision-Systems (Komponenten mit Wolke sind Cloud-Infrastruktur)
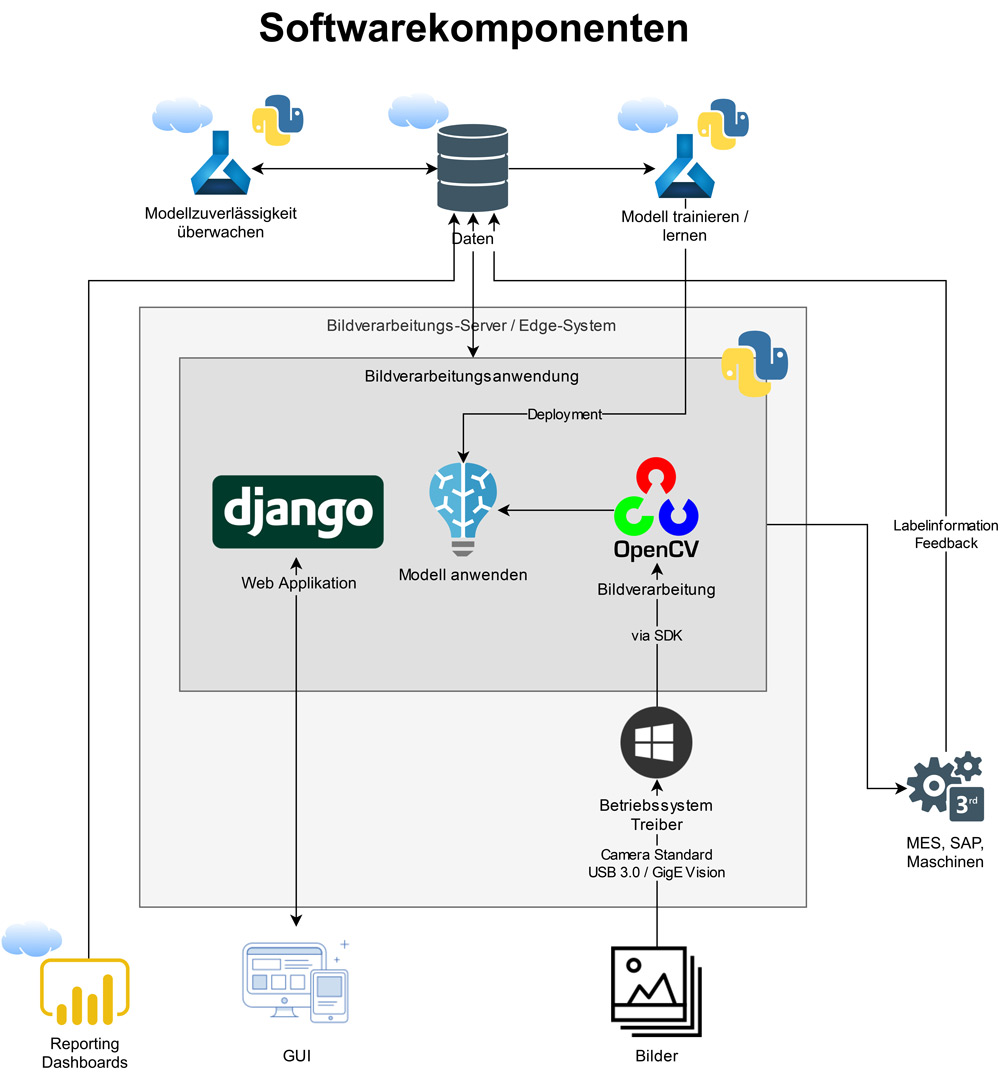
Abb. 4: Softwarekomponenten eines Vision-Systems (die Lösung ist in Python implementiert mit Services aus der Microsoft Azure Cloud)
Kamera
Industriekameras gibt es in verschiedensten Auflösungen und Schutzklassen. Für klassische Machine-Vision-Anwendungen wird üblicherweise eine monochrome Kamera verwendet, da Farben oftmals keine Rolle spielen. Bei Klassifizierungsaufgaben mit Deep Learning liefert die Farbe jedoch wichtige zusätzliche Informationen. Auf eine große Auflösung kann indes meist verzichtet werden, da die verwendeten Modelle mit kleineren Bildern einfacher zu trainieren sind. Dies rührt daher, dass die Größe der Neuronalen Netzwerke (und entsprechend auch die Anzahl der Parameter) proportional zur Bildauflösung ist. Kleinere Netzwerke ermöglichen deshalb ein stabileres Training und benötigen bei der Anwendung nur eine reduzierte Rechenleistung.
Heutzutage implementieren die meisten Industriekameras den GenICam-Standard (Generic Interface for Camera, vgl. [EMVA]). Damit lässt sich die Kamera unabhängig von Hersteller, Firmware und Schnittstellentechnologie einheitlich steuern. Die gängigsten Hardware-Schnittstellen sind USB3 Vision und GigE Vision. Letztere wird bei einem längeren Kabel zwischen Kamera und Host bevorzugt.
Beleuchtung
Optimal ist eine kontrollierte Beleuchtung in einer von anderen Lichtquellen abgeschirmten Box. Falls dies nicht praktikabel ist, empfiehlt sich eine zusätzliche, verstärkte Beleuchtung. Die Ausleuchtung der Objekte ist bei klassischen Machine-Vision-Anwendungen viel wichtiger. Jedoch ist auch bei Deep-Learning-Ansätzen wichtig, dass die Ausleuchtung einigermaßen konstant bleibt, da ansonsten bei Schattenbildung das Modell das Bild falsch interpretieren kann. Sind jedoch in den Daten zum Training die verschiedenen Ausprägungen der Ausleuchtung genügend gut repräsentiert, kann das Neuronale Netzwerk damit umgehen.
Trigger
Je nach Problem werden die Bilder der Kamera nicht kontinuierlich benötigt, sondern lediglich, wenn sich ein Objekt darin befindet. Dies lässt sich mit Hilfe von Software detektieren. Vielfach ist es jedoch einfacher, wenn die Aufnahme durch einen Trigger, wie zum Beispiel eine Lichtschranke, ausgelöst wird. Häufig bieten die Kameras schon integrierte Schnittstellen, mit denen das Trigger-Signal abgegriffen werden kann.
Bildverarbeitungs-Server / Edge-System
Wenn das Bild nun über die physische Schnittstelle zum Bildverarbeitungs-Server gelangt ist, ist der Treiber der Kamera für die Bereitstellung des Bildes verantwortlich. Die Funktionen zur Bild-Akquise können über eine API (GenTL Producer) in die eigene Applikation integriert werden. Die Kompatibilität mit anderen Kameras ist gewährleistet, sofern die verwendete API keine spezifischen Kamerahersteller blockiert.
Die Verarbeitung der Bilder wird auf dem Server durchgeführt, wobei je nach Kamera bereits auf der Kamera selbst eine Vorverarbeitung vorgenommen werden kann. Sobald die Fotos im gewünschten Format vorhanden sind, wird das Modell auf diese angewendet. Die Bilder sowie die Resultate werden abgespeichert. Die Bilder dienen später als Trainingsdatensatz, um das Modell zu verfeinern oder neue Modellvarianten zu entwickeln. Dabei ist es wichtig, dass die Daten auf ihre Richtigkeit geprüft werden, um nicht potenzielle Fehler ins Training einzuschleusen.
Die Anforderungen an den Server sind stark abhängig von der Komplexität des Modells, der maximalen Latenzzeit sowie dem gewünschten Durchsatz. Um die Rechenzeit bei größeren Modellen gering zu halten, kommen oft GPUs (Graphics Processing Units) zum Einsatz.
Modell-Training
Dem Deep-Learning-Modell und dessen Training kommt in der intelligenten Bildverarbeitung eine besondere Rolle zu. Anders als bei der klassischen Machine Vision werden hier Parameter nicht manuell optimiert, sondern Millionen von Variablen innerhalb des Neuronalen Netzwerks automatisch auf den bestmöglichen Wert justiert. Bei der Bildverarbeitung mit Neuronalen Netzwerken kommen meist sogenannte Convolutional Neural Networks (CNNs) zum Einsatz. Diese bestehen unter anderem aus unterschiedlich vielen Convolutional Layers, die als Faltungsprodukt auf die Bilder angewendet werden. Seit ihrer Einführung 1989 [LeC89] wurden die CNNs stets weiterentwickelt [GBC16, Sch15, LBH15] und sind heute der Standard in der Bildverarbeitung mit Deep Learning. Für interessierte Leser bietet die Stanford-Universität dazu ihre gesamte Vorlesung online gratis an [CS230].
Zur Justierung der Parameter innerhalb der Convolutional Layers werden dem Netzwerk jeweils die Bilder mit entsprechenden Labeln (zum Beispiel „gut“ / „schlecht“) gezeigt. Das Netz lernt nun aus den Bildern eine Repräsentation und berechnet daraus direkt die entsprechenden Labels. Dieser zum Teil wenig stabile Prozess kann mitunter mehrere Tage dauern und birgt ganz eigene Herausforderungen. Entsprechend kann gezieltes Eingreifen bei der Bildvorverarbeitung, den Trainingsparametern und der Netzwerkarchitektur nötig sein.
Es empfiehlt sich, das Modell nicht auf demselben Server zu trainieren, auf dem auch die operative Bildverarbeitung und die Anwendung eines Modells gerechnet wird. Da das Trainieren des Modells viel Rechenleistung benötigt und nur gelegentlich ausgeführt werden muss, eignet sich dazu Cloud-Computing hervorragend. Ein weiterer Vorteil der Cloud ist die Skalierbarkeit des Speichers für die Erfassung der Bildinformationen der aktuellen Bilder. Für die Archivierung kann anschließend ein kostengünstiger Cold Storage genutzt werden.
Gewisse Cloud-Dienste wie etwa Azure Machine Learning von Microsoft unterstützen die Versionierung und den Trainings- und Deployment-Prozess der neu gewonnenen Modelle.
GUI (Graphical User Interface)
Bei einer Bildverarbeitung ist es immer sinnvoll, auf einem Bildschirm darzustellen, was das System gerade „sieht“. Wird ein intelligentes Vision-System mit Supervised Deep Learning trainiert, werden zudem Bilder in gelabelter Form benötigt. Meist werden die Labels der Bilder durch einen Mitarbeitenden schon im System erfasst oder aber es muss möglich sein, dies im GUI zu tun. Das Erstellen der Bild-Label-Datenbasis ist sehr wichtig. Die Datenqualität muss stimmen, denn ein trainiertes System ist nur so gut wie die Daten, die es zur Verfügung hat.
Für die Transparenz und die Akzeptanz des Systems ist ein GUI vor allem bei der Einführung des Vision-Systems sehr wichtig. Meist müssen bestehende Prozesse Schritt für Schritt transformiert werden.
Menschliche Kontrolle
Ein Vision-System, das die Qualitätskontrolle übernehmen soll, muss selbst auch kontrolliert werden. Der Vorteil des Systems ist, dass es Bilder für die menschliche Inspektion definieren kann. Zum einen sind das zufällig ausgewählte Fälle, zum anderen aber auch solche, in denen das Modell eine Unsicherheit zeigt. Schließlich soll gewährleistet sein, dass sich das laufende System ständig verbessern kann.
An Systemen mit Künstlicher Intelligenz (KI) wird häufig die Kritik geübt, dass sie den Menschen als Arbeitskraft wegrationieren. Dies ist bei Vision-Systemen nicht unbedingt der Fall. Denn die Arbeitslast wird zwar verringert, jedoch ist das System in vielen Fällen als Unterstützung des Menschen konzipiert. In industriellen Umfeldern kann der Produkt-Durchsatz schnell einmal eine gewisse Grenze überschreiten, bei der es schier unmöglich ist, jedes Fabrikat noch manuell zu inspizieren oder zu klassifizieren.
Systematische Datenerhebung bietet Mehrwert
Eine Ablösung der manuellen Inspektion bietet neben den offensichtlichen Vorteilen (Steigerung von Produktivität, Tempo und Qualität) auch den Vorteil, dass eine systematische Datenerhebung der Fehler in der Produktion vorgenommen wird. Dieser neue Datenbestand ermöglicht es, Korrelationen zwischen Fehlern und Messdaten von Produktionsmaschinen zu bestimmen. Womöglich können so Muster in den Messdaten gefunden werden, die darauf hindeuten, wann die Fehlerhäufigkeit zunimmt. Diese Erkenntnis ermöglicht es, Ausschuss zu reduzieren oder gar den Wartungsprozess zu verbessern.
Wo neu Daten gesammelt werden, ergibt sich oft zusätzlich die Möglichkeit, Prozessinformationen zu extrahieren. Mit den gesammelten Bilddaten sind zum Beispiel auch jeweils die Zeitpunkte der Bildaufnahme/Verarbeitung vorhanden, die Aufschluss über die Betriebszeiten und den Durchsatz geben. Diese Prozessinformationen können dann in Business-Intelligence-Anwendungen wie einem Dashboard ausgewertet werden.
Fazit
Ein Vision-System mit Deep Learning eignet sich für die visuelle Qualitätskontrolle, wenn die klassischen Machine-Vision-Methoden nicht genügen. Grund dafür sind meist fehlende, gleichbleibende Rahmenbedingungen und/oder fehlende Flexibilität der klassischen Modelle (neue Produkte, neue Farbvarianten, …). Die Bausteine einer Bildverarbeitung sind neben Kamera, Beleuchtung und Trigger auch der Bildverarbeitungs-Server, das Modelltraining, ein benutzerfreundliches GUI sowie die menschliche Qualitätskontrolle. Eine hybride Architektur (Cloud/On-Premises) dieser Komponenten bietet viele Vorteile.
Wer sich für einen Deep-Learning-Ansatz entscheidet, setzt auf Daten. Diese gilt es in einer Qualität und einer Quantität zu halten, die es erlaubt, daraus einen Mehrwert zu erzielen. Die manuelle Qualitätskontrolle entfällt nicht notwendigerweise zu 100 Prozent. Mitarbeitende in der Qualitätssicherung erhalten jedoch durch ein Vision-System mit Deep Learning ein Werkzeug, mit dem sie fehlerfreier, effizienter und zielgerichteter Qualitätssicherung betreiben können.
Weitere Informationen
[CS230]
CS230: Deep Learning. 2021,
https://cs230.stanford.edu/, abgerufen am 5.11.2021
[EMVA]
European Machine Vision Association: GenICam,
https://www.emva.org/standards-technology/genicam/, abgerufen am 5.11.2021
[GBC16]
Goodfellow, I. / Bengio, Y. / Courville, A.: Deep learning. MIT press 2016
[Hec16]
Heckenkamp, C.: Machine Vision Fundamentals Outline and Principles, 01/2016.
https://www.emva.org/wpcontent/uploads/EMVA_MV-Fundamentals-01_2016-11.pdf, abgerufen am 5.11.2021
[LBH15]
LeCun, Y. / Bengio, Y. / Hinton, G.: Deep learning. In: Nature, Vol. 521, No. 7553, 2015, S. 436
[LeC89]
LeCun, Y. et al.: Backpropagation applied to handwritten zip code recognition. In: Neural computation, Vol. 1, No. 4 1989, S. 541–551
[Sch15]
Schmidhuber, J.: Deep learning in neural networks: An overview. In: Neural networks, Vol. 61, 2015, S. 85–117









