

Die Frage nach dem konkreten Vorgehensmodell für KI-Entwicklung und Betrieb stößt in den Unternehmen oft auf Verwunderung. Die meisten Unternehmen sind mit den allerersten KI-Projekten beschäftigt, die oft noch den Charakter eines Experiments haben. Jedenfalls sind sie aber weit davon entfernt, ein ganzes Portfolio von KI-Projekten zu managen, sodass sich die Frage nach festgelegten Arbeitsschritten, entsprechenden standardisierten Ergebnistypen und Quality Gates bis jetzt nicht gestellt hat. Das soll natürlich nicht sagen, dass überhaupt kein Vorgehensmodell verwendet wird. Im Gegenteil wird je nachdem, wo die KI-Initiative organisatorisch aufgehängt ist, das dort etablierte Verfahren verwendet. So finden wir FuE-orientierte Produktentwicklungsverfahren, etwa Design Thinking, BI-orientierte Modelle, wie das CRISP-DM [Wir00], oder natürlich Vorgehen der Anwendungsentwicklung, sowohl „Wasserfall“-artige als auch agile.
All diesen Vorgehensweisen ist gemein, dass sie erstens als Einzelprojekte verstanden werden und zweitens ausgehend von konkreten Anforderungen einem vorgegebenen Projektziel zustreben. Auch wenn dabei Schleifen und Rückkopplungen sowohl vorgesehen sind als natürlich auch vorkommen, unterstützen diese Vorgehensweisen in erster Linie einen sukzessiven Aufbau von zusätzlichen Funktionalitäten. Diese Funktionalitäten werden üblicherweise in einem oder wenigen Releases ausgeliefert und so im Betrieb stabilisiert, dass sie zuverlässig und robust laufen.
Derartige Vorgehensmodelle spiegeln die Realität der KI-Projekte, wie etwa im Data-Science-Prozess-Modell [Sch20] beschrieben, nur ungenügend. Der darüber hinausgehende dauerhafte Betrieb, insbesondere eines ganzen Portfolios von KI-Anwendungen, wird bei allen Vorgehensweisen eher am Rande betrachtet.
Entwicklung und Betrieb einer KI-Anwendung folgen anderen Regeln als die einer normalen Anwendung. Obwohl natürlich auch hinter einem KI-Vorhaben eine Geschäftsanforderung steckt, ist die Art der Umsetzung wegen des noch unbekannten Verhaltens des verwendeten Trainingsdaten-Korpus zu Beginn völlig offen. Statt also eine spezifische Funktionalität aufzubauen, geht es eher darum, verschiedene, Code-seitig meist schon existierende Optionen systematisch auf ihre Eignung zu untersuchen bzw. zu optimieren.
Die Konsequenz daraus ist, dass – obwohl ein fertiges KI-Modell letztlich natürlich auch Software ist – typische Softwareentwicklung zunächst eine untergeordnete Rolle spielt. Die Data Scientists fügen bestehende Code-Komponenten zusammen, wobei ihre Aufmerksamkeit darauf liegt, in kurz getakteten Iterationen die grundsätzliche Eignung der verwendeten Verfahren mit den verfügbaren Trainingsdaten zu prüfen oder in einem nachgelagerten Schritt die Leistungsfähigkeit des Modells durch Parameter-Tuning systematisch zu verbessern. Sie verwenden oft „bequeme“ Softwarewerkzeuge, wie Pandas und SciKit-learn, die oft nicht für einen produktiven Betrieb optimiert sind. Wenn ein Modell die Anforderungen in Bezug auf Vorhersagequalität erfüllt und der Data Scientist damit seine Arbeit als getan sieht, hat die dann vorliegende Software in der Regel nicht einen Produktionsstandard im Sinne von robust, performant und sicher. Problematischer noch ist, dass die Software kaum Anknüpfungspunkte für ein systematisches Refactoring bietet, weil beispielsweise kein umfassendes Portfolio von Testfällen existiert.
Eine weitere Konsequenz der oben genannten Vorgehensweise ist, dass die Zuständigkeit des Projektteams endet, sobald das Vorhaben im Anlaufbetrieb eine gewisse Stabilität und Anwenderakzeptanz erreicht hat. Der Betrieb der Software wird vom Projektteam übergeben und die anschließende Pflege und Wartung zielt auf die Umsetzung kleinerer inhaltlicher Änderungen oder der Beseitigung von Programmfehlern ab, sodass ein üblicher Release-Zyklus meist ausreicht. Die Trennung zwischen Entwicklung und Betrieb von KI-Modellen ist im Gegensatz dazu kein erfolgversprechender Ansatz, besonders weil die Leistungsfähigkeit bzw. Vorhersagekraft eines KI-Modells sehr schnell nachlassen kann, wenn sich die unterliegende Realität von jener der Trainingsbedingungen entfernt – der sogenannte Concept Drift. Entsprechende Vorkehrungen werden aber in den klassischen Vorgehensmodellen nicht explizit abgebildet.
Zwar nicht direkt Teil des Vorgehensmodells, aber eng damit verbunden, ist die Frage nach der eingesetzten Entwicklungsumgebung. In den klassischen BI oder IT-Projekten stehen für Entwicklung und Test typischerweise technische Umgebungen bereit, deren Leistungsfähigkeit deutlich niedriger sein kann als die der späteren Produktionsumgebung. Für die KI-Entwicklung sind die Anforderungen genau entgegengesetzt: Rechenleistung wird vor allem beim Modelltraining gebraucht. Steht diese nicht zur Verfügung, arbeiten die Data Scientists oft nur auf einem Ausschnitt der Daten, damit die Modellberechnungen in annehmbarer Zeit ablaufen können. Trotz aller Bemühungen sind diese Teildatensätze dann oft doch nicht hinreichend repräsentativ und die Modellqualität ist in der Realität deutlich schlechter als erwartet.
Anforderungen an ein zielführendes Vorgehensmodell für KI-Modell-Entwicklung und -Betrieb sind deshalb zusammengefasst:
- Entwicklung und Betrieb des KI-Modells werden gesamthaft betrachtet.
- Das Vorgehen ist auf das Ausprobieren vieler Modell-Varianten in kurzer Zeit ausgelegt.
- Am Ende der Modellbildung steht produktionsreifer Code.
- Das KI-Modell wird im Betrieb durchgängig überwacht, um „Concept Drift“ zu erkennen.
- Organisatorische und technische Vorkehrungen unterstützen ein schnelles Nachschärfen und Re-Deployment des Modells.
Vorgehensmodell für industrialisierte KI-Entwicklung und -Betrieb
Als Auslöser zur Anwendung von DevOps-Prinzipien im Kontext von KI-Anwendungen gilt die Präsentation von Sculley [Scu15], die in verschiedenen Gruppen weltweit Aktivitäten auslöste, in Deutschland etwa [Mar21]. Interessant dazu auch das schon früh formulierte Konzept eines Data & Analytics-Ökosystems, in dem Entwicklung und Betrieb zusammenspielen [Zim19].
Abbildung 1 zeigt eine Übersicht des von uns regelmäßig und erfolgreich eingesetzten Vorgehensmodells, das die oben hergeleiteten Anforderungen erfüllt. Ähnlich wie bei DevOps des Software Engineering stehen Entwicklung und Betrieb der KI-Modelle gleichberechtigt nebeneinander. Weil aber das Ausprobieren verschiedener Modellvarianten im Kern der KI-Entwicklung steht, wird nicht jeder Entwicklungsschritt in die Produktion übernommen, sondern nur solche, bei denen das KI-Modell als hinreichend gut bewertet wird – daher die dünner gezeichnete Verbindung der Anmeldung eines KI-Modells für den Betrieb.
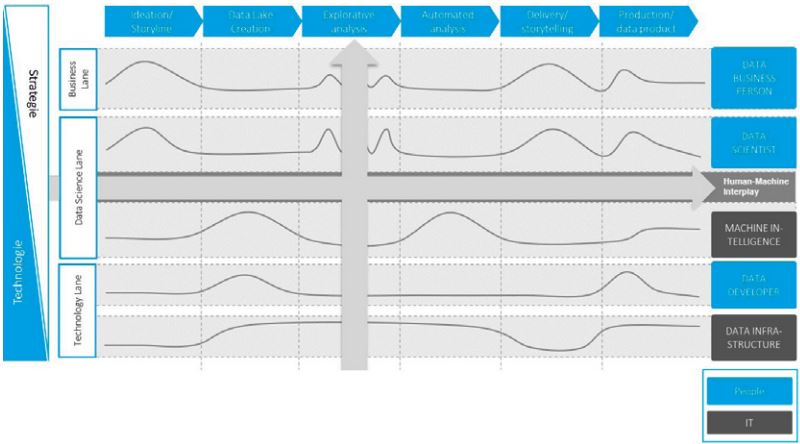
Abb. 1: Vorgehensmodell für industrialisierte KI-Entwicklung und -Betrieb
Auch auf dem Rückweg von Betrieb zu Entwicklung unterscheidet sich der Ansatz vom klassischen DevOps-Ansatz, der ja darauf ausgelegt ist, im Sinne von Continuous Delivery laufend neue Funktionalität in kleinen Inkrementen produktiv zu bringen. Aber auch wenn Aktualisierungen der KI-Modelle wegen des Concept Drift laufend vorkommen können und deshalb vorgesehen werden müssen, sind sie nur fallweise relevant. Auch das ist in dem Schaubild durch eine dünner gezeichnete Verbindung zum Nachschärfen des Modells abgebildet.
Vor dem Hintergrund der oben beschriebenen Tatsache, dass im Ziel sehr viele jeweils hochspezialisierte KI-Anwendungen betrieben und auf ihre Leistungsfähigkeit überwacht werden müssen, erhält der Monitoring-Aspekt eine herausgehobene Bedeutung im Vorgehensmodell.
Zusammenfassend gesagt, unterscheidet sich das hier vorgestellte Vorgehensmodell vom klassischen DevOps insofern, als die Kopplungen zwischen KI-Entwicklung und -Betrieb unregelmäßiger sind, aber nichtsdestotrotz gut institutionalisiert sein müssen. Das alles natürlich in einer festen Klammer des mit dem Anwendungsfall (Use-Case) angestrebten betriebswirtschaftlichen Nutzens und dessen Nachweis.
Nachfolgend werden die einzelnen Phasen des Vorgehensmodells genauer beleuchtet.
Use Cases – Identifikation von KI-Anwendungsfällen
Viele Führungskräfte interessieren sich für den Einsatz Künstlicher Intelligenz, entweder um die Effizienz im Unternehmen zu steigern oder ihr Angebot aus Produkten und Dienstleistungen aufzuwerten. Da sie dabei aber oft nur vage Vorstellungen von KI haben, müssen KI-Experten helfen, in Bezug auf den angestrebten Nutzen einerseits und die verfügbaren Daten andererseits geeignete Anwendungsfälle zu finden.
Als Startpunkt für solche Überlegungen hat es sich bewährt, Beispiele von bereits realisierten KI-Anwendungen darzustellen, um Ambition und Realitätsnähe bei der Ideenfindung zu steuern. Wenn es etwa um die Selbststeuerung eines Prozesses gehen soll, ist es deshalb wichtiger zu zeigen, mit welcher Art von Daten welche Art von Vorhersagen gemacht werden können, als zu diskutieren, welcher Algorithmus genau dazu verwendet werden könnte. Insbesondere die Frage, wie andere Unternehmen die verfügbaren Daten in Bezug auf Umfang und Qualität für den angestrebten Zweck beurteilt haben bzw. den Use-Case daraufhin abgestimmt haben, hilft zum Verständnis. Zusätzlich schafft das auch das Vertrauen, Ähnliches im eigenen Unternehmen schaffen zu können. Bei aller Erfahrung, die bei einem derartigen Vorgehen von außen hereingetragen wird, sind die Erwartungen trotzdem zu managen, weil die Rest-Unsicherheit bezogen auf die eingesetzten Daten endgültig erst im Projekt ausgeräumt werden kann.
In jedem Fall aber können die verschiedenen Projektideen hinsichtlich ihrer Erfolgsaussicht verglichen und priorisiert werden. Bei der Diskussion von möglichen Use-Cases ist es entscheidend, den Horizont der Führungskräfte von Anfang an so zu erweitern, dass sie über klischeeartige Anwendungsfälle, beispielsweise Predictive Maintenance in einem Produktionsszenario, hinausdenken und stattdessen die gesamte Wertschöpfungskette betrachten, etwa
- Absatzvorhersagen für Marketing und Produktionssteuerung,
- schnelle Preisindikation bei Kleinserienfertigung für den Vertrieb,
- Übersetzung des Portfolios noch offener Angebote in die erwartete Ressourcenauslastung für die Fertigung oder
- Vorhersage des Ersatzteilbedarfs eines Reparaturauftrags allein aus der Symptombeschreibung der Störung.
Selbst wenn die vorgestellten Beispiele aus anderen Industrien kommen, beobachten wir regelmäßig kreative Transferleistungen der Führungskräfte, um für ihr Unternehmen passende Ideen zu finden.
Aufsatzpunkt sind dabei oft gravierende Probleme, die bis dahin mit konventionellen Mitteln nicht erfolgreich gelöst werden konnten und deshalb jetzt mit Verfahren des maschinellen Lernens angegangen werden sollen. Weil diese Themen im Unternehmen jeweils schon länger im Zentrum der Aufmerksamkeit stehen, werden sie in der Regel bereits durch eine entsprechende Kenngröße charakterisiert, die auch regelmäßig verfolgt wird. Das Ziel des KI-Einsatzes ist deshalb einfach als eine Verbesserung ebenjener Kenngröße leicht zu fassen. Ein angenehmer Seiteneffekt: Da der erwartete Nutzen für die Führungskräfte eines solchen Use-Case so offensichtlich ist, wird eine monetäre Bewertung des KI-Einsatzes, etwa durch eine explizite Wirtschaftlichkeitsrechnung, zu diesem Zeitpunkt oft nicht so dringend wie sonst üblich in Projekten eingefordert. Das umso mehr, als der Projektumfang idealerweise so gewählt wird, dass ein erstes Minimum Viable Product absehbar innerhalb von drei Monaten produktiv gesetzt werden kann und schon deshalb das betriebswirtschaftliche Risiko begrenzt ist.
KI-Entwicklung
Wie bereits oben ausgeführt, gibt es selbst bei sorgfältigster Auswahl des Use-Case erst bei der konkreten Arbeit mit den Daten letzte Sicherheit über den Projekterfolg. Insofern ist ein agiles Vorgehen noch wichtiger als in der klassischen Softwareentwicklung, um schnell auf Erkenntnisse reagieren zu können. Bewährt haben sich zweiwöchentliche Sprints, an deren Ende die Ergebnisse in einem abschließenden Review gemeinsam durch Product Owner und Entwicklerteam bewertet werden. Data Scientists entwickeln ihre KI-Modelle in der Regel auf Basis von Algorithmen, für die Code als Open Source meist bereits verfügbar ist. Insofern liegt die Entwicklungsarbeit weniger darin, Funktionalität zu programmieren, als vielmehr darin, in einer Abfolge von Trainings- und Testläufen zu bestimmen, welcher der möglichen Algorithmen mit den vorhandenen Daten die besten Vorhersagen liefert.
Im Sinne des agilen Vorgehens werden die Ergebnisse im Sprint-Review selbstverständlich immer so präsentiert, als könnte der aktuelle Stand des Modells produktiv gesetzt werden. Insofern ist in der Entwicklungsphase von Anfang an – und parallel zur KI-Modellbildung – klassisches Software Engineering gefragt, damit der Code am Ende des Sprints Produktionsstandards erfüllt, das heißt robust, performant und sicher ist.
Data Scientists arbeiten dazu Hand in Hand mit Software Engineers und folgen dabei insbesondere einem testgetriebenen Softwareentwicklungsprozess, mit konsequentem Versionsmanagement und automatisierten Software-Builds. Dies ist ein bedeutender Unterschied zu einem oft beobachteten, durch Provisorien getriebenen KI-Entwicklungsprozess und der dann nachgelagerten Optimierung des Codes für Produktionszwecke. Entscheidender Vorteil des hier vorgeschlagenen Vorgehens ist, dass das Modell unmittelbar einsatzfähig ist und der erwartete Nutzen sofort eingefahren werden kann, sobald der Product Owner eine hinreichend gute Vorhersagequalität bescheinigt.
Der Product Owner, in der Regel der ursprüngliche Initiator der Idee, verfolgt den Entwicklungsfortschritt eng und nimmt zwingend an den Sprint-Reviews teil, um dem Entwicklungsteam jederzeit Orientierung geben zu können. Das ist deshalb wichtig, weil in jedem Sprint wegen der vielen Experimente deutliche Erkenntnissprünge in Bezug auf die zugrunde liegenden Daten erwartet werden.
In den Sprint-Reviews wird deshalb regelmäßig diskutiert, ob die verfolgte Richtung anhand der aktuellen Ergebnisse noch erfolgversprechend ist oder ob – und wenn ja, wie – die Richtung des Vorhabens angepasst werden muss, um mit den verfügbaren Daten dem angestrebten Geschäftsziel gerecht zu werden. So kann es beispielsweise notwendig sein, die ursprüngliche Ambition anzupassen, wenn der Datenumfang gering ist. Dazu könnte der Product Owner die ursprünglichen Anforderungen senken, indem er eine niedrigere Vorhersagequalität akzeptiert oder die vorherzusagende Größe selbst vereinfacht wird, etwa indem statt einer Multi-Klassifizierung auf eine einfache binäre zurückgegangen wird. Maßgabe sollte dabei immer sein, das KI-Modell möglichst schnell produktiv zu setzen, um während der Zeit etwaiger weiterer Datensammlung parallel schon konkrete Erfahrungen im Betrieb zu sammeln.
KI-Betrieb
Der Product Owner entscheidet, wann ein KI-Modell gut genug ist, um eingesetzt zu werden. Ein hoher Automatisierungsgrad ist zwingend, um Schnelligkeit und Verlässlichkeit im Deployment zu erreichen, insbesondere wenn praktisch jedes Modell absehbar zu einem späteren Zeitpunkt nachgeschärft werden muss und die Downtime dabei klein gehalten werden soll. Bei den im Ziel sehr vielen KI-Modellen hilft die Automatisierung darüber hinaus, den Arbeitsaufwand so gering wie möglich zu halten. Das Vorgehensmodell setzt dazu auf die Prinzipien der Continuous Delivery, die durch eine entsprechende Werkzeuglandschaft unterstützt wird, wie sie weiter unten beschrieben wird.
Die laufenden KI-Modelle müssen natürlich wie andere Software auch überwacht werden in Hinsicht darauf, inwieweit sie verfügbar sind und wie sie die Ressourcen nutzen – bei KI-Anwendungen aber eben auch, wie es um ihre Vorhersagequalität steht. Diese kann im Betrieb deutlich nachlassen, wenn sich die Umwelt im Vergleich zu den ursprünglichen Trainingsbedingungen ändert. Hierfür ist ein Quality of Service Monitoring vorzusehen, das anschlägt, wenn die Vorhersagequalität unter ein definiertes Maß abzusinken droht und deshalb das Modell nachtrainiert werden muss.
Spätestens wenn ein Modell dann zum Nachschärfen zurück in die Entwicklung gegeben wird, zahlt sich die Investition in professionelles Software Engineering aus. In der Regel wird das ursprüngliche Entwicklungs-Team bereits in neuen Projekten gebunden sein, sodass andere Entwickler auf einem gut dokumentierten und mit umfassenden Testfällen untermauerten Stand aufsetzen können, um das Modell zu aktualisieren und schnell wieder produktiv zu setzen.
Nutzen-Nachweis
Auch wenn bei der ursprünglichen Auswahl der Anwendungsfälle möglicherweise auf eine detaillierte Wirtschaftlichkeitsrechnung verzichtet wurde, ist es ratsam, den mit KI realisierten Nutzen durchgängig zu messen und nachzuhalten, um die Investitionen und laufenden Kosten für KI betriebswirtschaftlich zu rechtfertigen. Zusätzlich kann mit einem derartigen Reporting aber auch das Vertrauen in die Leistungsfähigkeit von KI im Unternehmen auf breiter Basis gestärkt werden. Das ist gerade am Anfang des KI-Einsatzes noch wichtig, sollte die KI noch skeptisch gesehen oder sogar belächelt werden. Im einfachsten Fall werden für das Reporting die von KI beeinflussten Leistungsindikatoren verfolgt, die entsprechenden Verbesserungen monetär bewertet und das Ganze regelmäßig an prominenter Stelle im Unternehmen veröffentlicht.
Werkzeuglandschaft für industrialisierte KI-Entwicklung und -Betrieb
Die klassischen BI-Umgebungen der Unternehmen sind nicht in der Lage, mit den teilweise sehr großen und schwach oder sogar unstrukturierten Datensätzen umzugehen. Den IT-Abteilungen fehlt oft die Kompetenz für die Big-Data-Technologie, aber viel mehr noch die Kapazität, um schnell relevante KI-Werkzeuge bereitzustellen. Viele Data Scientists ziehen sich deshalb darauf zurück, solche Werkzeuge lokal auf ihren Rechnern zu installieren. Doch selbst wenn diese Geräte mit leistungsfähigen CPUs und GPUs sowie großen Speicherplatten ausgestattet sind, kommen sie beim maschinellen Lernen schnell an ihre Grenzen. Data Scientists begegnen solchen Beschränkungen sehr pragmatisch, indem sie die Modelle nur auf einem Teil der Daten trainieren und auf die systematische Evaluation alternativer Modelle oder Hyperparameter-Ausprägungen verzichten.
Das oben beschriebene Vorgehensmodell ist darauf ausgelegt, KI von Anfang an so zu entwickeln, dass sie schnell produktiv gesetzt werden kann. Soll darüber hinaus aber KI im Unternehmen dauerhaft und in entsprechender Breite eingesetzt werden, muss das Vorgehensmodell mit einer IT-Werkzeuglandschaft unterlegt sein, die den Schritt von der manufakturhaften zur industrialisierten Entwicklung und Betrieb erlaubt.
Anforderungen an eine Data-Science-Plattform
Die übergreifenden Anforderungen an eine solche Data-Science-Plattform sind deshalb daraus abgeleitet, die Produktivität bei Entwicklung und Betrieb von KI zu steigern:
- Flexible Bereitstellung von skalierbarer Infrastruktur für massive Parallelverarbeitung bei Data Engineering und KI-Modellbildung
- KI Software Development Kits (SDK) in verschiedenen Programmiersprachen mit wiederverwendbaren und modularen KI- Softwarekomponenten
- Unterstützung eines testgetriebenen Software Engineering mit entsprechendem Versionsmanagement
- Betriebswerkzeuge mit hohem Automatisierungsgrad für Deployment und Monitoring
Abbildung 2 zeigt diese Anforderungen, vor allem die reibungslose Zusammenarbeit der im Entwicklungs- und Betriebsprozess Beteiligten unterstützen. Auch wenn gerade am Anfang des KI-Einsatzes möglicherweise mehrere Rollen von einer Person ausgefüllt werden, ist doch von Anfang an im Auge zu behalten, dass mit der Skalierung der KI-Aktivitäten eine Rollenspezialisierung einhergeht und die Zusammenarbeit deshalb von Anfang an durch die entsprechenden technischen Werkzeuge institutionalisiert wird.
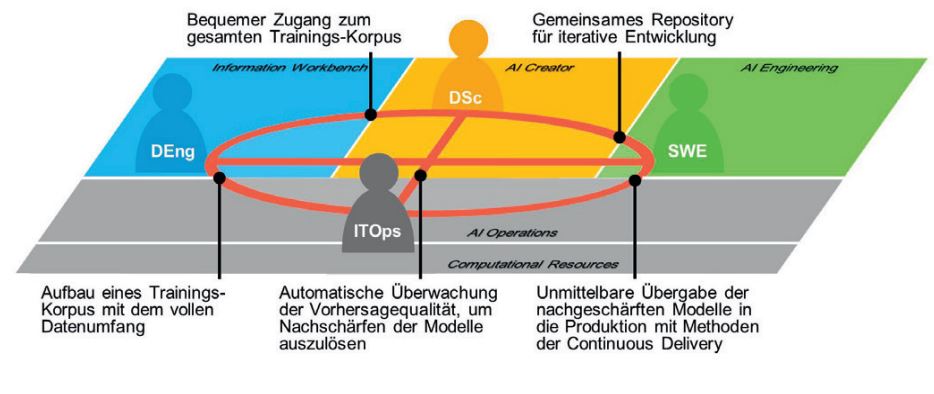
Abb. 2: Struktur einer Data-Science-Plattform und Anforderungen für die übergreifende Zusammenarbeit der beteiligten Rollen Data Engineer (DEng), Data Scientist (DSc), Software Engineer (SWE) und IT-Betrieb (ITOps)
Die Entwicklung von KI-Modellen mittels überwachtem oder unüberwachtem maschinellem Lernen erfordert den Aufbau eines Datenkorpus meist aus verschiedenen Quellen. Ein solcher Datenkorpus ist in der Regel eine sehr große flache Datentabelle mit Zehntausenden Spalten – den Merkmalen – und oft Millionen von Zeilen. Einen derartigen Korpus aufzubauen und effektiv für das maschinelle Lernen vorzubereiten, etwa zu reinigen, und später im maschinellen Lernen zu verarbeiten, erfordert die Datenspeicherung in einem verteilten Dateisystem und eine skalierbare massive Parallelverarbeitung, wie sie etwa mit der Spark-Technologie möglich ist. Das ist notwendig, um angesichts solcher im Unternehmensumfeld typischen Datenmengen sowohl in der Datenaufbereitungs- als auch der Modellierungsphase in einem iterativen Ansatz zügig und breit verschiedene Optionen testen zu können. Data Engineers und Data Scientists sollen sich dabei um die technische Bereitstellung derartiger Infrastruktur nicht explizit kümmern müssen.
Damit die Data Scientists das am besten geeignete Modell schnell identifizieren und dann optimieren können, sollten die grundsätzlich verfügbaren Open-Source-Algorithmen so gekapselt und in eine Entwicklungsumgebung integriert sein, dass „Plug and Play“ verwendet werden kann, um die KI-Modelle gewissermaßen „industrialisiert“ zu entwickeln. Da nicht alle Algorithmen in den verschiedenen Programmiersprachen gleich gut umgesetzt sind, ist es vorteilhaft, wenn die Data Scientists die Programmiersprache für jeden Use-Case flexibel wählen oder sogar kombinieren können.
Erfüllt ein KI-Modell die Anforderungen, wird es als voll lauffähige Instanz in Form eines Software-Containers vollautomatisch für die Inbetriebnahme bereitgestellt, um in den verschiedenen IT-Umgebungen, also der Cloud, der Edge oder der klassischen IT-Welt, laufen zu können. Ein weiterer Vorteil solcher Container ist, dass sie über APIs angesprochen werden und deshalb die Integration mit der existierenden IT-Landschaft nur schwach ausgeprägt sein muss. Die Belastung der IT-Ressourcen und Abhängigkeiten etwa aus bestehenden Release-Zyklen werden damit wirksam umgangen. Unternehmen, die KI entlang der Wertschöpfungskette einsetzen, werden im Normalfall viele, vielleicht Hunderte, Container mit KI-Anwendungen betreiben müssen, weil der Umfang jeder einzelnen KI-Anwendung bekanntermaßen sehr begrenzt ist. Um diese Mengen sowohl in Bezug auf das Deployment, das Auslastungsmanagement der erforderlichen Ressourcen, als auch in Bezug auf das Monitoring zu beherrschen, ist auf die Orchestrierung der Microservice-artigen KI-Anwendungen zu achten.
Beispiel einer Data-Science- Plattform – TI.KI mDSP
Die großen Cloud-Anbieter haben in den letzten Jahren ihr Dienstleistungsspektrum entlang der oben beschriebenen Anforderungen perfektioniert. Gleichzeitig ist im Markt aber auch zu beobachten, dass einige Unternehmen aus strategischen oder betriebswirtschaftlichen Gründen nach Alternativen suchen. Nachfolgend wollen wir einen Ansatz zeigen – die in Abbildung 3 gezeigte TI.KI Managed Data Science Platform mDSP –, der entsprechend den oben beschriebenen Anforderungen konzipiert ist. Die Ti.Ki mDSp besteht vollkommen aus Open-Source-Lösungen, die so konfiguriert und integriert sind, dass sie den Prozess von KI-Entwicklung und -Betrieb wie oben beschrieben durchgängig unterstützen. Neben der automatischen Provisionierung von Compute und Storage als Notebook Pods für das Data Engineering und die Entwicklung der KI-Modelle stellt sie Software Development Kits mit aktuell mehr als 40 wiederverwendbaren und gleichartig modularisierten Verfahren zur Verfügung, die eine industrialisierte KI-Entwicklung unter dem Gesichtspunkt der Wiederverwendung erst ermöglichen. Die Software Development Kits sind in verschiedenen Programmiersprachen verfügbar, derzeit Python, Java/Scala und R sowie Go im Versuchsstadium, um der Tatsache Rechnung zu tragen, dass nicht alle KI-Verfahren gleich gut in allen Sprachen realisiert sind. Auf die Weise kann der KI-Entwickler für den jeweiligen Zweck die beste Sprache auswählen – auch verschiedene in einem Projekt. Der Code der Projekte für Aufbau und Verfeinerung des Datenkorpus und jener der Modelle wird genauso in einem Versionsmanagement-Programm verwaltet wie Metadaten zu den Datenkorpora und den KI-Modellen.
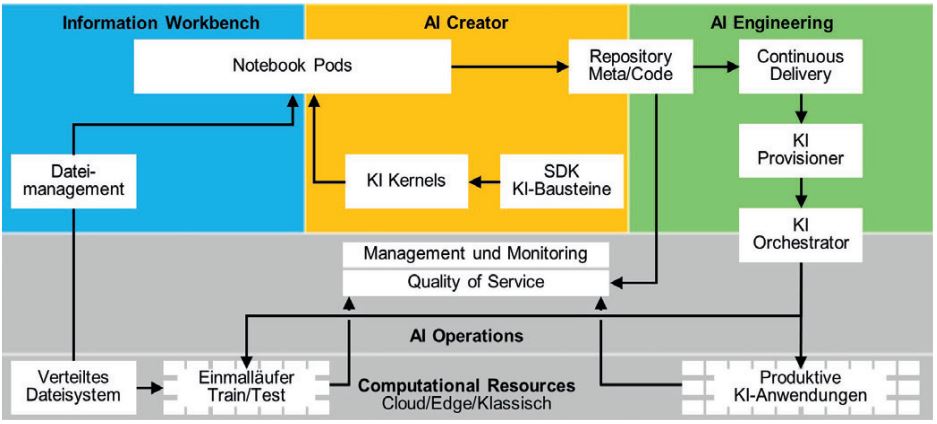
Abb. 3: TI.KI mDSP als Beispiel einer Werkzeuglandschaft für industrialisierte Entwicklung und Betrieb von KI-Anwendungen
Die Code-Komponenten werden automatisch und im Sinne kontinuierlicher Integration mit einem webbasierten Softwarepaket zu lauffähigen und containerisierten KI-Modellen gebaut und produktiv gesetzt. Da die Zahl der laufenden KI-Anwendungen sehr schnell wachsen kann, werden die laufenden Container automatisch orchestriert und die unterliegende Infrastruktur automatisch skaliert.
Das Quality of Service Monitoring verfolgt die Vorhersagequalität der Modelle.
Bis auf wenige Ausnahmen ist die gesamte Landschaft aus führenden Open-Source-Komponenten zusammengebaut. Bei der Verwendung von Open-Source-Software haben einige Unternehmen lizenztechnisch schlechte Erfahrungen gemacht. Für die TI.KI mDSP wird deshalb ausschließlich unter Apache 2.0 lizenzierte Software eingesetzt, sodass im Unternehmenskontext entwickelte Derivate und Erweiterungen von einer Veröffentlichung ausgenommen werden können: Insbesondere KI-Anwendungen sind deshalb dauerhaft geschützt.
Gleichzeitig garantiert der Open-Source-Ansatz die totale Transparenz über die Datenverwendung und die Unternehmen müssen nicht befürchten, dass ihre Daten nicht doch durch eine Hintertür abgezogen werden. Hier ist die Open-Source-Community ein wachsamer Partner.
Fazit und Ausblick
Der Einstieg in das strategische Feld des Einsatzes von KI für die Prozessoptimierung sowie die Erweiterung von Produkten und Dienstleistungen ist sowohl methodisch als auch IT-technisch auch für mittelständische Unternehmen beherrschbar, ohne zwingend auf die großen Cloud-Anbieter angewiesen zu sein. Durch den Einsatz von Open-Source-Komponenten können auch kleinere Unternehmen von der weltweiten Innovationskraft profitieren und dabei die Kosten in Grenzen halten.
Weitere Informationen
[Atl21]
Atlassian, 2021,
https://www.atlassian.com/zh/devops, abgerufen am 14.5.2021
[Bun20]
Bundesregierung: KI-Strategie der Bundesregierung – Dashboard. 2020,
https://www.ki-strategiedeutschland.de/files/downloads/201125_Dashboard_KI-Strategie.pdf, abgerufen am 14.5.2021
[Mar21]
Martel, Y. et al.: Software Architecture Best Practices for Enterprise Artificial Intelligence. In: INFORMATIK 2020, 2021, S. 165–181
[Sch20]
Schulz, M. / Neuhaus, U. et al.: DASC-PM v1.0 – Ein Vorgehensmodell für Data-Science-Projekte. 2020,
https://www.nordakademie.de/sites/default/files/2020-02/20200220_DASC-PM%20%28002%29.pdf, abgerufen am 4.5.2021
[Scu15]
Sculley, D. et al.: Hidden technical debt in machine learning systems. In: Advances in neural information processing systems, Vol. 28, 2015, S. 2503–2511
[Wir00]
Wirth, R. / Hipp, J.: CRISP-DM: Towards a standard process model for data mining. In: Proceedings of the 4th international conference on the practical applications of knowledge discovery and data mining, 2000, S. 29–39
[Zim19]
Zimmer, M.: Von einer BI-Landschaft zum Data & Analytics Ökosystem. In: Haneke, U. et al.: Data Science: Grundlagen, Architekturen und Anwendungen (Edition TDWI), Kindle Ausgabe, 2019, Kap. 7









