

Die in einer IoT-Landschaft anfallenden Sensor-Daten stellen neue Anforderungen an die Speicherung, Verarbeitung und Analyse von Daten [STH18]:
- Es können extrem große Datenmengen in sehr kurzer Zeit anfallen.
- Die geforderte maximale Zeitspanne zwischen der Erzeugung der Daten und ihrer (eventuell komplexen) Auswertung kann sehr gering sein.
- Die in den Sensoren anfallende Datenmenge kann die verfügbare Bandbreite der Anbindung zu zentralen Auswertungssystemen überschreiten.
- Neue Arten von Auswertungen, wie etwa Machine-Learning-basierte Advanced Analytics, sollen möglichst in Echtzeit durchgeführt werden.
Um diese Anforderungen zu erfüllen, sollten die Architekturen für die Speicherung, Verarbeitung und Analyse von IoT-Daten von vornherein entsprechend aufgebaut werden. Dazu werden im Folgenden vier Varianten mit unterschiedlichen Schwerpunkten vorgestellt.
Die Herausforderungen bei der Analyse von IoT-Daten
Das Charakteristische von IoT-Daten ist, dass sie nicht durch menschliche Interaktion, sondern automatisch durch Sensoren erzeugt werden. Es gibt unterschiedliche Arten von Sensoren: Sie reichen vom einfachen numerischen Temperaturmesswert bis hin zum mit einer Kamera aufgenommenen Bild. Auch der Zeitpunkt des Anfallens der Daten ist interessant: Es ist weit verbreitet, dass Sensoren in festen Zeitabständen, zum Beispiel jede Sekunde, neue Messwerte liefern. Zum anderen können die Daten aber auch in unregelmäßigen Zeitabständen erzeugt werden, wenn Daten nur geschickt werden, wenn ein Auslöseereignis aufgetreten ist. Ein Beispiel für Letzteres wäre eine Kamera, die nur Bilder schickt, wenn ein Bewegungssensor auslöst.
Für Sensoren werden Metadaten gespeichert wie etwa die Position oder der Typ des Sensors. Metadaten sind typischerweise über einen längeren Zeitraum konstant. Sensoren sind häufig sehr einfach ohne (größeren) Speicher und ohne Verarbeitungsleistung. Deshalb hat man in einer IoT-Architektur normalerweise sogenannte Edge Devices, die Daten von mehreren lokalen Sensoren sammeln, speichern und auswerten können.
Verwendung der IoT-Daten
Aus den Ausführungen des vorherigen Abschnitts kann man sehen, dass von Sensoren erzeugte Daten Zeitreihen [Cha03] bilden. Es gibt zum einen Auswertungen, die sich auf die Zeitreihe eines Sensors beziehen, und Auswertungen, die sich über viele oder gar alle Sensoren erstrecken. Diese Auswertungen können traditionelle Analysen sein, wie man sie aus dem BI-Bereich kennt, oder auf Machine Learning beruhende Advanced Analytics [HAP18].
Eine weitere Unterscheidung kann nach dem Verwendungszweck im Unternehmen gemacht werden, für den man die Auswertungen nutzen möchte. Dabei können das Ziel sowohl strategische Erkenntnisse, Erkenntnisse zur Geschäftsentwicklung, operationale Erkenntnisse, aber auch Erkenntnisse zur automatischen Steuerung sein. Während man die ersten drei Arten von Erkenntnissen auch bei traditionellen BI-Systemen findet, führen die für IoT-Systeme typischen Erkenntnisse zur automatischen Steuerung zu der Notwendigkeit, diese in Echtzeit zu erhalten.
Das Alter (Zeit seit der Erzeugung der Daten) und die mögliche Nutzung aggregierter Daten hängen vom beabsichtigten Verwendungszweck der Analysen ab. Dieser Zusammenhang ist in Abbildung 1 dargestellt.
Wie schon erwähnt, spielen Echtzeiterkenntnisse für viele IoT-Anwendungen eine große Rolle, um sie für die automatische Steuerung zu nutzen. Deshalb benötigt man dazu Detaildaten kurz nach ihrer Erzeugung. Für operative bis strategische Erkenntnisse genügt es oft, aggregierte Daten zu verwenden.
Die potenziell große Anzahl der Sensoren (kann bei Hunderten bis Tausenden pro Maschine liegen) und die Notwendigkeit von Detaildaten für Echtzeitanwendungen bedingt eine große Gesamtdatenmenge.
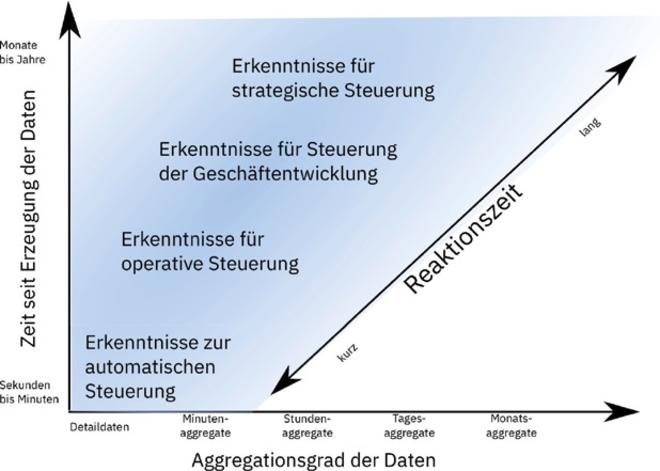
Abb. 1: Zusammenhang von Alter und Aggregationsgrad der Daten
Wieso Edge Devices?
Es gibt mehrere Gründe, wieso in einer IoT Architektur für die Datenanalyse Edge Devices benötigt werden:
- Sensoren können Daten meist nur über kurze Stecken übertragen. Die verwendeten Protokolle für die Datenübertragung sind auf diesen Fall abgestimmt und proprietär.
- Die Datenmenge, die pro Zeiteinheit von den Sensoren erzeugt wird, übersteigt die zur Verfügung stehende Bandbreite zum zentralen System.
- Die geforderte geringe Latenz benötigt lokale Entscheidungen auf Detaildaten.
Edge Devices bieten die Möglichkeit, Daten von lokalen Sensoren einzusammeln, zu speichern, zu verarbeiten und zu analysieren und über Standardprotokolle an eine zentrale Stelle weiterzuleiten. Weitere Gründe für die Verwendung von Edge Devices findet man in [SPX19].
Wie sieht die grundsätzliche Architektur für die IoT-Datenanalyse aus?
Abbildung 2 zeigt, aus welchen Komponenten eine Architektur für die Analyse von IoT-Daten besteht.
Unterschiedliche Sensoren liefern Daten an ein Edge Device, das die Daten speichert. Mit jedem Edge Device können viele Aktoren [Jan04] verbunden sein, um die aus der Analyse der Daten gewonnenen Erkenntnisse in Aktionen umzusetzen. Neben der Speicherung der Daten können Edge Devices die Daten auswerten und aggregieren (vor der lokalen Speicherung oder Weiterleitung). Von diesen Edge Devices gibt es im Allgemeinen ebenfalls viele.
Die Edge Devices sorgen zudem für die Übertragung von (aggregierten) Daten zu einer zentralen Verarbeitung. Dort kann die Speicherung und Auswertung von Daten über alle Sensoren hinweg erfolgen.
Aktionen, die sich aus den Erkenntnissen ergeben, die durch die Auswertung der Daten gewonnen wurden, können von einem zentralen System (im Folgenden sprechen wir nur noch von der Cloud) zu den Edge Devices zurückkommuniziert und von dort in Aktionen für die Aktoren umgesetzt werden. Alternativ können die Ergebnisse der Auswertung in der Cloud natürlich auch an andere Systeme oder Personen kommuniziert werden.
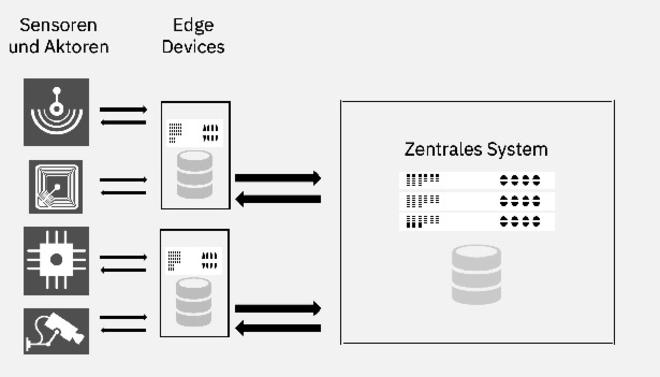
Abb. 2: Grundsätzliche Architektur für Analysen auf IoT Daten
Wo soll man Daten halten, verarbeiten und auswerten?
Als Nächstes soll untersucht werden, ob Daten lokal, das heißt auf den Edge Devices, oder zentral, das heißt in der Cloud, gehalten und verarbeitet werden sollen. Dazu muss man betrachten, welche Hardwareressourcen (CPU, Hauptspeicher und externer Speicher) auf den Edge Devices und in der Cloud zu Verfügung stehen, wie viele Edge Devices verfügbar sind und welche Parameter (Bandbreite, Latenz) für das Netzwerk Edge Devices und Cloud gelten.
Um zu veranschaulichen, wie die Abwägung zwischen lokaler und zentraler Speicherung aussehen kann, soll der Vergleich anhand typischer Annahmen an einem Zahlenbeispiel erfolgen.
Gehen wir von folgenden Annahmen aus:
- 1.000 Edge Devices
- 20 GB Speicherkapazität pro Edge Device
- 0,1 MB Daten pro Sekunde werden von den an einem Edge Device hängenden Sensoren erzeugt.
Damit haben die Edge Devices genügend Speicherkapazität, um die Detaildaten für 2,3 Tage (20.000 MB ÷ 0,1 MB/s = 200.000 s) zu halten. Für die pro Tag anfallenden Detaildaten werden 8,64 TB (86.400 s/Tag ×1 .000 × 0,1 MB/s) als Speicher in der Cloud benötigt. Der in der Cloud benötigte Speicherplatz für die Detaildaten von zwei Jahren beträgt ungefähr 6,3 PB (8,64 TB/ Tag × 2 × 365). Die Bandbreite, die zwischen den Edge Devices und der Cloud benötigt wird, liegt bei 0,1 GB/s (1.000 × 0,1 MB/s).
Nun betrachten wir in diesem Szenario die Ressourcenanforderungen, wenn man lokal die Detaildaten für die möglichen 2,3 Tage hält und in der Cloud nur Daten speichert, die bereits auf eine Minute aggregiert sind. Für die zentrale Speicherung sind dann nur 144 GB pro Tag (8,64 TB ÷ 60) und 105 TB für die zentrale Speicherung der Daten von zwei Jahren notwendig. Auch die benötigte Netzbandbreite zwischen den Edge Devices und der Cloud sinkt drastisch: Es werden nur noch 1,66 MB/s (100 MB/s ÷ 60) benötigt. In diesem Szenario können Abfragen auf den Detaildaten der letzten zwei Tage auf den Edge Devices durchgeführt werden, zentral nur noch Abfragen auf den aggregierten Daten.
Nun betrachten wir den Fall, dass wir lokal nur für einen Tag die Detaildaten speichern und die restliche Speicherkapazität nutzen, um auch lokal auf Minuten aggregierte Daten zu speichern: Für die Detaildaten braucht man lokal 8,64 GB. Damit kann man im lokalen Speicher aggregierte Daten für 78,8 Tage halten: (20 GB – 8,64 GB)÷(0,1 MB/s ÷ 60) ÷ 86.400 s/Tag. Damit kann man auch bei Abfragen nur auf den Edge Devices aktuelle Detaildaten mit historischen aggregierten Daten verknüpfen. Die Anforderungen an den Platz in der Cloud und an die Netzwerkbandbreite ändern sich in diesem Szenario nicht.
Die verschiedenen betrachteten Beispielszenarien sind in Tabelle 1 zusammengefasst.
Die lokale Rechenleistung in den Edge Devices kann genutzt werden, um Abfragen auf den Daten sofort auszuführen. Ein anderer Vorteil dieser lokalen Rechenkapazität ist, dass diese selbst für Abfragen, die alle Sensoren betreffen, genutzt werden kann, wenn man die vielen Edge Devices als einen großen Parallelrechner auffasst.

Tab. 1: Zusammenfassung der betrachteten Beispielszenarien
Architekturvariante 1: Nur zentrale Analyse
Aus der vorhergegangenen Diskussion zur Speicherung, Übertragung und Analyse von IoT-Daten lassen sich mögliche Architekturen konkreter fassen. In der ersten Architekturvariante (Abbildung 3) erfolgt die komplette Speicherung und Analyse der Daten auf einem zentralen System (in der Cloud). Die Sensoren sind an einem Edge Device angeschlossen und liefern die Daten der Sensoren in vollem Umfang an die zentrale Instanz zur Analyse. Typischerweise sind Hunderte Sensoren an ein Edge Device angeschlossen und es werden viele Edge Devices verwendet. Aus der Analyse können sich dann zentrale oder externe Aktionen ergeben. Zentrale Aktionen werden von der Zentrale an das Edge Device weitergeleitet und von dort an die Aktoren übergeben. Die Sensordaten werden in vollem Umfang an die Zentrale übermittelt, was zu einem hohen Transfervolumen und einer Abhängigkeit von der Netzwerkverbindung führt. Die Aktionen haben eine gewisse Latenz, weil die Analyse zentral durchgeführt wird. Die Analyse kann umfassend auf den zentral gespeicherten Detaildaten durchgeführt werden. Die Anforderungen an die Hardware der Edge Devices sind gering, weshalb sich dafür auch Kleinstrechner, zum Beispiel Raspberry Pi, eignen.

Abb. 3: Nur zentrale Analyse
Variante 2: Zentrale Analyse mit lokaler Aggregation
Die zweite Architekturvariante (Abbildung 4) führt einen lokalen Aggregator im Edge Device ein, der die Daten von den Sensoren einsammelt und aggregiert an die Zentrale weiterreicht. Dies vermindert die Datenmenge, die zur Zentrale übertragen werden muss, und erlaubt außerdem eine Pufferung der Daten, falls die Netzwerkverbindung nicht zur Verfügung steht. Analysen werden aber weiterhin nur in der Zentrale durchgeführt, allerdings nur auf aggregierten Daten. Ein Zugriff auf Detaildaten ist nicht möglich. Die Anforderungen an das Edge Device nehmen zu, da eine lokale Datenhaltung und Rechenleistung zur Aggregation nötig sind.

Abb. 4: Zentrale Analyse mit lokaler Aggregation
Variante 3: Zentrale Analyse kombiniert mit lokaler Aggregation und Edge Analytics
In der dritten Architekturvariante (Abbildung 5) wird der lokale Aggregator um Analysefähigkeiten erweitert. Aktionen können damit lokal ausgelöst werden, was zu einer Unabhängigkeit vom Netzwerk führt und die Latenz automatischer Entscheidungen reduziert. Allerdings können diese nur auf lokalen Daten getroffen werden. Zentrale Aktionen sind jedoch weiterhin möglich. Die Anforderungen an das Edge Device nehmen weiter zu, weil nun auch Analysefunktionen durchgeführt werden müssen. Zudem ist ein Modell-Management nötig, das Modelle und Regeln von der Zentrale, wo sie auf dem Gesamtbestand entwickelt werden, auf die Edge Devices überträgt.

Abb. 5: Zentrale Analyse kombiniert mit lokaler Aggregation und Edge Analytics
Variante 4: Zentrale Analyse kombiniert mit lokaler Aggregation, Edge Analytics und verteilten Abfragen
Variante 2 und Variante 3 reduzieren den Datentransfer durch Aggregation. Dabei geht allerdings die Fähigkeit verloren, Auswertungen auf feingranularen Daten lokationsunabhängig durchzuführen. Dies hat auch Auswirkungen auf die Möglichkeiten der Modellbildung, weil dazu unter Umständen Aggregate nicht geeignet sind. In Architekturvariante 4 (Abbildung 6) wird daher die Fähigkeit hinzugefügt, granulare Daten, die auf den lokalen Aggregatoren liegen, abzufragen (zum Beispiel Datenvirtualisierung [Lig17]).
Selbst eine Kombination von Daten aus mehreren (oder allen) Aggregatoren ist damit möglich. Diese Variante ist somit eine Kombination der Fähigkeiten von Variante 1 mit denen von Variante 2 und 3, was wiederum zu einer Erhöhung der Anforderungen an die Edge Devices führt. Zudem ist hier auch entsprechende Software in der Zentrale zu implementieren.
Tabelle 2 gibt einen Überblick über die Architekturvarianten hinsichtlich der besprochenen Merkmale, Anforderungen und Fähigkeiten.

Abb. 6: Zentrale Analyse kombiniert mit lokaler Aggregation, Edge Analytics und verteilten Abfragen
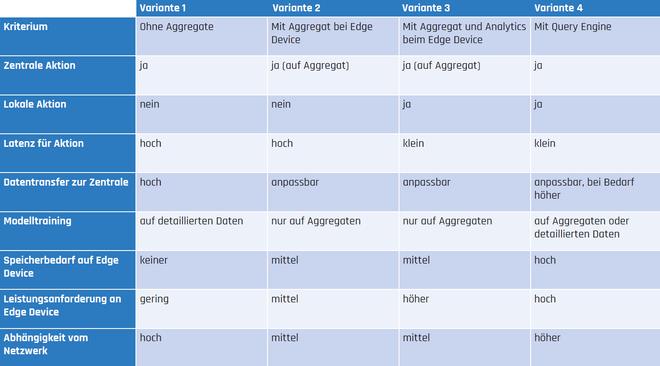
Tab. 2: Vergleich der Architekturvarianten
Zusammenfassung
Die untersuchten Architekturvarianten zeigen, dass es je nach Anforderungen und Anwendungsszenario geeignete Architekturen gibt. Die Datenmenge, die in die zentrale Instanz übertragen werden muss, kann durch lokale Aggregation reduziert werden, wobei allerdings die Fähigkeit verloren geht, auf granulare Daten zuzugreifen. Sollen jedoch Modelle über granulare Daten erstellt werden, kann eine verteilte Query Engine den Zugriff darauf wiederherstellen. Vor allem auf den Edge Devices muss die jeweils passende Technologie implementiert werden. Die eingangs geschilderten Herausforderungen für die Speicherung und Analyse von IoT-Daten lassen sich also durch die Wahl der passenden Architektur bewältigen.
Weitere Informationen
[Cha03]
Chatfield, C.: The Analysis of Time Series: An Introduction. Chapman & Hall/ CRC Texts, in: Statistical Science, 2003.
[HAP18]
Harth, N. / Anagnostopoulos, C. / Pezaros, D.: Predictive intelligence to the edge: impact on edge analytics. In: Evolving Systems 9, 2018, S. 95–118
[Jan04]
Janocha, H.: Actuators: Basics and Applications. Springer 2004
[Lig17]
Lightstone, S.: Query many data sources as one: IBM Queryplex for data analytics.
https://www.ibm.com/blogs/cloud-archive/2017/03/query-many-data-sources-oneibm-queryplex-data-analytics/, abgerufen am 21.5.2020
[SPX19]
Shi, W. / Pallis, G. / Xu, Z.: Edge Computing. Proceedings of the IEEE, Vol. 107, No. 8, Aug. 2019, S. 1474–1481
[STH18]
Siow, E. / Tiropanis, T. / Hall, W.: Analytics for the Internet of Things: A Survey. ACM Comput. Surv. 51, 4, Juli 2018, Artikel 74









