

Fundierte Entscheidungen aller Art basieren auf einer soliden Datenbasis. Dies gilt vor allem für die Finanzbranche. Zu beobachten sind in den letzten Jahren Trends, auf die es zu reagieren gilt. Datenmengen nehmen explosionsartig zu und die Datenvarianz steigt. Die Analyse traditionell gut strukturierter Daten aus beispielsweise Kernbanken-Systemen spielt neben der Auswertung unstrukturierter Daten aus beispielsweise Social-Media-Quellen und Log-Dateien eine zunehmend große Rolle.
Dem Wandel unterliegt jedoch auch die Art der durchgeführten Analysen. Stichtagsbezogene Reports haben weiterhin ihre Daseinsberechtigung. Echtzeitauswertungen – gerade auch großer Datenmengen – gewinnen zunehmend an Bedeutung. Damit verbunden stellt sich die Frage nach der Art und Weise, wie Schlussfolgerungen aus den Analysen gewonnen werden. Künstliche Intelligenz (KI) und maschinelles Lernen (ML) halten Einzug in viele Werkzeuge und gestatten die effektive Vorselektion großer Datenmengen.
Die elementare Bedeutung von Daten für die Finanzbranche
Technologie alleine bringt jedoch noch keinen Mehrwert. Der fachliche Kontext ist entscheidend. Am Beispiel des Finanzdienstleistungssektors lässt sich die Bedeutung von Daten besonders gut aufzeigen. Erfolgt doch sowohl die Herstellung als auch Vermarktung von Finanzprodukten weitestgehend digital und vor allem datengetrieben. Und dies – im wahrsten Sinne des Wortes – durch die Bank. Angefangen bei der Produktentwicklung, über Preis- und Risikokalkulationen bis hin zur Kundeninteraktion.
Manche der Daten liegen intern vor, andere hingegen müssen extern beschafft werden. Oft sind Zeitreihen wichtig, um Trends oder Zyklen erkennen zu können. Der Zugriff auf bestimmte Daten ist eingeschränkt, sodass nur bestimmte Mitarbeiter ausgewählte Daten sehen können. Die Implementierung eines entsprechenden Data-Governance-Konzepts ist daher wichtig. Betrachtet werden in stark regulierten Industrien wie der Finanzbranche Daten auch noch aus einem anderen Blickwinkel – dem der Regulatorik. Deren Einhaltung ist nicht nur für die Beschaffung, Verarbeitung und Speicherung der Daten notwendig. Regelmäßige Meldungen an die Aufsichtsbehörden sind darüber hinaus zu leisten sowie die Durchführung entsprechender Risiko- und Stresstests.
Finanzdienstleister stehen damit – wie viele andere Unternehmen – vor einer gewaltigen Aufgabe. Damit stellt sich vor allem eine zentrale Frage: Wie erfolgt eigentlich der Zugriff auf diese sehr unterschiedlich strukturierten Daten, die leicht einen Umfang erreichen, der auch größere Unternehmen vor Herausforderungen stellt? Als Lösungsansatz hat sich hier das Konzept der Data Lakes etabliert. Dieser ermöglicht die Integration unterschiedlicher Datenquellen und bietet zudem einheitliche Zugriffsschichten. Die Übersicht behält man mit einem zentralen Repository, welches Meta-Daten der unterschiedlichen Datenquellen und Attribute verwaltet.
Warum Data Lakes in der Cloud erstellen?
Daten sind für Finanzinstitute das Pendant zu Rohstoffen anderer Industrien. Gerade deshalb spielen Data Lakes für diese Industrie eine wichtige Rolle. Ein wesentliches Entscheidungskriterium für die Cloud ist vor allem deren nahezu unbegrenzte Skalierbarkeit. Das Aufsetzen des Data Lakes in der Cloud bietet sich aufgrund der teils sehr großen Datenmengen und der Notwendigkeit der flexiblen und sicheren Verarbeitung an.
Damit gehören Kapazitätsprobleme weitestgehend der Vergangenheit an. Entfallen kann damit auch die detaillierte Kapazitätsplanung, da Ressourcen in der Cloud on-demand und quasi per Knopfdruck bereitgestellt werden. Die Verfügbarkeit vieler Services zum Aufbau eines Data Lakes erfolgt durch den Cloud-Provider als „Managed Service”. Damit wird nicht nur die Infrastruktur zur Verfügung gestellt – der Cloud-Provider sorgt zudem für den sicheren Betrieb, das Management und die Skalierung der Services.
Relevante Technologien für den Aufbau eines Data Lakes
Die Suche in der Cloud nach einem großen monolithischen „Managed Data Lake Service” ist jedoch vergeblich. Cloud-Services sind eher modular aufgebaut und besitzen eine API. Die Kombination unterschiedlicher Services für verschiedene Anwendungsfälle ist dadurch möglich. Ebenso der Aufruf aus eigenen Anwendungen. Für den Aufbau eines Data Lakes sind eine Reihe von Cloud-Services (s. Abb. 1) notwendig. Diese sorgen für den Import der Daten, Datenspeicherung, Verwaltung von Zugriffsrechten und bieten Möglichkeiten zur Datenanalyse. Die Analyse der Daten kann entweder mit klassischen Business Intelligence-Werkzeugen oder aber über maschinelles Lernen erfolgen.
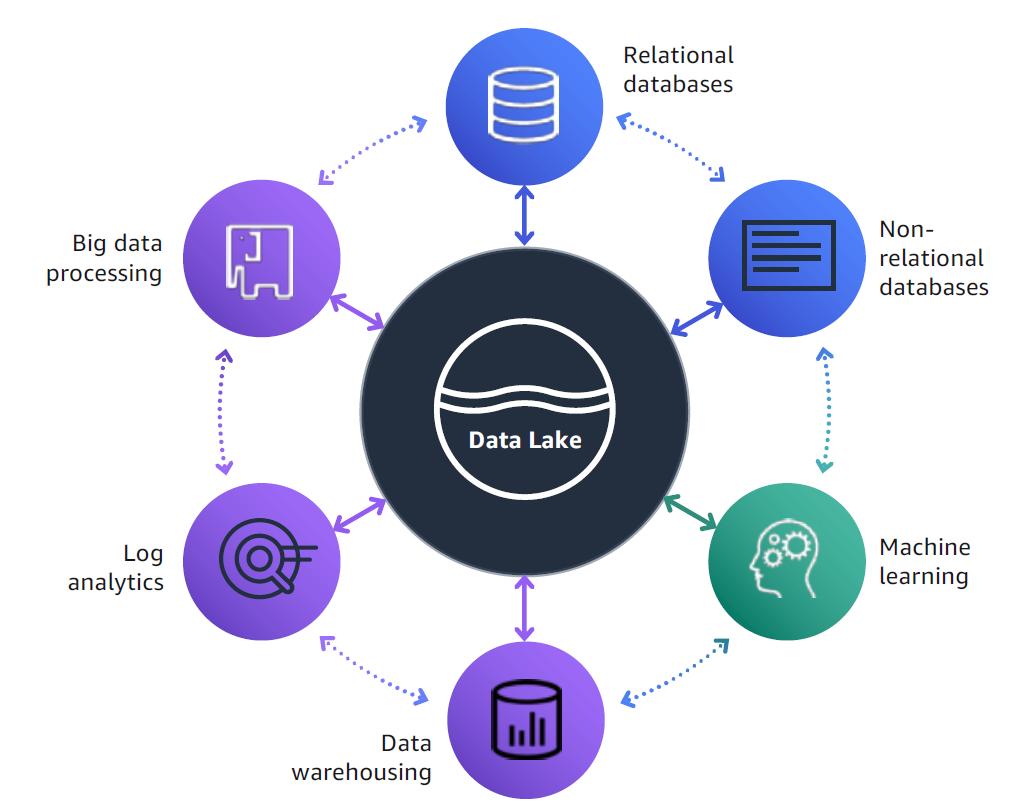
Abb. 1: Data Lakes können von unterschiedlichen Quellen gespeist werden und lassen sich vielfältig analysieren
Wodurch skalieren Cloud-Provider so gut?
Cloud-Provider verfügen über eine globale Infrastruktur, die sie im Hintergrund nutzen, um hoch skalierbare und zuverlässige Dienste anzubieten. Eigene Anwendungen beziehungsweise der eigene Data Lake läuft auf genau dieser Infrastruktur und profitiert damit von den Skaleneffekten des Cloud-Providers.
Die Umsetzung von lokalen Anforderungen (beispielsweise der zuständigen Aufsichtsbehörde) wird durch die geografische Aufteilung der globalen Infrastruktur in Regionen ermöglicht. Eine Region verfügt über mehrere Availability Zones (AZ). AZs befinden sich in räumlicher Nähe von einigen Kilometern – sind jedoch unabhängig voneinander in Bezug auf Strom- und Wasserversorgung. Eine AZ ist eine logische Gruppierung mehrerer Rechenzentren (s. Abb. 2). Anwendungen laufen innerhalb einer Region und einer oder mehreren AZs. Die Verteilung der Anwendung auf mehrere AZs ist jedoch klare Empfehlung und Best Practice moderner Architekturen. Gleiches gilt für Daten. Diese werden – je nach verwendetem Service – unter Umständen auf unterschiedlichen Servern in verschiedenen Rechenzentren gespeichert.
Speicherplatz – Grundlage eines jeden Data Lakes
Wesentliche Grundlage eines jeden Data Lakes ist die Bereitstellung von Speicherplatz. Die Grenzen des Machbaren sind in On-premises-Umgebungen in Bezug auf Verfügbarkeit, Größe und Skalierung schnell erreicht. Hier spielen Cloud-basierte Systeme ihre Trümpfe aus. In der AWS Cloud beispielsweise fällt die Wahl schnell auf den „Amazon Simple Storage Service” – besser bekannt als „Amazon S3”. S3 ist ein Objektspeicher und bietet praktisch unbegrenzte Skalierbarkeit. Speichern lassen sich in S3 Objekte bis maximal 5 Terabyte. Über eine Webservices-Schnittstelle ist der Zugriff auf diese Objekte jederzeit auch von anderen Services möglich.
Verschiedene Eigenschaften machen S3 interessant für den Aufbau eines Data Lakes. So ist die Verfügbarkeit von S3 auf 99,99 Prozent und die Haltbarkeit der gespeicherten Objekte auf 99,999999999 Prozent (elf 9en) ausgelegt. Würden beispielsweise 10.000.000 Objekte in S3 gespeichert werden, so kann im Durchschnitt alle 10.000 Jahre mit einem Verlust eines einzelnen Objekts gerechnet werden. Die Erreichung dieser hohen Haltbarkeit wird durch die redundante Speicherung von Objekten auf mehreren Servern in mindestens drei AZs innerhalb einer AWS-Region ermöglicht. Erst dann wird eine Erfolgsmeldung an die Anwendung zurückgegeben.
Die Speicherung von Objekten mit unterschiedlichen Anforderungen an Haltbarkeit, Zugriffszeiten und Kosten wird durch Zuordnung einer Speicherklasse (s. Abb. 3) möglich. Speicherklassen, die Objekte lediglich in einer AZ speichern (beispielsweise die Speicherklasse S3 One Zone-IA), sorgen trotzdem noch für die redundante Verteilung auf mehrere Server. Die schnelle Erkennung und Reparatur bei gleichzeitigem Ausfall mehrerer Server ist damit möglich. Die Behebung von Inkonsistenzen in der Datenintegrität erfolgt über regelmäßigen Abgleich von Prüfsummen. Um Beschädigung von Datenpaketen im Netzwerk festzustellen, werden auch hier Prüfsummen für den gesamten Netzwerkverkehr verwendet.
Die automatisierte Zuordnung von Objekten zu einer anderen Speicherklasse erfolgt über die Definition von Regeln. Beispielsweise lassen sich Objekte, die älter als 30 Tage sind, automatisch in die Speicherklasse „Infrequent Access” und Objekte, die älter als 365 Tage sind, in die Klasse „Glacier Deep Archive” verschieben. In puncto Sicherheit bringt S3 die notwendigen Mechanismen mit, auf denen Data Lake-Technologien aufsetzen können. So kann beispielsweise der Zugriff auf bestimmte Objekte nur für bestimmte Personen, Gruppen oder andere Ressourcen gestattet werden. Die Speicherung der Daten in S3 kann verschlüsselt erfolgen, genauso wie die Übertragung zu oder von S3. Damit ist S3 eine ausgezeichnete Basis, um Daten fast jeder Art mit hoher Haltbarkeit zu speichern und den Zugriff auf diese Daten zu verwalten.
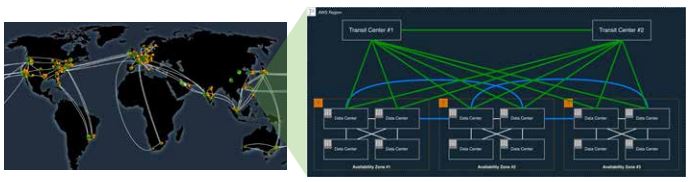
Abb. 2: Hoch skalierbare und zuverlässige Dienste werden über die globale Infrastruktur des Cloud-Providers zur Verfügung gestellt

Abb. 3: S3 bietet verschiedene Speicherklassen, die über unterschiedliche Eigenschaften verfügen
Datenimporte – Rohstoff des Data Lakes
Zum Laden der Daten in den Data Lake bietet sich zum Beispiel AWS Glue an. Glue ist ein Datenintegrationsdienst, mit dem Daten aus unterschiedlichen Quellen importiert werden können (s. Abb. 4). Glue ist ein managed Service – den Betrieb übernimmt der Cloud-Provider. Nutzer können sich somit auf die Konfiguration der Datenquellen sowie den Datenimport konzentrieren. Glue verfügt über Funktionen, die typischerweise Weise in ETL (Extract, Transform, Load)-Werkzeugen zu finden sind. Um den Import von Daten so einfach wie möglich zu gestalten, stellt Glue neben einer programmatischen Schnittstelle eine grafische Benutzeroberfläche (AWS Glue Studio) zur Verfügung. Datenimporte und Transformationen lassen sich damit visuell modellieren und ausführen.
Erkannte Schemata können in einem Datenkatalog – dem AWS Glue Data Catalog – abgelegt werden. Aufgabe des Datenkatalogs ist die Dokumentation von Metadaten und Ablage in einem einheitlichen Repository. Die Nutzung der Metadaten erfolgt beispielsweise über ETL-Strecken in Abfragen und Transformationen. Die Befüllung des Datenkatalogs erfolgt über sogenannte Crawler. Diese erkennen automatisch neue Daten und extrahieren die Schemadefinitionen beziehungsweise erkennen Änderungen bestehender Schemata.
Die eigentliche Verbindung zur Datenquelle erfolgt über die Definition einer Glue Connection. Je nach Typ der Datenquelle (z. B. Datenbank oder S3) werden spezifische Zugriffsparameter gekapselt. Verantwortlich für das Lesen der Daten ist ein sogenannter Glue Classifier. Erkennt dieser das Datenformat (z. B. JSON oder XML), wird ein Schema erzeugt. Eine Reihe integrierter Classifier sind bereits verfügbar. Die Erstellung benutzerdefinierter Classifier ist möglich.
Einheitliches Governance-Modell – Vertrauen ist gut, Kontrolle ist besser
Die Bereitstellung eines wirkungsvollen Governance-Modells ist eine der größten Herausforderungen beim Aufbau einer modernen Data Lake-Architektur. Die Autorisierung, Verwaltung und Prüfung von Zugriffsrechten auf verschiedene Datenquellen und Systeme eines Unternehmens ist komplex, zeitaufwendig und fehleranfällig. Die Verwaltung von Zugriffsrechten in einem zentralen Governance-Modell vereinfacht der Einsatz von AWS Lake Formation (s. Abb. 5). Lake Formation setzt auf AWS Glue auf und nutzt insbesondere den Glue-Datenkatalog, darüber hinaus auch Glue-Funktionen wie Jobs, Crawler und Workflows. Das automatisierte Laden von Daten aus typischen Datenquellen kann über Workflows erfolgen. Für Datenbanken und Log-Dateien stellt Lake Formation entsprechende Blueprints bereit.
Berechtigungskonzepte zur Festlegung von Datenzugriffen sind naturgemäß komplex, deren Umsetzung oft herausfordernd. Die einfache Realisierung typischer Governance-Anforderungen eines Data Lakes war deshalb ein wichtiges Entwurfsziel von Lake Formation. So gestattet Lake Formation beispielsweise Benutzern den generellen Zugriff auf bestimmte Tabellen – einzelne Spalten jedoch lassen sich ausblenden. Dies ist oft notwendig, falls diese personenbezogene Daten enthalten. Je nach Anwendungsfall ist dies nicht immer ausreichend. Erforderlich ist in manchen Fällen eine Zugriffsbeschränkung auf Zeilenebene. Beispielsweise wenn Benutzer lediglich Daten aus ihrem Gebiet oder Bereich sehen dürfen. Die Zeilen-basierten Filterregeln (zur Drucklegung in Preview) von Lake Formation ermöglichen genau dies.
In Abfragen sollen die ausgeblendeten Inhalte unter Umständen jedoch weiterhin verwendet werden. Beispielsweise wenn anhand der Sozialversicherungsnummer zwei Kundenobjekte verglichen werden sollen. Für diesen Anwendungsfall ersetzt Lake Formation die zu schützenden Daten mit einem generierten Token (zur Drucklegung in Preview), der in Abfragen verglichen werden kann. Mit diesen Board-Werkzeugen ausgestattet, lassen sich für verschiedene Benutzergruppen unterschiedliche Zugriffsregeln definieren. Eine Kopie der Daten ist – im Gegensatz zu vielen On-premises-Lösungen – jedoch nicht mehr notwendig.
Die Protokollierung der Zugriffe über Lake Formation wird in einem Audit Trail festgeschrieben. Insbesondere in regulierten Industrien wie der Finanzbranche kann dadurch ein entsprechender Nachweis gegenüber der Aufsichtsbehörde erfolgen.

Abb. 4: Über Glue Crawler werden Daten dem Datenkatalog bekannt gemacht
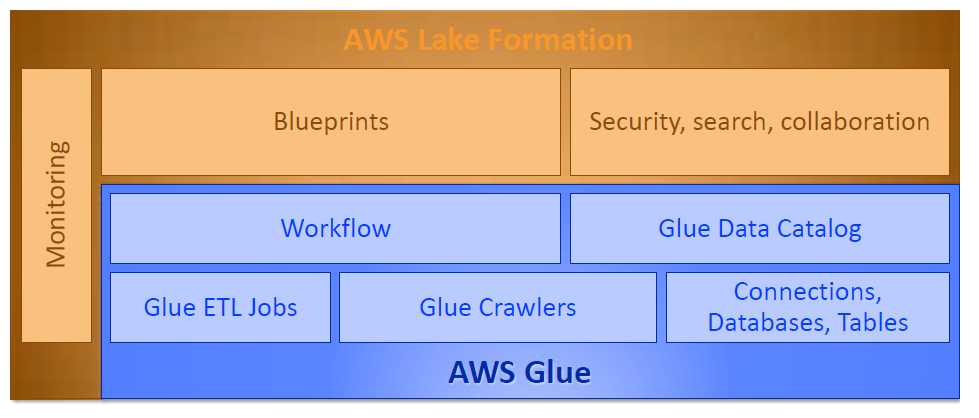
Abb. 5: Lake Formation setzt auf AWS Glue auf und bietet weitere Governance-Funktionen
Infrastructure-as-Code
Mithilfe der bisher beschriebenen Konzepte lässt sich ein Data Lake zum Beispiel über die AWS Console – also der Weboberfläche zur Erzeugung und Verwaltung von AWS Cloud-Ressourcen – konfigurieren und aufbauen. Zur Erprobung der Technologie ist dies ein sinnvoller Ansatz, da der Benutzer mithilfe der grafischen Oberfläche durch die notwendigen Konfigurationsschritte geführt wird. Wenig geeignet ist dieser Ansatz für die professionelle Entwicklung im Team oder sogar für den Aufbau einer Produktionsumgebung. Zu groß ist das Risiko einer fehlerhaften Konfiguration.
Ressourcen werden deshalb idealerweise per Skript oder als Anwendung definiert, was bei Ausführung die entsprechenden Ressourcen in der Cloud erzeugt, aktualisiert oder löscht. Bezeichnet wird dieses Konzept als „Infrastructure-as-Code (IaC)”. Zielsetzung von IaC ist die automatisierte Bereitstellung und Aktualisierung von Systemen und deren Konfiguration in einer konsistenten und wiederholbaren Art und Weise. IaC basiert auf Praktiken der Softwareentwicklung. Die Nutzung gängiger Werkzeuge zur Versionsverwaltung sowie automatisierter Deployment-Pipelines ist damit möglich. Dadurch lassen sich inkrementelle Änderungen umsetzen und erprobte Muster wiederverwenden. Governance-Anforderungen lassen sich mit IaC besser umsetzen, da Unternehmensanforderungen unabhängig von den Projektanforderungen definiert und über die Deployment-Pipeline bereitgestellt werden können.
Die Beschreibung von AWS-Infrastrukturkomponenten erfolgt beispielsweise über AWS Cloud Formation oder Terraform. Entwicklern steht zudem das Open-Source-Framework AWS Cloud Development Kit (AWS CDK) mit Unterstützung von unterschiedlichen Sprachen zur Verfügung (s. Abb. 6). Während Cloud Formation und Terraform ihre eigene Syntax zur Beschreibung der Infrastrukturkomponenten mitbringen, kann mithilfe des CDK deren Beschreibung auf Basis von beispielsweise Java oder TypeScript erfolgen. Der große Vorteil dabei: Anwendungslogik und Infrastrukturkomponenten lassen sich über die gleiche Programmiersprache und das gleiche Programmiermodell beschreiben. Das Erlernen neuer Werkzeuge ist damit nicht mehr zwingend notwendig und ein DevOps-Modell lässt sich einfacher implementieren. Neben Java unterstützt das CDK noch weitere Programmiersprachen wie beispielsweise TypeScript, JavaScript, Python und C#.
Doch wie funktioniert eine CDK-basierende Anwendung genau? Im Wesentlichen so wie andere Java-Anwendungen. Das CDK stellt einige neue Bibliotheken und Klassen bereit, die in die eigenen Java-Anwendungen eingebunden werden. Voraussetzungen für die Nutzung des CDK mit Java ist ein installiertes JDK in der Version 8 oder höher sowie die Installation des CDK selbst über:
npm install -g aws-cdk
oder – abhängig vom Betriebssystem – einem entsprechenden Package Manager. Ein erstes Gerüst einer CDK-Anwendung kann auf der Kommandozeile über folgenden Befehl erzeugt werden:
cdk init beispiel-app —language java
Per init-Befehl wird ein einfaches Gerüst einer CDK-Java-Anwendung erzeugt. Listing 1 zeigt das Gerüst eines Stacks, welcher über eine Java-App (s. Listing 2) instantiiert wird.
Eine CDK-App definiert einen oder mehrere Stacks. Stacks wiederum enthalten sogenannte Constructs. Constructs sind wiederverwendbare Komponenten und repräsentieren Infrastrukturkomponenten, die zum Beispiel zum Aufbau eines Data Lakes notwendig sind. Also zum Beispiel ein Verzeichnis in S3 – ein sogenanntes Bucket – oder einen Glue Crawler. In Listing 3 wird der entsprechende Beispielcode für die Erzeugung eines S3 Buckets exemplarisch gezeigt.
Mehrere Constructs können auch in einem neuen Construct zusammengefasst werden, sodass Muster oder Workflows sich abbilden lassen. Apps, Stacks und auch Constructs sind Teil des Java-Typensystems und lassen sich dementsprechend nutzen. Damit können beispielsweise Vererbungsmechanismen angewandt werden. Die Erstellung unternehmensweiter Frameworks mit projekt-spezifische Ergänzungen ist damit auf elegante Art und Weise möglich. Für weitestgehend alle Services existieren bereits definierte Constructs. Diese werden in der AWS Construct Library bereitgestellt.
Das Deployment der Ressourcen in der Cloud erfolgt über den CDK-deploy-Befehl, der den definierten Stack in dem Standardkonto des Benutzers erzeugt:
cdk deploy
Unter der Haube erzeugt das CDK Cloud Formation Code. Über den CDK-synth-Befehl kann dieser auf der Konsole ausgegeben werden:
cdk synth
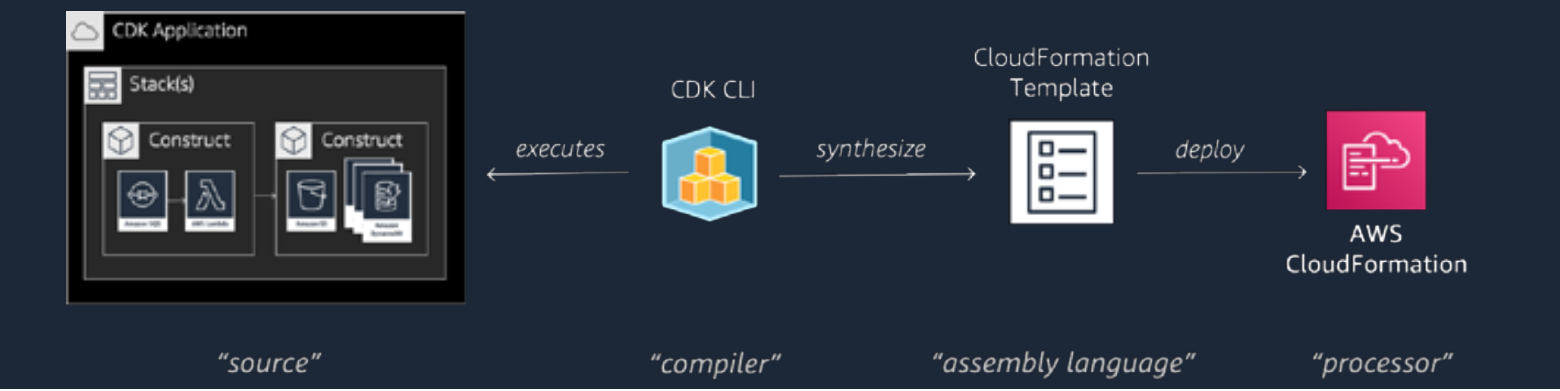
Abb. 6: Infrastrukturkomponenten lassen sich mithilfe des CDK in Java beschreiben und in der Cloud erzeugen oder aktualisieren
Zusammenfassung und Ausblick
Eine Vielzahl von Architekturentscheidungen muss für den erfolgreichen Aufbau sowie Betrieb eines Data Lakes getroffen werden. Dazu gehören elementare Fragestellungen hinsichtlich der zentralen Infrastruktur- und Betriebsumgebung, der Speichertechnologien, der Realisierung von Governance-Modellen bis hin zur Automatisierung wesentlicher Abläufe. Die reibungslose Zusammenarbeit der ausgewählten Technologien ist dabei ein entscheidender Erfolgsfaktor, um fachliche Anforderungen schnell und flexibel umsetzen zu können. Durch die Verfügbarkeit skalierbarer, hoch-performanter Infrastrukturen sowie leistungsfähiger Services bieten sich Cloud-Technologien zur Umsetzung eines Data Lakes an.
Mithilfe von Werkzeugen wie dem CDK sowie der entsprechenden CDK Constructs lässt sich ein Data Lake über Java definieren und es lassen sich die entsprechenden Ressourcen in der Cloud erzeugen. Dabei können die gleichen Entwicklungswerkzeuge genutzt werden, die typischerweise für den Bau und das Deployment von Unternehmensanwendungen verwendet werden. Über das CDK lassen sich spezifischen Vorteile von Java wie beispielsweise Vererbungsmechanismen nutzen, um Frameworks zu entwickeln, die unternehmensweite Governance- und Security-Regeln implementieren.
package com.myorg;
import software.amazon.awscdk.core.Construct;
import software.amazon.awscdk.core.Stack;
import software.amazon.awscdk.core.StackProps;
import software.amazon.awscdk.services.s3.Bucket;
import software.amazon.awscdk.services.lakeformation.
CfnDataLakeSettings;
import software.amazon.awscdk.services.lakeformation.CfnResource;
import software.amazon.awscdk.services.glue.*;
public class DataLakeJavaStack extends Stack {
public DataLakeJavaStack(final Construct scope, final String id) {
this(scope, id, props: null);
}
public DataLakeJavaStack(final Construct scope, final String id,
final StackProps props) {
super(scope, id, props);
// The code that defines your stack goes here
Bucket.Builder.create(scope: this, id: "MyFirstBucket")
.versioned(true).build();
}
}package com.myorg;
import software.amazon.awscdk.core.App;
import java.util.Arrays;
public class DataLakeJavaApp {
public static void main(final String[] args) {
App app = new App();
new DataLakeJavaStack(app, id: "DataLakeJavaStack");
app.synth();
}
}package com.myorg;
import software.amazon.awscdk.core.*;
import software.amazon.awscdk.services.s3.Bucket;
public class S3BucketSample extends Stack {
public S3BucketSample(final Construct scope, final String id) {
this(scope, id, props: null);
}
public S3BucketSample(final Construct scope, final String id,
final StackProps props) {
super(scope, id, props);
Bucket.Builder.create(scope: this, id: "MyFirstBucket")
.versioned(true).build();
}
}








