

Sicher: Es gab auch schon vor dem agilen Manifest automatisierte Tests. Doch wo stünden wir ohne den Grundgedanken der kontinuierlichen Integration (continuous integration), wenn nicht gar der kontinuierlichen Bereitstellung (continuous deployment)? Was täten wir ohne die Tools und Frameworks, die im Zusammenhang mit XP & Co. das Licht der Welt erblickt haben? Generell gilt, dass die Qualitätssicherung im agilen Umfeld einen hohen Stellenwert hat.
Dennoch beobachten wir ein Problem, welches mit dem Verlust der Teststufen aus dem V-Modell zusammenhängt. Durch den starken Fokus auf automatisierte Tests drohen System- und Nutzerakzeptanztests in den Hintergrund zu rücken. Obgleich Acceptance Testing zu den agilen Praktiken zählt, ersetzen die Akzeptanztests im agilen Umfeld nur bedingt einen umfassenden Systemtest oder eine übergreifende Validierung. In der Regel orientieren sie sich nämlich an den User-Storys, die wiederum so kleinteilig sein müssen, dass sie in den Sprint passen. Der Fokus ist damit zwangsläufig begrenzt. Auch das Behavior-Driven Development (BDD) schafft das Problem nicht wirklich aus dem Weg. Zwar orientiert sich BDD an Szenarien, doch die gerne verwendete Syntax Given-When-Then schränkt uns im Test komplexerer Abläufe stark ein.
Wirklich Abhilfe schafft der explorative Test. Leider wissen wir nach einer explorativen Test-Session in der Regel nicht, wie gut die Abdeckung der Anforderungen ist (die ja möglicherweise auch nie formalisiert wurden). Außerdem lassen sich explorative Tests mit herkömmlichen Methoden nicht so ohne Weiteres automatisieren.
User Storys vs. Use Cases
Eine Lösung besteht darin, auf die altbewährten Anwendungsfälle zurückzugreifen.
Alistair Cockburn hat es in seinem Pamphlet „Why I Still Use Use Cases” wunderbar auf den Punkt gebracht [Cock]. User-Storys dienen der Projektsteuerung, liefern jedoch keinen Kontext und damit auch keine Grundlage für die Bewertung, ob eine Lösung den Bedarf der Anwender vollständig abdeckt oder nicht. Anwendungsfälle hingegen sind eine ultrakurze Zusammenfassung des Projektumfangs. Darüber hinaus liefern die dazugehörigen Szenarien Informationen über Abläufe, die meist mehrere User-Storys abdecken. Dabei tauchen Fragen auf wie: „… und was passiert, wenn XY nicht gegeben ist?“. Je früher wir solche Fragen stellen, desto seltener übersehen wir Definitionslücken.
In der Praxis arbeiten oft mehrere Teams zusammen an verschiedenen Komponenten des Produkts, was zusätzlich das Blickfeld einschränkt. Es hat sich daher bewährt, den Teams einen oder mehrere dedizierte Systemtester beizustellen. Diese Systemtester stehen nun vor der Herausforderung, mit dem rasanten Tempo der agilen Entwicklung Schritt zu halten. Denn wenn sich User-Storys und deren Umsetzung im Zwei-Wochen-Rhythmus ändern können, wird es zunehmend schwerer, die bereits erstellten Testfälle anzupassen und obendrein neue zu schreiben. Wie schön wäre es, wenn wir die Testfallerstellung und -pflege automatisieren und so ihre Implementierung beschleunigen könnten!
Hier kommt die Modellierung ins Spiel, die als Grundlage der automatischen Testgenerierung dienen kann. Betrachten wir ein (halb) fiktives Beispiel. Es handelt sich um ein bildverarbeitendes System aus einem realen Projekt, dessen Beschreibung allerdings deutlich verfälscht wurde:
Die Bilder können auf verschiedenen Wegen an das System geschickt werden, welches dann per Mustererkennung Schlüsse zieht, sofern die Bildqualität dies zulässt. Die Ergebnisse können in einer grafischen Oberfläche (UI) angezeigt und dort vom Anwender akzeptiert oder verworfen werden. Nur akzeptierte Ergebnisse wandern in das Bildarchiv. Alternativ kann das System so konfiguriert werden, dass die Ergebnisse ohne vorherige Sichtung im Archiv abgelegt werden. Fehlerhafte Ergebnisse werden weder angezeigt noch archiviert.
Abbildung 1 zeigt den Standard-Arbeitsablauf, wie er während des ersten (oder der ersten) Sprints erstellt werden kann. Die Unterdiagramme (in der Abbildung als Brille dargestellt) müssen zunächst noch nicht ausformuliert sein. Genau genommen können sie es auch aufgrund der agilen Vorgehensweise noch gar nicht sein, da die Details erst mit der Zeit festgelegt werden.
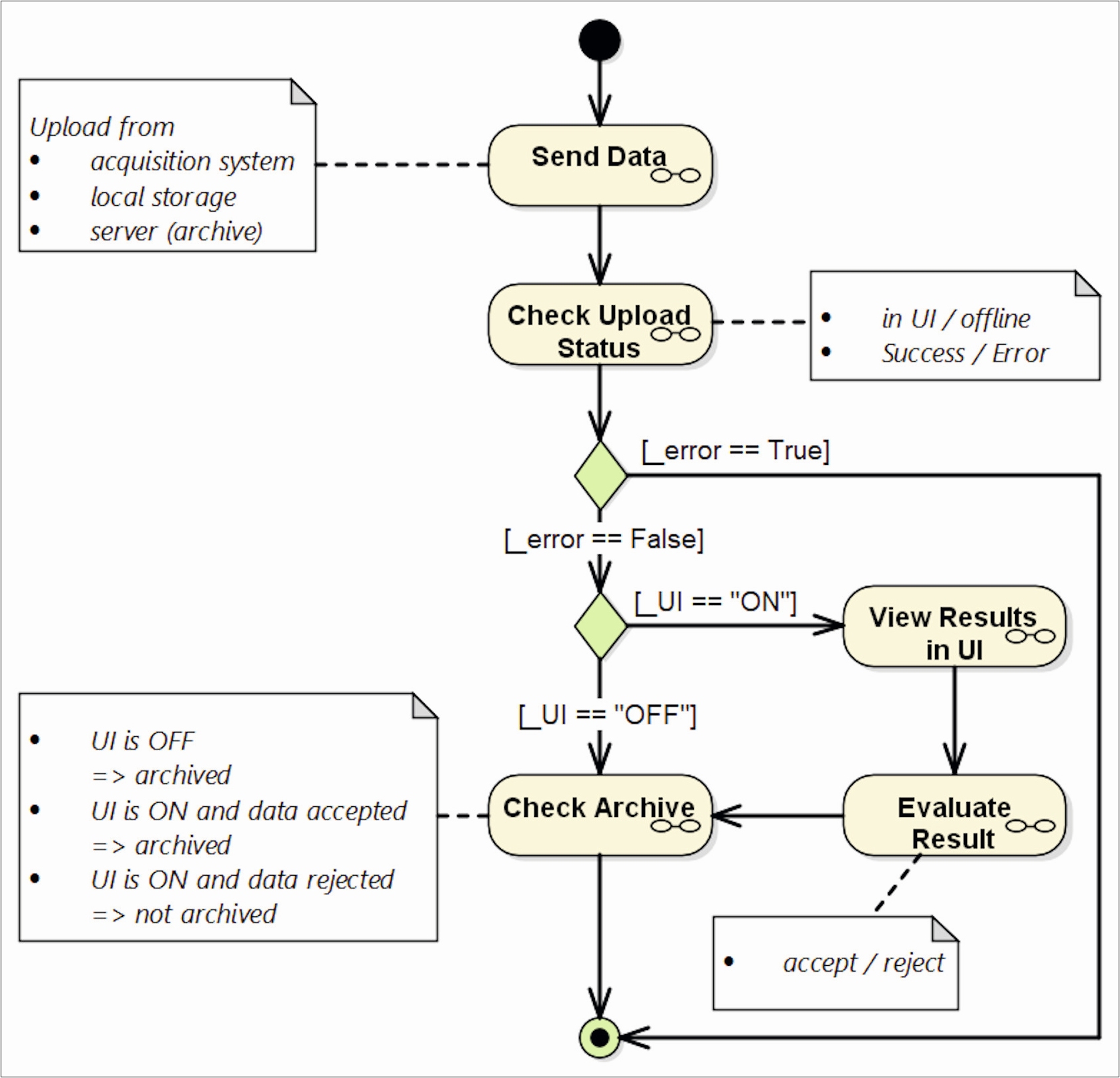
Abb. 1: Standard-Workflow eines (fiktiven) Bildverarbeitungssystems
Wir können das Modell nun nehmen und eben diese Fragen mit dem Product Owner (PO) klären. Welche Möglichkeiten gibt es, Daten an das System zu senden? Wie verhält sich das System, wenn die Anzeige der Bilder deaktiviert ist (UI ON/OFF)? Wann, wie und wo werden die Bilder archiviert? In den Notizfeldern kann man erkennen, welche Äquivalenzklassen in den Unterdiagrammen bislang schon behandelt werden. Diese Unterdiagramme werden Sprint für Sprint inkrementell erstellt und verfeinert, wobei die Änderungen der aktuellen Sprint-Planung folgen.
Abbildung 1 zeigt das Hauptszenario, welches sich direkt aus den User-Storys ergibt. Interessanter sind allerdings die Alternativund Fehlerszenarien. Hier steckt die eigentliche Arbeit, aber auch der größte Mehrwert. Denn genau diese Szenarien sind es häufig, die im Sprint zu Verzögerung aufgrund von Klärungsbedarf und am Ende zu bösen Überraschungen führen.
Workflows vs. BDD
Was hat das nun mit (automatisierten) Tests zu tun? Die Visualisierung der gewünschten beziehungsweise vorhersehbaren Abläufe ist für sich genommen schon eine qualitätssichernde Maßnahme, die der Philosophie des Test-first-Ansatzes folgt. Im Modell werden die relevanten Workflows der Anwender im Zusammenhang sichtbar. Oft tauchen schon während der Erstellung eines Workflow-Modells Fragen auf. In vielen Fällen schafft die daraufhin entbrennende Diskussion erst die erforderliche Klarheit zwischen den beteiligten Gruppen.
Darüber hinaus liefert die Workflow-Modellierung die Grundlage für Szenario-basierte Tests. Jeder Pfad durch das Modell ist ein potenzieller Testfall. Es obliegt dem Tester, eine sinnvolle Auswahl zu treffen. Was „sinnvoll“ ist, hängt stark vom angestrebten Ziel ab:
- Für einen Regressionstest reicht es möglicherweise, einen für die vorgesehene Nutzung besonders repräsentativen Pfad auszuwählen.
- Wenn etwas geändert wurde, sind alle Pfade sinnvoll, die durch den geänderten Teil des Modells verlaufen.
- Für eine volle Abdeckung der Äquivalenzklassen sollte die Summe aller Pfade so gewählt werden, dass jeder Knoten wenigstens einmal durchlaufen wird.
- Um sich weiter abzusichern, können die Pfade so gewählt werden, dass jeder Pfeil wenigstens einmal durchlaufen wird. (Dies entspricht der Entscheidungsabdeckung, die wir aus dem Unittest kennen.)
- Bei kritischen Abläufen kann die Kombinatorik weiter erhöht werden.
Vermutlich ruft jetzt der erste Kritiker: „Zuviel Aufwand. Viel zu viel manuelle Arbeit. Wir machen lieber BDD.“ Schauen wir uns daher die Alternative an.
Abbildung 2 zeigt ein typisches BDD-Szenario in Gherkin-Syntax, welches sich auf die Anzeige des Upload-Status konzentriert. Um diesen Punkt vollständig abzutesten, sind insgesamt vier BDD-Szenarien erforderlich (UI ON/OFF kombiniert mit Success/Error). Weitere Szenarien sind nötig, um die drei Bildquellen, die zwei Möglichkeiten der Bewertung in der UI (accept/reject) und schließlich die Archivierung zu prüfen. Wir erhalten somit 12 Szenarien, von denen viele im Given enthalten, was andere im Then prüfen.

Abb. 2: Beispiel für BDD-Szenario
Hand aufs Herz: Haben Sie auf Abbildung 1 geschaut, um nachzuvollziehen, wie die 12 BDD-Testfälle zustande kommen? Konnten Sie die Überlegungen nachvollziehen? Wie wäre es Ihnen ergangen, wenn Sie nur die textuelle Systembeschreibung weiter oben zur Verfügung gehabt hätten? Das Modell verschafft den Testern einen Überblick, der allein mit den BDD-Testskripten nicht in gleicher Weise gegeben wäre. Zudem lassen sich Abdeckungskriterien definieren und damit die Qualität der Testabdeckung messen beziehungsweise belegen. Somit ist die Visualisierung bereits in Kombination mit BDD ein Schritt in die richtige Richtung.
Im Workflowtest gehen wir allerdings noch weiter und testen statt der BDD-Szenarien ganze Arbeitsabläufe. Hinter jeder Aktivität in Abbildung 1 verbergen sich ein oder mehrere detaillierte manuelle oder automatisierte Testschritte. Im einfachsten Fall wird jeder Knoten im Modell mit einem Aktionswort (action word) verknüpft, ganz analog zu BDD mit Gherkin, wo jede Zeile einem Aktionswort entspricht. Diese werden gemäß dem ausgewählten Pfad durch das Modell „eingesammelt“ und zu automatisierbaren Testfällen kombiniert.
Die Summe der Pfade bestimmt die Testabdeckung. Werden Teile des Modells nicht erreicht, so entspricht dies einer Testlücke, die es zu bewerten gilt.
Wie bereits erwähnt, entwickeln wir das Workflow-Modell inkrementell. Es kommen also in jedem Sprint Pfade hinzu und bestehende Pfade ändern sich. Dann kommt der Clou, wir erzeugen die Testfälle automatisiert mit einem Generator (Mehr Informationen zum verwendeten Testfallgenerator finden Sie unter [MBTsuite]). So können wir in jedem Sprint einen Satz an Testfällen generieren, der minimal notwendig ist, um die bereits implementierten User-Storys in einer Art End-to-End-Test abzuprüfen. Anstatt inkrementell immer mehr Testfälle anzuhäufen, variieren beziehungsweise erweitern wir die Tests Sprint für Sprint und erhalten doch immer die bestmögliche und durchgängige Abdeckung. Da die Erstellung neuer Testfälle auf Knopfdruck erfolgt, können wir uns voll auf die Modellierung und damit auf die Klärung der Erwartungshaltung unseres PO beziehungsweise der Anwender konzentrieren.
Fazit
Die Modellierung in Kombination mit der Testfallgenerierung hilft uns, über den gesamten Zeitraum der agilen Entwicklung den Überblick über das System als Ganzes und seine Nutzung zu behalten, die Systemtestfälle schnell anzupassen beziehungsweise zu erweitern, Testfälle automatisiert zu generieren und Sprint für Sprint neue Szenarien automatisiert zu testen. Dies ist der Grund, weshalb wir von „entwicklungsbegleitender Validierung“ sprechen.
Weitere Informationen
[Coc] A. Cockburn, Why I Still Use Use Cases, siehe:
http://www.inf.puc-rio.br/~ivan/INF1013/NotasAula/Why%20I%20Still%20Use%20Use%20Cases.pdf (Die Original-Webseite von Alistair Cockburn ist zurzeit „under construction“)
[MBTsuite]
www.mbtsuite.com









