

Warum überhaupt Java?
Wenn man über Machine-Learning (ML) spricht, fällt einem nicht als erstes Java ein, sondern eher Python. Warum also Java? Java gehört zu den am häufigsten verwendeten Programmiersprachen der Welt [Tiobe]. Viele große Organisation besitzen eine hohe Anzahl von Applikationen, die auf der Java Virtual Machine (JVM) basieren, sodass die Integration von Lösungen in diese Welt natürlich auch ein wichtiges Thema darstellt.
Auch ein Großteil der Open-Source-Big-Data-Lösungen wird in Java entwickelt, wie Apache Spark, Apache Hadoop, Apache Kafka, ElasticSearch und Apache Lucene. Und wichtige Voraussetzungen für ML sind große Datenmengen und das Vorliegen dieser in einer hohen Qualität. Durch Lösungen wie Apache Spark lassen sich aufwendige Datentransformation einfach skalieren. Aber auch in der ML-Welt haben sich zum Beispiel H2O und deeplearning4J bereits einen Namen gemacht.
Prozess-Engines als Dirigent
Viele Unternehmen nutzen Prozess-Engines, wie die wahrscheinlich populärste (Java-basierte) Open-Source-Prozess-Engine Camunda [Camunda], um ihre wichtigsten Geschäftsprozesse möglichst effizient zu gestalten. Die Prozess-Engine stellt dabei die zentrale Komponente dar, wenn es um die Steuerung der Prozesse sowie die zentrale Datenquelle für prozessrelevante Daten geht. Das liegt daran, dass die modellierten Geschäftsprozesse üblicherweise sämtliche für die Prozessausführung relevanten Informationen protokollieren (ggfs. nach Aktivierung der Protokollierung).
Der in Abbildung 1 dargestellte, stark vereinfachte Beispielprozess, modelliert in BPMN 2.0 [BPMN2], zeigt eine typische Konstellation, wie sie häufig in Unternehmensprozessen zu finden ist. Der Prozess startet mit dem Ereignis, dass eine Rechnung zur Reparatur eines Schadens zur Prüfung eingereicht wurde. Diese Rechnung enthält zum Beispiel den Rechnungsbetrag, das reparierte Fahrzeug, aber auch die ausführende Werkstatt und den Rechnungsempfänger. In der anschließenden Serviceaktivität „Daten zum Versicherten sammeln“ werden zusätzliche Informationen zur versicherten Person gesammelt, wie der Versicherungsstatus, frühere Versicherungsfälle usw.
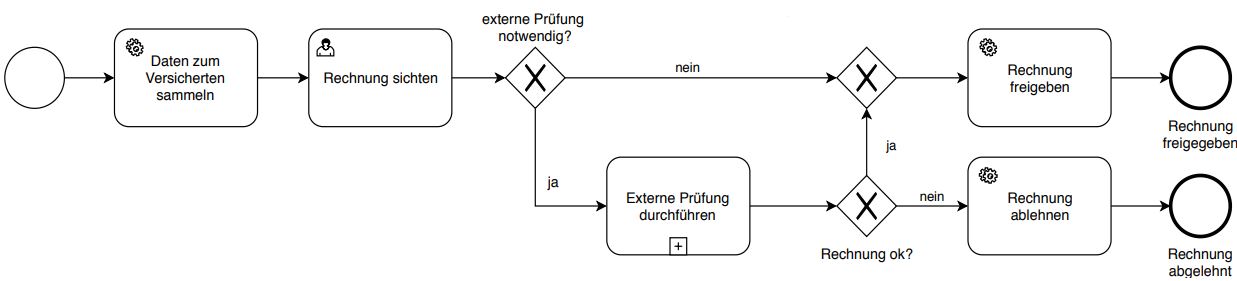
Abb. 1: BPMN2.0 - Beispielprozess
In der Benutzeraktivität „Rechnung sichten“ wird dann auf Basis der vorliegenden Informationen entschieden, ob eine externe Prüfung für die vorliegende Rechnung nötig ist oder ob diese zur Auszahlung freigegeben werden kann. Die Prüfung durch den Sachbearbeiter entscheidet damit über den weiteren Prozessverlauf, anhand der im Prozess vorliegenden Informationen.
Ein Fall für Machine-Learning
Der oben skizzierte Fall stellt eine in Geschäftsprozessen häufig zu findende Konstellation dar, in der Einsatz von ML lohnen kann. Die gesammelten Daten von vergangenen Prozessausführungen enthalten sowohl die Informationen, welche der manuellen Entscheidung zur Notwendigkeit einer externen Prüfung zugrunde lagen (die potenziellen Features), als auch die Entscheidung (die Zielvariable) selbst. Sie liegen jeweils als Prozessvariablen vor. Durch die Aufbereitung dieser Daten und das Anlernen eines ML-Modells kann eine KI-gestützte Prozessoptimierung erfolgen, so sich denn das Modell als nutzbar erweist. Eine manuelle Entscheidungsaktivität kann potenziell durch eine (teil-)automatisierte Aktivität ersetzt werden.
Neben der Unterstützung einer konkreten Aktivität in einem Prozess können ML-Modelle auch an anderer Stelle zur Prozessoptimierung beitragen. So können sie zum Beispiel auch zur Laufzeitprognose von ganzen Prozessinstanzen genutzt werden. In diesem Fall schaut man für das Anlernen von ML-Modellen auf abgeschlossene Prozessinstanzen, konkret auf deren Endzustand, wogegen im Fall der Optimierung der manuellen Aktivität der Zustand zu einem bestimmten Punkt während der Laufzeit von Interesse ist.
Zwei verschiedene Sichten auf Prozessdaten
Durch die zwei beschriebenen Szenarien, wie Prozessdaten für ML genutzt werden können, ergeben sich zwei verschiedene Formen, wie Prozessdaten für ML aufbereitet werden können. Zum einen das Aufbereiten auf der Prozessebene und zum anderen auf der Aktivitätsebene.
Auf der Prozessebene wird ein Datensatz pro abgeschlossene Prozessinstanz erzeugt. Dieser stellt den Zustand einer Prozessinstanz inklusive der Werte aller Prozessvariablen zum Ende dar. Tabelle 1 zeigt Beispieldaten für die Prozessebene.

Tabelle 1: Beispielprozessdaten auf Prozessebene
Bei der Aktivitätsebene liegen die Daten auf einem höheren Detaillierungsgrad vor. Für jede Prozessinstanz gibt es eine Zeile pro Aktivität, die in dieser Prozessinstanz durchlaufen wurde, inklusive der Werte aller Prozessvariablen, wie sie zu dem Zeitpunkt in der Prozessinstanz gesetzt waren. Ein einfaches Beispiel zeigt Tabelle 2.
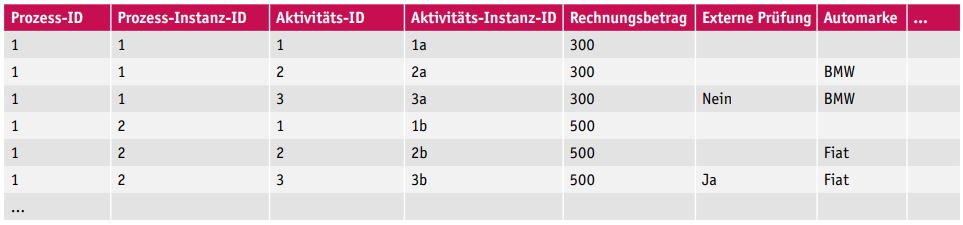
Tabelle 2: Beispielprozessdaten auf Aktivitätsebene
Prozessdatentransformationen auf Aktivitätsebene ermöglichen Zeitreisen
Wie in Tabelle 2 zu erkennen, kann der Zustand einer Prozessinstanz für jede beliebige durchlaufene Aktivität wiederhergestellt werden. Dies erlaubt die Nutzung dieser Daten zum Anlernen eines ML-Modells zur Optimierung oder Unterstützung einer beliebigen Aktivität eines Prozesses, vorausgesetzt natürlich, der Einsatz von ML ist an dieser Aktivität auch sinnvoll. Man kann so gewissermaßen Zeitreisen innerhalb der gesammelten Prozessdaten machen und nachträglich zur Datenanalyse verwenden. Dies setzt jedoch voraus, dass die Daten in einem Format vorliegen, wie in Tabelle 2 dargestellt.
Da Prozess-Engines üblicherweise einzelne Events loggen (wie „Aktivität A wurde gestartet“ oder „Variable X wurde gesetzt“), spiegeln einzelne Logeinträge in ihrer Ausgangsform nicht den kompletten Prozesszustand, sondern nur die gerade getätigte Änderung. Durch die eventbasierte Protokollierung liegt üblicherweise eine sehr hohe Anzahl an Datensätzen vor, die zum einen effizient gespeichert werden müssen und zum anderen vor deren möglicher Nutzung eine gewisse Transformation durchlaufen müssen.
Im Fall der Prozess-Engine Camunda gibt es drei Typen von Events: Prozess-, Aktivitäts- und Variablen-Events. Abbildung 2 zeigt beispielhaft, wann welche Events in Camunda auftreten können, und deutet an, wie viele Events bereits bei einem kleinen Prozess anfallen können. Listing 1 zeigt, in welcher Form beispielsweise die Prozess-Events in Camunda geloggt werden. Für Aktivitäts- und Variablen-Event sehen die Events ähnlich aus.
{
"id":"050de6fb-254f-11e6-9f55-005056a04102",
"processInstanceId":"050de6fb-254f-11e6-9f55-005056a04102",
"executionId":"050de6fb-254f-11e6-9f55-005056a04102",
"processDefinitionId":"118832db-06af-11e5-b07d-005056a07c95",
"processDefinitionKey":null,
"processDefinitionName":null,
"processDefinitionVersion":null,
"caseInstanceId":null,
"caseExecutionId":null,
"caseDefinitionId":null,
"caseDefinitionKey":null,
"caseDefinitionName":null,
"eventType":"start",
"sequenceCounter":0,
"durationInMillis":null,
"startTime":1464493199000,
"endTime":null,
"businessKey":null,
"startUserId":"1",
"superProcessInstanceId":null,
"superCaseInstanceId":null,
"deleteReason":null,
"endActivityId":null,
"startActivityId":"startAct",
"tenantId":null,
"state":"ACTIVE"
}Wohin mit den ganzen Daten?
Da beim Betrieb von Prozess-Engines potenziell eine sehr hohe Anzahl an Logeinträgen anfallen kann, vorausgesetzt die Prozesse werden häufig durchgeführt, stellt sich die Frage nach einer effizienten Speicherung der Daten, sodass diese bei einer Analyse auch möglichst schnell wieder verfügbar gemacht werden können.
Aus unserer Sicht bietet sich hier der Einsatz von Apache Kafka an, da es sowohl für die Speicherung als auch die Verarbeitung von großen Datenmengen inkl. deren direkte Verarbeitung im Stream entwickelt wurde [Kafka]. Häufig werden solche Daten aber in Data-Warehouses abgelegt, um sie für einem mögliche spätere Nutzung verfügbar zu haben. Mithilfe von Kafka Stream-Applikationen können die anfallenden Events auch modifiziert werden, bevor sie aufbewahrt werden. In Szenarien mit sehr hohem Datenaufkommen sind Kafka Stream-Applikationen eine in Betracht zu ziehende Lösung.
Sämtliche Transformationen lassen sich sehr gut in Apache Spark realisieren, weshalb wir hier annehmen, dass lediglich drei Topics in Kafka existieren, die jeweils einen der drei Event-Typen enthalten: processInstance, activityInstance und variableUpdate. Für den Import von Prozessdaten aus Camunda in Apache Kafka kann zum Beispiel der Camunda Kafka Polling Client verwendet werden, der als Open-Source-Applikation in GitHub zur Verfügung steht [Polling]. Aber auch die Anwendung von Kafka Connect stellt eine Möglichkeit dar, Daten in Apache Kafka zu bekommen.
Zudem nehmen wir an, dass Prozessdaten zunächst für einen gewissen Zeitraum gesammelt werden und die Datentransformation für das ML als Batch-Prozess geschieht, da ML-Modelle üblicherweise zu einem bestimmten Zeitpunkt mit einer definierten Datenmenge trainiert werden. Es ist aber natürlich möglich und bei sehr großen Datenmengen auch eventuell sinnvoll, die Datentransformation intervallartig im Batch-Prozess durchzuführen.
Viele unserer Kunden haben ähnliche Fragestellungen. Teilweise liegt bereits eine große Anzahl an Prozess-Engine-Logs vor, sie wissen aber nicht, wie sie diese sinnvoll einsetzen können. Wir haben uns entschlossen, zum „Best-of“ der Anforderungen eine integrierte Lösung zusammenzustellen und als Open Source [github] zur Verfügung zu stellen. Daraus wurde bpmn.ai.
Abbildung 3 zeigt die grobe Architektur von bpmn.ai. Apache Kafka wird für die Prozess-Engine Camunda zur Datenspeicherung verwendet, wobei auch ein Import als CSV möglich ist. Im nächsten Schritt kommt Apache Spark für die Datentransformation zum Einsatz. Das Ergebnis wird anschließend in H2O genutzt, um ML-Algorithmen zu trainieren.
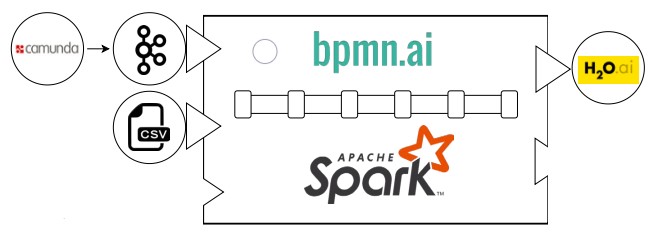
Abb. 3: bpmn.ai-Architektur
Shit in, Shit out
Bei dem Einsatz von ML kommt der Datenvorverarbeitung eine entscheidende Bedeutung zu. Die Daten, die zum Anlernen eines ML-Modells verwendet werden, müssen zum einen in einer gewissen Menge vorliegen, um auf ihnen überhaupt sinnvoll ML betreiben zu können, zum anderen ist aber die Qualität, in der sie vorliegen, mindestens genauso wichtig.
Deshalb stellen Apache Spark-Applikationen das Herzstück von bpmn.ai dar. Sie erlauben eine flexible, konfigurierbare und skalierbare Datentransformation von Prozessdaten, wie sie in der jeweiligen Prozess-Engine entstehen, hin zu einer Datenstruktur, die sich für ML eignet.
Warum Apache Spark?
Wie zuvor dargelegt, kommt der Aufbereitung der Daten, die für das Trainieren von ML-Modellen verwendet werden, eine zentrale Rolle zu, und bei der Ausführung von Geschäftsprozessen fällt potenziell eine sehr hohe Anzahl an Daten an, die es zu verarbeiten gilt. Für das ML müssen die Daten in einer denormalisierten Form vorliegen, das heißt, jedes potenzielle Feature sowie die Zielvariable müssen in einer eigenen Spalte stehen (s. beispielhaft Tabelle 3).
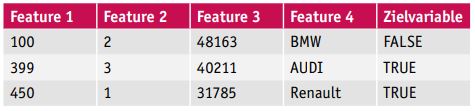
Tabelle 3: Beispielhafte Tabellenstruktur für ML
Die in der Prozess-Engine anfallenden Events liegen üblicherweise nicht in der benötigten Struktur vor. Im Beispiel der Prozess-Engine Camunda gibt es die drei verschiedenen Event-Typen:
Prozess-, Aktivitäts- und Variablen-Events (vgl. Abb. 2). Listing 1 zeigt ein Beispiel für einen Event-Typ.
In bpmn.ai wird eine Pipeline aus Vorverarbeitungsschritten definiert, die selbst jeweils eine bestimmte Aufgabe in der Datentransformation übernehmen. Diese werden mithilfe von Spark-Operationen definiert und die Gesamtpipeline kann dann zum Beispiel an einen Spark Cluster übergeben werden, um die vorliegenden Prozessdaten für das ML aufzubereiten.
Die bpmn.ai-Vorverarbeitungs-Pipeline
Die Vorverarbeitungs-Pipeline von bpmn.ai ist in Abbildung 4 dargestellt. Dabei wird, wie bereits erwähnt, zwischen der Datentransformation auf Prozess- und auf Aktivitätsebene unterschieden.
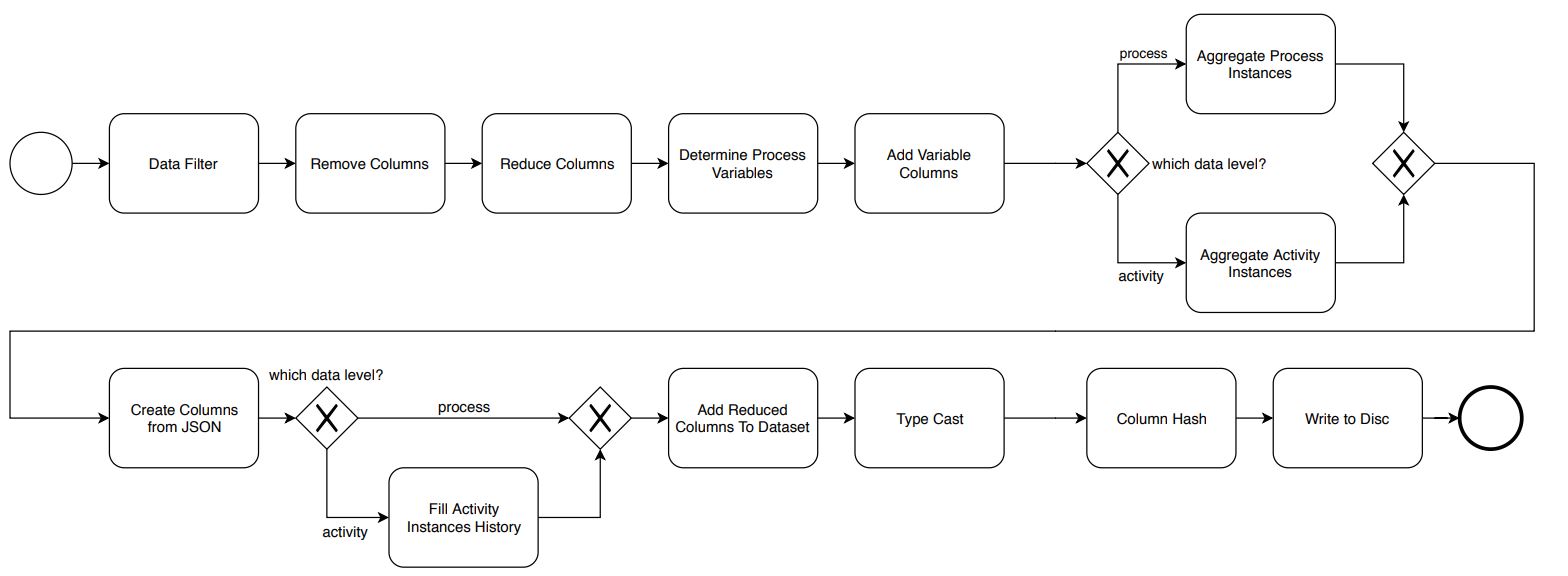
Abb. 4: Vorverarbeitungs-Pipeline von bpmn.ai
Im ersten Schritt werden die Daten gefiltert. Dabei kann zum Beispiel nach einer bestimmten Prozessdefinition gefiltert werden (Data Filter).
Anschließend werden nicht benötigte Spalten aus den Daten entfernt (Reduce Columns). Das betrifft zum Beispiel technische Spalten, die keine Datentransformation benötigen und daher am Ende der Pipeline wieder per Join-Operation in die Daten eingefügt werden können (Add Reduced Columns To Dataset). Dies kommt bei großen Datenmengen der Performanz zugute. Spalten, die nicht benötigt werden, können endgültig rausgefiltert werden (Remove Columns).
Im nächsten Schritt werden die Prozessvariablen und ihre Datentypen bestimmt (Determine Process Variables). Sind alle Prozessvariablen bestimmt, besteht der nächste Schritt darin, diese Variablen jeweils als einzelne Spalten hinzuzufügen (Add Variable Columns).
Bis hierhin sind die Schritte auf Prozess- und Aktivitätsebene identisch. Im anschließenden Aggregationsschritt wird je nach Zielebene entweder nach Prozess-Instanz-ID oder nach Aktivitäts-Instanz-ID gruppiert. Im Fall der Prozessebene liegt nach diesem Schritt für jede Prozessinstanz nur noch ein Datensatz mit allen Prozessvariablenwerten vor, wie sie am Ende der Prozessinstanz gesetzt waren (Aggregate Process Instances). Bei der Aktivitätsebene liegt für jede Aktivitätsinstanz ein Datensatz vor, welcher die Werte aller Variablen enthält, die in dieser Aktivität gesetzt oder verändert wurden (Aggregate Activity Instances).
Im nächsten Schritt werden weitere Prozessvariablen gesucht. So werden zum Beispiel Variablen vom Typ String daraufhin geprüft, ob sie JSON-Objekte enthalten, und falls ja, soweit automatisiert möglich, in neue Variablenspalten transformiert (Create Columns From JSON). An dieser Stelle könnten auch andere komplexe Datentypen nach weiteren Variablen durchsucht werden (z. B. Java-Klassen).
Anschließend wird im Falle der Aktivitätsebene noch jede Zeile so verändert, dass sie den kompletten Stand der Prozessvariablen enthält (Fill Activity Instance History). Dies erlaubt die zuvor erwähnten Zeitreisen in den Prozessinstanzen.
Zum Ende werden die Spalten auf den entsprechenden Datentyp gecastet (Type Cast), ausgewählte Spalten anonymisiert (Column Hash) und anschließend das Ergebnis, zum Beispiel in ein Apache Hadoop-Cluster, persistiert (Write To Disc).
Die Pipeline kann durch Implementierungen von vorgegebenen Interfaces leicht erweitert werden. So haben wir unter anderem für Kunden bereits weitere Schritte implementiert, die zum Beispiel eine Umwandlung von Postleitzahlen in Geo-Koordinaten vornimmt, über die Levenshtein-Distanz [Wiki] ähnliche Markennamen zu eindeutigen Markennamen zusammenführt oder weitere fachliche Daten aus anderen Quellen anreichert.
Unsere Erfahrungen mit Apache Spark
Im Nachhinein hat sich die Wahl von Apache Spark als richtig herausgestellt. Zum Beispiel waren wir waren damit in der Lage, Prozessdaten eines Kunden von über einem Jahr (über 7,5 Mio. Events und ca. 180 Prozessvariablen bei ca. 25.000 abgeschlossenen Prozessinstanzen) auf einem Laptop auf der Prozessebene in sechs Minuten vollständig zu transformieren. Durch Ausführen derselben Transformation auf einem Cluster konnte die Ausführungszeit, bei entsprechendem Ressourceneinsatz, bis auf eine Minute reduziert werden.
Scala oder Java?
Die Umsetzung barg aber auch einige Tücken. Apache Spark ist in Scala geschrieben, bietet jedoch APIs, um Spark-Anwendungen sowohl in Scala als auch in Java oder Python zu schreiben. Auch für die beliebte Programmiersprache für Datenanalysen R wird eine Programmierschnittstelle angeboten, sodass einer Datenanalyse nach der Vorverarbeitung auch direkt aus einem Spark-Cluster heraus nichts im Wege steht. Etwas, von dem wir aufgrund der vielen Möglichkeiten in R auch selbst regen Gebrauch machen. Die Tatsache, dass Apache Spark in Scala geschrieben wurde, führt zu einigen Stolpersteinen, wenn man sich für Java als Programmiersprache entscheidet.
Die meisten Diskussionsbeiträge zu Apache Spark referenzieren Scala, sodass häufig ein Transfer zu Java stattfinden muss. Mit der Zeit gewöhnt man sich jedoch daran und weiß, wo sich bestimmte Funktionen im Java-API befinden. Wenn es um die Implementierung einzelner Transformationsschritte geht, hat sich die Nutzung der Notebook-Lösung Zeppelin bewährt, da sie ein schnelles Ausprobieren von Spark-Operationen ermöglicht. Der fertige Code kann dann einfach übertragen werden.
Spark optimiert viel, aber nicht alles!
Apache Spark macht einen hervorragenden Job, wenn es um Optimierung und Skalierung von Datentransformationen geht. Dies
setzt jedoch voraus, dass man konsequent alle seine Transformationen mithilfe der angebotenen Operationen schreibt und nicht aus Bequemlichkeit, oder weil man gerade nicht weiß, wie man die nötige Transformation als Spark-Operation umsetzt, Daten per collect() in ein Java-Objekt umwandelt und wieder auf „normalen“ Java-Code ausweicht. Dann kann Spark diesen Code nicht optimieren und er stellt ein Nadelöhr in der Pipeline dar.
Aber auch bei der Wahl der Spark-Operationen lohnt sich manchmal ein Blick auf die Details, um zu überlegen, ob die naheliegende Wahl der Operation auch die effizienteste darstellt. Dies ist vor allem dann sinnvoll, wenn einem die Ausführungszeit verhältnismäßig lang vorkommt. Meistens war es dann auch nicht die optimale Wahl der Operation. Wir hatten beispielsweise den Fall, dass wir für den Schritt Fill Activity Instances History zunächst eine Window-Operation verwendet haben, um die Vergangenheitswerte der Prozessvariablen für die jeweilige Aktivität zu bestimmen. Die Window-Operation ist jedoch bei vielen Spalten sehr ineffizient, weswegen wir die Funktionalität in eine User Defined Function implementiert haben. Durch ein solche Function können eigene Operationen definiert werden und Spark ist dadurch in der Lage, die Ausführung zu parallelisieren.
Eine weitere Möglichkeit, Spark bei der Optimierung der Pipeline zu unterstützen, ist die Partitionierung. Spark partitioniert die Daten zwar selbst im Hinblick auf die durchzuführenden Operationen, kennt man jedoch selbst bereits eine Partitionierung, um die Daten zum Beispiel in einem Cluster möglichst sinnvoll auf mehrere Worker zu verteilen, so kann ein manuelles Partitionieren für zusätzlichen Geschwindigkeitszuwachs sorgen.
Ausblick und Fazit
Bei der Verwendung von Prozessdaten aus Prozess-Engines für ML ist eine aufwendige Datentransformation von großen Datenmengen erforderlich. Gleichzeitig gibt es je nach Geschäftsprozess fachliche Anforderungen, die in die Datentransformation einfließen müssen.
Bpmn.ai erlaubt die effiziente und flexible Vorverarbeitung von Prozessdaten, um sie für ML nutzbar zu machen. Durch Konfiguration und Erweiterungen lässt sie sich zudem einfach an spezielle fachliche Anforderungen anpassen. Bpmn.ai ist generell nicht auf Camunda als Prozess-Engine mit Datenspeicherung in Apache Kafka und anschließendem ML in H2O festgelegt. Vielmehr kann durch die flexible Architektur eine Anbindung von anderen Prozess-Engines erfolgen. Die aus der Transformation resultierenden Daten lassen sich auch in anderen ML-Lösungen verwenden, wenn zum Beispiel spezielle ML-Modelle genutzt werden sollen, die nicht in H2O verfügbar sind, oder bereits andere Lösungen für ML im Einsatz sind.
Links
[Camunda]
https://camunda.com/
[BPMN2]
http://www.bpmn.org/
[github]
https://github.com/viadee/bpmn.ai
[Kafka]
https://kafka.apache.org/
[Tiobe]
https://tiobe.com/tiobe-index/
[Polling]
https://github.com/viadee/camunda-kafka-polling-client
[Wiki]
https://de.wikipedia.org/wiki/Levenshtein-Distanz
[Zeppelin]
https://zeppelin.apache.org/









