

Ein Staging-Konzept ist aus der modernen Softwareentwicklung nicht mehr wegzudenken. Einer der Hauptgründe dafür ist mit Sicherheit die verbesserte Testbarkeit der Software: Staging ermöglicht realistische Tests noch vor der Produktivsetzung, indem ein (beliebiger) Softwarestand in eine produktionsnahe Umgebung deployt wird. Das bringt gleich mehrere Vorteile mit sich:
- Der Installationsprozess wird dabei vorab getestet.
- Die Software wird in einem realistischen Set-up betrieben und kann dabei auf nicht funktionale Anforderungen (wie Performance oder Stabilität) getestet werden.
- Tester bekommen auf einfache Art und Weise die Möglichkeit, neue Features und Funktionen zu testen oder Bug-Fixes zu verifizieren.
Staging sorgt initial für zusätzlichen Aufwand und Komplexität, aber durch die bereits genannten Vorteile wird dieser Nachteil rasch wieder wett gemacht. Welche Herausforderungen mit Staging einhergehen und wie wir diese für eine unserer Applikationen gemeistert haben, soll dieser Beitrag veranschaulichen.
Staging bedingt Parametrisierung
URLs, Zugangsdaten, IDs, ... in Applikationen werden immer Daten verwendet, die zur jeweiligen Umgebung passen müssen. Erst bei der Einführung von Staging merkt man, wie viele dieser Konstanten dann doch nicht ganz so konstant sind und somit pro Umgebung parametrisiert werden müssen.
Umgebungsabhängige Parameter bei unserer Applikation
Neben den üblichen und bereits genannten Parametern interagiert unsere Applikation mit Atlassen Jira und liest beziehungsweise manipuliert Eigenschaften von Tickets (z. B. Custom Fields mit eindeutigen IDs) über die Jira-eigene REST-API. Damit unser Staging-Konzept durchgehend funktioniert, gibt es natürlich auch eine eigene Jira-Instanz in unserer Testumgebung, initial eine Kopie der Produktion. Die IDs aller Custom Fields waren somit in der Test- und Produktionsumgebung ident, mussten also anfangs nicht parametrisiert werden. Und dann die Überraschung: Ein nachträglich angelegtes Custom Field in Produktion bekommt eine andere ID als in der Testumgebung. Und schon gibt es einen weiteren Parameter, der umgebungsabhängig behandelt werden muss.
Wie wird eigentlich parametrisiert?
Üblich ist eine Kombination aus Parametern auf der Command Line und Umgebungsvariablen. Kommandozeilenparameter ermöglichen es schnell und einfach, der Applikation zum Startzeitpunkt neue Werte mitzugeben, die auf die Umgebung abgestimmt sind. Gerade bei Applikationen, die oft mit verschiedenen Werten gestartet werden, ist diese Methode durchaus sinnvoll, weil die Werte sehr einfach verändert werden können. Alternativ werden Werte aus den Umgebungsvariablen ausgelesen (die zuvor natürlich auch zur Umgebung passend gesetzt werden müssen). Für das Management der Umgebungsvariablen gibt es viele Möglichkeiten, zwei übliche sind die Parametrisierung über .env-Dateien und die Parametrisierung über den Applikations-Container.
Parametrisierung über .env-Dateien
In .env-Dateien werden Key-Value-Paare hinterlegt, die mittels passendem Framework beim Start der Applikation automatisiert gelesen und als Umgebungsvariable gesetzt werden (der Key entspricht dabei dem Namen der Umgebungsvariable). Dieses System erlaubt auch, ganz einfach eine eigene .env-Datei pro Umgebung zu verwalten. Aber Achtung: Niemals dürfen Zugangsdaten in diesen Dateien hinterlegt werden, die dann letztendlich im Versionierungssystem landen! Auch wenn zum Beispiel der Git-Server selbst gehostet wird, sollte man diese Regel grundsätzlich befolgen, denn jeder Entwickler mit Zugriff auf das Versionierungssystem hat dann Zugriff auf diese sensiblen Daten im Klartext.
Parametrisierung über den Applikations-Container
In den allermeisten Fällen wird die entwickelte Applikation durch andere Programme/Frameworks/Server/… gebaut, deployt oder gehostet. Diese Systeme bieten oft die Möglichkeit, Umgebungsvariablen zu setzen, auf die dann während des Builds oder der Ausführung zugegriffen werden kann. Außerdem können hier auch sensible Daten sicher hinterlegt werden. Der Zugriff auf diese Systeme muss natürlich entsprechend eingeschränkt werden.
Parametrisierung bei unserer Applikation
Wir selbst setzen ausschließlich auf Umgebungsvariablen. Das von uns verwendete UI-Framework Vue.js bringt das Management von Umgebungen über den Kommandozeilenparameter „--mode“ bereits mit und verwendet so die jeweils passende .env-Datei (siehe Abbildung 1). Serverseitig verwenden wir dafür die node.js-Library custom-env, die ebenfalls über einen Kommandozeilenparameter gesteuert wird.
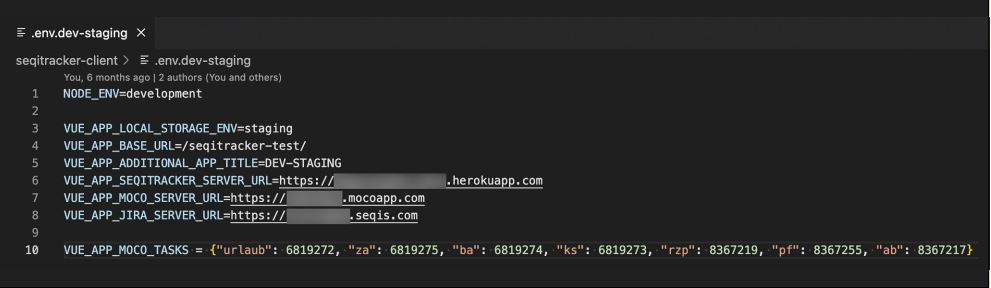
Abb. 1: Einfache .env-Datei für unsere lokale DEV-Umgebung, SEQIS GmbH
Für unsere Produktionsumgebung wird ausschließlich das Umgebungsvariablen-management der umliegenden Systeme verwendet: Während Build-Prozess und Deployment werden die Umgebungsvariablen über Gitlab selbst verwaltet, und während der Ausführung wird auf die in Heroku (unser hosting Provider https://www.heroku.com) hinterlegten Umgebungsvariablen zurückgegriffen. Für alle anderen Umgebungen setzen wir auf .env-Dateien, die von jedem Entwickler bei Bedarf angepasst werden können (siehe Abbildung 2).
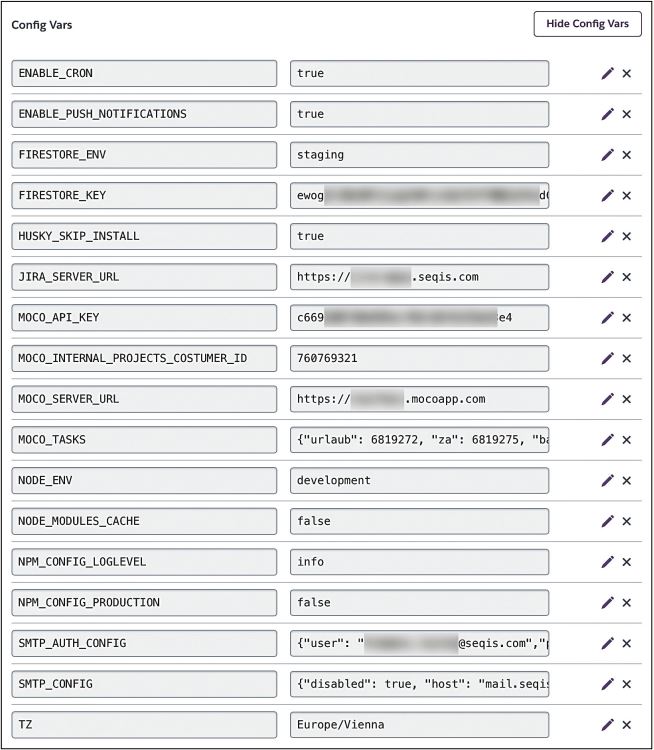
Abb. 2: Verwaltung der Umgebungsvariablen in Heroku, SEQIS GmbH
Staging bedingt Releasemanagement
Eigentlich ist Releasemanagement ja auch schon bei einer Umgebung, der Produktion, notwendig: Es muss sichergestellt werden, dass die richtige Version jeder Applikation verfügbar ist, damit die korrekte Kommunikation gewährleistet ist. Schließlich darf es nicht passieren, dass Applikation A plötzlich nicht mehr mit Applikation B reden kann, weil B die API geändert hat und A nicht mitgezogen ist. Releasemanagement ist in der Produktion schon nicht trivial, in den Umgebungen davor (DEV, TEST) noch deutlich schwieriger: Das Deployment-Intervall ist erheblich kürzer und die Gefahr von Inkompatibilitäten zwischen Applikationen sehr hoch. Je komplexer die Architektur (Stichwort Microservices) und verteilter die Entwicklung (Stichwort Outsourcing) desto aufwendiger und auch wichtiger ist ein effizientes und ernsthaft gelebtes Releasemanagement. Sonst endet man, bildlich gesprochen, im Turmbau von Babylon. Ein weiterer Aspekt von Releasemanagement ist, jederzeit mit Sicherheit und mit möglichst wenig Aufwand sagen zu können, welcher Code-Stand beziehungsweise welches Feature auf welcher Umgebung verfügbar ist. Fehlt diese Möglichkeit, kann es leicht passieren, dass halb fertige Applikationsversionen getestet oder Bug-Fixes verifiziert werden, die noch gar nicht verfügbar sind.
Releasemanagement bei unserer Applikation
In unserem aktuellen Projekt haben wir nur vier Teil-Applikationen, von denen drei von uns direkt betreut und verantwortet werden. Dementsprechend leichtgewichtig gestaltet sich auch unser Releasemanagement: Im Wesentlichen organisieren wir den Fortschritt über Jira-Tickets, die über Verlinkungen die Abhängigkeiten zueinander verdeutlichen. Außerdem zeigt jedes Feature-Ticket an, auf welchen Git-Branch es verfügbar ist – das passiert automatisch durch eine eigens dafür entwickelte Integration von Jira mit Gitlab. So haben wir jederzeit im Blick, welches Feature wo deployt sein muss, damit die Applikation als Ganzes richtig funktioniert, und welches Feature auf welcher Umgebung aktuell verfügbar ist. Ganz automatisch, ohne manuelle Eingriffe. Wir taggen automatisch alle Test- und Produktions-Releases, wodurch sich über die Versionsnummer immer eindeutig auf den genauen Code-Stand rückschließen lässt.
Staging bedingt Automation
Ein Staging-Konzept ist nur automatisiert vernünftig umsetzbar. Auch wenn es keine technische Notwendigkeit dafür gibt, sind Build und Deployment manuell bei Bedarf auf die jeweilige Umgebung auf Dauer viel zu ineffizient und fehleranfällig.
Automation des Builds
In den allermeisten Softwareprojekten ist irgendeine eine Art von Build-Pipeline notwendig, um ein lauffähiges Stück Software zu erhalten. Typische Schritte innerhalb des Builds sind zum Beispiel:
- Überprüfung der statischen Code-Qualität,
- Ausführen der Unit-Tests,
- Übersetzung (Transpile/Compile/…) der Code-Basis in ein ausführbares Programm.
Diese Schritte sind natürlich alle auch manuell durchführbar. Ohne Staging-Konzept, also nur mit einer Produktionsumgebung und einem Deployment alle paar Monate, hält sich auch der Aufwand stark in Grenzen. Es bleibt trotzdem eine gewisse Fehleranfälligkeit, weshalb die Automation des Builds zu bevorzugen ist. Als Build-Automat hat sich schon seit Langem das Open-Source-Projekt Jenkins etabliert. Mit dem Einsatz von Gitlab, Github und Konsorten, die jeweils ihre eigene Build-Automation mit sich bringen, ist die Hürde für die Automation noch weiter gesunken.
Automation des Deployments
Deployments unterscheiden sich je nach eingesetzter Programmiersprache, Frameworks und genereller Systemarchitektur stark. Die Containerisierung hat noch einmal das Prinzip des Deployments stark verändert. Sehr oft haben Deployments aber eines gemein:
Das Build-Artefakt muss vom Build-Server auf einen anderen Server übertragen werden. Das geht meist mit einem Re-Start der Applikation einher.
Diese wenigen Schritte sind aber durchaus anspruchsvoll und bedingen bereits eine funktionierende Parametrisierung des Build und Deployments, denn diverse Eigenschaften der Zielumgebung, sowie die (zumeist notwendigen) Zugangsdaten, müssen dynamisch festgelegt werden.
Automation bei unserer Applikation
Bei uns ist mittlerweile alles automatisiert, was möglich und (aus unserer Sicht) sinnvoll ist (siehe Abbildung 3):

Abb. 3: 342 Tests decken fast 95 Prozent des Server-Codes ab, SEQIS GmbH
- Die Commit Messages werden bei jedem Commit automatisch über Git Hooks angepasst. Dafür wird jeder Feature-Branch mit dem zugehörigen Jira Feature Ticket Key gepräfixt, feature/RZFZ-123_Very_ Cool_Feature, und jede Commit Message kann daraufhin automatisiert mit dem Jira Feature Ticket Key gepräfixt werden (per pre-commit hook, der Entwickler muss sich nicht darum kümmern und kann es auch nicht vergessen).
- Vor jedem Push (abgesehen von Feature-Branches) werden Unit-Tests und verschiedene inhaltliche Checks lokal durchgeführt, bevor der eigentliche Push überhaupt ausgeführt wird. Die Checks sind natürlich auch vollständig automatisiert, per pre-push hook. Wir prüfen beispielsweise, ob das package-lock.json tatsächlich dem package.json entspricht (oder ob die beiden auseinanderlaufen) und ob tatsächlich keine neuen Features auf bereits releaste Versionen gepusht werden.
- Jeder Push wird per Gitlab WebHook mit Jira synchronisiert und verändert dort den Status (und weitere Eigenschaften) der jeweiligen Feature-Tickets.
- Änderungen am staging-Branch werden unmittelbar auf unsere Testumgebung deployt, Änderungen am master-Branch führen sofort zu einem neuen Produktions-Release.
- Zusätzlich haben wir wiederkehrende Tasks als optionale Gitlab-Jobs umgesetzt, beispielsweise ist es möglich, jeden beliebigen Branch per Knopfdruck in die Testumgebung zu übernehmen, was das Testen von neuen Features stark vereinfacht
Das Deployment auf unseren Hosting-Provider Heroku führen wir mit der Ruby-Library Dpl (https://github.com/travis-ci/dpl) durch. Dpl abstrahiert die Eigenheiten von einer Vielzahl von Hosting-Providern. Ein Deployment auf Heroku ist damit mit einem einzigen Shell-Befehl durchführbar
Mein persönliches Learning
Abbildung 4 fasst unseren Staging-Prozess in einer Übersicht zusammen. Aber auch ein ausgereiftes Staging-Konzept ist nicht etwas, das man einfach so umsetzt: Die Parametrisierung zieht sich durch das ganze Projekt, ist aber der notwendige Grundstein für das ganze Unterfangen. Die Automation von Build und Deployment ist mitunter langwierig und mühsam zu testen und man braucht meistens mehrere Versuche, bis alles reibungsfrei funktioniert.
Bei Projektstart war bei uns auch noch vieles manuell – ein Command hier, ein Copy/ Paste dort, Server-Neustart per API-Call im Postman – und hat (meistens) auch problemlos funktioniert. Trotzdem ist jeder einzelne Schritt zur vollständigen Automation ein wichtiger und richtiger gewesen und der Aufwand hat sich längst bezahlt gemacht.
... und ganz ehrlich: Ein voll automatisiertes Staging-Konzept inklusive Produktions-Release ist einfach geil :)!
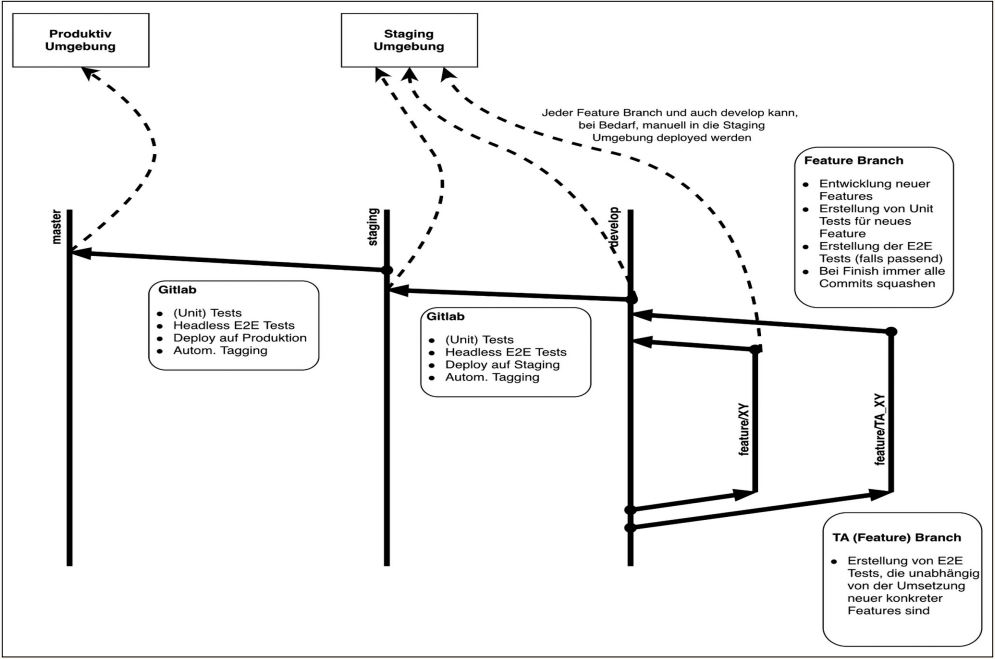
Abb. 4: Staging-Prozess, Übersicht, SEQIS GmbH









