

Für alle Arten von Daten (Produktdaten, Benutzerinformationen, Käufe, Rabattaktionen usw.) gibt es bei otto.de üblicherweise ein System, das die Hoheit darüber hat. Falls andere Systeme diese Daten ebenfalls benutzen möchten, wird eine Kopie davon im Hintergrund, also asynchron, an einer bereitgestellten Schnittstelle angefragt und automatisch in die eigene Datenbank übertragen. Auf diese Weise können wir lange Request-Kaskaden zwischen den Systemen vermeiden. Das ist gut für unsere Antwortzeit bei Kunden-Requests und sehr hilfreich, um die Gesamtarchitektur resilient zu halten.
Die Server kommunizieren bei uns bislang fast ausschließlich über REST-artige HTTP-Schnittstellen. Es gibt also
- ein System, das Daten bereitstellt (den Server), und
- ein oder mehrere Systeme, die sich von dort die Daten abrufen sollen (die Clients).
Die Backend-Integration von Systemen birgt einiges an Herausforderungen, aber durch eine besondere Klasse von Integrationstests – nämlich den CDC-Tests – können Teams sich versichern, dass die Schnittstellen noch immer wie erwartet funktionieren.
Welches Problem soll gelöst werden?
Der Server stellt einen HTTP-Endpunkt bereit – beispielsweise für aktuelle Produktpreise – und ein Client kann HTTP-Requests dagegen absetzen. Weil die Endpunkte im Allgemeinen gegen unberechtigten Zugriff geschützt sind, gehören noch Keystores und Zugangsdaten mit ins Bild (siehe Abbildung 1), aber im Wesentlichen war es das auch schon.
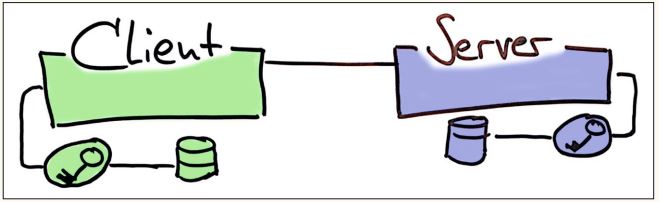
Abb. 1: Asynchrone Datenversorgung sind häufig nur glorifizierte HTTP-Requests zwischen Client und Server. Beide Seiten benutzen üblicherweise ihre eigenen Keystores und die Secrets daraus, um die Requests zu authentifizieren
Die Schnittstelle des Servers hat meist irgendeine Art von Dokumentation oder Spezifikation und eine Test-Abdeckung, die vom Server-Team für angemessen gehalten wird. Dennoch kommt es immer wieder vor, dass im Client Abhängigkeiten zu Implementierungsdetails entstehen. Da verlassen sich Teams darauf, dass JSON-Elemente stets in einer bestimmten Reihenfolge auftauchen, oder sie können mit neuen Datenfeldern nicht umgehen. Natürlich nehmen sich alle Beteiligten vor, ganz besonders aufmerksam zu sein. Oder sie sind überzeugt, dass diese Art von Fehlern nur anderen passiert.
Dennoch kommt es immer wieder vor, dass etwas, das zuvor funktionierte, plötzlich nicht mehr funktioniert: ein Bug. Diese Art von Störung ist zudem unauffällig genug, dass sie sich eine ganze Zeit im Live-System befinden kann, bevor es jemandem auffällt.
Ich wünsche mir also, dass wir das zumindest schnell bemerken:
- ( ) Bugs werden erkannt.
Woher wir kommen
Wir haben gute Erfahrungen mit Pipelines gemacht. Ein Test, der nach dem Deployment auf ein Develop-System prüft, ob die Antwort des Servers noch in Domänenobjekte übersetzt werden kann, ist schnell geschrieben. Zwar wird jetzt noch ein weiterer Keystore in der Nähe der Pipeline benötigt, damit auch dieser Request authentifiziert werden kann, aber damit ist mein Wunsch schon erfüllt (siehe Abbildung 2).
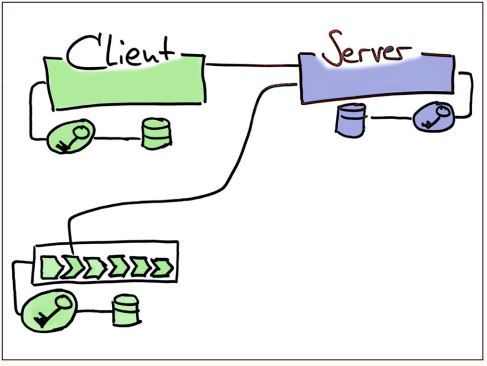
Abb. 2: In der Client-Pipeline prüft ein Test, ob die Antwort des Servers noch den Erwartungen entspricht. Die Pipeline wird rot, wenn sich die Schnittstelle ändert, und das Team kann reagieren
Der Test läuft allerdings nur, wenn die Pipeline des Client-Teams angestoßen wird, beispielsweise durch eine Code-Änderung. Falls das Team aber gerade an einem anderen Service arbeitet, könnte vom Server-Team unbemerkt eine inkompatible Änderung live gebracht werden.
Meine Wunschliste ist also eigentlich noch ein bisschen länger, es kommen zwei weitere Wünsche hinzu:
- (x) Bugs werden erkannt.
- ( ) Die richtige Pipeline wird rot.
- ( ) Bugs gehen nicht live.
Wenn der Test des Client-Teams in der Pipeline des Server-Teams ausgeführt wird, dann nennt man das einen CDC-Test. Das Konzept wurde 2006 durch einen Artikel von Martin Fowler [Fow06] populär, ist dann aber anscheinend wieder ein bisschen in Vergessenheit geraten. Das ist schade, denn dadurch wird effektiv verhindert, dass eine problematische Schnittstellenänderung im Server überhaupt live geht (siehe Abbildung 3).
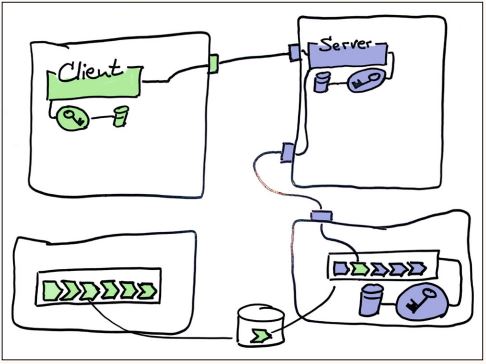
Abb. 3: Der Test des Client-Teams wird in der Server-Pipeline ausgeführt und kann so verhindern, dass eine inkompatible Server-Änderung überhaupt ins Live-System deployt wird
Im Kontext von otto.de wurde zunächst der Test zum Beispiel als Jar-Datei ins zentrale Artifactory gelegt, von der Server-Pipeline abgeholt und dort ausgeführt. Einige Teams stellten Shell-Skripte zur Verfügung, die zum Beispiel die richtige Version des Jars ermitteln und herunterladen.
Ein Nachteil dieser Herangehensweise ist, dass Laufzeit-Abhängigkeiten des Tests in der Pipeline vorhanden sein müssen. Bei der Einführung von Java 8 hat uns beispielsweise gestört, dass manche Server-Pipelines noch in Java 6 liefen. Die Tests anderer Teams wiederum sind auf ein Chrome-Binary oder X11-Libraries angewiesen, die dann vom Server-Team in der Pipeline bereitgestellt werden müssen.
Als Reaktion haben einige Teams ihre Jar-Dateien in Docker-Images verpackt. Das hat das Problem ein wenig reduziert, obwohl das Server-Team natürlich mit dem uralten Docker-im-Docker-Problem kämpfen muss und Versionsänderungen von Docker auch gerne mal inkompatible Änderungen mit sich bringen.
Aus dem gleichen Grund war ein Experiment mit Pact [Pact] auch recht schnell vorbei, als ein Team eine neuere Version einführen wollte, die mit der Version des anderen Teams nicht mehr funktionierte.
Auch ist störend, dass das Server-Team die Zugangsdaten des Client-Tests in der Pipeline zur Verfügung haben muss, weil Credentials natürlich nicht im Code stehen dürfen. Diese Zugangsdaten existieren also parallel zu denen, die das Client- und das Server-Team ohnehin in ihrer Umgebung haben müssen, um damit Requests authentifizieren und validieren zu können.
Während sich die einen Wünsche erfüllten, wurde meine Wunschliste also fast genauso schnell länger und wächst um weitere zwei Wünsche:
- (x) Bugs werden erkannt.
- (x) Die richtige Pipeline wird rot.
- (x) Bugs gehen nicht live.
- ( ) Passworte werden nicht dupliziert.
- ( ) Keine Tooling-Abhängigkeiten.
Trotz der Unzulänglichkeiten und in völliger Missachtung meiner Wunschliste blieb dies fast sechs Jahre lang der Zustand unserer CDC-Tests. Das war zwar nicht richtig, richtig gut, aber immerhin gut genug.
Wo wir keinesfalls hinwollen
Seit wir unser dediziertes Rechenzentrum verlassen haben, um in die Cloud zu migrieren, sind in fast allen Teams die Umgebungen der Systeme netzwerkseitig voneinander und von dem Bereich getrennt, in dem die Pipelines laufen. Das hat natürlich Konsequenzen für die Tests. Der Versuch, den alten Zustand in die neue Welt der Cloud zu übersetzen, hat zu Abbildung 4 geführt.
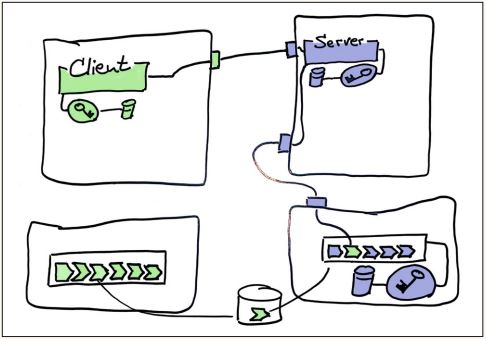
Abb. 4: Versuch, den alten Zustand in die neue Welt der Cloud zu übersetzen
Damit die CDC-Tests weiter funktionieren, musste das Server-Team also teilweise auch noch Löcher in ihre Firewalls bohren. Darüber hinaus ist jetzt durch Infrastruktur-as-Code die Netzwerkstrecke zwischen Client und Server potenziell kontinuierlichen Änderungen unterworfen: eine neue Möglichkeit, versehentlich Clients kaputtzumachen.
Das Server-Team muss nun also schon …
- …die Version des Tests ermitteln, die zu dem Client passt,
- …den Test (ein potenziell riesiges Artefakt) downloaden,
- …Laufzeit-Abhängigkeiten bereitstellen,
- …Passworte im Pipeline-Bereich ablegen,
- …Löcher in die Firewall bohren.
Dabei ist nicht mal sicher, dass die Kommunikation auch wirklich funktioniert, weil die Netzwerkstrecke sich unerwartet ändern kann.
Nachdem einige Jahre lang Ruhe um das Thema eingekehrt war, wuchs nun die Wunschliste plötzlich in unerträglichem Maße auf sieben Wünsche:
- (x) Bugs werden erkannt.
- (x) Die richtige Pipeline wird rot.
- (x) Bugs gehen nicht live.
- ( ) Passworte werden nicht dupliziert.
- ( ) Keine Tooling-Abhängigkeiten.
- ( ) Keine Kompromisse in der Sicherheit.
- ( ) Infrastructure-as-Code wird mitgetestet.
Das war ein guter Zeitpunkt, die Aufgabenverteilung neu zu überdenken.
Wo wir letztlich gelandet sind
Das Client-Team stellt nun den Test als Lambda-Funktion, als EC2-Instanz oder als Teil ihres Systems bereit (siehe Abbildung 5). Ein API-Gateway ermöglicht es dem Server-Team, mit einem HTTP-Request den Test zu starten. Da der Test gleichzeitig mit dem Productioncode ausgeliefert wird, hat er stets die richtige Version. Das Server-Team muss nichts mehr herunterladen, und die einzige technische Abhängigkeit ist die Fähigkeit, einen HTTP-Request aus der Pipeline absetzen zu können – was dank Curl oder WGet für kein Team eine Herausforderung darstellt. Die Zugangsdaten für den Test liegen ohnehin im Keystore für den Client.
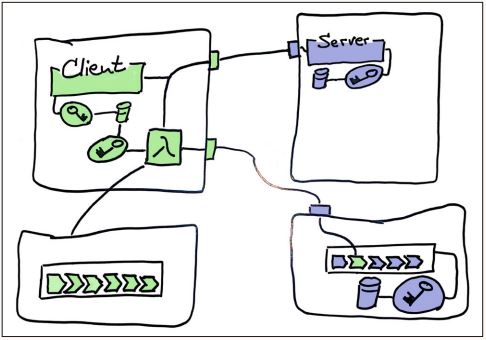
Abb. 5: Wo wir letztlich gelandet sind
Und nun endlich sind alle Wünsche auf der Liste in Erfüllung gegangen, die im Kasten zusammengefasst ist.

Vollständige Wunschliste
Was noch zu tun ist
Mit den neuen Möglichkeiten, auf einfache Weise Kommunikationskanäle aufzubauen, die nicht auf Requests und Responses basieren, sondern die Messaging-Systeme wie SQS, Kinesis oder Kafka benutzen, hat sich das Problemfeld plötzlich derart erweitert, dass wir noch gar keine gute, also allgemeingültige Antwort darauf gefunden haben. Ich wünsche mir neuerdings also, dass wir das auch testen können.
Zwar haben einige Teams schon mit Testnachrichten experimentiert und auch Pact wird wieder mit neuer Zuneigung betrachtet. Andere Teams benutzen die Messaging-Systeme ohnehin in beide Richtungen und können mit wenigen Anpassungen der bisherigen Strategie gute Tests bauen. Bei manchen kommt sogar die Frage auf, ob diese Art von Infrastruktur überhaupt getestet werden sollte.
Ich bin also guter Hoffnung, dass uns neben den wachsenden fachlichen Anforderungen nicht die Gründe ausgehen, intensive technische Diskussionen zu führen. Eigentlich bin ich sogar froh, dass immer neue Wünsche dazu kommen. Denn so wird mir nie langweilig.
Referenzen
[Fow06]
I. Robinson, Consumer-Driven Contracts, martinFowler.com, 12.6.2006, siehe: https://www.martinfowler.com/articles/consumerDrivenContracts.html#Consumer-drivenContracts
[Pact]
https://docs.pact.io









