

Transparenz und Verantwortlichkeit sind die neuen Buzzwords der IT-Industrie. Plötzlich fordern Apple, Google und Facebook eine stärkere Regulierung bei der Erhebung, Verarbeitung und Verwendung von Daten und – vor allem – mehr Transparenz für die Anwender. Das ist nach den jüngsten Skandalen auch nicht verwunderlich. Auch der Uber-Unfall oder die Crashs mit Tesla-Fahrzeugen haben sicher zusätzliches Misstrauen gesät.
Tatsächlich werden immer mehr Entscheidungen, Empfehlungen und Handlungen von Modellen Künstlicher Intelligenz (KI) und ihren Algorithmen vorgenommen, welche die Menschen sowohl als Individuum als auch als Gruppe in immer stärkerem Ausmaß betreffen. Viele der hierbei eingesetzten stochastischen Methoden, zum Beispiel des Machine Learning (ML), imitieren menschliche Intelligenz. Sie können für ihre vermeintlich neutrale Empfehlung, Entscheidung oder Handlung weit mehr und schneller Daten auswerten, als es ein Mensch an gleicher Stelle tun könnte. Kritische Anwendungsbereiche sind etwa die Verbrechensbekämpfung beziehungsweise die juristische Entscheidungsfindung, die Bewertung von Kreditwürdigkeit, die Suche und Auswahl von Personal, die Medizin oder der Einsatz im Straßenverkehr und militärischen Bereichen. Auf europäischer Ebene wird hier häufig die DSGVO als mögliches Allzweckmittel gehandelt, welche eine ausreichende Transparenz und Verantwortlichkeit garantieren soll. Zum Beispiel sollen Auskunftspflichten für die notwendige Transparenz sorgen.
Explainable Artificial Intelligence
Auf der Ebene der Technologie arbeitet der Forschungsbereich der Explainable Artificial Intelligence (kurz XAI = erklärbare künstliche Intelligenz) daran, durch Erklärbarkeit von ML-Modellen mehr Transparenz, Verantwortlichkeit und dadurch letztendlich Vertrauen zu entwickeln. Die US-amerikanische Defense Advanced Research Projects Agency (DARPA) verfolgt in einem 2016 aufgesetztem Programm zum Beispiel das Ziel der XAI, neue oder modifizierte ML-Techniken zu entwickeln [2]. Diese sollen es Anwendern in Kombination mit effektiven Erklärungstechniken ermöglichen, die Entscheidungen, Empfehlungen und Handlungen der zukünftigen KI-Systeme zu verstehen, ihnen zu vertrauen und sie in effektiverer Weise einzusetzen.
In den frühen Jahren der KI standen noch regelbasierte Modelle im Vordergrund, die sich durch den Einsatz von Logik und für den Menschen verständlichen Symbolen auszeichneten („Glass Box“-Modelle). Heute hingegen basieren die aktuell erfolgreicheren Modelle auf probabilistischen Modellen und statistischem Lernen. Der Nachteil der SVM (Support Vector Machines), Random Forests, des Deep Learning und so weiter besteht darin, dass sie eine eigene interne Repräsentanz der Welt beinhalten, die für den Menschen nicht mehr verständlich ist. In diesem Sinne scheint es eine Art „Tauschgeschäft“ zwischen der Genauigkeit (engl. accuracy) der Modelle und ihrer Erklärbarkeit zu geben. Die Modelle werden dabei solange mit Trainingsdaten trainiert, bis sie eine ausreichende Genauigkeit erzielen, um sie dann auf noch unbekannte Ist-Daten anzuwenden. Warum dann ein Modell eine bestimmte Entscheidung trifft, eine bestimmte Empfehlung abgibt oder eine Handlung vollzieht, ist weder dem Modellersteller noch dem Anwender verständlich.
In Abbildung 1 ist im oberen Teil der heutige „Blackbox“-ML-Prozess mit Entscheidung, Empfehlung und Handlung und im unteren Teil der ML-Prozess mit XAI dargestellt. Ähnlich den Expertensystemen verfügen die neuen Modelle über eine Erklärungskomponente mit einem Erklär-Interface als Anwenderschnittstelle, das in der Lage ist, Anwendern die zum Teil nicht trivialen Erklärungen der Modelle zu liefern.
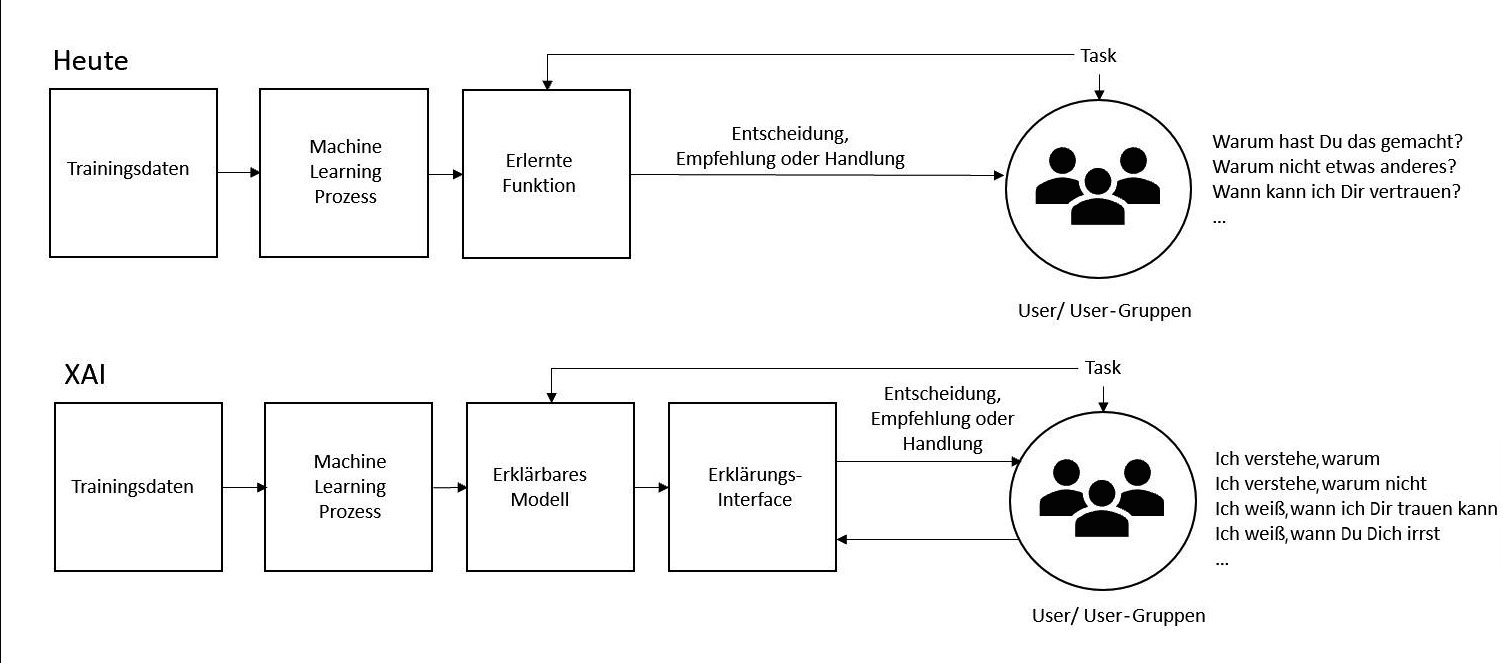
Abb. 1: Unterschied zwischen heute üblichem ML-Prozess und Prozess mit XAI (in Anlehnung an [2])
Einige der Methoden und Herangehensweisen sollen hier kurz vorgestellt werden [3]. Sie nähern sich entweder anhand von erklärbaren Modellen den Ergebnissen der Blackbox-Modelle an oder aber erklären durch Variationen von Daten die Veränderungen der Entscheidungen, Empfehlungen oder Handlungen der Blackbox-Modelle.
LRP (Layer Wise Relevance Propagation)
Dem LRP-Ansatz geht es beispielsweise im Rahmen der Klassifizierung von Bildern und Verwendung von Neuronalen Netzen darum, vom Ergebnis zurück zum Ausgangspunkt beim sogenannten “backward pass“ die Neuronen, die am meisten oder am relevantesten („relevance propagation“) zum Ergebnis beigetragen haben, höher zu gewichten. Das Ergebnis kann dann anhand einer Heatmap, welche die Relevanz der einzelnen Neuronen in unterschiedlicher farblicher Abbildung aufzeigt, dargestellt werden. Wenn etwa mittels eines Neuronalen Netzes eine Klassifizierung von genetischen Daten durchgeführt wird, um zum Beispiel erblich bedingte Erkrankungen vorherzusagen, kann so anhand von LRP erkannt werden, welche Merkmale das Modell stärker als andere bei der Vorhersage beeinflusst haben.
In Abbildung 2 werden oben die Features, die für die Klassifizierung des Bildes herangezogen wurden, dargestellt. Unten gibt die farbliche Hervorhebung der Neuronen (stark vereinfacht) die Stärke der Relevanz der Features wieder, die für die Klassifizierung als „Border Collie“ für das Modell von Bedeutung waren [1].

Abb. 2: Darstellung der Relevanz von Features anhand von „Relevance Propagation“ (vereinfachte Darstellung in Anlehnung an [1])
LIME (Local Interpretable Model Agnostic Explanations)
LIME von Marco Tulio Ribeiro, Sameer Siingh und Carlos Guestrin kann auf jedes Machine Learning-Modell angewendet werden. Es ist modellagnostisch, kann aber ein Modell nur annäherungsweise lokal erklären, also nicht das gesamte Modell. Dabei wird das ursprüngliche Blackbox-Modell lokal begrenzt durch ein interpretierbares Modell ausgetauscht und somit annäherungsweise eine Erklärung für das Ergebnis geliefert. Zunächst werden dazu die Eingabedaten verändert. LIME generiert sodann ein verändertes Dataset mit den veränderten Beispielwerten und den dazugehörigen Prognosen. Auf diesem Dataset wird dann ein interpretierbares Modell angewendet und die Abweichung zum Blackbox-Modell betrachtet.
In Abbildung 3 diagnostiziert das Modell, dass ein bestimmter Patient eine Grippe hat. Anhand von LIME kann die Diagnose/Vorhersage der relevantesten Symptome ermittelt werden. Durch diese Hintergrundinformationen ist der Arzt in der Lage zu entscheiden, ob er dem Modell trauen kann oder nicht.
Die „Counterfactual“-Methode
Ausgangspunkt der „Counterfactual Method“ ist die Annahme, dass es einen kausalen Zusammenhang gibt, der lautet: „Wenn X nicht wäre, dann wäre auch Y nicht“. Statt der tatsächlichen Beobachtung wird nun versucht, das Gegenteil zu denken und das Modell genau mit diesen Werten („counterfactual“ – den Tatsachen widersprechend) zu berechnen. Beispiel: Eine Person möchte eine Wohnung vermieten und die Preisermittlung mithilfe eines ML-Modells berechnen lassen. Dazu verwendet sie Features wie zum Beispiel „Haustiere erlaubt/nicht erlaubt“, „Größe der Wohnung in qm“ oder „Stockwerk“. Wenn sie das Modell mit den tatsächlichen Parameterwerten berechnen lässt und sich ein Mietwert von 500 Euro ergibt, kann diese Person beginnen, die Feature-Werte entsprechend anzupassen, etwa indem sie Features wie „Haustiere erlaubt/nicht erlaubt“ oder die Wohnungsgröße abändert. Die so vorgenommene Änderung kann einen Einfluss auf den berechneten Mietwert haben. Die Person kann somit das Verhalten des Modells besser verstehen [3].
Gesellschaft, Staat und Unternehmen
Florian Sauerwein stellt mit seinem Verantwortlichkeitsnetzwerk einen ersten umfassenden Ansatz vor, bei dem zum Beispiel Regierung, Politik und nichtstaatliche Organisationen eine Mitverantwortung tragen, wenn es um die Auswirkungen des KI-Einsatzes geht [5]. Auf Ebene der Technologie muss über XAI hinaus eine „Accountability by Design“ umgesetzt werden, bei der die Designer sich beispielsweise zu RRI (Responsible Research and Innovation) verpflichten. Unternehmen, die KI einsetzen, dokumentieren ihre soziale Verantwortung etwa mittels CSR (Corporate Social Responsibility). Der Staat hat im Sinne einer Meta-Verantwortlichkeit die Aufgabe, Steuerungsrahmen zu setzen und dabei Regulierungen zu etablieren, wie es sie zum Beispiel für den Schutz der Privatsphäre bereits gibt. Gleiches gilt natürlich auch auf supranationaler Ebene wie der Europäischen Union.
Bezogen auf den Aspekt der Verantwortlichkeit gibt es zudem Überlegungen, für KI-Systeme die Instanz einer „elektronischen Person“ einzuführen. Wenn eine solche „elektronische Person“, etwa ein Roboter, zur Rechenschaft gezogen werden muss, dann müssen gegebenenfalls negative Auswirkungen seines Handelns zum Beispiel im Rahmen einer für ihn geltenden (Haftpflicht-)Versicherung abgedeckt werden.
Doch kann durch ausreichende Transparenz und Verantwortlichkeit auch sichergestellt werden, dass Entscheidungen ethischen und moralischen Gesichtspunkten gerecht werden? Computer beziehungsweise KI-Modelle und -Algorithmen verfügen über kein eingebautes Wertesystem. Bei Modellen oder Algorithmen kann man im Sinne von Hannah Arendt von gewissenhaft gewissenlosen Instanzen, von gehorsamen Ausführungsorganen sprechen. Moral entsteht, so Arendt, erst durch das „Zwiegespräch“ mit sich selbst. So geht es darum, dass eine Person als Mensch bestimmte Dinge nicht durchführt, da die Person danach nicht mehr mit sich selbst im Reinen wäre. All dies ist einem Algorithmus aber völlig fremd. Für die Moral von KI-Algorithmen und -Modellen können daher nur jene Menschen zuständig sein, die sie entwerfen und einsetzen, so Werner Reichmann [4].
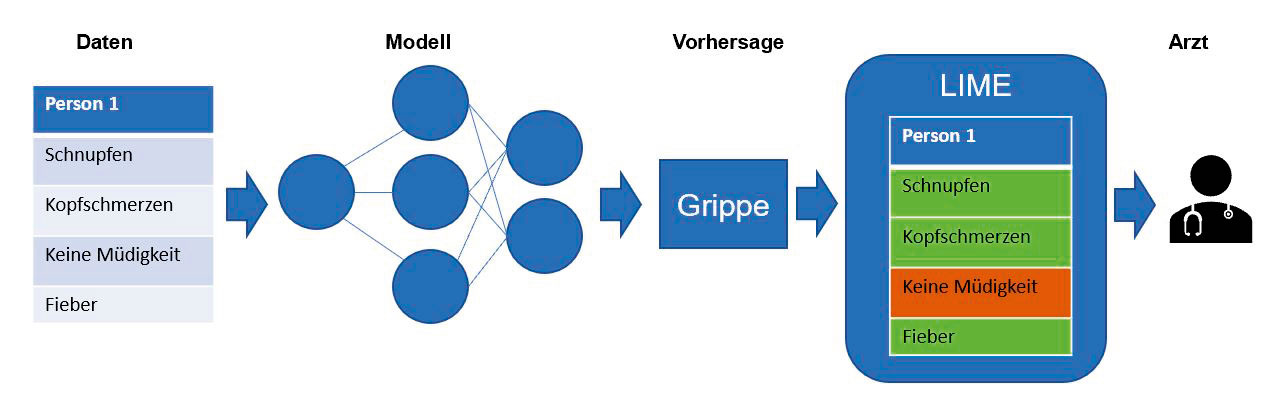
Abb. 3: Erklärung individueller Prognosen für einen menschlichen Entscheidungsträger wie zum Beispiel einen Arzt (in Anlehnung an Marco Tulio Ribeiro [6])
Die von vielen Analysten und Autoren als vierte industrielle Revolution bezeichnete Digitalisierung der Gesellschaft wird ohne Zweifel tiefgreifende Veränderungen mit sich bringen. Sie ist disruptiv, weil sie sich im Wesentlichen ausschließlich mit der Automatisierung und Optimierung von vorhanden Prozessen beschäftigt. Unternehmen, die von den Effizienzvorteilen des Einsatzes Künstlicher Intelligenz profitieren, müssen die sich daraus ergebenden sozialen Kosten mittragen oder übernehmen – etwa bei der Freisetzung von Mitarbeitern und anderen Effekten. Eine Externalisierung und damit Abwälzung der Kosten auf die Gesellschaft, die ohnehin schon durch Alterung und Migration bereits belastet ist, ist sicher zu verhindern.
Auf Ebene der einzelnen Unternehmen geht es im Wesentlichen darum, Prozesse zu automatisieren und zu optimieren, die bisher von Menschen durchgeführt wurden. Allerdings setzen laut einer Studie von PricewaterhouseCoopers (PwC) von 2019 nur rund vier Prozent der befragten Unternehmen in Deutschland bereits Künstliche Intelligenz ein. Dabei geht es zu 70 Prozent um den Bereich der Datenanalyse und um Entscheidungsprozesse. Es ist sogar so, dass 48 Prozent der Befragten das Thema Künstliche Intelligenz als nicht relevant für ihr Unternehmen ansehen.
Fazit
Künstliche Intelligenz bietet eine Fülle an Möglichkeiten, Prozesse und Entscheidungen zu automatisieren und somit effizienter durchzuführen. Um die Chancen der KI zu nutzen, ist es jedoch notwendig, offen und kritisch die Auswirkungen ihres Einsatzes auf allen denkbaren Ebenen zu betrachten und offen zu diskutieren. Die Forderung nach Transparenz, Verantwortlichkeit und Erklärbarkeit der Algorithmen ist daher eine existenzielle Grundforderung, wenn es darum geht, den Empfehlungen, Entscheidungen und Handlungen von KI trauen zu können. KI-Modelle und ihre Algorithmen müssen im Praxiseinsatz auch ethischen und rechtlichen Anforderungen genügen. Nur so kann ein verantwortungsvoller und nachhaltiger Umgang mit Künstlicher Intelligenz gelingen.
Weitere Informationen
[1] Bach (Lapuschkin), Sebastian, Binder, Alexander, Montavon, Grégoire, Klauschen, Frederick, Müller, Klaus-Robert, Samek, Wojciech (2015): On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation, PLoS ONE 10(7): e0130140. https://doi.org/10.1371/journal.pone.0130140
[2] Gunning, David (2016): Broad Agency Announcement Explainable Artificial Intelligence (XAI) DARPA-BAA-16-53, Arlington 2016
[3] Christoph Molnar: https://christophm.github.io/interpretable-ml-book/index.html (abgerufen 31.03.2019)
[4] Reichmann, Werner (2019): Die Banalität des Algorithmus in Rath, Matthias, Krotz, Friedrich, Karmasin, Matthias (Hrsg.) „Maschinenethik, Normative Grenzen autonomer Systeme“, Springer, Wiesbaden, 2019, S. 135- 154
[5] Sauerwein, Florian (2019): Automatisierung, Algorithmen, Accountability. Eine Governance Perspektive in Rath, Matthias, Krotz, Friedrich, Karmasin, Matthias (Hrsg.) „Maschinenethik, Normative Grenzen autonomer Systeme“, Springer, Wiesbaden, 2019, S. 35- 56









