

In der sich schnell entwickelnden Welt des Cloud-Computing verlassen sich Unternehmen zunehmend auf die Flexibilität, Skalierbarkeit und Kosteneffizienz, die Cloud-Plattformen bieten. In dem Maße, wie Unternehmen ihre Anwendungen und Dienste in die Cloud migrieren, müssen sie jedoch auch neue Herausforderungen in Bezug auf Systemzuverlässigkeit, Fehlertoleranz und Ausfallsicherheit bewältigen. An dieser Stelle wird das Chaos Testing in der aktuellen Cloud-Ära unentbehrlich.
Chaos Testing ist eine Disziplin, die sich darauf konzentriert, proaktiv und kontrolliert Fehler und Fehlercluster, das sogenannte "Chaos", in ein System zu injizieren. Es handelt sich um einen gezielten Ansatz zum Testen und Validieren des Systemverhaltens unter erschwerten Bedingungen (Abb. 1). Fehler werden frühzeitig identifiziert und gefixt, bevor sie mit mehr Aufwand in späteren Phasen oder gar im Live-Betrieb gefixt werden müssen.
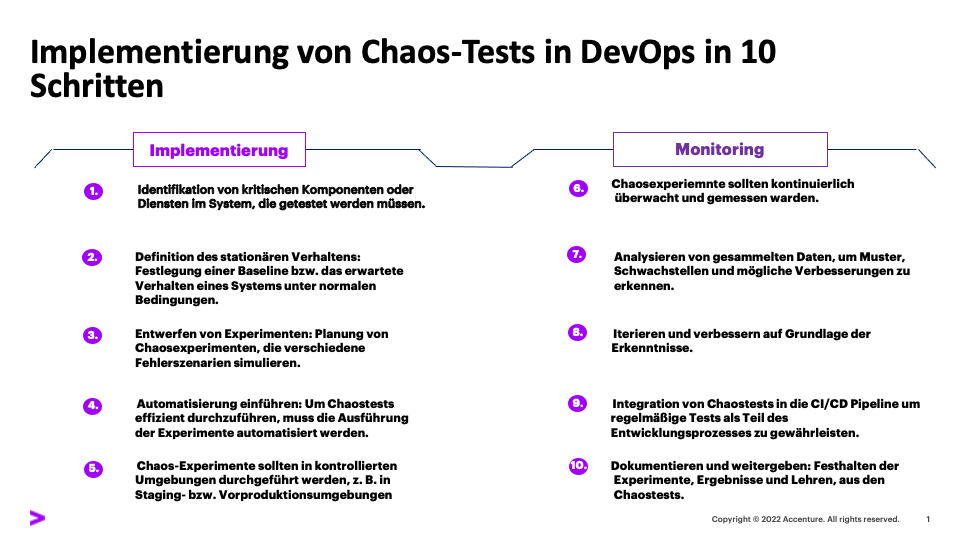
Abb. 1: Implementierung von Chaostests in DevOps in 10 Schritten
Warum Chaos Testing in der Cloud-Ära so wichtig ist
Als Beispiel für Chaos Testing sei "Chaos Kong" genannt. Dabei wird simuliert, wie sich das System verhält beziehungsweise erholt, wenn eine vollständige AWS-Region gelöscht wird, indem der Datenverkehr ohne Leistungseinbußen in eine andere Region übertragen wird. Chaos Engineering geht noch eine Ebene weiter. Es werden bewusst Thesen aufgestellt, um Zuverlässigkeit, Ausfallsicherheit, Performance, Sicherheit und Resilienz aktiv zu verbessern. Chaos Engineering geht dabei fließend ins Quality Engineering über, das einen holistischen Ansatz bietet, um die Qualität von Systemen ganzheitlich zu analysieren und zu verbessern.
Chaos Testing beziehungsweise Chaos Engineering gibt es seit längerem auch in On-Premises-Systemen. Im Zusammenhang mit Cloud-Computing haben sie aus mehreren Gründen zusätzlich stark an Bedeutung gewonnen:
Komplexität verteilter Systeme
Cloud-Umgebungen sind auf verteilten Systemen aufgebaut, die verschiedene miteinander verbundene Komponenten, Dienste und Infrastrukturebenen umfassen. Die Komplexität dieser Systeme macht es schwierig vorherzusagen, wie sie sich unter verschiedenen Szenarien und Fehlerbedingungen verhalten werden. Mit Chaostests können Unternehmen Einblicke in das Verhalten ihrer verteilten Systeme unter Stress und bei Fehlern gewinnen und so Schwachstellen aufdecken, die sonst unbemerkt bleiben würden.
Erhöhte Skalierbarkeit und Dynamik
Cloud-Plattformen bieten eine hohe Skalierbarkeit, die es Unternehmen ermöglicht, Ressourcen je nach Bedarf schnell hoch- oder herunterzufahren. Die Dynamik und der Umfang von Cloud-Umgebungen machen es jedoch schwierig, die Systemzuverlässigkeit zu validieren. Chaostests helfen Unternehmen zu verstehen, wie sich ihre Systeme verhalten, wenn sie plötzlichen Lastspitzen, der Erschöpfung von Ressourcen oder Schwankungen der Netzwerkbedingungen ausgesetzt sind. Durch die Simulation solcher Szenarien in einer kontrollierten Umgebung können Unternehmen Probleme proaktiv angehen und sicherstellen, dass ihre Systeme mit der dynamischen Natur der Cloud umgehen können.
Abhängigkeiten von Drittanbietern
Cloud-basierte Anwendungen sind oft auf mehrere Dienste und APIs von Drittanbietern angewiesen, um ihre Funktionen bereitzustellen. Diese Abhängigkeiten führen zu einer zusätzlichen Ebene der Komplexität und zu potenziellen Fehlerquellen. Mit Chaostests können Unternehmen die Auswirkungen von Ausfällen oder Leistungseinbußen bei diesen externen Diensten abschätzen und so geeignete Ausweichmechanismen oder alternative Dienstanbieter implementieren. Indem sie die Widerstandsfähigkeit ihrer Systeme gegen Ausfälle von Drittanbietern validieren, können Unternehmen das Risiko von Serviceunterbrechungen minimieren und die User Experience verbessern.
Kontinuierliche Bereitstellung und DevOps-Kultur
In der Cloud-Ära setzen Unternehmen zunehmend auf eine neue DevOps-Kultur, um Software-Updates und neue Funktionen mit CI/CD/CT-Pipelines per Continuous Integration, Continuous Deployment und Continuous Testing schneller bereitstellen zu können. Dies kann jedoch zu unvorhergesehenen Problemen bezüglich der Systemzuverlässigkeit führen. Chaostests fügen sich gut in ein DevOps-Vorgehen ein, da sie kontinuierliche Validierungen und Experimente in die Entwicklungs- und Bereitstellungs-Pipelines integrieren.
Geschäftskontinuität und Kundenvertrauen
Für Unternehmen, die in der Cloud arbeiten, können Ausfallzeiten oder Serviceunterbrechungen schwerwiegende finanzielle und rufschädigende Folgen haben. Die Erwartungen der Kunden an eine 24/7-Verfügbarkeit und einen ununterbrochenen Service waren noch nie so hoch. Chaostests helfen Unternehmen bei der Validierung ihrer Business-Continuity-Pläne und stellen sicher, dass ihre Systeme Ausfällen standhalten und sich ohne nennenswerte Beeinträchtigung der Kundenerfahrung erholen können. Dadurch können Unternehmen das Vertrauen ihrer Kunden auf dem wettbewerbsintensiven Cloud-Markt sichern.
Proaktive Wartung
Zu guter Letzt: Eine belastbare Cloud-Struktur erfordert eine kontinuierliche Überwachung und proaktive Wartung, um potenzielle Schwachstellen oder Leistungsengpässe zu identifizieren und schnellstmöglich zu beheben. Regelmäßige Audits, Sicherheitsbewertungen und Systemaktualisierungen sind unerlässlich, um die Infrastruktur robust und auf dem neuesten Stand zu halten.
Wie man Cloudstrukturen widerstandsfähiger macht – ein kurzer Leitfaden
Der Aufbau belastbarer Cloud-Strukturen ist unerlässlich, um die Verfügbarkeit, Skalierbarkeit und Zuverlässigkeit von cloud-basierten Diensten zu gewährleisten. Wenn Sie Ihre Cloud-Infrastruktur mit Blick auf die Ausfallsicherheit konzipieren, können Sie Ausfallzeiten und Unterbrechungen bei unvorhergesehenen Ereignissen minimieren. Der folgende Leitfaden hilft Ihnen, Ihre Cloud-Strukturen widerstandsfähiger zu machen.
- Verteilte Architektur:
Verteilen Sie Ihre Anwendungen und Dienste über mehrere Availability Zones (AZs) und Rechenzentren. Dadurch wird ein Single Point of Failure verhindert und die Redundanz erhöht. - Lastausgleich:
Implementieren Sie einen Lastausgleich über mehrere Instanzen und Availabilty Zones hinweg, um den Datenverkehr gleichmäßig zu verteilen und eine Überlastung einer einzelnen Komponente zu verhindern. - Automatisierte Skalierung:
Verwenden Sie Auto-Scaling-Gruppen, um die Anzahl der Instanzen automatisch an den Bedarf anzupassen. Dadurch wird sichergestellt, dass Ihre Anwendungen unterschiedliche Arbeitslasten ohne manuelle Eingriffe bewältigen können. - Datenredundanz und Backup:
Speichern Sie wichtige Daten in unterschiedlichen Brand -abschnitten beziehungsweise an mehreren geografischen Standorten, um sich vor Datenverlusten bei regionalen Ausfällen zu schützen. Sichern Sie Ihre Daten regelmäßig in einer anderen Region oder bei einem anderen Cloud-Anbieter, um die Wiederherstellbarkeit im Falle eines katastrophalen Ausfalls zu gewährleisten. - Überwachung und Warnungen:
Richten Sie ein umfassendes Monitoring für alle Komponenten Ihrer Cloud-Infrastruktur ein. Verwenden Sie Cloud-native Überwachungsdienste, um Leistungskennzahlen, Nutzung und mögliche Engpässe zu verfolgen. Konfigurieren Sie Warnungen, um Ihr Betriebsteam zu benachrichtigen, wenn vordefinierte Schwellenwerte überschritten werden, sodass es sofort Maßnahmen ergreifen kann. - Isolierung von Fehlern:
Nutzen Sie die Microservices-Architektur, um verschiedene Komponenten Ihrer Anwendung zu isolieren. Wenn ein Microservice ausfällt, wird dadurch nicht die gesamte Anwendung beeinträchtigt. - Graceful Degradation:
Entwerfen Sie Ihre Anwendungen so, dass sie mit Teilausfällen umgehen können und die Funktionalität ordnungsgemäß abgebaut wird, wenn bestimmte Dienste nicht mehr verfügbar sind. Die Benutzer sollten dadurch auch bei Ausfällen noch auf wichtige Funktionen zugreifen können. - Plan für die Wiederherstellung im Katastrophenfall (DR):
Entwickeln Sie einen umfassenden Notfallwiederherstellungsplan, der Prozesse im Zusammenhang mit Rollenkonzepten bei größeren Ausfällen oder Störungen festlegt. Testen und aktualisieren Sie diesen Plan regelmäßig, wenn sich Ihre Infrastruktur weiterentwickelt. - Containerisierung und Orchestrierung:
Nutzen Sie Containerisierungsplattformen wie Docker und Container-Orchestrierungstools wie Kubernetes, um die Flexibilität und Portabilität der Bereitstellung zu verbessern. Dies ermöglicht eine bessere Ressourcennutzung und eine einfachere Skalierung. - Hochverfügbare Datenbanken:
Wählen Sie Datenbanklösungen, die Replikation und automatische Ausfallsicherung unterstützen. Dies gewährleistet die Datenverfügbarkeit und verringert das Risiko von Datenverlusten bei Ausfällen. - Sicherheit und Zugriffskontrolle:
Implementieren Sie robuste Sicherheitsmaßnahmen, um Ihre Cloud-Infrastruktur vor unbefugtem Zugriff, Datenverletzungen und anderen Bedrohungen der Cybersicherheit zu schützen. - Regelmäßige Disaster-Recovery-Übungen:
Führen Sie regelmäßige Notfallübungen durch, um die Wirksamkeit Ihrer Ausfallsicherheitsstrategie zu testen und sicherzustellen, dass Ihr Team auf potenzielle Katastrophen gut vorbereitet ist. - Redundanz der Cloud-Anbieter:
Ziehen Sie die Nutzung einer Hybrid-Cloud-Strategie (Private und Public Cloud) und oder einer Multi-Cloud-Strategie (mehrere Cloud-Anbieter) in Betracht, um Ihr Infrastrukturrisiko zu diversifizieren. Dieser Ansatz mildert die Auswirkungen eines vollständigen Ausfalls eines einzelnen Cloud-Anbieters. - Dokumentation und Wissensaustausch:
Dokumentieren Sie alle Aspekte Ihrer widerstandsfähigen Architektur und geben Sie das Wissen an Ihr Team weiter. Dadurch wird sichergestellt, dass jeder mit der Ausfallsicherheitsstrategie vertraut ist und bei Zwischenfällen effektiv reagieren kann.
Wenn Sie diese Best Practices befolgen, können Sie Ihre Cloud-Strukturen widerstandsfähiger machen und die Auswirkungen von Ausfällen minimieren, um eine stabile und zuverlässige Erfahrung für Ihre Nutzer und Kunden zu gewährleisten.
Der Aufbau einer widerstandsfähigen Cloud-Struktur ist allerdings mit zusätzlichen Kosten für redundante Hardware, Datenreplikation und Disaster-Recovery-Lösungen verbunden. Diese Investitionen können vor allem für kleine und mittlere Unternehmen mit begrenzten Budgets eine finanzielle Herausforderung darstellen. Unternehmen müssen ihren Bedarf sorgfältig prüfen und ein Gleichgewicht zwischen Kosten und dem erforderlichen Grad an Ausfallsicherheit herstellen. Eine effektive Ressourcenzuweisung und Kapazitätsplanung sind entscheidend, um die Infrastrukturkosten zu optimieren, ohne das gewünschte Maß an Ausfallsicherheit zu gefährden.
Implementierung von Chaostests in DevOps
Durch die Integration von Chaostests in Ihren DevOps-Prozess können Sie proaktiv Schwachstellen in der Belastbarkeit Ihres Systems erkennen und beheben, was zu einer verbesserten Gesamtzuverlässigkeit und Robustheit führt. Eine Checkliste von 10 Schritten (vgl. Abbildung 1) zeigt auf, wie Chaostests implementiert werden.
Fazit
Chaos ist nicht gleich Chaos. Denn wer das Chaos kontrolliert, kontrolliert letztendlich auch seine Cloud-nativen Architekturen. Mit der Durchführung von Chaos Testing und holistischem Chaos Engineering können Unternehmen proaktiv Schwachstellen in ihren Cloud-nativen Architekturen identifizieren und beheben. Dieser iterative und kontinuierliche Testansatz hilft bei der Aufdeckung potenzieller Fehlerquellen und stellt sicher, dass die Systeme unerwarteten Ereignissen wie Netzwerklatenz, Ressourcenerschöpfung oder Softwarefehlern standhalten können. Durch die Chaos-Experimente erhalten Entwickler, Quality Engineers und Architekten wertvolle Einblicke in das Systemverhalten, sodass sie die Infrastruktur und die Anwendungskomponenten für eine verbesserte Fehlertoleranz feinabstimmen können.
Chaos Testing, inspiriert von Netflix' Chaos Monkey, ermöglicht es heute Unternehmen, außergewöhnliche Benutzererfahrungen zu liefern, sich an wechselnde Anforderungen anzupassen und das volle Potenzial von Cloud-Technologien zu erschließen – und all das durch den Chaos-Effekt, der auftritt, wenn das System unter Stress gesetzt wird. Kreatives Chaos findet somit nicht nur in künstlerischen Disziplinen, sondern auch in der IT eine neue Heimat.









