

Ein Konzept, das im Analytics-Umfeld in der letzten Zeit merklich an Sichtbarkeit gewonnen hat, ist DataOps. Hinter DataOps steht die Idee, den aus dem Feld des IT-Managements stammenden DevOps-Ansatz auf den Datenbereich zu portieren [Ere18]. Eckpfeiler von DevOps sind eine enge Kooperation zwischen der Entwicklung und dem Betrieb von IT-Lösungen, eine Professionalisierung und Automatisierung von deren Bereitstellung sowie eine Verstetigung der Weiterentwicklung. Im Fokus stehen vor allem die kontinuierliche Integration neuer Komponenten in ein laufendes System (Continuous Integration), die bruchlose Auslieferung von Software (Continuous Delivery), ein weitgehend automatisiertes Testen sowie eine softwarebasierte Spezifikation, Administration und Versionierung aller Systemkomponenten (Infrastructure as Code) [Ebe16; Kim22]. Das Thema wird außerdem mit einer starken Tool-Unterstützung sowie definierten und automatisierten Prozessen zur Softwarebereitstellung – sog. Pipelines – assoziiert [Kro23].
Ohne Weiteres lassen sich diese Ansätze nicht auf den Analytics-Kontext übertragen, da Analytics-Prozesse häufig deutlich unstrukturierter, kreativer und unvorhersehbarer ablaufen als klassische Softwareentwicklungen. Eine Konsequenz dieser Besonderheiten ist, dass das Konzept „DataOps“ weiterhin unscharf ist und die unter DataOps diskutierten Konzepte und Werkzeuge sehr heterogen erscheinen. Ohne Zweifel sind allerdings eine enge Zusammenarbeit der Entwicklung und des Betriebs von Modellen und Berichten sowie eine softwaregestützte Professionalisierung und Automatisierung auch im Datenumfeld erstrebenswert [Mun20].
Unabhängig davon fällt auf, dass die DataOps-Diskussion stärker von organisatorischen Maßnahmen geprägt wird. Die DevOps-Grundidee wird hierbei so interpretiert, dass auch Analyse- und Berichtsprozesse ganzheitlich betrachtet werden – von der Idee für ein Datenprodukt bis hin zu dessen kontinuierlicher Pflege. Aus den allgemeinen „Pipelines“ werden so „Daten-Pipelines“, für deren Gestaltung Data Engineers, Data Scientists und Data Analysts in definierten Prozessen effizient und agil zusammenarbeiten sollen. Weitere Empfehlungen bestehen darin, die zugrunde liegende Datenhaltungs- und -analyselandschaft an der Infrastructure-as-Code-Idee auszurichten, alle Datenprodukte systematisch und möglichst automatisiert zu testen und zu versionieren sowie eine übergreifende Metadatenhaltung insbesondere mit Data-Catalog-Werkzeugen aufzubauen.
Es stellt sich die Frage, wie sich die DataOps-Ideen speziell in einem Self-Service-Analytics-Umfeld umsetzen lassen, das bis zu einem gewissen Grad als Personalunion von Lösungsentwickler, -betreiber und -benutzer verstanden wird. Auf den ersten Blick scheinen die beiden Ansätze fast gegensätzlich – das auf Professionalisierung und Standardisierung setzende DataOps auf der einen Seite und das auf kreativen Individuallösungen fußende Self-Service Analytics auf der anderen.
Eine Einzelfallstudie
Ein mittelgroßer deutscher Automobilhersteller (OEM) hat versucht, zusammen mit uns zu Antworten zu kommen und zu eruieren, in welchen Fällen die Konzepte Self-Service Analytics und DataOps sinnvoll kombiniert werden können sowie welche Potenziale daraus resultieren.
Hervorzuheben ist, dass der Automobilhersteller bereits eine gleichermaßen ausgereifte wie moderne Business-Intelligence- und Analytics-Landschaft mit einem Data Warehouse und einem cloudbasierten Data Lake betreibt. Betreut werden die Systeme von einem in der IT aufgehängten agilen Team mit breitem Data-Engineering- und Analyse-Know-how (Data & Analytics). Die Zusammenarbeit zwischen den Fachbereichen und Data & Analytics ist bereits eng, es wächst allerdings der Bedarf, die Betreuung prozessual „End-to-End“ aufzuziehen, so wie es auch im DataOps-Ansatz vorgesehen ist. Self-Service Analytics hat im Unternehmen bereits fast alle betrieblichen Funktionen erreicht, was es uns ermöglichte, sieben Self-Service-Analytics-erfahrene Power-User aus heterogenen Fachabteilungen zu interviewen (vgl. Tabelle 1). Deren verwendungsorientierte Perspektive haben wir mit der Sicht der zentralen IT-Abteilung kontrastiert, wofür wir einen separaten Workshop durchgeführt haben, an dem unterschiedliche IT-Rollenträger beteiligt waren, insbesondere CIO, Head of Data & Analytics, IT-Governance und IT-Operations. In dem Workshop haben wir vor allem übergreifende Fragen der IT-Unterstützung thematisiert, primär zur Standardisierung, zur Datensicherheit oder zum Metadatenmanagement.
| Fachbereich (FB) | Schwerpunkte des Self-Service-Analytics-Einsatzes |
|---|---|
| FB1: Vertriebscontrolling | Datenkonsolidierung und Analyse insbesondere von Vertriebs- und Marktdaten |
| FB2: Erlöscontrolling | Ad-hoc-Analysen für das Erlöscontrolling mit Daten aus verschiedenen Quellsystemen |
| FB3: After Sales | Analyse von Fehlermeldungen und Beanstandungen von Fahrzeugen (insbesondere Clustering) |
| FB4: Forschung & Entwicklung (R&D) für die Komponentenentwicklung im Antriebsstrang | Statistische Auswertungen von Fahrzeugdaten für die kontinuierliche Verbesserung der Fahrzeugentwicklung |
| FB5: Produktion und Montage | Konstantes Qualitätsmonitoring sowie deskriptive Fehleranalyse |
| FB6: Logistik | Optimierung der Lagerbestände |
| FB7: Marketing und Sales | Analyse und Planung von Fahrzeugbeständen in verschiedenen Märkten |
Betrachtet man die Self-Service-Anwendungen der verschiedenen Fachbereiche näher, so wird deren erhebliche Heterogenität deutlich:
FB1: Für das Vertriebscontrolling stellt die zentrale Data&Analytics-Einheit Daten aus heterogenen Systemen aus den Bereichen Finanzen, Einzelhandel und Marketing in einem auf den Vertrieb ausgerichteten Data Mart bereit. Die zu analysierenden Daten sind bereits transformiert, die Erstellung von Dashboards liegt jedoch vollständig in der Hand der Benutzer.
FB2: In FB2 wird insbesondere das Erlöscontrolling per Self-Service unterstützt und hier vor allem die Analyse von Sonderausstattungen. Die von den Benutzern generierten Berichte werden primär auf der Grundlage dateibasierter Quellsysteme generiert. Im Gegensatz zu FB1 liegen die Hauptherausforderungen für die Benutzer in der Datenextraktion und -transformation.
FB3: Die auszuwertenden Daten für den Bereich After Sales stammen hauptsächlich aus einem einzelnen System. Hierin werden Freitexte zu Beschwerden gesammelt, die aus den über den Globus verteilten Werkstätten stammen. Der Interviewpartner verwendet Cluster-Analyse-Techniken, um Beschwerden zu gruppieren.
FB4: Wie in FB3 werden die relevanten Daten auch in FB4 primär aus einem einzelnen System extrahiert. Die Datenstrukturen sind jedoch sowohl komplex als auch heterogen (Messdaten von Fahrzeugen). Außerdem sind die Datenmengen groß und jede Analyse ist hochindividuell. Dies reduziert sowohl das Potenzial zur Automatisierung der Datenanalyse als auch den möglichen Beitrag der zentralen Data&Analytics-Einheit über die reine Datenbereitstellung hinaus.
FB5: Für die Überwachung der Produktions- und Montageprozesse wird auf eine Vielzahl von (oft eingebetteten) IT-Quellsystemen unterschiedlicher Anbieter zurückgegriffen, was zu erheblichen Herausforderungen bei der Datenextraktion und -integration führt. Speziell bei individuellen Fehleranalysen werden aufwendige (halb-)manuelle Datenaufbereitungsschritte erforderlich.
FB6: Die notwendigen Daten für die Optimierung der Lagerbestände stammen aus einem einzigen, zentral verwalteten SAPTM-System mit hoher Datenqualität. Die Herausforderung besteht darin, die Daten so aufzubereiten, dass sie für die Lagermitarbeiter rechtzeitig als verständliche Informationen bereitgestellt werden können.
FB7: Der Bereich Marketing und Sales hat Zugriff auf ein Data Warehouse, das von der Data&Analytics-Einheit zur Verfügung gestellt wird. Wie im Anwendungsfall von FB1 entwickeln die Benutzer ihre eigenen Dashboards. Darüber hinaus werden hier jedoch häufig zusätzliche Datenquellen hinzugefügt, insbesondere solche aus dateibasierten Quellen (zum Beispiel mit Tabellenkalkulationen). Zu diesem Zweck entwickeln die Benutzer individuelle ETL-Strecken.
Hervorzuheben ist, dass alle beschriebenen Aufgaben von regulären Mitarbeitern aus den Fachbereichen übernommen werden und nicht von professionellen Datenanalysten oder Data Scientists. Das gilt auch für die Fälle mit komplexeren Datentransformationen (FB2, FB4, FB5, FB7) und anspruchsvolleren Analysen (FB3, FB4). Für die Analyseaufgaben gibt es bislang weder einen standardisierten Prozess noch ein festes Toolset. Die Benutzer setzten auf so unterschiedliche Werkzeuge wie MS ExcelTM, TableauTM, Tableau PrepTM, KNIMETM, spezifische Tools zur Analyse von Engineering-Daten, aber auch auf VBA- und Python-Programmierung. Die erhebliche Varianz der im Self-Service übernommenen Aufgaben macht es schwer, weitreichende Prozessstandardisierungen umzusetzen, wie dies im DataOps-Ansatz eigentlich angestrebt wird. Die Unterschiede betreffen neben den konkreten Aufgabeninhalten auch
- die Komplexität der Analysen,
- die Art, die Anzahl und die Homogenität der zu integrierenden Datenquellen,
- die Art der Systemanbindung, die Datenformate und die Datenqualität sowie
- den Bedarf für Flexibilität und Ad-hoc-Auswertungsmöglichkeiten.
Viele der im Self-Service übernommenen Aufgaben erfordern aufgrund ihrer Individualität, ihrer Spezifität und ihres Agilitätsbedarfs einen hohen Grad an Benutzerautonomie. Gleichzeitig stellen vor allem das Auffinden und Aufbereiten relevanter Datenquellen die Benutzer oftmals vor erhebliche Herausforderungen. Auch bei der Weitergabe und Wiederverwendung der generierten Berichte und Analysen besteht noch erhebliches Verbesserungspotenzial. Die entsprechenden Aufgaben binden große Ressourcen und gehen mit massiven Doppelarbeiten einher. Zudem droht die Data&Analytics-Einheit trotz einer engmaschigen Betreuung der Benutzer den Überblick zu verlieren, welche Zusammenhänge zwischen den verschiedenen, von den Benutzern verantworteten Datenversorgungssträngen bestehen.
Erkenntnisse
Bezogen auf die Mehrwerte eines kombinierten Self-Service-/DataOps-Einsatzes, die damit verbundenen Herausforderungen und mögliche Lösungsansätze konnten wir die folgenden sechs Kernerkenntnisse extrahieren:
Erkenntnis 1:
Die Heterogenität der Analytics-Aufgaben macht einen Self-Service-Analyseansatz erforderlich, der allerdings eine enge und kontinuierliche Zusammenarbeit mit der zentralen IT bei der Bereitstellung der Tools, eine Begleitung der Analysen sowie eine Unterstützung beim Austausch von generierten Berichten und Modellen erfordert. Für Letzteres wäre ein möglichst weitgehend automatisiertes Continuous Deployment im Sinne von DevOps/DataOps hilfreich.
Erkenntnis 2:
Eine professionalisierte Datenbereitstellung ist essenziell für einen effizienten Self-Service-Ansatz. Die gemeinsame Spezifikation und das Management definierter Pipelines durch Benutzer und Data&Analytics-Einheit kann potenziell Ressourcen für neue, weitergehende Analysen freisetzen.
Erkenntnis 3:
Eine strikte, auf Analytics ausgerichtete Data Governance für die gesamte Datenlandschaft des Unternehmens legt den Grundstein für einen tragfähigen Self-Service-Ansatz. Diese sollte auch potenzielle Datenquellen wie Maschinen oder Sensoren umfassen und deren spätere Einbindung in Daten-Pipelines gedanklich vorwegnehmen – gewissermaßen eine Continuous Integration neuer Datenquellen.
Erkenntnis 4:
Effizienzgewinne lassen sich auch erzielen, wenn die zentrale Data&Analytics-Einheit Regelungen zur Entwicklung und Dokumentation von Daten-Pipelines erstellt und überwacht, um so Doppelarbeiten zu vermeiden.
Erkenntnis 5:
Ein systematisches Metadatenmanagement ist eine Voraussetzung für Self-Service Analytics in einem Unternehmen – und sollte Teil eines DataOps-Ansatzes sein.
Erkenntnis 6:
Aufgrund der Besonderheiten der analytischen Aufgaben sind Self-Service-Analysen selten mit automatisierten Testroutinen kompatibel. Trotzdem ist das Testing ein wichtiger Bestandteil der Generierung von Berichten und Modellen, da darauf aufbauende (Fehl-)Entscheidungen durchaus gravierende Konsequenzen haben können. In diesem Fall haben sich bei mehreren Befragten Validierungen durch Peers und/oder Experten als geeignete Alternative zu automatisierten Tests erwiesen.
Abbildung 1 stellt diese sechs Erkenntnisse noch einmal im Überblick dar. Eine übergreifende Schlussfolgerung konnten wir im Workshop sowie späteren Folgeterminen weiter vertiefen: Die Einführung eines DataOps-Ansatzes hat das Potenzial, die Zusammenarbeit zwischen den Fachbereichen und der zentralen Data&Analytics-Einheit neu auszutarieren. So können Pipelines zur Datenbereitstellung aus eingebetteten Systemen von (ungewollten) Self-Service-Aufgaben bei der Datenbereitstellung befreien (FB5) und würden so in den Verantwortungsbereich der zentralen IT zurückwandern. Bei FB4 hingegen würde eine stärkere Begleitung und Automatisierung der Datentransformationen komplex strukturierter Messdaten Ressourcen freisetzen, die für zusätzliche Analysen genutzt würden. Somit würde hier der Self-Service-Bereich noch ausgeweitet.
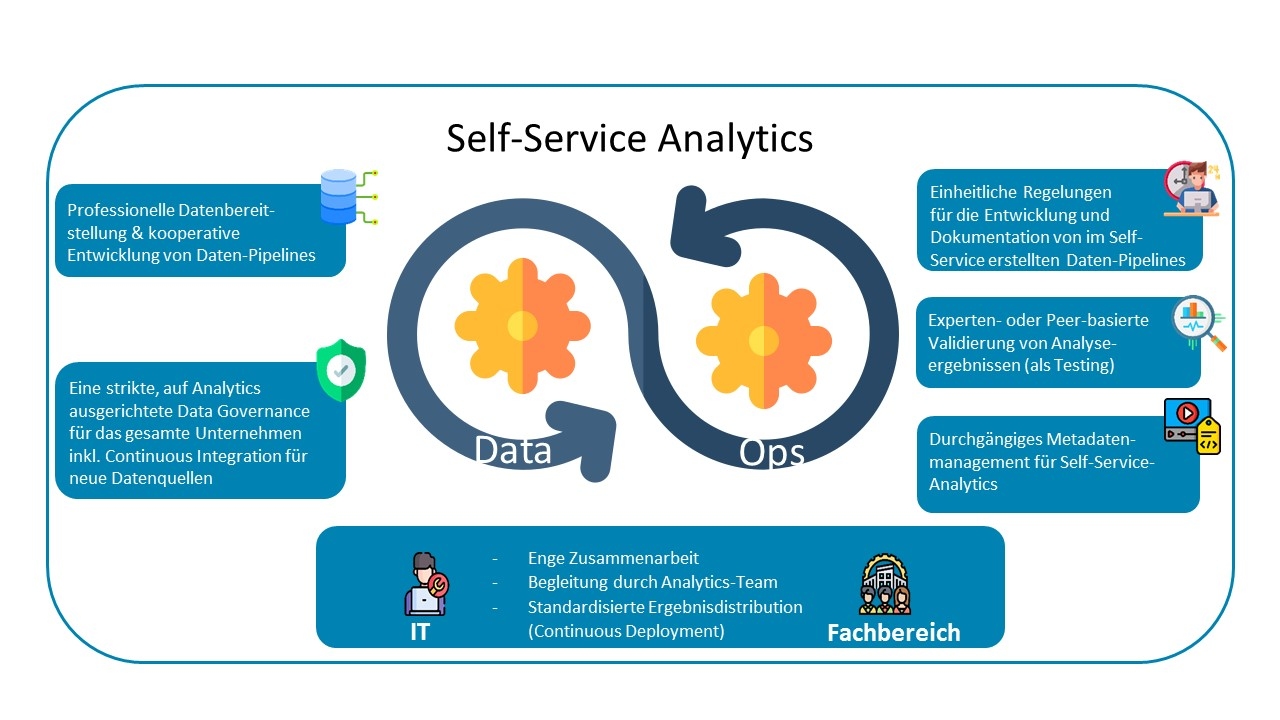
Abb. 1: Erkenntnisse aus der Studie
Insgesamt lässt sich festhalten, dass die bereits intensive Zusammenarbeit zwischen der Data&Analytics-Einheit und den Self-Service-Nutzern noch ausgebaut werden kann – sowohl bei der Datenbereitstellung als auch bei der Aufbereitung und Verteilung der Analyseergebnisse. Dabei können definierte Daten-Pipelines mit einer individuell abgestimmten Aufteilung der Zuständigkeiten zwischen zentraler IT und Fachbereich Entlastungen schaffen. Gleichzeitig legt eine strikte Governance, die eine Analyseorientierung aller potenziellen Datenquellen, die expertenbasierte Validierung der Ergebnisse sowie eine durchgängige (möglichst automatisierte) Metadatenbereitstellung das Fundament für den weiteren Analytics-Ausbau. Tatsächlich wurden im konkreten Fall bereits erste Schritte in diese Richtung eingeleitet – und zwar gemeinsam von der IT und den Power-Usern der Fachbereiche. Die DataOps-Ideen können insofern relevante Impulse für einen Self-Service-Ansatz liefern – und werden mit der zunehmenden Durchdringung der Unternehmen durch KI und damit der Notwendigkeit zur Integration von Analytics in die operative IT noch weiter befördert.
Weitere Informationen
[Ebe16] Ebert, C. et al.: DevOps. IEEE Software, 33(3), 2016, S. 94–100
[Ere18] Ereth, J.: DataOps – Towards a Definition. In: Proceedings of the Lernen, Wissen, Daten, Analysen, LWDA, CEUR Workshop Proceedings, 2018, 2191, Paper 13, S. 104–112
[Kim22] Kim, G. et al.: Das DevOps-Handbuch: Teams, Tools und Infrastrukturen erfolgreich umgestalten. O’Reilly 2022
[Kro23] Krohn R.: Überlegungen zu deiner DevOps-Toolkette.
https://www.atlassian.com/de/devops/devops-tools/choose-devops-tools, abgerufen am 12.5.2023
[Mun20] Munappy, A. R. et al.: (2020), From Ad-Hoc Data Analytics to DataOps. In: Proceedings International Conference on Software and System Processes, ICSSP20, Seoul, Republic of Korea, 2020, S. 165–174









