

Datenqualität bezeichnet die Gesamtheit der Ausprägungen von Qualitätsmerkmalen eines Datenbestandes bezüglich dessen Eignung, festgelegte und vorausgesetzte Erfordernisse zu erfüllen [HGM21]. Ein bekannter Ansatz zur Strukturierung der Datenqualitätsmerkmale ist die Unterteilung in die drei Hauptmerkmale mit insgesamt elf Untermerkmalen [Eng99]:
- Qualität der Datendefinition (Datenspezifikation, Geschäftsregeln, Integritätsbedingungen)
- Inhaltliche Datenqualität (Korrektheit der Datenwerte, Vollständigkeit, Eindeutigkeit, Einhaltung der Geschäftsregeln, Genauigkeit und Fehlerfreiheit)
- Qualität der Datenpräsentation (Rechtzeitige Bereitstellung, Angemessenheit des Formats, Verständlichkeit des Formats)
Dabei hat die Bedeutung einer hohen Datenqualität in den letzten Jahren zugenommen, da gute Daten insbesondere durch KI immer mehr Anwendungsszenarien finden. Doch häufig scheitern KI-Vorhaben aufgrund zu geringer Datenqualität. Dabei sind die Gründe für schwache Datenqualität breit gefächert und lassen sich in die nicht ganz trennscharfen Kategorien organisatorisch, fachlich und technisch bedingt einteilen (Abbildung 1). Als Erstes muss der organisatorische und fachliche Rahmen für das Arbeiten mit Daten geklärt werden, bevor Probleme mit technischem Ursprung gelöst werden. Eine gute Zusammenfassung von Best Practices bietet das Buch [DAM17].
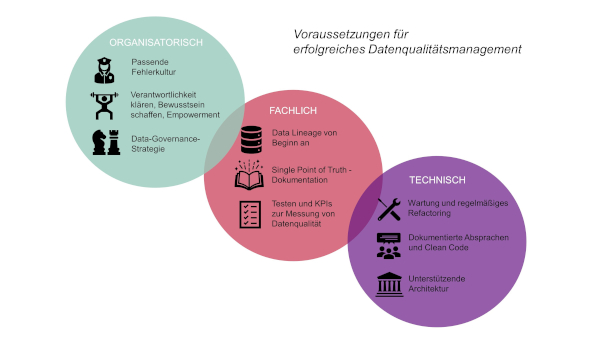
Abb.1: Vorraussetzungen fuer erfolgreiches Datenqualitaetsmanagement
Organisatorische Ebene
Jedes Unternehmen, das Daten sammelt und Entscheidungen auf Basis dieser Daten trifft, muss organisatorische Maßnahmen zur Erhaltung der Datenqualität ergreifen. Dabei ist es ein entscheidender Faktor, im Rahmen einer Data-Governance- Strategie klare Rollen, Verantwortlichkeiten und Prozesse im Umgang mit Daten zu definieren. Denn nur wenn ein Bewusstsein für Verantwortlichkeiten gegeben ist und die Verantwortlichen auch das nötige Know-how zur Beurteilung der Datenqualität besitzen, kann auch systematisch Problemen entgegengewirkt werden.
Ein derzeit viel diskutierter Ansatz zur Verteilung und Demokratisierung von Verantwortlichkeiten ist Data Mesh. Dieser ist vor allem durch folgende Prinzipien charakterisiert [MCS2022; Deh22]:
- Dezentralisierung: Die Datenverantwortlichkeit liegt nicht bei einem zentralen Team, das potenziell zu wenig Ressourcen und Wissen hat, um alle Fragestellungen rund um die Datenqualität zu beantworten. Stattdessen werden die Verantwortlichkeiten auf unterschiedliche und im besten Fall cross-funktional besetzte Teams aufgeteilt. Die Idee dahinter ist, das im Unternehmen vorhandene Wissen effizienter zu nutzen, damit weniger Engpässe bei der Analyse und Behebung von Problemen entstehen.
- Produktdenken: Teilmengen der Daten werden als Produkte betrachtet, die durch unabhängige Produktteams auf einer zentralen Plattform aufbereitet und anderen Produkten über eine standardisierte Schnittstelle bereitgestellt und zum Beispiel per SQL abgefragt werden können. Die Last auf die einzelnen Teams soll dadurch überschaubarer und die Qualität der bereitgestellten Datenprodukte besser werden. Die Bereitstellung manueller Datenexporte, die für eine Vielzahl von Datenqualitätsproblemen sorgen, soll minimiert werden.
Der entgegengesetzte Ansatz zum Data Mesh ist das klassische, zentrale Data Warehouse. Je nach Unternehmensgröße kann dieser Ansatz vorteilhaft gegenüber dem Data Mesh sein, da es prinzipiell leichter ist, Verarbeitungs- und Datenqualitätsstandards durchzusetzen, wenn diese durch ein zentral und aufeinander abgestimmtes Team umgesetzt werden. Je größer und vielfältiger das Unternehmen und je vielfältiger die Datenquellen und Berichte, desto wahrscheinlicher ist es jedoch, dass die Kapazität des Teams nicht mehr ausreicht, um sich in erforderlichem Maße mit Datenqualitätsproblemen zu beschäftigen, geschweige denn ein ausreichendes fachliches Verständnis über die zugrunde liegenden Daten zu erlangen.
Bei beiden Ansätzen empfiehlt es sich, die Daten in fachliche Domänen aufzuteilen. Dabei sollte zu jeder Datendomäne eine verantwortliche Person bestimmt werden, die entscheiden kann, ob Daten plausibel sind und in der nötigen Granularität erhoben werden. Der Domänenverantwortliche muss dafür eintreten, dass Sonderregeln nicht im dispositiven System eingebaut, sondern Fehler direkt an der Quelle behoben werden. Außerdem muss er den Rückbau von falschen oder nicht mehr benötigten Datenprodukten im Blick haben und für dessen Finanzierung sorgen. Er ist außerdem dafür verantwortlich, sicherzustellen, dass eine fachgerechte Dokumentation erstellt wird. Insbesondere beim Data-Mesh-Ansatz, bei dem die Daten von unterschiedlichen Teams an unterschiedlichen Stellen verwaltet werden, ist die Abstimmung der Produktteams essenziell: Nur so kann sichergestellt werden, dass relevante Daten in ausreichender Qualität auffindbar sind und von anderen Produkten effizient genutzt werden können. Grundvoraussetzung hierfür ist die Schaffung eines einheitlichen Verständnisses zum Data-Mesh-Ansatz [Deh22].
Neben der reinen Zuweisung von Rollen und Verantwortlichkeiten spielt auch die Fehlerkultur innerhalb des Unternehmens eine entscheidende Rolle für gute Datenqualität: Aufgedeckte Fehler dürfen nicht für persönliche Schuldzuweisungen verwendet werden. Stattdessen muss akzeptiert werden, dass Fehler passieren und partnerschaftlich daran gearbeitet wird, diese zu beheben.
Fachliche Ebene
Erst wenn der organisatorische Rahmen geklärt ist, sollten der fachliche Rahmen und die inhaltlichen Grenzen der Datenbank definiert und dokumentiert werden. Eine Voraussetzung dafür ist, auf organisatorischer Ebene Verantwortliche zu finden, die diesen fachlichen Rahmen festlegen können. Eine sinnvolle Dokumentation von fachlichen Inhalten und Anforderungen sollte dabei durch den ganzen Prozess hindurch gefördert werden, um langfristig die Datenqualität durch einheitliche Standards, Wissensbewahrung und Nachvollziehbarkeit von Entscheidungen sicherzustellen. Als Ort für die Dokumentation sollte sowohl beim Data Mesh als auch beim DWH-Ansatz ein Single Point of Truth gewählt werden, damit eine globale Sicht auf die Datenbasis ermöglicht wird.
Begleitend sollte eine Data-Catalog-Anwendung (zum Beispiel DataHub oder Collibra) eingeführt werden, welche die Ansprechpersonen sichtbar macht. Dies gilt besonders für dezentralisierte Ansätze wie Data Mesh, die für mehr Verantwortlichkeiten sorgen und einen stärkeren Austausch zwischen Produktteams notwendig machen. Dabei sollte eine Lösung bevorzugt werden, die auch die Datenflüsse (ETL-Strecken) hinter den Datenprodukten von der Quelle bis zur Verwendung visualisiert. Data Lineage kann durch die IT für die Analyse von Auswirkungen, etwa bei Störungen im Betrieb oder bei der Entwicklung, und für den Rückbau obsoleter Datenprodukte genutzt werden [Glu20]. Durch visualisierte Datenflüsse können Maßnahmen zur Steigerung der Datenqualität effizienter identifiziert werden und die Komplexität wird auch für Anwendende sichtbar. Viele ETL-Tools bieten die automatische Visualisierung der Data Lineage an (zum Beispiel manta). Ohne entsprechendes Tool müssen Datenflüsse aufwendig eigenständig aus den Metatabellen der Datenbank zusammengestellt werden. Die Visualisierung muss dann ebenfalls manuell durchgeführt werden (zum Beispiel mit dem Pythonmodul NetworkX). Daher ist es kostengünstiger, Data Lineage zu Beginn eines Projekts einzuführen, da sich damit die Notwendigkeit teurer Nacharbeiten oder Korrekturen im Verlauf des Projekts reduziert.
Die nächste wichtige Aufgabe ist die Messung der Datenqualität, die stark vom individuellen Kontext abhängt. Durch Prüfregeln und selbst definierte Kennzahlen – auch Key Performance Indicators (KPIs) genannt – können der aktuelle Stand und die Entwicklung der Datenqualität durch Kennzahlen dargestellt werden. Ein Beispiel für einen KPI könnte zum Beispiel die Anzahl der Objekte in der Datenbank sein, die seit einem Jahr nicht mehr aufgerufen wurden, oder die Anzahl der Datensätze mit leeren Einträgen oder die Anzahl der Verstöße gegen Prüfregeln.
Die KPIs sollten für das gesamte Unternehmen zugänglich dokumentiert werden – zum Beispiel in einem Grafana- oder Power-BI-Dashboard. Dabei ist die Existenz aussagekräftiger und vollständiger Testfälle entscheidend für die Aufrechterhaltung einer hohen Datenqualität. Es ist ratsam, sich im Vorhinein Gedanken zu machen, welche fehlerhaften Datensätze die Integrität und Funktionalität eines Datenprodukts gefährden könnten, und genau diese Fälle durch Prüfregeln abzudecken. Die Technikabteilung leitet daraus die Definition einer Eingabeüberprüfung im operativen System ab. Die Testfälle schaffen somit eine Voraussetzung für erfolgreiches Arbeiten auf technischer Ebene.
Technische Ebene
Aufbauend auf den Anforderungen der fachlichen Ebene erfolgt anschließend die technische Umsetzung. Dabei ist der zentrale Baustein für die Datenqualität die Korrektheit und Nachvollziehbarkeit der Verarbeitungslogik. Ist diese gewährleistet, reduziert sich die Menge der nachgelagerten Datenqualitätsprobleme und der Datenfluss und die Herkunft von Daten in Aufbereitungen und Berichten können nachvollzogen werden.
Besonders wichtig hierfür sind klare und einheitliche Standards und Vorgehensweisen. Diese Standards auch teamübergreifend abzusprechen ist besonders beim Data-Mesh-Ansatz erforderlich, damit die Datenqualität nicht erheblich leidet. Häufig ist dabei die Dokumentation und Einheitlichkeit wichtiger, als ein perfektes Vorgehen im Individualfall zu finden. Dadurch können im Projektlebenszyklus auftretende Wissenslücken schnell geschlossen werden.
Um die Verständlichkeit der Verarbeitung darüber hinaus auf Code-Ebene zu steigern, eignet sich das Vorgehen nach den Clean-Code-Prinzipien [Mar13]. Sie formulieren Herangehensweisen für verständlichen Code und sinnvolles Vorgehen bei Entwicklungen. Zentrale Bestandteile sind regelmäßige Investitionen in das Löschen und Aufräumen von obsoleten Code-Bestandteilen zur Steigerung der Übersichtlichkeit, Code-Reviews zur Einhaltung von Code Conventions, abgestimmte Vorgehensweisen und aktuell gehaltene Kommentare und Dokumentationen zur späteren Nachvollziehbarkeit. Darüber hinaus empfiehlt es sich, jederzeit sprechende Namen für Tabellen und Spalten zu nutzen. Dies fördert die Verständlichkeit und Wiederverwendbarkeit zu einem späteren Zeitpunkt. Etwaige Nachteile wie geringerer Speicherplatzbedarf und gesparte Zeit beim Tippen von kürzeren Variablennamen sind in der Regel vernachlässigbar.
Beim Data-Mesh-Ansatz ist die Identifizierung von obsoleten Datenobjekten einfacher, da alle Datenprodukte einem Produktteam zugeordnet sind und diese Teams ihre Daten besser bewerten können. Doppelte Objekte kommen bei diesem Ansatz häufiger vor und sind kein Zeichen für schlechte Datenqualität, da jedes Produktteam seine Daten einzeln aufbereitet. Auf der anderen Seite hat der DWH-Ansatz Vorteile bei globalen Aufräumarbeiten in der Datenbank, da die Akteure im selben Team arbeiten und somit der Informationsfluss einfacher ist.
Zur Unterstützung von Entwicklern und der weiteren Etablierung der zuvor beschriebenen Vorgehensweisen sollte eine die Clean-Code-Prinzipien unterstützende Architektur und ein Rahmen für die Dokumentation von Erkenntnissen und Entscheidungen gewählt werden. Daneben sollte die Architektur gewährleisten, dass nur zuverlässige und getestete Entwicklungen im produktiven Kontext eingesetzt werden, um die Daten nicht unbeabsichtigt zu manipulieren. Hierfür eignet sich eine Trennung der Entwicklung vom produktiven System.
Jede Neuentwicklung sollte auf einer Testumgebung umfassend überprüft werden. Entweder auf dieser Testumgebung oder einer weiteren getrennten Umgebung sollte anschließend eine fachliche Prüfung auf Korrektheit der Verarbeitung erfolgen. Dieses Vorgehen gewährleistet, dass nur eine technisch und fachlich überprüfte Änderung der Datenverarbeitung auf für die Entscheidungsfindung relevanten Systemen produktiv genutzt wird. Zur späteren Nachverfolgbarkeit der Änderungen sollten diese mit verständlichen Commit-Messages dokumentiert werden. Wenn zusätzlich Änderungen der Quelldaten gespeichert werden, kann so zu einem späteren Zeitpunkt ein beliebiger alter Stand vollständig rekonstruiert werden.
Fazit
Schlechte Datenqualität kann erhebliche wirtschaftliche Konsequenzen für Unternehmen haben. So können fehlerhafte oder unvollständige Daten zu betrieblichen Ausfällen, ungenauen Analysen oder auch falschen Geschäftsstrategien führen, die die Wirtschaftlichkeit eines Unternehmens gefährden. Die Schärfung des Bewusstseins für die immense Bedeutung guter Datenqualität ist der erste wichtige Schritt hin zu einem guten Datenqualitätsmanagement.
Ist dieser Schritt getan, können systematische Maßnahmen ergriffen werden, um die Datenqualität dauerhaft zu verbessern und zu erhalten. Dabei wird zuerst die organisatorische Ebene analysiert, danach die fachliche und dann die technische. Die Kernidee auf allen Ebenen ist dabei, die Nachvollziehbarkeit von Datenflüssen zu verbessern, klare Ansprechpersonen zu definieren und einen Rahmen zu schaffen, in dem möglichst wenig Fehler überhaupt erst entstehen, um Zeit und Geld für aufwendige Nacharbeiten zu sparen. Probleme können auf diese Weise direkt an der Wurzel gelöst werden. Sowohl mit dem Data-Mesh- als auch mit dem klassischen DWH-Ansatz ist dabei gute Datenqualität möglich.
Leitlinien für erfolgreiches Datenqualitätsmanagement
- Eindeutige und transparente Zuweisung von Verantwortlichkeiten für Datenquellen bzw. Datenprodukte
- Vermeidung falscher Eingaben im Quellsystem durch Input-Validierung
- Einheitliche Dokumentation von Datenquellen bzw. Datenprodukten
- Standardisierte Entwicklungs- und Deploymentprozesse
- Sicherstellung der Nachvollziehbarkeit des Datenflusses (Data Lineage)
- Einheitliche Standards für Datenprodukte und Schnittstellen
- Offener Umgang mit Datenqualitätsproblemen ohne persönliche Schuldzuweisungen
- Einführung von systematischen KPIs zur Bewertung der Datenqualität
- Regelmäßiges Housekeepi
Literaturangaben
[DAM17] DAMA International: DAMA-DMBOK Data Management Body of Knowledge. 2. Aufl., Technics Publications 2017.
[Deh22] Dehghani, Z.: Data Mesh. O’Reilly 2022.
[Eng99] English, L.: Improving Data Warehouse and Business Information Quality. Wiley & Sons 1999.
[Glu20] Gluchowski, P.: Data Governance: Grundlagen, Konzepte und Anwendungen. dpunkt.verlag 2020.
[HGM21] Hildebrand, K. / Gebauer, M. / Mielke, M.: Daten- und Informationsqualität: Die Grundlage der Digitalisierung. Springer 2021.
[Mar13] Martin, R. C.: Clean Code-Refactoring, Patterns, Testen und Techniken für sauberen Code. Deutsche Ausgabe. MITP-Verlags GmbH & Co. KG 2013.
[MCS2022] Machado, I. A. / Costa, C. / Santos, M. Y.: Data Mesh: Concepts and Principles of a Paradigm Shift in Data Architectures. In: Procedia Computer Science, Vol. 196, 2022.









