

Datenströme aus Metriken und Events entstehen an vielen Orten, beispielsweise im IoT-Umfeld in Form von Messwerten von Sensoren oder auch beim Monitoring von Anwendungen. Grundsätzlich bedeutet dies, dass die gewonnenen Zeitreihendaten mittels verschiedenster Technologien und Protokolle gesammelt, verarbeitet und gespeichert werden müssen. Gerade für die Themen Sammlung, Verarbeitung und Weitergabe der Daten hin zur Speicherung gibt es mit Telegraf [Tel] ein frei verfügbares Open-Source-Tool.
Wo sonst eigens entwickelte Schnittstellen und Tools eingesetzt werden müssten, erlaubt es, das Konfigurations- und Plug-in-Konzept an eine Vielzahl von Datenquellen mit relativ wenig Aufwand anzubinden.
Plug and Play
Durch die Kombination unterschiedlicher Plug-ins ist es möglich, komplexe Verarbeitungspipelines zu erstellen. Der Vorteil hierbei ist, dass nur eine Konfigurationsdatei benötigt wird. Der Telegraf-Agent selbst stellt dabei eine einzelne, ohne weitere Abhängigkeiten ausführbare Datei für viele Zielsysteme (bspw. Linux, Windows oder MacOS) zur Verfügung.
Im Rahmen der Konfiguration können mittlerweile mehr als 300 Plug-ins genutzt werden. Diese lassen sich nach den abgebildeten Verarbeitungsschritten, das heißt Datensammlung (Input-Plug-ins), Datentransformation (Processor-Plug-ins), Datenaggregation (Aggregator-Plug-ins) und Datenausgabe (Output-Plugins), unterteilen (vgl. Abb. 1).
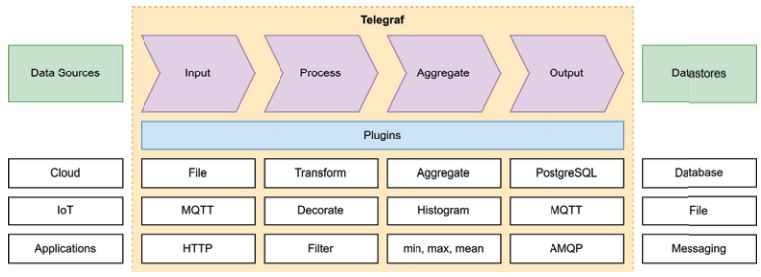
Abb. 1: Telegraf-Übersicht (in Anlehnung an [Tel])
Konfiguration
Die Konfiguration von Telegraf wird über die Datei „telegraf.conf“ vorgenommen und bedient sich dem TOML-Format [Tom], einem für Menschen leicht verständlichen Format. Für umfangreiche Projekte lässt sich die Konfiguration zudem auf mehrere Dateien aufteilen.
Grundsätzlich besteht eine Telegraf-Konfigurationsdatei aus fünf Bausteinen: der Konfiguration des Agents, der Inputs, der Prozessoren, der Aggregatoren und der Outputs. Im Allgemeinen sind mindestens ein Input und ein Output notwendig, damit Telegraf weiß, von wo die Daten erfasst und wohin sie übermittelt werden sollen. Nicht explizit gesetzte Werte werden dabei mit Standardwerten befüllt. Eine minimale, voll funktionsfähige Konfiguration, um zyklisch CPU-Metriken in eine Datei zu schreiben, ist dabei in Listing 1 dargestellt.
[[inputs.cpu]]
[[outputs.file]]Um komplexe Verarbeitungspipelines zu realisieren, können mehrere Datenquellen über jeweils unterschiedliche Input-Plug-ins aufgenommen werden. Die gesammelten Daten müssen dabei nicht zwangsweise alle dieselben Verarbeitungsschritte aus Prozessoren und Aggregatoren durchlaufen, sondern können je nach Bedarf individuell behandelt und an ein oder mehrere Outputs geschrieben werden.
Agent
Der in der Programmiersprache Go entwickelte Agent bildet die Laufzeitumgebung von Telegraf. Was bei eigener Entwicklung einen hohen Aufwand bedarf, wird hier durch Anpassen einer Konfigurationsdatei realisiert. Gestartet wird der Telegraf auf der Kommandozeile unter Windows mittels telegraf.exe –config telegraf. conf. Je nach Betriebssystem können die Befehle variieren. Dies gilt auch für die Installation als Service, um einen langfristigen Betrieb zu ermöglichen.
In Listing 2 ist beispielhaft eine Auswahl der Agenten-Parameter angegeben. Hierbei legt interval fest, in welchem Abstand Metriken von den Input-Plug-ins eingelesen und anschließend weiterverarbeitet werden sollen. Weiterhin definiert das metric_ buffer_limit, wie viele Metriken für jeden Output zwischengespeichert werden. Ein höherer Wert ermöglicht es, längere Ausfälle der Output-Ziele ohne Datenverluste zu überbrücken. Dies impliziert jedoch einen höheren Speicherverbrauch. Aus diesen Puffern werden regelmäßig, abhängig vom Parameter flush_interval, die Daten in Batches der Größe metric_batch_size an die Outputs geschickt.
Darüber hinaus können an dieser Stelle weitere Konfigurationen, wie beispielsweise die Steuerung der Telegraf-Logdateien, vorgenommen werden.
[agent]
interval = "10s"
metric_batch_size = 1000
metric_buffer_limit = 10000
flush_interval = "10s"Eingabequellen und -formate
Um Daten aus unterschiedlichen Quellen zu importieren, bedient sich Telegraf sogenannter Input-Plug-ins. Diese erlauben es, technologische Unterschiede zu überbrücken und so Daten aus heterogenen Quellen zusammenzuführen. Input-Plug-ins lassen sich in unterschiedliche Gruppen kategorisieren, je nach Art und Weise, wie Daten angebunden werden sollen. Beispielsweise lassen sich so Daten aus Cloud- oder Container-Umgebungen und -Anwendungen wie auch aus dem IoT-Umfeld rein mittels Konfiguration einlesen. Für eine Vielzahl an Anwendungsfällen existieren bereits entsprechende Plug-ins.
Besonders interessant sind hierbei die generischen Input-Plug-ins wie File, Tail, HTTP-Listener oder auch das Exec-Input-Plug-in. Diese ermöglichen es, beliebige, applikationsspezifische Daten einzulesen. In Listing 3 ist beispielhaft das Exec-Input-Plug-in aufgeführt, wodurch externe Befehle, Skripte oder Programme ausgeführt werden können.
[[inputs.exec]]
commands = ["sh collect.sh"]
environment = ["KEY=value"]
data_format = "influx"Die von den Input-Plug-ins aufgezeichneten Rohdaten können in verschiedensten Formaten geparst werden. So kann beispielsweise das File-Input-Plug-in, welches zyklisch die Dateien ausliest, unter anderem mit CSV-, XML- und JSON-Dateitypen umgehen.
In Listing 4 wird beispielhaft gezeigt, wie Input-Datenformate eingesetzt werden. Hier soll eine Datei im CSV-Format eingelesen werden. Dazu muss im entsprechenden File-Input-Plug-in zunächst das Datenformat festgelegt werden. Der csv_header_row_count
sagt dabei aus, dass eine Kopfzeile existiert, aus der die Namen für die extrahierten Felder entnommen werden können. Des Weiteren werden noch die Datentypen der einzelnen Spalten festgelegt, sodass die Werte korrekt interpretiert werden können. Zuletzt wird noch das Trennzeichen vom standardmäßigen Komma auf einen Strichpunkt umkonfiguriert.
[[inputs.file]]
files = ["example.csv"]
data_format = "csv"
csv_header_row_count = 1
csv_column_types = ["string", "int"]
csv_delimiter = ";"Prozessoren
Nachdem die Daten mittels Input-Plug-ins eingelesen wurden, kann es sinnvoll sein, sie in verschiedenen Schritten weiterzuverarbeiten. Dies ermöglicht es, nachgeschaltete Verarbeitungsprozesse zu vermeiden, die ansonsten in eigenentwickelten Anwendungen umgesetzt werden müssten. Insbesondere wenn mehrere Ausgabeorte unterstützt werden sollen, hat dies den Vorteil, dass die Verarbeitung zentralisiert mit Telegraf stattfinden kann.
Auch bei den Prozessoren steht eine Vielzahl an Plug-ins zur Verfügung. Durch sie können vorrangig die gesammelten Daten angepasst werden, indem beispielsweise ihr Datentyp geändert, reguläre Ausdrücke angewandt oder Standardwerte für fehlende Datenpunkte eingesetzt werden. Zudem können neue Felder aus den bestehenden Daten generiert oder die Daten mit externen Informationen angereichert werden.
In komplexeren Szenarien lässt sich jedoch auch die Datenstruktur vollständig an den vorliegenden Anwendungsfall adaptieren. Es können zum Beispiel Feldbezeichnungen umbenannt oder entfernt sowie Duplikate in den Daten gefiltert werden. Reichen die vorhandenen Processor-Plug-ins nicht für die gewünschte Aufgabe aus, so ist es wiederum möglich, externe Programme einzubinden oder eigene Plug-ins zu schreiben.
Aggregatoren
Bei den Aggregatoren wird deutlich, dass Telegraf besonders im Hinblick auf die Verarbeitung von Zeitreihendaten konzipiert ist. So fassen Aggregatoren die Rohdaten zu aggregierten Metriken zusammen, um sie an die Output-Plug-ins weiterzuleiten. Dadurch kann die Datenmenge reduziert oder es können statistische Kenngrößen wie Minimum, Maximum oder Mittelwert ermittelt werden.
Es sei angemerkt, dass die Datenpunkte, die den Aggregatoren entspringen, wiederum die Prozessoren durchlaufen können. So können weitere Verarbeitungsschritte auch noch nach dem Aggregieren erfolgen.
Ausgabeziele und -formate
Die Weiterleitung der gesammelten Datenpunkte an ihr konfiguriertes Ziel übernehmen die Output-Plug-ins. Beispiele für Ziele sind Datenbanken wie InfluxDB [Inf], PostgreSQL [Pos] oder Elasticsearch [Ela], Messaging Anwendungen wie AMQP [Amp], MQTT [Mqt] oder Apache Kafka [Kaf] sowie das Schreiben in Dateien. Ähnlich zu den Eingabequellen ist es auch bei den Ausgabequellen möglich, eine Vielzahl an Datenformaten wie beispielsweise JSON zu konfigurieren.
Ein nichttriviales Beispiel
Anhand eines Beispiels soll das Zusammenspiel der verschiedenen Plug-ins näher beleuchtet werden. Angenommen es soll die Anzahl an Anfragen gemessen werden, die an zwei unterschiedliche APIs verschickt werden. Diese APIs nutzen unterschiedliche Arten, um die Auslastung zu erfassen. Gesammelt werden sollen die Daten aller APIs jedoch an zentraler Stelle, weshalb ihr Format aneinander angeglichen werden muss.
Die erste Art sei eine Logdatei im CSV-Format (Listing 5), in der für jede Anfrage an die API eine Zeile mit den Feldern Zeitstempel, ID der API und Status über Erfolg oder Misserfolg der Anfrage (1 oder 0) steht.
2023-02-06 14:45:00,api_1,1
2023-02-06 14:45:03,api_1,0
2023-02-06 14:45:05,api_1,1Eine andere API sammelt bereits Anfrage-Statistiken und kann diese schon aggregiert verschicken (Listing 6). In diesem Format sollen die Daten auch final abgespeichert werden, weshalb die Daten aus der ersten API zusätzlich noch auf Intervalle von einer Minute aggregiert werden müssen.
{
"timestamp": "2023-02-06 14:45:00",
"api_id": "api_2",
"successful_requests": 103,
"failed_requests": 4
}Basierend auf dieser Ausgangslage soll nachfolgend die konkrete Telegraf-Konfiguration veranschaulicht werden. Der Agent wird nur dahingehend angepasst, dass der Hostname nicht als „Tag“ in den Datenpunkten mit aufgenommen wird (Listing 7). Ein „Tag“ beschreibt dabei die Art oder den Ursprung einer Metrik (im Beispiel die API-ID). Die eigentlichen Metriken (z. B. Anzahl erfolgreicher Anfragen) werden im Telegraf-Umfeld als Felder bezeichnet.
[agent]
omit_hostname = trueUm das kontinuierliche Auslesen der CSV-Datei abzubilden, wird das Tail-Plug-in (vgl. Listing 8) verwendet. Hier wird zunächst mittels name_override die Bezeichnung der Daten, die über diesen Input eingelesen werden, angegeben. Weiterhin wird noch ein zweiter Tag verworfen (path), welcher den Dateinamen der ausgelesenen Datei enthält. Im files-Parameter werden die auszulesenden Dateien gelistet. Die restliche Konfiguration ist für das korrekte Parsen des CSV-Formats notwendig. So werden die Spaltennamen festgelegt, die Spalten, die als „Tag“ verwendet werden sollen, die Spalte, die den Zeitstempel enthält und dessen Format und Zeitzone.
[[inputs.tail]]
name_override = "datasource_file"
tagexclude = ["path"]
files = ["log.csv"]
data_format = "csv"
csv_column_names = ["timestamp", "api_id", "request"]
csv_tag_columns = ["api_id"]
csv_timestamp_column = "timestamp"
csv_timestamp_format = "2006-01-02 15:04:05"
csv_timezone = "Local"Das zweite Plug-in ist ein „http_listener_v2“ (Listing 9), das eine HTTP-Schnittstelle aufbaut (hier „localhost:8080/ telegraf“). Das erwartete Datenformat ist in diesem Fall JSON. Auch hier werden die Keys bestimmt, die Tags und den Zeitstempel enthalten, wie auch das Zeitformat. Im Beispiel werden alle weiteren Keys automatisch als Metriken interpretiert, da sie numerische Werte enthalten.
[[inputs.http_listener_v2]]
name_override = "datasource_http"
service_address = ":8080"
methods = ["POST"]
data_format = "json"
tag_keys = ["api_id"]
json_time_key = "timestamp"
json_time_format = "2006-01-02 15:04:05"
json_timezone = "Local"Nach dem Einlesen der Daten werden zunächst die Processor-Plug-ins angewandt (Listing 10). Über den order-Parameter kann die Ausführungsreihenfolge gesteuert werden. Zunächst werden mit dem rename-Prozessor die Felder request_1 und request_0 in successful_requests und failed_requests umbenannt. Durch den Parameter namepass wird dieser nur auf die Daten aus der CSV-Datei angewandt. Da die Rohdaten keine Felder mit solchem Namen haben, passiert hier jedoch zunächst nichts. Der zweite Prozessor (converter) wird auf alle Daten angewandt und wandelt die Felder successful_requests und failed_requests in Ganzkommazahlen um. Dieser wird zunächst nur auf die Daten datasource_http angewandt, da datasource_file keine Felder mit dieser Bezeichnung besitzt.
[[processors.rename]]
order = 1
namepass = ["datasource_file"]
[[processors.rename.replace]]
field = "request_1"
dest = "successful_requests"
[[processors.rename.replace]]
field = "request_0"
dest = "failed_requests"
[[processors.converter]]
order = 2
[processors.converter.fields]
integer = ["successful_requests",
"failed_requests"]Im dritten Schritt werden die Aggregatoren durchlaufen (Listing 11). Hier werden wiederum nur die datasource_file-Daten verarbeitet, um diese in das gewünschte Format zu bringen. Der valuecounter-Aggregator teilt das request-Feld in zwei neue Felder auf, mit der Anzahl an erfolgreichen und fehlgeschlagenen Anfragen (requests_1 und requests_0). Gleichzeitig erfolgt eine Aggregation auf ein Intervall von einer Minute. Mittels drop_orginal werden nur die neu generierten, aggregierten Daten weitergeschrieben. Diese Daten durchlaufen nun nochmals die Prozessoren. Der rename-Prozessor benennt die Felder um und konvertiert sie in ein einheitliches Format. Abschließend werden die Daten mittels dem File-Output-Plug-in (Listing 12) in einer gemeinsamen Ausgabedatei im „InfluxDB Line Protocol“ gespeichert (Listing 13).
[[aggregators.valuecounter]]
namepass = ["datasource_file"]
period = "1m"
drop_original = true
fields = ["request"][[outputs.file]]
name_override = "api_usage"
files = ["metrics.out"]
data_format = "influx"api_usage,api_id=
api_1 successful_requests=2i,failed_requests=1i 1675691100000000000
api_usage,api_id=
api_2 successful_requests=103i,failed_requests=4i 1675691100000000000Integrationsmöglichkeiten
Im Telegraf-Umfeld existiert mit dem TICK-Stack (Telegraf, InfluxDB, Chronograf, Kapacitor) [TIC] eine Lösungsarchitektur aus Open-Source-Tools, um zeitreihenbasierte Daten wie Metriken oder Events zu sammeln, abzuspeichern, zu verarbeiten und zu visualisieren. Hierbei werden neben Telegraf die Zeitreihendatenbank InfluxDB zur Speicherung sowie Chronograf zu Visualisierung der Daten und Kapacitor als Data Processing Engine eingesetzt (vgl. Abb. 2).
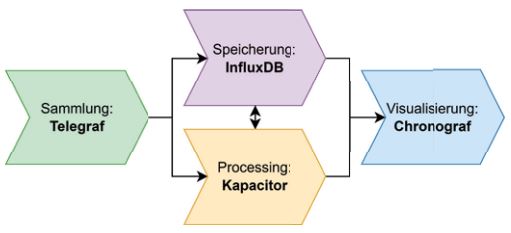
Abb. 2: TICK-Stack
Neben dem TICK-Stack existieren auch Varianten, in denen beispielsweise die NoSQL-Datenbank InfluxDB durch eine auf PostgreSQL basierende Zeitreihenbank (Timescale [Tim]) ersetzt wird.
Fazit
Telegraf bildet eine pragmatische und robuste Lösung, um Metriken und Events aus unterschiedlichen Eingabequellen zu verarbeiten und an unterschiedliche Ausgabeziele weiterzuleiten. Gerade die einfache Installation und Konfiguration erlaubten es, ohne großen Infrastrukturaufwand komplexe Datenpipelines zu realisieren.
Literatur und Links
[Amp] Advanced Message Queuing Protocol, https://www.amqp.org
[Ela] Elasticsearch, https://www.elastic.co/de/elasticsearch
[Kaf] Apache Kafka, https://kafka.apache.org
[Inf] InfluxData, https://www.influxdata.com
[Mqt] MQTT, https://de.wikipedia.org/wiki/MQTT
[Pos] PostgreSQL, https://www.postgresql.org
[Tel] Telegraf, https://www.influxdata.com/time-series-platform/telegraf
[TIC] TICK-Stack, https://www.influxdata.com/time-series-platform
[Tim] Timescale, https://www.timescale.com
[Tom] Tom’s Obvious Minimal Language, https://toml.io









