

Software, die früher als native Anwendung entwickelt und auf dem System des Nutzers installiert wurde, wird heute immer häufiger als Web-App angeboten. Die Vorteile sind vielfältig: Jedes Endgerät kann auf die gleichen Daten zugreifen. Das Web als gemeinsame Plattform beseitigt den Mehraufwand der Entwicklung für verschiedene Betriebssysteme. Mit der zunehmenden Verbreitung von Progressive Web Apps erreicht man auch mobile Anwender, ohne eine App speziell für Android oder iOS entwickeln zu müssen. Die Software lässt sich stetig verbessern, ohne die Endnutzer ständig zur Installation von Updates aufzufordern. Das Abo-Modell zur Vermietung der Software kann eine attraktive Alternative zum Geschäftsmodell des einmaligen Verkaufs von Lizenzen sein.
Auf der Kehrseite der Medaille macht sich dabei der Betrieb der Anwendung (Operations) als Verantwortung des Anbieters bemerkbar. Dies bedeutet nicht nur Kosten, sondern vor allem auch Risiken, beispielsweise durch Ausfall der Systeme und daraus folgender Verlust von Umsatz und Reputation. Im klassischen Szenario sind die Operations eine für sich stehende Aufgabe, bewältigt von IT-Administratoren, die sich um Anschaffung und Installation der Server, Einrichtung der Software, Monitoring der laufenden Systeme, Ausrollen von Updates und vieles mehr kümmern. Mit der Komplexität der Systeme steigt hier nicht nur der personelle Aufwand, sondern auch die Wahrscheinlichkeit von Fehlern. Oft verbleiben Praxiswissen und Erfahrung in den Köpfen einzelner, und es gelingt nicht, die Dokumentation bei Änderungen stets aktuell zu halten.
Aus der Perspektive der Entwickler ergeben sich weitere Herausforderungen: Um zeitnah auf Kundenwünsche und neue Anforderungen reagieren zu können, setzen sie immer häufiger auf agile Entwicklungsmethoden. Dank Continuous Integration und Continuous Delivery (CI/CD) sind sie zwar in der Lage, in kurzen Entwicklungszyklen Änderungen automatisiert zu verifizieren und betriebsfertig zu liefern, die tatsächliche Bereitstellung an den Endnutzer hängt jedoch stets von den Arbeitsabläufen der Operations ab.
Abhilfe durch DevOps
Der DevOps-Ansatz verspricht hier ersehnte Abhilfe, indem er die Aufgaben von Entwicklung (Dev) und Betrieb (Ops) näher zusammenführt. So nah sogar, dass die Grenze zwischen den Disziplinen verschwimmt und ein Team meist beide Aufgaben übernimmt. Dahinter steht die Idee, bewährte Vorgehensweisen aus der Domäne der Entwickler auf den Betrieb zu übertragen. Die schnelle und kleinschrittige Integration von Code-Änderungen mithilfe automatisierter Tests hat als heutiger Stand der Technik viele Herausforderungen der klassischen Software-Integration beseitigt. Unangenehme Überraschungen in späten Phasen der Entwicklung werden immer seltener, da ihre frühzeitige Entdeckung fester Bestandteil der täglichen Arbeit ist. Die konsequente Fortsetzung dieses Erfolgsrezeptes ist seine Ausdehnung auf den Produktiv-Betrieb: Nach Fertigstellung und Review einer Änderung ist nicht nur die Integration automatisiert, sondern auch die Delivery in die QA-Phase mit tiefergehenden Tests, gefolgt vom Deployment in den Produktivbetrieb.
Hat man einen entsprechenden Reifegrad erreicht, kann eine solche Pipeline sogar ohne jegliches weitere Zutun vollautomatisch durchlaufen werden. Auf den ersten Blick mag das riskant erscheinen, schließlich könnte ein Entwicklerfehler viel schneller zum Endnutzer durchschlagen. Doch letztlich handelt es sich nur um die Abbildung der vormals manuellen Prozesse auf Code. Damit ist zum einen sichergestellt, dass ein Deployment stets exakt so erfolgt wie vorgesehen, und zum anderen eröffnet es völlig neue Möglichkeiten der Qualitätssicherung, wie sich später zeigen wird. Nun ist die werkzeugunterstützte Automation von IT-Infrastruktur verglichen mit dem DevOps-Ansatz keine neuartige Angelegenheit. Doch auch moderne Inkarnationen von Tools in diesem Bereich, wie beispielsweise Puppet oder Ansible, haben eine grundsätzliche Einschränkung in ihrem Ansatz: Sie nehmen die Konfiguration der Infrastruktur durch Automation ab, aber sie bieten keine abstraktere Sicht auf die Infrastruktur, die sie auf ihre Konzepte reduziert. Schließlich ist es sowohl für den Entwickler wie auch sein Softwareprodukt meist recht egal, in welchem Server-Schrank, auf welchem Computer, mit welcher Storage-Lösung der Betrieb erfolgt, sondern nur, dass diese Ressourcen zur Verfügung stehen.
Klassisches Deployment eines Webservice
Der Unterschied zwischen einem klassischen und einem containerbasierten Deployment lässt sich an einer kleinen Webanwendung illustrieren. Diese besteht aus einem von einem Webserver ausgelieferten Frontend, das mit einem Backend per API kommuniziert. Dieses Backend läuft in einem eigenen Prozess, möglicherweise auf einem eigenen Server, und kommuniziert mit einer Datenbank. Diese kann wiederum auf einem eigenen Server laufen. Webserver, Backend und Datenbank werden normalerweise direkt im Host-System installiert und teilen sich Laufzeitumgebung und Dateisystem mit allen anderen Programmen. Soll nun eine dieser Komponenten skaliert werden, muss auf zusätzlichen Servern eine möglichst identische Umgebung (Betriebssystem und Software) aufgesetzt werden. Zusätzlich muss als weiterer Service ein Loadbalancer konfiguriert werden, der die eingehenden Anfragen auf die verschiedenen Instanzen eines Service verteilt.
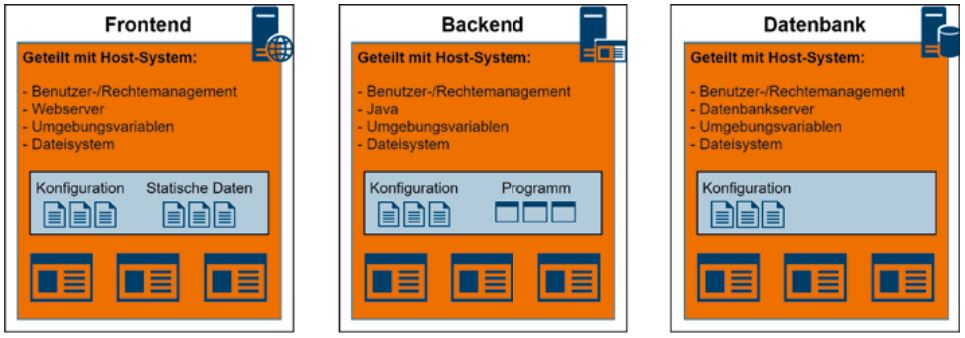
Abb. 1: Klassisches Deployment
Abbildung 1 zeigt ein klassisches Deployment, bei dem die Software direkt im Host-System installiert wird. Die Komponenten des Webservice sind in Blau eingezeichnet, zum Beispiel für das Frontend die Konfigurationsdateien für den Webserver und die statischen Inhalte. Orange hinterlegt ist die Laufzeitumgebung, also das Benutzer- und Rechtemanagement, Dateisystem und Umgebungsvariablen. Diese teilt sich der Webservice mit dem Host-System und anderen auf dem gleichen Server installierten Programmen. Das Operationsteam muss hier sicherstellen, dass es in dieser gemeinsamen Umgebung keine Konflikte mit anderen Programmen oder dem Host-System gibt. Um eine weitere Instanz einer der Webservice-Komponenten zu erstellen, muss diese Laufzeitumgebung möglichst identisch aufgesetzt werden.
In der Entwicklungsphase wird normalerweise eine Umgebung verwendet, die sich von der Produktivumgebung unterscheidet. Um unabhängig testen zu können, wird häufig eine lokale, kleinere und ressourcensparende Datenbank eingesetzt. Der Webserver wird meist mit einer für die Entwicklung optimierten Konfiguration betrieben, zum Beispiel ohne Caching und mit ausführlichem Logging. Wenn Fehlerbehebungen für ältere Versionen entwickelt werden, die eventuell andere Abhängigkeiten haben (z. B. ältere Java-Version), muss dafür eine spezielle Umgebung angelegt werden. Die Verwaltung der verschiedenen Varianten wird hier sehr schnell komplex.
Deployment mit Containern
Ein erster Schritt, die Abhängigkeit zwischen Anwendungen und Betriebssystem aufzulösen, ist die Ausführung der Software in Containern, beispielsweise mit Docker. Ein Container ist vergleichbar mit einer leichtgewichtigen virtuellen Maschine, in der nur die notwendigen Pakete für eine bestimmte Anwendung installiert wurden. Das Dateisystem des Containers ist unabhängig vom Dateisystem des Host-Systems; somit kann es auch keine Pfadkonflikte zwischen verschiedenen Anwendungen in separaten Containern geben. Außerdem ist die Laufzeitumgebung für die Anwendung immer gleich, egal auf welchem Host-System der Container ausgeführt wird.
Container kommunizieren untereinander wie klassische Server über Netzwerkschnittstellen. Das initiale Dateisystem im Image, von dem ein Container gestartet wird, ist unveränderlich, alle so gestarteten Container-Instanzen sind beim Start identisch. Die Konfiguration der Anwendung im Container erfolgt entweder über Umgebungsvariablen, die im Container gesetzt werden, oder über von außen übergebene Konfigurationsdateien.
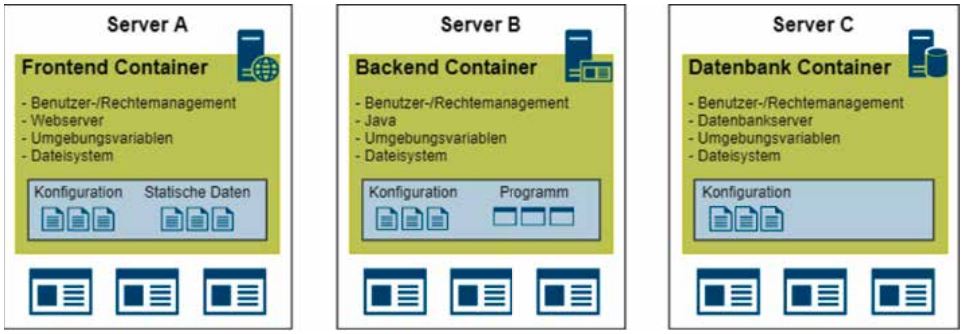
Abb. 2: Containerbasiertes Deployment
Abbildung 2 zeigt ein containerbasiertes Deployment, das die Laufzeitumgebung für den Webservice isoliert. Dateisystem, Umgebungsvariablen, Benutzer- und Rechtemanagement im Container (grün hinterlegt) sind unabhängig vom Host-System. Diese Isolation schließt Konflikte mit anderen auf demselben Host-System ausgeführten Programmen aus. Da benötigte Programme wie der Webserver oder die Java-Runtime ebenfalls fest im Container integriert sind, können identische Instanzen auf beliebigen weiteren Systemen ausgeführt werden.
Container-Orchestrierung mit Kubernetes
Somit sind die einzelnen Komponenten des Systems unabhängig von den darunterliegenden Servern, aber die Konfiguration der Container und der Ort ihrer Ausführung liegen noch immer beim Operationsteam. Hier kommt ein Tool zur Container-Orchestrierung ins Spiel. Dabei hat sich in den letzten Jahren Kubernetes gegenüber der Konkurrenz wie Docker Swarm durchgesetzt.
Kubernetes wurde ursprünglich von Google entwickelt und später als Open-Source-Software an die Cloud Native Computing Foundation übergeben. Es abstrahiert Konzepte wie persistenten Speicher, redundante Services mit vorgeschaltetem Loadbalancer und Konfigurationsdateien. Außerdem ist es von Grund auf für Skalierung und Ausfallsicherheit ausgelegt, sowohl auf Anwendungsebene mit redundanten Service-Instanzen als auch auf Systemebene mit automatischer Lastverteilung auf verschiedene Servernodes. Dabei kann Kubernetes sowohl als Single-Node-Instanz auf einem Entwicklerrechner als auch mit mehreren tausend Nodes weltweit verteilt betrieben werden.
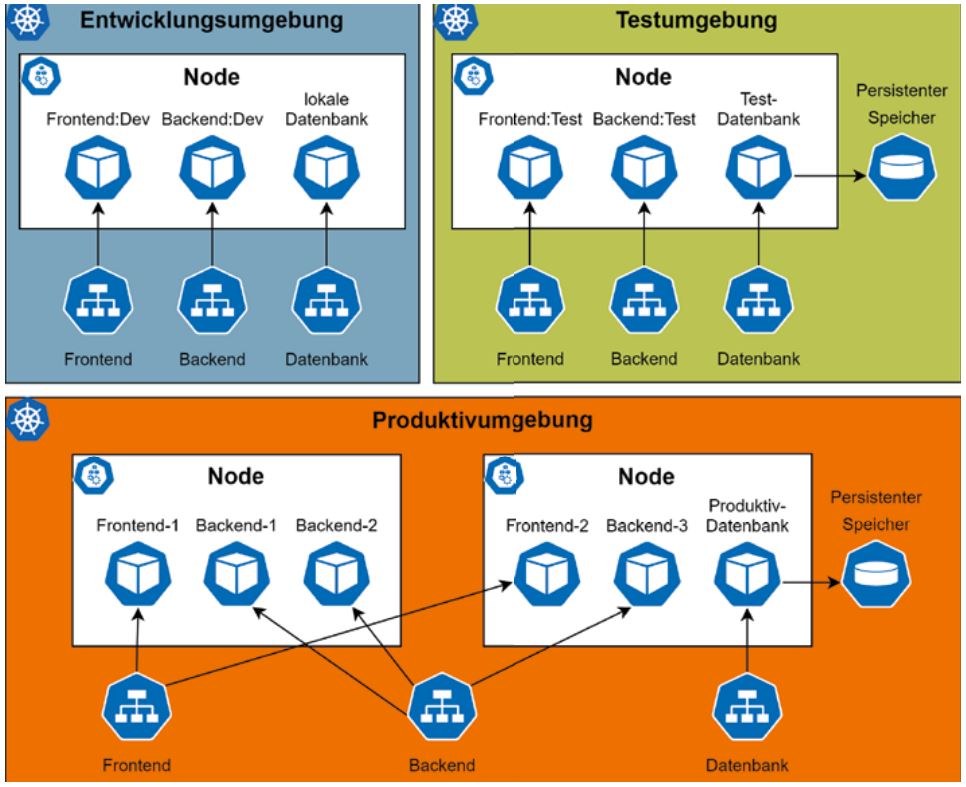
Abb. 3: Kubernetes abstrahiert Services in unterschiedlichen Umgebungen
Durch die Abstraktion von Kubernetes ist es möglich, einen Service mit wenigen Änderungen an der Konfiguration in verschiedenen Umgebungen zu betreiben (s. Abb. 3). Die Service-Adresse, mit der auf die verschiedenen Komponenten zugegriffen wird, ist dabei in allen Umgebungen gleich. Die blau hinterlegte Entwicklungsumgebung besteht aus einem Single-Node-Cluster auf dem Entwicklerrechner. Ein Entwickler kann hier lokal gebaute Dockerimages mit einer lokalen Datenbank testen. Die grün hinterlegte Testumgebung kann, je nach Ressourcenbedarf, aus einem oder mehreren Nodes bestehen. Sie bildet die Produktivumgebung möglichst realistisch ab, verwendet aber eine eigene Testdatenbank.
Hier werden bereits die per CI/CD erstellten Dockerimages der einzelnen Komponenten verwendet; nur die Konfiguration der Komponenten kann noch zusätzliche Einstellungen enthalten, die das Testen erleichtern (z. B. erweitertes Logging). Orange hinterlegt ist die Produktivumgebung; hier werden mehrere Instanzen des Frontend und Backend auf unterschiedlichen Nodes gestartet. Obwohl in den unterschiedlichen Umgebungen verschiedene Dockerimages beziehungsweise mehrere Instanzen der Komponenten eingesetzt werden, können diese untereinander über die abstrahierten Services kommunizieren, ohne dass dafür der Code angepasst werden muss.
Die Konfiguration der verschiedenen Umgebungen lässt sich in Kubernetes mit dem De-facto-Paketmanager Helm verwalten. Dabei werden die verschiedenen Kubernetes-Ressourcen mit Templates beschrieben; für die einzelnen Umgebungen können diese dann mit spezifischen Werten instanziiert werden. Diese Chart genannten Sammlungen von Templates sind selbst versioniert, somit können benötigte Änderungen der Laufzeitumgebung eines Webservice auf eine neue Version eines Helm-Chart abgebildet werden. Jeder Chart enthält eine Standardkonfiguration für die enthaltenen Komponenten. Bei der Installation und bei Updates können einzelne Werte dieser Konfiguration überschrieben werden.
Mithilfe von Kubernetes und Helm lassen sich also auf einfache Weise verschiedene Umgebungen verwalten, vom Entwicklerrechner bis zum Produktiv-Cluster. Per CI/CD ist auch die Qualität der verwendeten Dockerimages gewährleistet, nur geprüfte Releases werden auch in der Produktivumgebung eingesetzt.
Qualitätskontrolle mit Review-Deployments
Zu einem sorgfältigen Code-Review zählt in der Regel, die in einem Pull Request (PR) vorgeschlagene Änderung nicht nur inhaltlich zu begutachten, sondern auch einer Funktionsprüfung zu unterziehen. Die programmatische Umsetzung des Deployments als Helm-Chart sorgt hier bereits für minimalen Aufwand, sodass ein Reviewer meist ohne Weiteres ein Deployment auf dem eigenen Laptop durchführen kann. Im Alltag empfinden Reviewer die damit verbundene Wartezeit – durchaus mehrere Minuten – dennoch oft als Hürde, sodass solche Probe-Deployments regelmäßig unterbleiben. Kleine, aber wichtige Details könnten dann leicht übersehen werden. Diese Details werden von Tests nicht als Probleme identifiziert, würden jedoch in der manuellen Benutzung der Anwendung schnell auffallen.
Diese Lücke im Workflow lässt sich mit Kubernetes auf charmante Weise schließen. Indem man eine Domain mitsamt aller Subdomains auf einen Cluster umleitet, kann man beliebige Subdomains auf interne Service-Adressen zuordnen, ohne dafür die Kubernetes-Welt zu verlassen. Für jeden offenen Pull Request wird damit ein neues Deployment unter eigener, dynamisch ausgewählter Adresse gestartet.
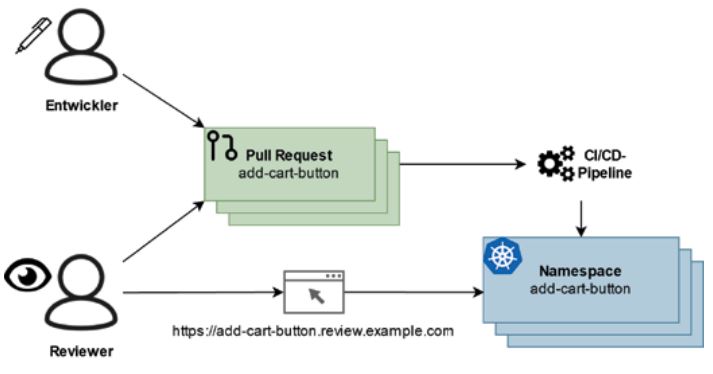
Abb. 4: Review-Deployments
Abbildung 4 zeigt das Beispiel eines Entwicklers, der in einem Webshop einen Einkaufswagen-Button ergänzen möchte.
Er eröffnet hierzu einen PR unter dem Branch-Namen add-cartbutton und bittet ein Teammitglied um Review. Die CI/CD-Pipeline wird ausgelöst und führt – neben ihren üblichen Tests und Checks – automatisch ein Deployment durch, das unter https:// add-cart-button.review.example.com für den Reviewer einsehbar ist. In Kubernetes legt man dabei die einzelnen Review-Deployments in gleichlautenden Namespaces ab und hält sie so voneinander getrennt. Nach Integration des PR können alle zugehörigen Ressourcen ganz einfach durch Löschen des zugehörigen Namespaces entfernt werden.
Das Konzept von Review-Deployments überträgt die Idee von vorgelagertem Code-Review auf den Bereich der Operations. Analog zu Pull Requests, die eine Begutachtung des Codes vor der tatsächlichen Änderung erlauben, ermöglichen die Review-Deployments einen greifbaren Einblick in die Auswirkungen der Änderung auf den Betrieb. Manche Entwicklungsplattformen bieten bereits Vorbereitungen für den Betrieb von Review-Deployments an, aber dank der Abstraktion von Kubernetes lassen sich Review-Apps in der Regel problemlos in der eigenen CI/CD-Lösung umsetzen.
Fazit
Die klassische Trennung von Entwicklung und Betrieb der Software führt zu erheblichem Aufwand beim Release neuer Versionen. Der DevOps-Ansatz vereinigt beide Disziplinen und ermöglicht die einfache Verwaltung unterschiedlicher Laufzeitumgebungen mit minimalem Aufwand. Dank der Abstraktion von Kubernetes lassen sich auch einzelne Änderungen in Pull Requests in einem Probe-Deployment begutachten. Dabei kann der Grad der Automatisierung den eigenen Bedürfnissen angepasst werden, von manuellen Deployments hin zu automatischen Releases nach der Integration eines Pull Request.
Das komplexe Ökosystem Kubernetes verlangt zwar initialen Aufwand, um bestehende Services dafür umzufunktionieren, danach nimmt es aber viel Verwaltungsaufwand ab. Dabei lässt sich diese Transformation schrittweise durchführen. Nachdem Services für die Ausführung in Containern vorbereitet wurden, kann als Nächstes das Deployment per Helm-Chart umgesetzt werden. Ab da ist es einfach, zusätzliche Betriebsumgebungen zu erstellen – sei es, um einzelne Pull Requests zu begutachten oder getrennte Instanzen für Kunden zu verwalten.








