

Bevor auf diese KI-Techniken eingegangen werden kann, muss jedoch zunächst definiert werden, welche Anforderungen an KI-gestütztes Black-Box-Unit-Testing gestellt werden und welche Probleme es zu lösen gilt. Denn aktuell gibt es zahlreiche Probleme, die dafür sorgen, dass Softwareentwickler Unittests in viel zu geringer Qualität und Menge herstellen. Dies wiederum hat sehr negative Auswirkungen auf die Wirtschaftlichkeit und Qualität des Softwaresystems. Es ist daher notwendig, qualitativ hochwertige Unittests in wirtschaftlich vernünftigem Ausmaß zu erstellen.
Anforderungen an eine KI-Unterstützung im Unit-Testing
Das Ziel eines Softwareentwicklers muss es sein, Unittests in möglichst guter Qualität in ausreichender Menge und mit maßgeblichem Einfluss auf die Softwarequalität zu erstellen – und genau darin liegt das Problem. In der Praxis ist Softwareentwicklern oft nicht klar,
- was gute Unittests sind,
- wie sie gute Unittests erstellen und
- welchen Einfluss der einzelne Unittest auf die Gesamtqualität hat.
Nicht jeder erstellte Unittest trägt maßgeblich dazu bei, die Qualität der Software sicherzustellen (vgl. [Kho20], S. 5 und 6). Um diese Probleme zu adressieren, hat sich daher in der Praxis die Verwendung von Clean-Code-Prinzipien (z. B. dem F.I.R.S.T. – Fast.Independent.Repeatable.Self-Validating.T imely-Prinzip, [Mar09], S. 132 f.) und Design-Patterns wie beispielsweise AAA (Arrange Act, Assert) [Mar09] bewährt.
Softwareentwickler verwenden außerdem Metriken wie die Code-Coverage, um die Testabdeckung von Testfällen auf den Quellcode und somit den Einfluss des Unit-Testings auf die Systemqualität zu bestimmen. Dies ist allerdings irreführend. Die Code-Coverage ist zwar eine wertvolle Metrik, um festzustellen, welche Teile des Quellcodes zu wenig mit Unittests abgedeckt sind, im Umkehrschluss kann jedoch nicht gesagt werden, dass jene Teile, die eine hohe Testabdeckung erreichen, auch qualitativ hochwertig sind und die Anforderungen erfüllen [Arg20]. Hierfür braucht es besseren Toolsupport.
Durch die Verwendung dieser Prinzipien, Kennzahlen und Muster kann es Softwareentwicklern gelingen, Unittests in qualitativ hochwertiger Form zu verfassen. Dies ist jedoch mit erheblichem Aufwand verbunden und geht zulasten der Effizienz des Teams. Das Einhalten dieser Grundregeln lässt jedoch folgende Probleme offen:
- Der Softwareentwickler empfindet Unit-Testing als eine langweilige, repetitive Aufgabe, bei der die Kreativität auf Grund der Regeln auf der Strecke bleibt.
- Die Testfälle unterscheiden sich nur mehr in den anzulegenden Testdaten.
- Softwareentwickler wissen nicht, wie gut die Qualität der erstellten Tests ist und wie groß der Einfluss eines Tests auf die Qualität der Software ist.
- Es ist auch nicht bekannt, ob genügend Tests vorhanden sind oder nicht.
Ein KI-basiertes Testtool muss also folgende Verbesserungen mit sich bringen:
- Eliminieren repetitiver Arbeiten.
- Fokus auf Anforderungen, nicht auf Syntax.
- Vorausfüllen und vorschlagen von passenden Testdaten.
- Einfaches Kombinieren von Testdaten zu Testfällen.
- Sichtbar machen von Qualitätsmetriken abseits der Code-Coverage.
- Vollautomatisches Generieren von Testcode.
- Massive Zeitersparnis für den Softwareentwickler.
KI-gestütztes Black-Box-Testing im Jahr 2021
Für diese anvisierten Verbesserungen gibt es nicht die eine KI-Lösung. Viel mehr benötigt es eine Kombination aus verschiedenen KI- und ML-Techniken sowie konventionellen Unit-Testing-Techniken.
Aktuell am Markt erhältliche Unit-Testtools lassen sich grob in Black-Box- und Whitebox-Testtechniken unterscheiden [Len20]. Während White-Box-Testtechniken ihre Berechtigung haben, sich jedoch nur auf den Code der Unit-under-Test konzentrieren, fokussieren sich Black-Box-Techniken voll und ganz auf die Anforderungen. Dadurch können mit Black-Box-Techniken Bugs gefunden werden, die aufgrund fehlender Anforderungen entstehen. Moderne KI-basierte Testtools fokussieren daher auf Black-Box- bzw. Gray-Box-Testverfahren (eine Kombination aus Black- und White-Box-Techniken).
Lösungsansätze
Da die Anforderungen in Softwareprojekten meist in Prosa verfasst sind, ist eine maschinelle Verarbeitung dieser Informationen jedoch sehr schwierig. Um dieses Problem zu lösen, wird eine geeignete Black-Box-Testmethode zum Modellieren der Anforderungen in KI-verträglicher Form benötigt. Eine Möglichkeit, dies zu tun, ist es, die Anforderungen mithilfe von Äquivalenzklassenbildung in Testmodellen festzuhalten (siehe Abbildung 1).

Abb. 1: Einfaches Beispiel: Äquivalenzklassen (ÄK) eines Prozentwerts
Softwareentwickler bilden dazu die Anforderungen in passenden Testfällen und Äquivalenzklassen ab [ISTQB]. Für jeden Eingabewert suchen sie passende Äquivalenzklassen, kombinieren diese zu Testfällen mit erwarteten Rückgabewerten und leiten daraus den Testcode ab. Da dies gut in maschinenlesbarer Form dargestellt werden kann, legt die Äquivalenzklassenbildung somit den Grundstein für den Einsatz von KI-Techniken zum Testen der Anforderungen.
Jedoch müssen Softwareentwickler viel Aufwand investieren, um
- gute Äquivalenzklassen pro Parameter zu finden,
- diese zu sinnvollen Testfällen zu kombinieren,
- die erwarteten Rückgabewerte zu modellieren und
- den Quellcode aus dem Testmodell abzuleiten.
Diese Aufwände werden nun durch eine Kombination von geeigneten KI-Techniken und konventionellen Algorithmen minimiert oder sogar vollständig eliminiert.
Finden sinnvoller Äquivalenzklassen mittels KI-Techniken
Sinnvolle Äquivalenzklassen können entweder (a) neu berechnet oder (b) aufgrund einer bestehenden Datenbasis anhand von Ähnlichkeiten vorgeschlagen werden (siehe Abbildung 2):
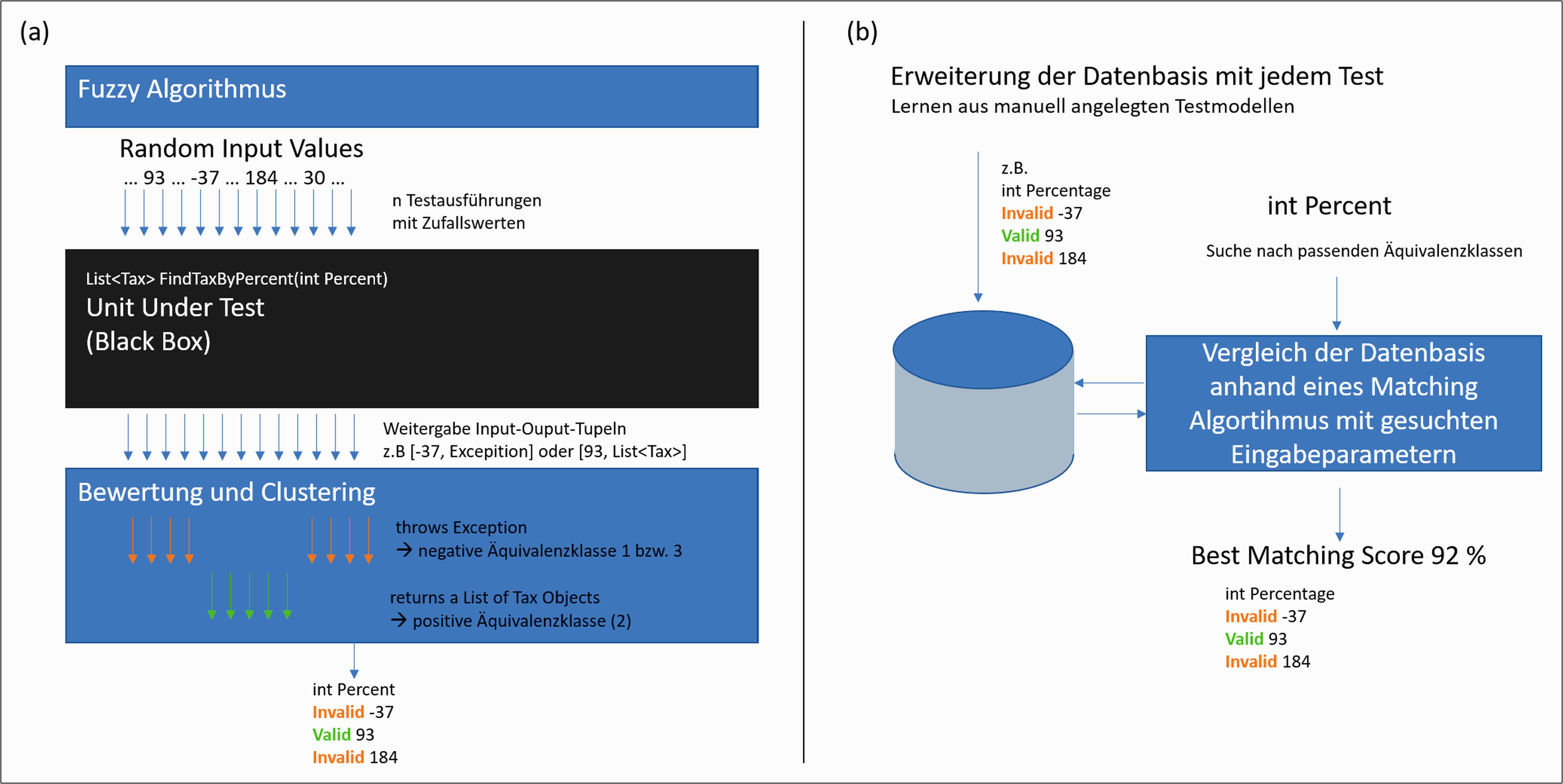
Abb. 2: Äquivalenzklassen können entweder (a) neu berechnet oder (b) aufgrund einer bestehenden Datenbasis anhand von Ähnlichkeiten vorgeschlagen werden
- (a) Zum Berechnen kann eine Clustering-Technik mit Fuzzing [Isp20] kombiniert werden, um Äquivalenzklassen zu bilden. Dabei führt ein Algorithmus die Unit-under-Test im ersten Schritt mit Tausenden Zufallswerten aus und bewertet und clustert im zweiten Schritt die Rückgabewerte nach gleichen Methodenverhalten. Diese Cluster bilden dann die gefundenen Äquivalenzklassen. Die generierten Eingabewerte stellen deren Repräsentanten dar.
- (b) Es besteht auch die Möglichkeit, die vom User über die Zeit händisch gebildeten Äquivalenzklassen und Repräsentanten zu sammeln und als Ausgangsbasis für Empfehlungen zu verwenden. Erstellt der User ein neues Testmodell, setzt eine intelligente Komponente die Eingabeparameter mit dieser Datenbasis in Beziehung, bewertet die Ähnlichkeit und empfiehlt die passenden Äquivalenzklassen und Repräsentanten.
Aufgrund dieser beiden Lösungsansätze lässt sich der Aufwand für die Definition der Äquivalenzklassen massiv vermindern.
Generieren und kombinieren sinnvoller Testfälle
Der Entwickler wählt zum Testen mit Äquivalenzklassen [ISTQB] pro Parameter mehrere Äquivalenzklassen mit mindestens einem Repräsentanten dieser Klasse aus. Er baut das Testmodell dann so auf, dass die verschiedenen Repräsentanten der Parameter zu Testfällen permutiert werden. Da dies jedoch zu sehr vielen, teilweise redundanten Testfällen führt, zu denen der Entwickler dann noch die richtigen Rückgabewerte setzen muss, ist dies mit viel Aufwand verbunden. Eine intelligentere Kombination von Testfällen ist also notwendig, die den Kompromiss zwischen Anzahl der Testfälle und Qualität des Testmodells optimiert.
Um dieses Optimierungsproblem zu lösen, kann ein Tool Regel-basierte Entscheidungsbäume und -algorithmen verwenden. Der Algorithmus nutzt die Menge alle potenziellen Tests und kombiniert diese zu einem optimierten Testmodelle mit möglichst guter Qualität. Dabei werden solange Testfälle hinzugegeben, bis keine signifikante Verbesserung der Qualität dieses Modells erzeugt werden kann.
Zur Beurteilung, wie hoch der Einfluss der einzelnen Testfälle auf die Qualität des Gesamtsystems ist, nutzen Tools eine Kombination aus Bewertungsfunktionen wie beispielsweise Mutation-Scores (vgl. [MT], [Len20] und [Jia11], S. 649 ff.) mit der klassischen Code-Coverage. Beim Mutation-Testing verändert (mutiert) die Lösung die Unit-under-Test ständig und führt das Testmodell gegen diese Veränderungen aus. Dann erkennt sie, ob der Testfall diese Mutanten aufdeckt.
Durch dieses Vorgehen analysiert die KI Schwachstellen im Testmodell und bewertet den Einfluss eines jeden Testfalls auf die Qualitätsmetrik. Ist dieser Einfluss zu gering, löscht die KI diesen aus dem Testmodell. Ein optimiertes Testmodell entsteht.
Erwartete Rückgabewerte automatisch generieren
Die Berechnung der Rückgabewerte mag auf den ersten Blick einfacher aussehen, als sie ist. Wenn ein Tool den Code ausführt und dieses Ergebnis für den Test verwendet, wird die aktuelle Funktionalität nur „einzementiert“, jedoch keine Anforderungen getestet. Durch diesen Ansatz werden also keine Bugs gefunden [Cha10]. Um dieses Problem zu lösen, nutzen Tools KI-Techniken wie beispielsweise Orakel-Funktionen [OTM] [Cha10]. Der sinnvolle Einsatz von Orakel-Funktionen ist aber aktuell noch ein offenes Forschungsthema, weshalb das Setzen dieser Rückgabewerte bis heute noch von Menschen gemacht werden muss.
Generieren von Quellcode aus Testmodellen
Das Tool generiert den Testcode auf Basis der durch die KI erstellten und optimierten Testmodelle. Dies passiert im klassischen Sinne mit herkömmlichen Codegeneratoren.
Stand der KI-Techniken im Unit-Testing 2021
In der Praxis nutzen bereits heute Tools wie devmate [DevM] zahlreiche Vorteile diverser KI-Techniken, um die Entwicklung von Unittests maschinell zu unterstützen. Eine der Hauptschwierigkeiten beim Testen ist jedoch, dass Tools die Anforderungen nicht automatisch in Testfälle umwandeln können. Softwareentwickler müssen immer noch Aufwand betreiben und ihre eigene Intelligenz investieren, um gute Testfälle zu erstellen. Moderne Tools verringern aber den Aufwand, der ins Unit-Testing investiert werden muss, um bis zu 75 Prozent [DevM], indem sie den Softwareentwickler unterstützen, langweilige Arbeiten abnehmen, sinnvolle Vorschläge machen und Code generieren. Dadurch kann sich der Softwareentwickler auf die spannenden, herausfordernden Aufgaben fokussieren.
Weitere Informationen
[Arg20] C. Arguelles u. a., Code Coverage Best Practices, Google, 7.8.2020, siehe:
https://testing.googleblog.com/2020/08/code-coverage-best-practices.html
[Cha10] W. K. Chan, J. C. F. Ho, T. H. Tse, Finding failures from passed test cases: Improving the pattern classification approach to the testing of mesh simplification programs, in: Software Testing, 20, no. 2, pp. 89-120, 2010
[DevM]
https://www.devmate.software/
[Isp20] K. K. Ispoglou u. a., FuzzGen: Automatic Fuzzer Generation, 29. USENIX Security Symposium, 2020, siehe:
https://www.usenix.org/system/files/sec20fall_ispoglou_prepub.pdf
[ISTQB] Äquivalenzklassenbildung,
https://istqb-glossary.page/de/aquivalenzklassenbildung/
[Jia11] Y. Jia, M. Harman, An Analysis and Survey of the Development of Mutation Testing, in: IEEE Trans. on Software Engineering, vol. 37, no. 5., 2011, siehe:
https://ieeexplore.ieee.org/document/5487526
[Kho20] V. Khorikov, Unit Testing Principles, Practices and Patterns, Manning Publications, 2020
[Len20] M. Lenger, Was ist ein guter Unit-Test? – Und wie entwickelt man ihn, in: Informatik Aktuell, 3.3.2020, siehe:
https://www.informatik-aktuell.de/entwicklung/methoden/was-ist-ein-guter-unit-test-und-wie-entwickelt-man-ihn.html
[Mar09] R. C. Martin, Clean Code: A Handbook of Agile Software Craftsmanship, Prentice Hall, 2009
[MT] Mutation Testing, siehe:
https://www.guru99.com/mutation-testing.html
[OTM] Orakel-Turing-Maschine, Lexikon der Mathematik, Spektrum, siehe:
https://www.spektrum.de/lexikon/mathematik/orakel-turing-maschine/7536









