

Komplexität erhöht das Fehlerrisiko. Das bedeutet, dass proportional zur Komplexität auch die Gefahr zunimmt, dass die Fehlerquote einer Software steigt. Denn letztlich müssen wir Softwareentwicklung als eine Art Transformation verstehen, bei der durchaus Übersetzungsfehler auftreten können: Anforderungen und Funktionen werden schließlich mithilfe von Programmiersprachen von einer anfänglich rein textuellen Beschreibung in echten Programmcode transformiert. Die Fehlerquellen und Schwierigkeiten, die daraus für die Erstimplementierung sowie die spätere Weiterentwicklung oder Wartung entstehen können, sind entsprechend vielfältig und den meisten Programmierern bekannt:
- fachliche Funktionen, die über viele verschiedene Programmbestandteile ohne erkennbaren Zusammenhang verteilt sind,
- eine nicht eindeutige Sprache bei der Bezeichnung von Klassen, Methoden und Variablen, welche die abzubildenden Dinge aus der realen Welt nur unzureichend oder gar nicht beschreiben und so das Codeverständnis insgesamt erschweren, oder
- die gefürchtete Frage, wo eine bestimmte Anforderung im Code zu finden ist. All dies ist nur ein kleiner Ausschnitt der Unwegsamkeiten, die sich von der Anforderungsspezifikation hin zum fertigen Softwareprodukt ergeben können.
Am Anfang war das Wort. DDD oder die allgegenwärtige Sprache
Am Anfang der Softwareentwicklung steht die Idee des Produkts. Meist in textueller Form, variiert sie in Umfang, Qualität und Dokumentenbezeichnung und stellt immer neue Herausforderungen, sowohl an das Projekt und Anforderungsmanagement als auch an die Entwicklung selbst.
Egal, ob es sich um Lastenhefte, Anforderungsdokumente oder eine lose Sammlung von E Mails handelt, gibt der Inhalt im Idealfall Aufschluss über alle benötigten Funktionen und Leistungsanforderungen an die Software. Mit steigendem Funktionsumfang der Software steigt auch der Umfang der Dokumente, was leider nicht immer zu einem besseren Verständnis der Anforderungen und zu schlüssigen und widerspruchsfreien Beschreibungen von Funktionen führt. Schnell wird bei umfangreichen Dokumenten etwas vergessen. Oder Abläufe werden nicht vollständig dokumentiert, unterschiedliche Bezeichnungen für ein und dasselbe verwendet oder Widersprüchliches gefordert. All das stellt den Softwareerstellungsprozess vor große Herausforderungen und kann dazu führen, dass die Software an den Anforderungen des Kunden vorbei entwickelt wird.
In einer idealen Welt wird deshalb das rohe Anforderungsmaterial in eine sorgfältige Spezifikation überführt, die das Erstellen einer Software in der gewünschten Ausprägung und mit dem gewünschten Funktionsumfang sicherstellt oder zumindest deutlich begünstigt. Das Schreiben von Spezifikationen sollte deshalb immer in enger Abstimmung mit dem Kunden geschehen und ein unmissverständliches Dokument dessen sein, was die fertige Software am Ende leisten soll. Es handelt sich daher nicht nur um eine Schärfung und Konkretisierung des Funktionsumfangs und der Leistungsanforderungen, sondern auch um das Erschaffen einer gemeinsamen Sprache, die auf Kunden und Entwicklerseite gleich verstanden wird und keinen Interpretationsspielraum beziehungsweise keine Missverständnisse zulässt.
Diese „allgegenwärtige“ Sprache (von Eric J. Evans in seinem 2003 bei Addison Wesley erschienenen Buch Domain-Driven Design – Tackling Complexity in the Heart of Software „ubiquitous language“ genannt) wäre aber nicht allgegenwärtig, wenn sie nur in Anforderungsdokumenten und Spezifikationen oder im Gespräch mit dem Kunden Verwendung fände. So liegt der Gedanke nahe, sie auch im eigentlichen Code zu verwenden. Begriffe, die in Anforderungen, Spezifikationen oder in Gesprächen genutzt werden, sollten sich laut Evans folglich genauso auch im Code wiederfinden, um besser nachvollziehen zu können, wo sich die beschriebenen Funktionen aus der Spezifikation im Code wiederfinden. So können auch die dort definierten Abläufe eins zu eins in den Code überführt werden. Anstatt also im Code neue Begrifflichkeiten zu verwenden, findet mit dem Konzept der allgegenwärtigen Sprache eine Art Projektion von der Spezifikation auf den Code statt.
DDD in der Praxis
In meinem Arbeitsalltag als Softwareentwickler für große Industrieanwendungen kannte ich Domain Driven Design (DDD) zunächst nur als nachträglich implementierte Methode zur Weiterentwicklung bestehender Legacy Software. Es zeigte sich schnell, dass die grundlegenden Prinzipien des DDD auch bei Bestandssoftware Wirkung zeigen und auch hier viele positive Impulse geben können:
- Der geschriebene Code orientiert sich in seiner Struktur stärker an den Anforderungen und ist dadurch viel verständlicher.
- Die Einführung von Serviceklassen mit Methoden, welche konkrete fachliche Funktionen abbilden, schafft deutlich mehr Übersicht und Struktur.
- Das Schreiben von Tests für fachliche Funktionen wird durch Serviceklassen ebenfalls vereinfacht.
Aber erst beim vollumfänglichen Einsatz von DDD im Kontext einer Produktneuentwicklung entfaltet die Methodik ihre ganze Wirkung. Selbst dann, wenn wir nicht strikt nach Lehrbuch vorgehen,sondern uns eine gewisse Freiheit bei der Anwendung bewahren. Und fairerweise muss auch gesagt werden, dass die Vorarbeit des Kunden an den Anforderungsdokumenten einen großen Teil zum Gesamterfolg beiträgt.
Bei der Sichtung von Anforderungsdokumenten wird nämlich schnell klar, ob der Kunde überhaupt eine konkrete Vorstellung von den Geschäftsprozessen hat, die er in seiner Software umgesetzt haben möchte. Funktionen, die solche Geschäftsprozesse abbilden, sind häufig als sogenannte Business Cases definiert. Diese sind in ihrer Struktur immer gleich: Sie definieren neben der gewünschten Funktion als solcher auch die benötigten Zugriffsrechte für den Nutzer, eingehende optionale und nicht optionale Parameter, etwaige Vorbedingungen und mögliche Rückgabeparameter. Der Typ dieser Parameter ist wiederum vollständig in einem Klassendiagramm erfasst – zumindest dann, wenn es sich um einen komplexen Typ handelt: Dann hat er hier immer einen eindeutigen Namen, alle Felder sind mit Typangabe und möglichen Beschränkungen aufgeführt (z. B. optional, nicht optional, Länge, Inhalt usw.). Darüber hinaus sind die Relationen zu anderen Typen dargestellt.
Ideale Voraussetzungen, um diese Business Cases ganz im Sinne von DDD unverändert im Code zu übernehmen, sollte man meinen. Doch kann dieser Prozess auch gestört werden. Hier eine kleine Liste möglicher Störungen und wie wir sie meistern können:
- Wenn die Anforderungen mit Hinweisen oder Fülltext durchsetzt sind: Dann erkenne das Wesentliche und extrahiere weitere für die Entwicklung relevante Informationen – sofern vorhanden.
- Wenn die Anforderungen die fachlich notwendigen Strukturen entweder gar nicht oder nur unvollständig beschreiben: Dann kläre mit der Fachseite, welche Strukturen benötigt werden, und erarbeite schlüssige Bezeichnungen.
- Wenn Bezeichnungen von Typen oder Feldern nicht einheitlich sind: Dann bestehe auf einem einheitlichen Sprachgebrauch und überprüfe, ob nicht doch unterschiedliche Dinge gemeint sind.
- Wenn die geschilderten Abläufe aus zu großer Höhe beschrieben sind und so das Verständnis oder die direkte Abbildung im Code erschweren: Dann betrachte zunächst Teilbereiche des Ablaufs und teile sie in logisch zusammenhängende kleinere Abläufe ein.
- Auch wenn eine Anforderung zunächst den Eindruck vermittelt,genauso umsetzbar zu sein, wie sie geschrieben steht: Dann prüfe dennoch zunächst die Umsetzbarkeit und den realen Nutzen, bevor es losgeht.
Muss das sein oder kann das weg?
Moderne Softwareanwendungen mit zigtausend Zeilen Code vereinen in sich eine Vielzahl unterschiedlicher Funktionen. Deshalb gilt beim DDD grundsätzlich: Weniger ist mehr! Wer unnützen Ballast abwirft, spart Entwicklungszeit und erleichtert das allgemeine Verständnis des Codes – beim Entwickler wie beim Kunden. Die positiven Effekte bei der späteren Pflege und Wartung der Software müssen nicht eigens genannt werden: mehr Transparenz, mehr Effizienz, weniger Risiko.
Die Gefahr: Babylonische Sprachverwirrung
Die eingesetzte Programmiersprache richtet sich entweder nach der Empfehlung des Softwaredienstleisters oder nach dem Wunsch des Kunden. In der Frage der Sprache für Klassen , Methoden und Feldnamen herrscht unter Entwicklern zumeist Einigkeit – hier ist Englisch schon deshalb die erste Wahl, weil der Großteil der Fachliteratur und nahezu alle Informationsquellen englisch sind. Ein Bruch im Code scheint daher wenig sinnvoll.
Die Entwicklung beim DDD beginnt damit, grundlegende Datenstrukturen anzulegen. Folgen wir dem Grundsatz der allgegenwärtigen Sprache, ist es wünschenswert, die Typ und Feldnamen im Code so zu verwenden, wie der Kunde sie vorgegeben hat. Doch ist das auch dann so, wenn vom Kunden in einer anderen Sprache als Englisch kommuniziert wird? In meinem Erfahrungsbeispiel sind die vorliegenden Anforderungsdokumente nämlich alle in Deutsch verfasst und eine Übersetzung ins Englische wurde verworfen, weil es für die verwendeten Fachbegriffe kaum treffende englische Entsprechungen gibt. Das hat zur Folge, dass das verwendete Fachvokabular weit vom Wortschatz der meisten Softwareentwickler entfernt ist: Bei Feldnamen wie „BetragsgrenzeInnergemeinschaftlicherErwerb“ ist nicht nur der gedankliche Spagat zwischen beiden Sprachen groß, sondern auch die Versuchung, durch eine sprachliche Neukreation ungewollt Fehler zu provozieren.
Nach den Prinzipien des DDD wäre die Verwendung deutscher Begriffe an sich folgerichtig, sofern sie auch in den Anforderungen deutsch sind. Aber wo alte Gewohnheiten herrschen, ist es nicht leicht, diese Entscheidung zu treffen und sie einvernehmlich umzusetzen. Fühlt es sich in fachlichen Codeteilen zunächst noch gut an, Deutsch zu verwenden, wird es spätestens bei den technischen Konstrukten zunehmend ungewohnt: Wenn aus dem weitläufig verwendeten Feldnamen „pk“ für „primary key“ eines Datenbankobjekts konsequenterweise „ps“ für „Primärschlüssel“ wird oder aus dem Datumsfeld „validFrom“ ein „gültigAb“, und das dann mit den englisch gehaltenen Schlüsselbegriffen kollidiert, kommt schnell Unmut auf. Hinzukommt, dass der Anblick von Umlauten im Code für Softwareentwickler mehr als gewöhnungsbedürftig ist.
Die Lösung: ein Zweischichtenmodell
Die Antwort auf die geschilderte Sprachverwirrung ist eine klare Trennung zwischen fachlichen und technischen Anforderungen, sprich zwischen dem Anwendungscode, der die fachliche Domäne des Kunden darstellt, und dem Anwendungscode, der die technischen Funktionen definiert (Datenbankzugriffe, Jobs usw.). Die „allgegenwärtige“ Sprache bleibt so im Code erhalten, ein Übersetzen gängiger Code Kürzel entfällt.
Dies sind die wichtigsten Vorteile des Zweischichtenmodells im Überblick:
- Fachliche und technische Funktionen im Code können besser unterschieden werden: Demjenigen, der den Code nicht selbst entwickelt hat, muss er zwangsläufig als unübersichtliches Konglomerat völlig unterschiedlicher Artefakte vorkommen. Das Zweischichtenmodell räumt auf, indem es diese Gemengelage in zwei sortenreine Schichten trennt.
- Der Kunde kann in der fachlichen Schicht selbstständig Codereviews durchführen: Die Zeiten, wo Software eine Blackbox war, die nur Eingeweihte verstehen, sind vorbei. Immer häufiger interessiert sich der Kunde dafür, wie seine Anwendung von innen aussieht, und möchte sich selbst ein Bild von der Codequalität machen. Das Zweischichtenmodell erleichtert ihm das Verständnis dessen, was er dort sieht.
- Der fachliche Code kann leichter mit den Anforderungsdokumenten abgeglichen werden: Papier ist geduldig. Wer prüfen möchte, ob die Realität des Codes der Theorie der Dokumente entspricht, kann das in einer fachlichen Schicht viel einfacher gegenchecken.
- Der technische Code kann risikoärmer weiterentwickelt, ausgetauscht oder aktualisiert werden: Je übersichtlicher die Lage im Code, desto leichter sind auch der Austausch oder die Weiterentwicklung einzelner technischer Bestandteile.
Abbildung 1 zeigt die Projektion der Spezifikation auf den fachlichen Code in der Domänenschicht. Diese Schicht beinhaltet die fachlichen Datentypen und funktionen unter Verwendung von Bezeichnungen, die in der allgegenwärtigen Sprache festgelegt sind. Technischer Code, zum Beispiel für Datenbankzugriffe oder E Mail Versand, ist entkoppelt und in der Technikschicht zusammengefasst.
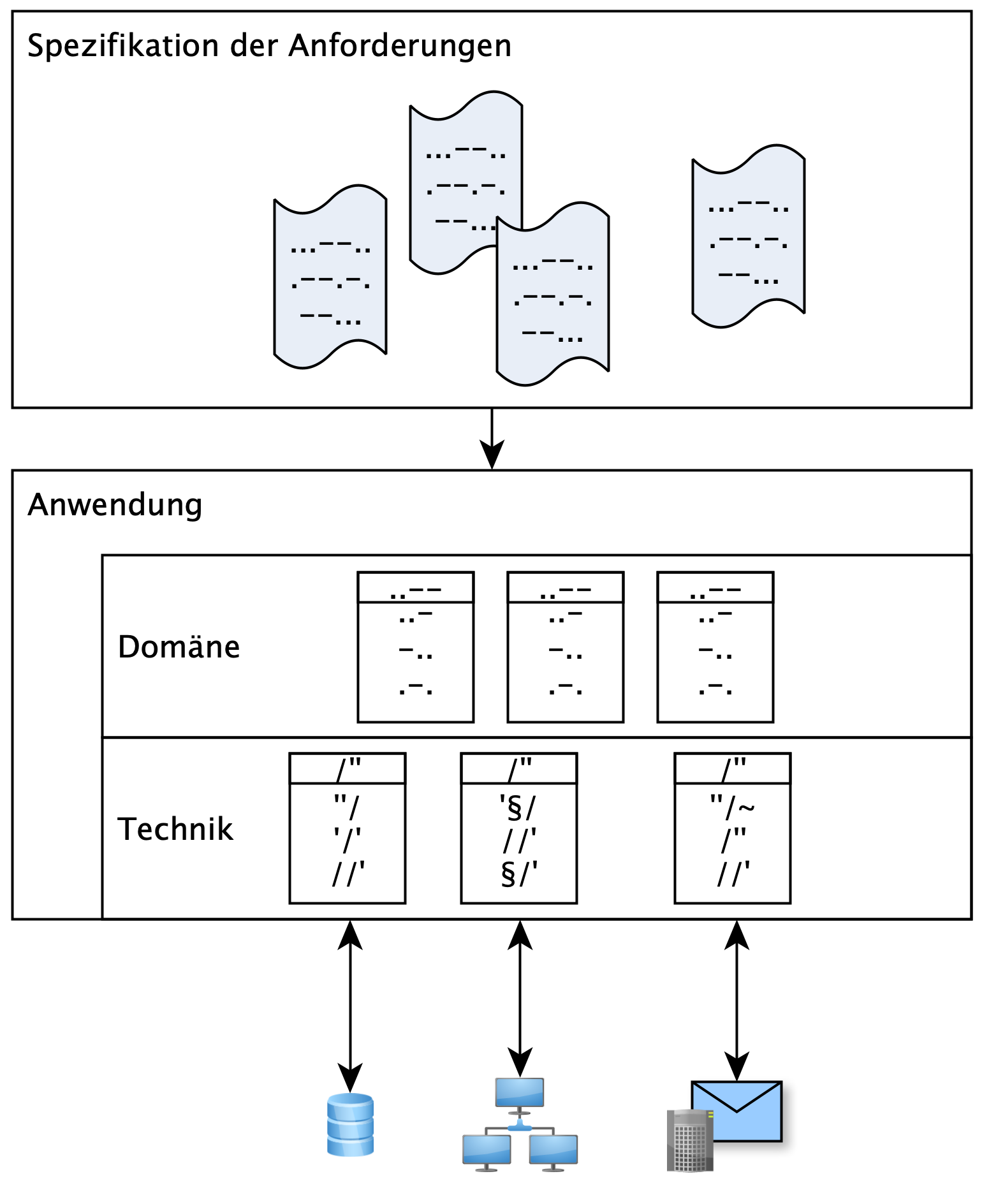
Abb. 1: Projektion von fachlichen Funktionen auf den Code in der Domänenschicht
Allgegenwärtige Bildersprache
Wäre eine Software schon fertig, wenn die Datenstrukturen und die Definition von Feldtypen und Beschränkungen fertig sind, hätten wir Softwareentwickler wenig zu tun. Zum Glück ist das ja nicht der Fall. Denn der spannendste Teil der Softwareentwicklung ist die Abbildung von Prozessen im Code. Mit einer entsprechenden Aufrufreihenfolge von Methoden und durch Verwendung von Kontrollflussanweisungen lassen sich nahezu beliebig komplexe Prozesse abbilden die Abbildung von Prozessen ist schließlich Alltag in der Softwareentwicklung.
Wie wir wissen, liegt die Beschreibung der gewünschten Abläufe zumeist in textueller Form vor. Es mag an der Unpopularität von UML liegen, aber Aktivitätsdiagramme zur Darstellung von Prozessen sind selten. In meinem Erfahrungsbeispiel haben wir bei der Produktneuentwicklung immer dann auf Aktivitätsdiagramme gesetzt, wenn es die Komplexität der abzubildenden Prozesse sinnvoll erscheinen ließ. Ein guter Gradmesser für die Komplexität war für uns die Menge an unterschiedlichen Ausführungspfaden und somit an verschiedenen Ausgängen, die die Ausführung eines Prozesses haben kann. Die Frage, wann eine kritische Menge an Ausführungspfaden erreicht ist, die den Einsatz eines Aktivitätsdiagramms rechtfertigt, ist nicht pauschal zu beantworten. Generell schadet es aber nicht, eine Visualisierung zu haben, die gut auf den Code projizierbar ist. Ziel sollte immer sein, eine möglichst hohe Deckungsgleichheit zwischen der Beschreibung einer Funktion in der Spezifikation und ihrer Entsprechung im tatsächlichen Code zu erreichen. Da UML nicht jedem geläufig ist und die Darstellungen auch für Projektleitung und Fachseite leicht verständlich sein sollen, haben wir darauf verzichtet, hundertprozentig UML konforme Aktivitätsdiagramme zu erzeugen. Stattdessen haben wir uns vom Motto „Keep it simple“ leiten lassen, was den Einsatz von speziellen UML Werkzeugen überflüssig gemacht hat.
Abbildung 2 zeigt den beispielhaften Businessprozess als Ablaufdiagramm und wie die Visualisierung eines Prozesses für die Spezifikation aussehen kann. Der freie Grapheditor yEd eignet sich zur Erstellung solcher Diagramme sehr gut. Die „Beispielfunktion“ nimmt einen String Parameter „Wert“ entgegen. Je nach Vorkommen bestimmter Buchstaben werden bestimmte Operationen ausgeführt.
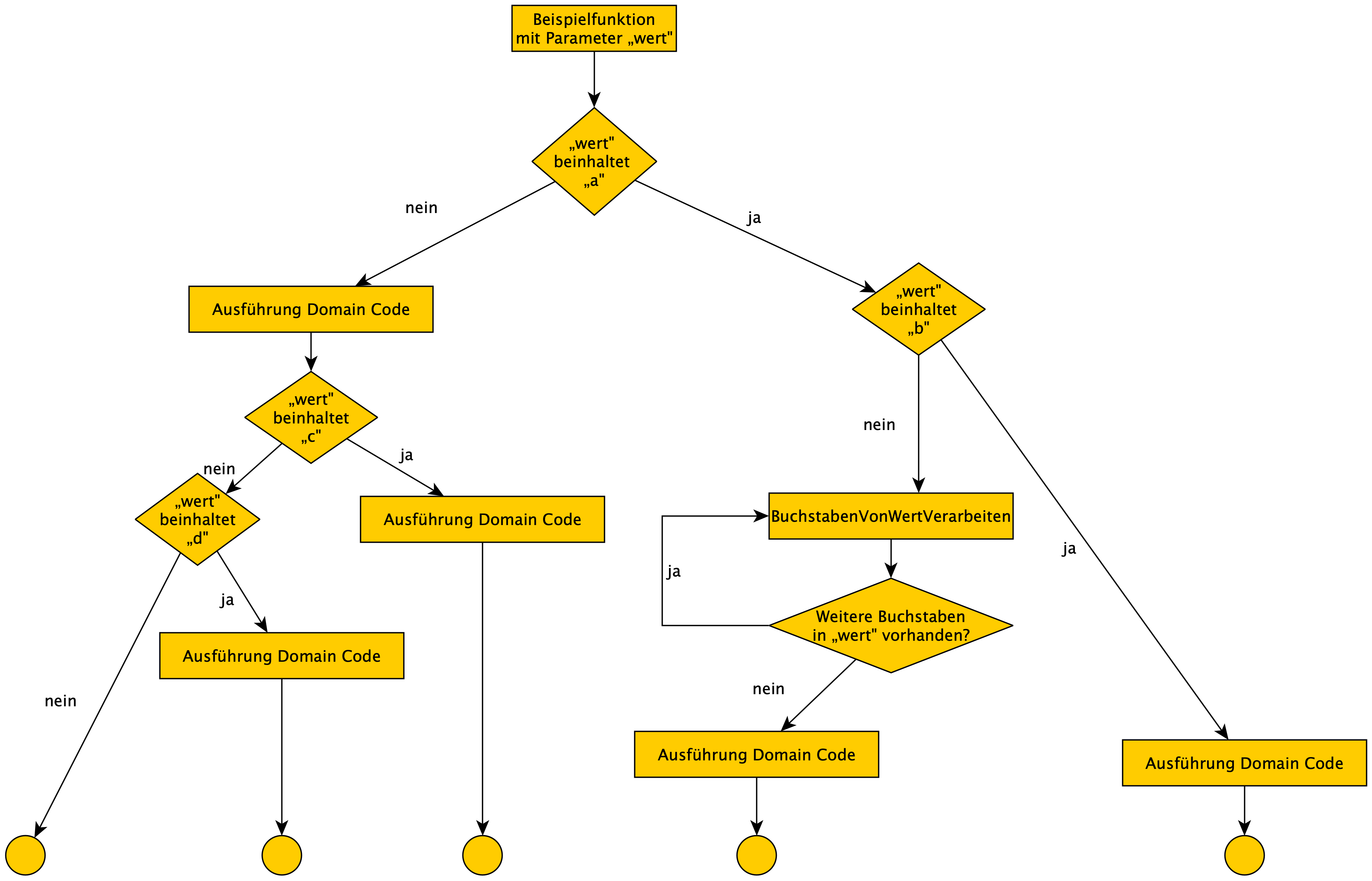
Abb. 2: Beispielhafter Businessprozess als Ablaufdiagramm
Eine Umsetzung im Code zeigt Abbildung 3. Wichtig ist hier die genaue Orientierung am Aktivitätsdiagramm:
- Der Methodenname ist identisch mit der fachlichen Bezeichnung „Beispielfunktion“.
- Der Parametername ist identisch mit der fachlichen Bezeichnung „Wert“.
- Anweisungen aus dem Diagramm, für die eine eigene Methode nicht zwingend notwendig ist, sind in Kommentaren genannt („BuchstabenVonWertVerarbeiten“).
- Kontrollflussanweisungen im Code zeigen den Ablauf wie im Diagramm.
- Ausführungspfade, die den Prozess beenden, ohne weiteren Code auszuführen, sind trotzdem vorhanden. Der leere Block ist mit dem Kommentar NOOP („No operation“) versehen.
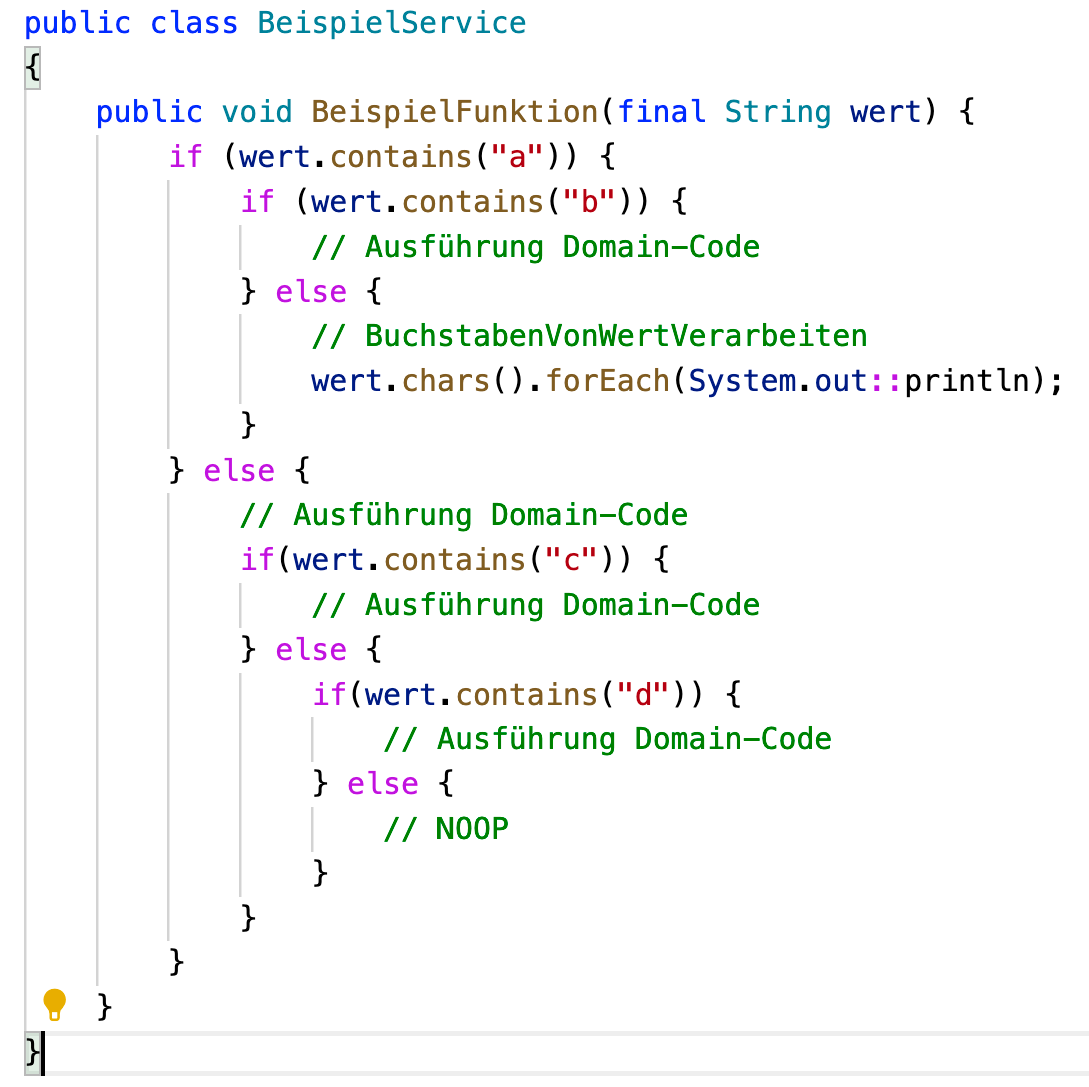
Abb. 3: Der gleiche Businessprozess als Code
Wer den letzten Punkt als unschön empfindet, kann den leeren oder nur mit einem Kommentar versehenen Block auch weglassen. Neben der allgegenwärtigen Sprache haben wir so auch eine allgegenwärtige Bildersprache.
Der Kitt, der alles zusammenhält
Wie beschrieben, befinden sich die fachlichen Datenstrukturen und Funktionen in der Domänenschicht. Dem Prinzip des DDD folgend, gruppieren wir die Funktionen dort auf zwei Arten:
- Funktionen, die fachliche Abläufe repräsentieren, und
- Funktionen, die Daten im Sinne der Fachlichkeit bereitstellen.
Das DDD Konzept sieht dafür zwei Strukturen für die Beheimatung dieser Funktionen vor: Service und Repository Klassen. Die Funktionen der Service Klassen sind als zentrale Einstiegspunkte in die Anwendung zu verstehen und können dort in Aufrufe von Repository oder Service Klassen verzweigen. Wie bei den fachlichen Datentypen bleiben wir hier der deutschen Sprache treu, um nicht schon in der Domänenschicht einen Sprachenbruch zu haben. Die Methodennamen geben wieder, um welchen fachlichen Ablauf es sich handelt.
Wichtig ist, dass für jede Stelle im Code die jeweils zugehörige Stelle im Anforderungs beziehungsweise Spezifikationsdokument auffindbar ist, gleiches gilt auch für die Repository Klassen. „Service“ und „Repository“ dienen deshalb als Präfix für den Klassennamen und erleichtern so das Auffinden dieser Konstrukte. Auch hier lässt sich, wie man sieht, ein gewisser Sprachenmix nicht vermeiden: Denn während der Begriff „Service“ im Deutschen wie im Englischen gleich ist, ist die Übersetzung des Begriffs „Repository“ ins Deutsche, zum Beispiel mit „Depot“ oder „Lager“, ungebräuchlich und deshalb nicht empfehlenswert. Leitbild sollte uns hier wie gesagt immer das Vokabular der internationalen Fachliteratur sein – und das ist Englisch.
Die Methodennamen in Repository Klassen geben uns jedenfalls schnelle Auskunft darüber, welche Kriterien zur Ermittlung der Daten herangezogen werden. Wer mit dem Spring Data Framework vertraut ist, kennt das bereits. Hier sind Methodennamen inhaltlich so eindeutig, dass nicht nur Missverständnisse über deren Funktionsweise selten sind, sondern Spring Data daraus sogar die konkreten Abfragen an die Datenbank ableiten kann.
Wie bereits erwähnt, finden sich in der Domänenschicht Klassen, welche die fachlich benötigten Daten zusammenfassen. Diese Domänenklassen werden von Service und Repository Klassen erwartet und verarbeitet. Um die klare Trennung zwischen Domänen und Technikschicht beizubehalten, beinhalten die Domänendatenstrukturen keinerlei technische Informationen, wie etwa einen Primärschlüssel aus der Datenbank (sofern vorhanden) oder ähnliches.
Damit wird, wie weiter oben schon gesagt, der Blick auf die fachlich relevanten Daten nicht von technischen Dingen abgelenkt – und dies führt zu einer einfacheren Handhabung des Domänencodes. Ein Beispiel: Sagen wir, unsere Anwendung sieht vor, bestimmte Daten so zu speichern, dass sie nur für einen bestimmten Zeitraum gültig sind. Das heißt, für eine bestimmte Entität können zum Zeitpunkt X andere Werte gelten als zum Zeitpunkt Y.
Die rein technische Umsetzung wäre eigentlich eine 1 zu n Relation. In den referenzierten Objekten befinden sich die für den gewünschten Zeitraum gültigen Werte. Was für das Speichern in der Datenbank ein gängiger Weg ist, erweist sich für die Anwendung und die von ihr benötigten Datenformate indes als zu komplex, weil hier die zu speichernden Daten nur zu genau einem Zeitpunkt relevant sind. Dies führt dazu, dass wir in der Domänenklasse auf die 1 zu n Relation verzichten und stattdessen nur die benötigten Daten bereitstellen.
Da Domänenklassen frei von technischem Code bleiben sollen, führen wir ein Pendant in der technischen Schicht ein. Die Rede ist von DO Klassen, die auch namensgebend für das Präfix dieser Klassen und im Java Umfeld weit verbreitet sind. Sie beinhalten alle Informationen, mit denen ORM Frameworks wie Hibernate eine Abbildung auf die Datenbank vornehmen können. Unsere Anwendung bedient sich dieser Technologie und hinterlegt die Transformation von Domänenklassen in DO Klassen und umgekehrt. Um keinen technischen Code in den Domänencode durchsickern zu lassen, nehmen die Methoden der Repositories nur Domänenklassen an und geben, falls nötig, auch nur Domänenklassen zurück. Die Verwendung von Repository Methoden in Services wird dadurch deutlich verschlankt.
Das Konzept der Domänenklassen wurde hinsichtlich einer für die Anwendung benötigten GUI noch weiter verfeinert. Funktionen in der GUI benötigen nämlich oftmals Informationen, die inhaltlich nicht in eine Domänenklasse passen. Das können beispielsweise Steuerinformationen für Bestandteile der Oberfläche sein, die vom Server bereitgestellt werden. Für diese Fälle bieten sich spezialisierte Datenstrukturen an, die die gewünschten Informationen liefern können, was seinerseits zu einer sauberen Trennung zwischen GUI und Domänen Code beiträgt.
Fazit
Der Einsatz von Domain Driven Design zeigt schon in der frühen Phase des Softwareerstellungsprozesses seine positive Wirkung. Zum einen ist da die allgegenwärtige und gemeinsame Sprache, deren positive Effekte ich im Laufe des Textes beschrieben habe. Von besonderer Relevanz ist sicher, dass Mehrdeutigkeiten und Verständnisprobleme zwischen Auftraggeber und Softwaredienstleister deutlich reduziert werden und dass der Abgleich zwischen Dokumentation und Code die Qualität der fertigen Software signifikant steigert.
Zum anderen führt die klare Trennung von Domänen und Technikcode zu einem generell besseren Verständnis des Codes insgesamt, was insbesondere dann von Vorteil ist, wenn mehrere Entwickler oder ganze Entwicklergenerationen an einer Anwendung arbeiten, die über Jahre gewachsen ist. Übergaben und Einarbeitungszeiten werden durch eine gute Orientierung im Code nämlich ebenfalls deutlich reduziert.
Auch für Unittests hat die Trennung von Domänen und Technikcode positive Folgen. Die Frage, ob fachlicher Code durch Unittests abgedeckt wurde, ist so leichter zu beantworten, da durch die Trennung offensichtlicher ist, wo sich fachliche Programmteile befinden. Dieser Effekt wird verstärkt durch die Verwendung von Service Klassen, deren Methoden Einstiegspunkte in die Fachprozesse bilden.
Die Liste der positiven Aspekte von Domain Driven Design lässt sich sicher noch weiter fortsetzen. Hier habe ich mich auf diejenigen konzentriert, die in meinem individuellen Alltag als Softwareentwickler besonders deutlich hervortreten.









