

Die verbreitetste Datenbank ist nicht etwa MySQL oder MS Access, sondern SQLite, das in Zehntausenden Anwendungen (mehr als eine Billion Datenbanken) in unseren Mobiltelefonen, Webbrowsern, Spielen, Fernsehern und anderen Geräten genutzt wird, um schnell und effizient strukturierte Daten abzulegen und mit SQL zugreifbar zu machen. Der besondere Reiz liegt darin, dass SQLite als Bibliothek einfach in Programme integriert werden kann und dann innerhalb des eigenen Prozesses läuft, ohne einen separaten Server zu betreiben. SQLite ist eine volltransaktionale OLTP-Datenbank mit einer extrem guten Testabdeckung und Verifikation. Im Podcast [SQLitePodcast] hat der Erfinder, Richard Hipp, die Geschichte der Datenbank anschaulich dargelegt.
DuckDB – „SQLite für Datenanalyse”
DuckDB ist der analytische OLAP-Zwilling dazu, also „SQLite für Datenanalyse”. Von Hannes Mühleisen und Mark Raasveldt als Senior Researcher beziehungsweise Doktorand am CWI (Centrum Wiskunde & Informatica) in Amsterdam entwickelt, hat DuckDB ihren Ursprung in der Erkenntnis, dass Data Scientists in R oft kein SQL benutzten, weil keine gute Datenbankintegration für R existierte und Client-Server-Datenbanken unpraktisch waren. Ausgehend von „wie schwer kann das den sein”, ist während nunmehr 8 Jahren
Arbeit erst im universitären und jetzt auch im kommerziellen Umfeld ein beeindruckendes Datenbanktool entstanden, das Anwendern weit über R hinaus den Zugang zur effizienten Datenanalyse ermöglicht. DuckDB ist in C++ 11 implementiert, hat keine weiteren Abhängigkeiten und ist als quelloffene Software unter der MIT-Lizenz veröffentlicht.
Oft assoziieren wir mit der Analyse von Datenmengen im zweioder dreistelligen Gigabytebereich größere Spark-Cluster oder DWH-Lösungen wie Snowflake, PowerBI, Cognos, Redshift oder Ähnliches. Jede davon mit den entsprechenden Investitionen in Infrastruktur, Zeit, Datentransfer und Komplexität.
Der Gründer von Motherduck, Jordan Tigani, einer der originalen Entwickler von Googles BigQuery, hat dazu im Artikel „Big Data is Dead” [BigData] Stellung genommen – die meisten Datensets sind nicht gigantisch (median 100 GB) und die wichtigsten Analysen erfolgen auf den jüngsten Daten, oft nur wenige Hundert Megabytes. Wie schon von Frank McSherry [McSherry] in 2015 demonstriert, kann man mit einer effizienten Implementierung unter Ausnutzung all der mächtigen Eigenschaften moderner CPUs (Vektorisierung, massives Pipelining, sehr große CPU-Caches) und aktueller Algorithmen der Datenbankforschung große Datenmengen selbst auf einem einzelnen Thread verarbeiten. Diesen Ansatz hat sich DuckDB auch zu eigen gemacht und ermöglicht damit effiziente, lokale Datenanalyse.
Erste Beispiele
Aber genug der Einleitung, am besten machen wir uns gleich einmal mit DuckDB vertraut. Keine Angst, die Ente beißt nicht. Entweder per Paketmanager, Python Installer (pip) oder einfach per [Download] kann die kompakte Installation auf den eigenen Computer geholt werden (s. Listing 1).

Listing 1: Installation
Aktuell ist gerade Version 0.8.1. Danach sind sowohl die Kommandozeilenanwendung duckdb als auch die jeweiligen Bibliotheken verfügbar. Wie schon erwähnt, gibt es keinen Datenbankserver, die Datenbank läuft direkt im Prozess der Anwendung. Es gibt auch eine In-Browser-Option [Web-Shell], die in einer WASM Sandbox läuft. Netterweise kann man auch komplett ohne Persistenz, das heißt mit einer reinen Hauptspeicherdatenbank, experimentieren.
Unser erstes Beispiel ist zwar ein „Hello World”, aber wir steigen gleich auch weiter ein, mit String-Operationen, Transposition (unnest), Aggregation und Sortierung (s. Listing 2). Für die Anzeige der Ergebnisse kann man zwischen verschiedenen Modi mittels .mode <name> wählen. Wir haben bisher duckbox gesehen, es gibt auch csv, json, jsoline und line (jeder Wert auf einer neuen Zeile), html, insert, trash (keine Ausgabe) und andere mehr. Andere nützliche Kommandos der CLI sind mittels .help verfügbar, .timer on gibt zum Beispiel die Laufzeit eines Statements aus.

Listing 2: Hallo Welt!
Bei Fragen steht die umfangreiche und detaillierte Dokumentation [DuckDBDocs] zur Verfügung und eine sehr hilfsbereite Community beantwortet Fragen auf [DuckDBDiscord].
DuckDB unterstützt einen Großteil des SQL-Standards, bringt zusätzlich noch viele nützliche Funktionen mit. Sehr angenehm ist auch, dass die Datenbank relativ einfach mit weiterer Funktionalität erweitert werden kann. Diese Erweiterungen werden der eigenen Installation mit INSTALL name/url und LOAD name hinzugefügt und stehen ab dann allen APIs zur Verfügung. Es gibt Erweiterungen für verschiedene Dateiformate und -quellen, Volltextsuche, Geodaten und vieles mehr. Wiederholte Konfiguration und Nutzung kann in $HOME/.duckdbrc abgelegt werden.
Ein sehr nützlicher Einsatzzweck von DuckDB ist die Analyse existierender Daten, die irgendwo in der Cloud via https oder Cloud Storage (S3, GCP, HDFS) zur Verfügung stehen, ohne dass man diese erst manuell herunterladen und importieren muss. Des Weiteren gibt es integrierte Unterstützung für CSV und eine Erweiterung für JSON und Parquet. Damit können wir im nächsten Schritt gleich mal ein paar Daten aus dem Internet analysieren, zum Beispiel Bevölkerungszahlen von Ländern [CSV] wie in Listing 3 zu sehen.

Listing 3: Bevölkerungszahlen analysieren
Die Integration zum Lesen und Schreiben verschiedener Datenformate ist wirklich beachtlich. Neben CSV- und JSON-Dateien können auch SQLite- und Postgres-Datenbanken verarbeitet werden. Besonders die Unterstützung von Parquet und Arrow ist weit gediehen, dort können Filter und Selektions-Prädikate von SQL schon in der Zugriffschicht ausgeführt und somit die zu ladende Menge von Daten erheblich reduziert werden.
Ein weiterer praktischer Einsatzzweck ist die Kombination von Datenbereinigung und Formatkonvertierung. So können zum Beispiel Daten aus JSON oder CSV gelesen und bereinigt und dann als Parquet abgespeichert werden.
Metadatenanalyse
DuckDB hilft uns auch dabei, Metadaten von Tabellen zu untersuchen (describe) und zu modifizieren, siehe Listing 4. Mit read_csv_auto beziehungsweise read_csv(AUTO_DETECT=true) versucht DuckDB mittels einer Stichprobe die Datentypen der Spalten herauszufinden, fällt aber im Zweifelsfall auf Stringtypen VARCHAR zurück. Außer den Spalten Country und Region sollten aber alle anderen Spalten Integer- oder Dezimalzahlen sein.

Listing 4: Metadaten
Mittels types={'spalte': 'typ'} können wir selbst die Standard-SQL-Typen angeben, die für spezifische Spalten genutzt werden sollen. Man kann auch in eine existierende Tabelle importieren, dann wird deren Schema genutzt:
COPY countries FROM 'countries of the world.csv' (AUTO_DETECT TRUE);
DuckDB kennt einige zusätzliche Typen wie:
- Enums für abgezählte Werte,
- Listen/Arrays,
- Map für Schlüssel-Wert-Paare,
- Structs für wiederkehrende Strukturen,
- Date, Timestamp, Interval,
- Bitstring,
- Blob,
- NULL,
- Union (von Datentypen).
Es gibt natürlich auch „Meta”"-Funktionen, mit denen man die Datenbank selbst inspizieren kann, hier sind einige davon aufgelistet, mittels
select function_name from duckdb_functions() where function_name like 'duckdb_%';
Für den SQL-Standard sind einige davon auch im information_schema-Schema als Tabellen verfügbar:
- duckdb_keywords()
- duckdb_types()
- duckdb_functions()
- duckdb_databases()
- duckdb_schemas() - information_schema.schemata
- duckdb_tables() - information_schema.tables
- duckdb_views()
- duckdb_sequences()
- duckdb_constraints()
- duckdb_indexes()
- duckdb_columns() - information_schema.columns
- duckdb_settings()
- duckdb_extensions()
- current_schema()
- current_schemas()
Test mit größeren Datenmengen - Stackoverflow Dump
Um DuckDB mit größeren Datenmengen zu testen, habe ich den aktuellen Dump von Stackoverflow [StackOverflowDump] heruntergeladen und mit meinem [XmlConverterTool] nach CSV gewandelt, da ich keine XML-Erweiterung für DuckDB gefunden habe. Es sind zwar nur 65000 Tags und 20 Millionen Nutzer (2,2 GB CSV), aber 58 Millionen Posts (5,3 GB CSV), sodass sich das schon mal lohnt. In Listing 5 ist zu sehen, wie wir die Daten lesen, in Tabellen konvertieren und dann analysieren können.
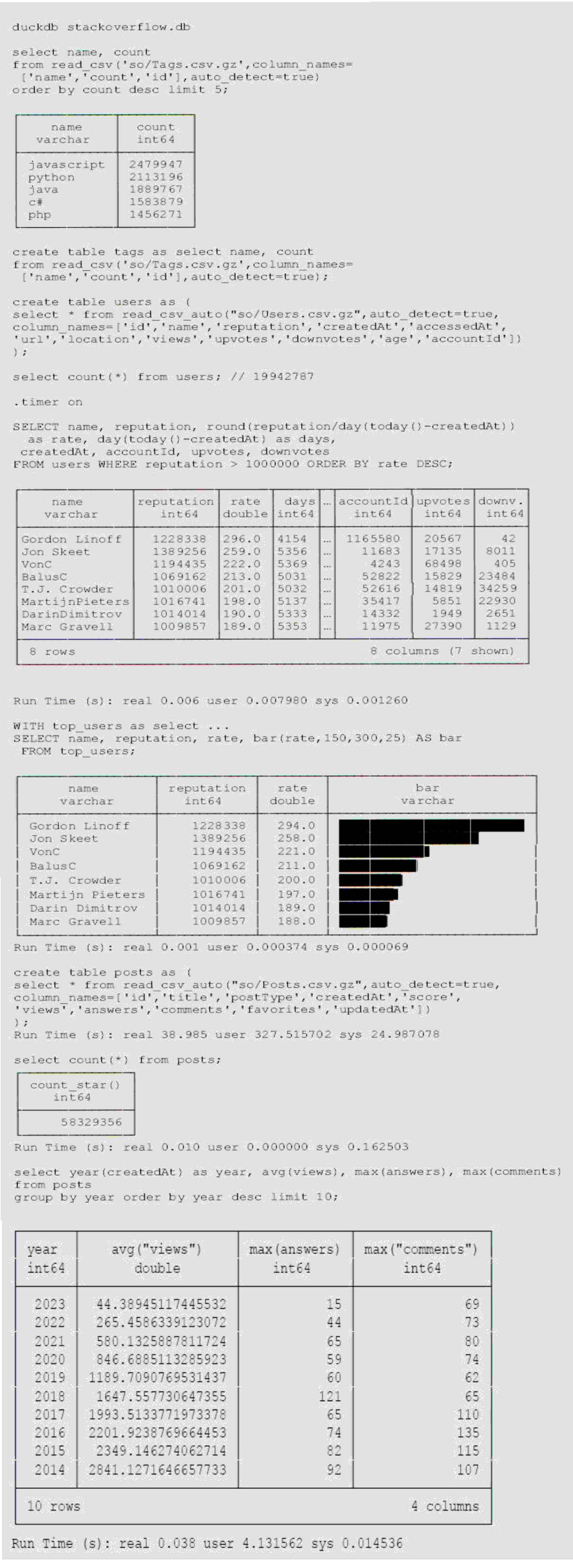
Listing 5: Stackoverflow-Analyse
Wie wir sehen, bringen auch mittelgroße Datenmengen DuckDB nicht aus dem Gleichgewicht, für Tests mit Milliarden von Datensätzen wird oft der [NewYorkTaxi]-Datensatz benutzt, der im Parquet-Format vorliegt. Da CSV schon etwas in die Jahre gekommen ist, können wir die Daten auch nach Parquet exportieren, ein modernes Format für die analytische Datenverarbeitung (s. Listing 6). Für die 20 Millionen Nutzer dauert es 5 Sekunden, bis die 10 Dateien mit 1 G geschrieben sind. Das Lesen der Dateien ist jetzt viel schneller als von CSV.
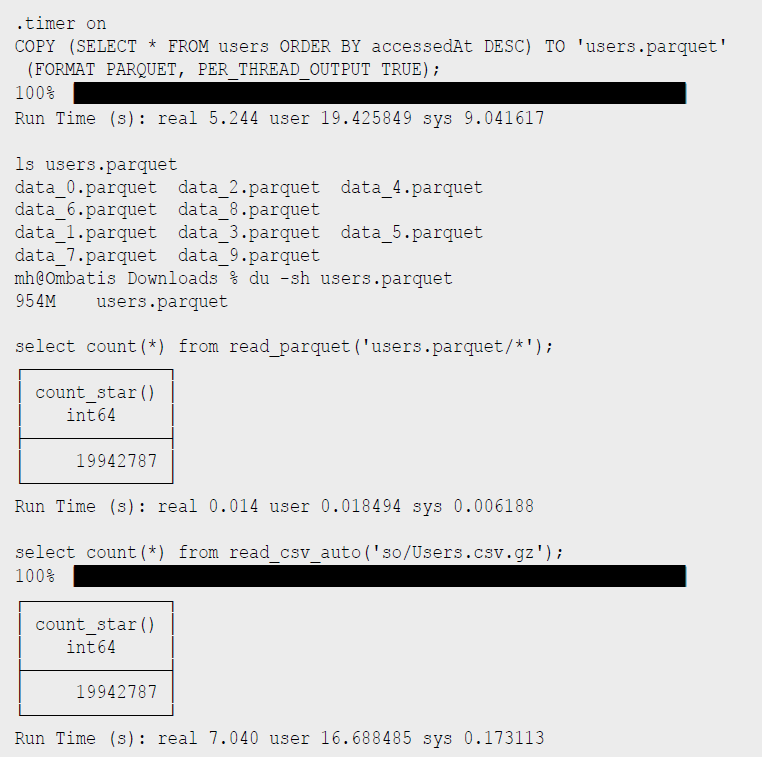
Listing 6: Parquet-Dateien schreiben
DuckDB und Python
Ein sehr praktischer Aspekt von DuckDB ist die Nutzung innerhalb von Python-Datenanalyse-Prozessen und -Notebooks. Daten, die in Pandas Dataframes vorliegen, können direkt und ohne Transformation oder Kopiervorgang von DuckDB genutzt werden. Ergebnisse von DuckDB werden ebenso als Dataframes bereitgestellt und können dann mit den gängigen Bibliotheken weiterverarbeitet werden (s. Listing 7).
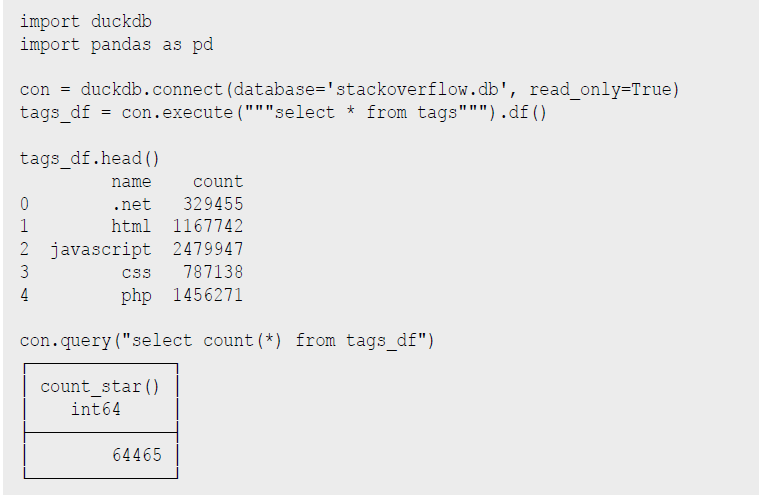
Listing 7: Nutzung mit Python
Für die Visualisierung von Ergebnissen können dank der transparenten Pandas-Integration existierende Bibliotheken wie matplotlib genutzt werden. Für interaktive Analyse-Anwendungen integriert es sich auch gut mit Streamlit, wie auf [LDWMStreamlit] zu sehen.
DuckDB stellt auch eine fluent „relational API” [PythonDSL] bereit, die statt SQL eingesetzt werden kann und die Wiederverwendung von „Relations” sowie Set-Operationen, Filter, Projektionen, Aggregationen usw. unterstützt, siehe Listing 8. Als Quelle für initiale „Relationen” können neben SQL-Statements auch Daten direkt aus Parquet, Arrow und CSV-Dateien gelesen werden. Mir persönlich ist die DSL nicht weit genug entwickelt, da immer noch SQL-Fragmente als Parameter übergeben werden müssen. Skalare Python-Funktionen können seit Version 0.8 mittels
duckdb.create_function('name', funktion, parameter-typen, return-typ)
in der Datenbank registriert und benutzt werden.
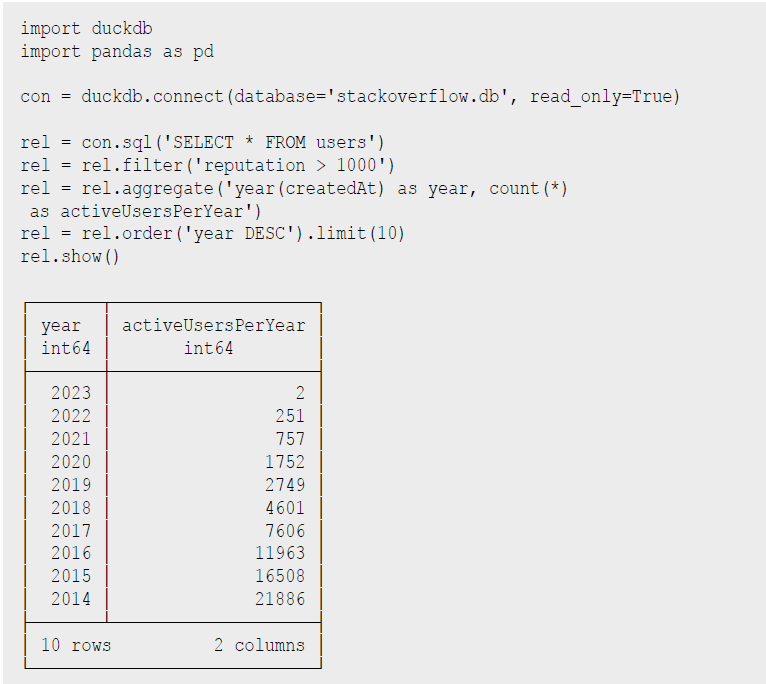
Listing 8: Relational API in Python
Nutzung mit Java
Ähnlich wie in Python ist die Nutzung von DuckDB in Java erfreulich unkompliziert. Der JDBC-Treiber ist auf Maven verfügbar und führt die Datenbank auch wieder innerhalb unseres Prozesses aus. In Listing 9 ist ein kleines JBang-Beispiel zu sehen, das die Verbindung zur Datenbank öffnet, die übergebene SQL-Abfrage ausführt und die Ergebnisse als Ascii-Tabelle darstellt.

Listing 9: Nutzung von Java mittels JDBC und JBang
Implementierungsdetails und Architektur
Wie einer an einem Datenbanklehrstuhl entwickelten Datenbank würdig, nutzt DuckDB alle relevanten Mechanismen moderner OLAP-Datenbanken. Wegen der zumeist eingebetteten Ausführung können keine komplexen Bibliotheken oder Infrastrukturen genutzt werden, da diese meist nicht portabel sind beziehungsweise Betriebssystem-Signale benötigen, oder im Ernstfall den Prozess beenden. Daher sind auch effizientes Ressourcenmanagement und Datenzugriff möglichst ohne Speicherkopien wichtig.
Für Endanwendungen wird neben der C/C API auch Integration für Python und R vom Kernsystem bereitgestellt, andere Bibliotheken nutzen die C/C API. Als Parser wird ein modifizierter Postgres-Parser genutzt, der sehr flexible auf die Bedürfnisse angepasst werden kann. Abfrageplanung erfolgt in einem zumeist kostenbasierten Optimizer, der Ansätze wie „join-order-optimization” und „dynamic programming” ausnutzt.
Für Indizes und Constraints (PK, FK) sowie Geo- und Range-Abfragen sowie Joins benutzt DuckDB Adaptive Radix Tree (ART) Indizes (Trees mit horizontaler und vertikaler Kompression). Die Ausführung des physischen Plans übernimmt eine vektorisierte, kolumnare, parallele Implementierung, die auf Teilmengen (Batches) von Daten arbeitet (Morsel-Ansatz) und damit eine gute Balance zwischen der Verarbeitung pro Zeile oder der kompletten Daten auf einmal erreicht. Alle Daten innerhalb von DuckDB liegen in getypten, optimierten Vektor-Implementierungen für verschiedene Inhalte (numerische Felder, Konstanten, Strings, Dictionary-Lookups, Listen, Structs usw.), die sowohl durch Kompression, Metadaten (min, max) und zusätzliche Indizes die Auswahl und Verarbeitung beschleunigen. Diese Vektoren implementieren alle relationalen Operationen in C++-Klassen mittels Templates für die verschiedenen Datentypen. Im Ablauf werden die Vektoren durch die Plan-Operatoren von einem zum anderen weitergereicht (push-based).
DuckDB ist auch transaktional, damit während der analytischen Abfragen auch Updates der darunterliegenden Daten erfolgen können. Es benutzt eine OLAP optimierte Variante MVCC (Multi Version Concurrency Control) mit serialisierten Transaktionen wie auch das HyPer-System der TU München. Dabei werden Aktualisierungen direkt ausgeführt und vorherige Werte in einem Undo-Puffer gehalten, falls die Transaktion zurückgerollt werden muss. Alles in allem laut Aussage der Entwickler eine Lehrbuch-Architektur, aber das Datenbank-Lehrbuch ist dann schon ziemlich modern.
Erweiterte Funktionen – PV-Analyse
Auch SQL-Experten werden nicht enttäuscht, neben voller Unterstützung von Windows-Funktionen (OVER ... PARTITION BY), PIVOT sind auch Common Table Expressions in DuckDB an der Tagesordnung. Mein Kollege Michael Simons, der auch schon öfter Autor dieser Kolumne war, hat DuckDB genutzt, um die Erzeugungs- und Verbrauchsdaten seiner nagelneuen Photovoltaik-Anlage zu analysieren [SimonsPV]. Dabei war die Extraktion der Daten aus der Anbietersoftware der größte Aufwand, zwei interessante Beispielabfragen sind in Listing 10 und 11 zu sehen.
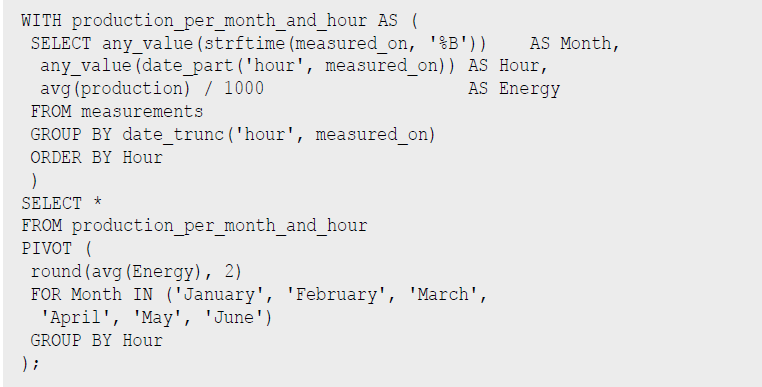
Listing 10: PV-Analyse
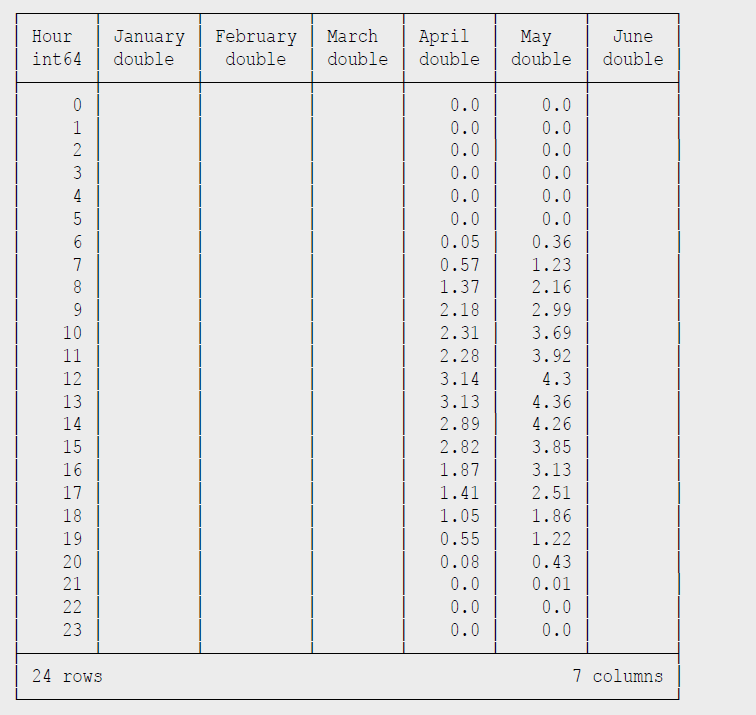
Listing 11: Ausgabe PV-Analyse
Anwendungsfälle
Für ein Tool wie DuckDB gibt es viele Anwendungsfälle, am spannendsten ist es natürlich, wenn es in existierende Cloud-, Mobile-, Desktop- und Kommandozeilenanwendungen integriert werden kann und hinter den Kulissen seinen Dienst versieht.
Gerade für die Analyse von Daten, die das eigene Gerät nicht verlassen sollen, wie Gesundheits-, Trainings-, Finanz- oder Heimautomatisierungs-Daten, bietet sich eine effiziente lokale Infrastruktur an. Aber auch für die schnelle Analyse größerer Datenmengen, wie Logdateien, bei der die Berechnung und Reduktion dort erfolgen kann, wo die Daten gespeichert sind, und damit hohe Datentransfer(kosten) gespart werden, ist DuckDB nützlich.
Für Data Scientists kann Datenaufbereitung, Analyse, Filterung und Aggregation effizienter als mit Pandas erfolgen, ohne die bequeme Umgebung eines Notebooks mit Python- oder R-APIs zu verlassen. Spannend wird auch die verteilte Analyse von Daten, je nach Menge, Speicherort, und Anwendungsfall, die zum Beispiel von [Motherduck] zwischen Cloud-Speicher, Edge-Netzwerk und lokalem Gerät balanciert wird.
Fazit
DuckDB ist ein erfrischend praktischer Ansatz für die effiziente Datenanalyse. Neben dem großen Funktionsumfang, nahtloser Integration, guter Dokumentation, hilfsbereiter Community und schnellem Einstieg ist auch die kontinuierliche Weiterentwicklung durch Datenbankforscher von Weltrang ein Garant für eine erfolgreiche Zukunft. Quack!
Weitere Informationen
[BigData]
https://motherduck.com/blog/big-data-is-dead/
[CSV]
https://github.com/bnokoro/Data-Science/
[Download]
https://github.com/duckdb/duckdb/releases
[DuckDBDiscord]
https://discord.duckdb.org/
[DuckDBDocs]
https://duckdb.org/docs/
[DuckDBJSON]
https://duckdb.org/docs/extensions/json.html
[InternalsVideo]
https://www.youtube.com/watch?v=bZOvAKGkzpQ
[LDWM] Learn Data With Mark,
https://youtube.com/@learndatawithmark
[LDWMStreamlit]
https://www.youtube.com/watch?v=65MoH1rlK7E&list=PLw2SS5iImhEThtiGNPiNenOr2tVvLj6H7&index=15
[McSherry]
http://www.frankmcsherry.org/graph/scalability/cost/2015/01/15/COST.html
[Motherduck]
https://motherduck.com
[New-York-Taxi]
https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page
[PythonDSL]
https://duckdb.org/docs/api/python/relational_api
[SimonsPV]
https://github.com/michael-simons/pv
[SQLitePodcast]
https://corecursive.com/066-sqlite-with-richard-hipp/
[StackOverflowDump]
https://archive.org/download/stackexchange
[Web-Shell]
[XmlConverterTool]
https://github.com/neo4j-examples/neo4j-stackoverflow-import








