

Mit Docker [Docker] hat es die Containertechnologie in den Mainstream geschafft. Wir können nun ein Artefakt für unsere Anwendung erzeugen, das neben der Anwendung selbst auch alle weiteren Abhängigkeiten, inklusive Betriebssystem, mitbringt. Dies erlaubt es, ähnlich wie dies früher mit Applikationsservern der Fall war, im Betrieb eine einheitliche Schnittstelle zu definieren: Container. Egal in welcher Sprache oder mit welchem Framework wir unsere Anwendung implementieren, solange sie als Container paketiert wird, kann sie vom Betrieb gestartet und überwacht werden.
Nach den ersten Schritten mit Containern werden schnell weitere Begehrlichkeiten geweckt. Diese Container sollen ausfallsicher auf mehreren Knoten parallel betrieben werden, das Starten und Überwachen soll weitestgehend automatisch erfolgen und auch das Deployment soll ohne Wartungsfenster funktionieren.
Natürlich lassen sich diese Anforderungen durch die Entwicklung einer eigenen Plattform auf Basis von Containern erfüllen, sinnvoller ist es jedoch, sich nach einer stabilen und etablierten Lösung umzuschauen. Im Rahmen einer solchen Evaluation fällt immer wieder der Begriff Kubernetes [Kubernetes] oder K8s und Begriffe wie Pod oder ReplicationController tauchen auf. In diesem Artikel wollen wir uns gemeinsam in die Welt von Kubernetes stürzen und die Grundlagen praktisch kennenlernen.
Minikube
Um Dinge in einem Kubernetes-Cluster ausprobieren zu können, brauchen wir natürlich ein nutzbares Cluster. Da es in diesem Artikel nicht um die Installation eines solchen geht und in der Cloud nutzbare Cluster, wie die von Amazon [EKS], Google [GKE] oder Microsoft [AKS], nur gegen Bezahlung nutzbar sind, nutzen wir hierzu Minikube [Minikube].
Minikube bietet uns die Möglichkeit, lokal – über Virtualisierung – ein Cluster, bestehend aus einem einzelnen Knoten, mit einem einfachen Kommando zu installieren. Dazu führen wir nach der Installation von Minikube den Befehle minikube start aus.
Der erste Schritt
Als Erstes wollen wir in unserem Cluster einen Pod anlegen, was genau das ist, lernen wir später kennen. Dazu speichern wir den Inhalt aus Listing 1 in einer Datei server.yaml und führen anschließend den Befehl kubectl create -f server.yaml aus.
apiVersion: v1
kind: Pod
metadata:
name: server
labels:
app: server
spec:
containers:
- name: server
image: innoq/k8s-training-webserverNun können wir mit dem Befehl kubectl get pods überprüfen, dass Kubernetes diesen Pod wirklich gestartet hat. Mit kubectl describe pods server können wir uns anschließend weitere Details zu diesem Pod anschauen. Listing 2 zeigt exemplarisch einen gekürzten Auszug der beiden Befehle.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
server 1/1 Running 0 3m30s
$ kubectl describe pods server
Name: server
...
Node: minikube/10.0.2.15
Start Time: Fri, 08 Feb 2019 08:06:50 +0100
Labels: app=server
Annotations: <none>
Status: Running
IP: 172.17.0.4
Containers:
server:
Container ID: docker://17e1d5a450e2f67d8f828388ab376e145de1e83a233d3d752b2de5f0938193ea
Image: innoq/k8s-training-webserver
Image ID: docker-pullable://innoq/k8s-training-webserver@sha256:720b13c94530f052cbb0834c6737596456effa5aa35e1aa77e0168d89214aeb9
Port: <none>
Host Port: <none>
State: Running
Started: Fri, 08 Feb 2019 08:06:52 +0100
Ready: True
Restart Count: 0
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
...Was genau hier passiert ist, zeigt Abbildung 1. In der Datei server.yaml haben wir ein Kubernetes-Objekt beschrieben. Anschließend haben wir das Command-Line-Tool kubectl angewiesen, dieses Objekt im Cluster anzulegen. Dazu übermittelt es das Objekt an den kube-apiserver. Dieser läuft auf einem oder mehreren Verwaltungsknoten innerhalb des Clusters und ist für die Kommunikation mit dem Cluster verantwortlich, indem er eine HTTP-Schnittstelle zur Verfügung stellt.
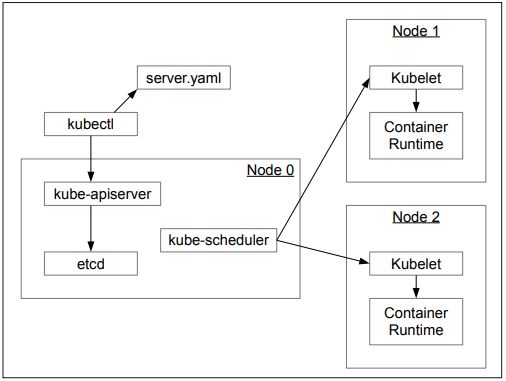
Abb. 1: Interaktion mit dem Kubernetes-Cluster
Das per kube-apiserver erhaltene Objekt wird anschließend in etcd [etcd] persistiert. etcd ist ein verteilter Key-Value-Speicher, also eine Datenbank, die primär Schlüssel-Wert-Paare speichert und über den Betrieb von mehreren Instanzen auf verschiedenen Knoten eine hohe Verfügbarkeit gewährleistet.
Nachdem das Objekt persistiert wurde, kommt der kube-scheduler ins Spiel. Dieser entscheidet, auf welchem der zur Verfügung stehenden Arbeitsknoten das Objekt angelegt werden soll. Das Scheduling erfolgt hierbei nicht zeitbasiert, das Objekt wird sofort zugewiesen, und zwar an denjenigen Knoten, auf dem noch genügend Ressourcen, wie Arbeitsspeicher oder CPU, zur Verfügung stehen.
Hat sich der kube-scheduler für einen Knoten entschieden, spricht er das auf dem Arbeitsknoten installierte kubelet an und teilt diesem mit, das Objekt zu erzeugen. Daraufhin nutzt dieses eine installierte Container-Runtime, wie Docker oder rkt [rkt], um einen Container zu starten, und stellt anschließend sicher, dass dieser Container auch dauerhaft läuft.
Im Gesamtergebnis haben wir nun also einen laufenden Pod. Doch was genau ist eigentlich ein Pod? Das wollen wir uns als Nächstes anschauen, doch vorher sollten wir klären, was genau Kubernetes-Objekte sind.
Kubernetes-Objekte
Wie bereits erwähnt, werden in einem Kubernetes-Cluster Objekte verwaltet. Diese nutzen einen deklarativen Ansatz, um einen bestimmten Sollzustand zu beschreiben. Die Summe aller verwalteten Objekte beschreibt somit den Gesamtsollzustand des Clusters. Jedes Kubernetes-Objekt besitzt einen Typ und gibt an, welcher Version dieses Typs es entspricht. Neben dem Typ besteht ein Objekt aus zwei Hauptbestandteilen: der Spezifikation und dem Status. Zusätzlich kann es noch Metadaten, wie den Namen oder Labels, geben.
Innerhalb des Clusters werden diese Objekte in JSON-Form vorgehalten. Auf Anwendungsseite ist es jedoch üblich, diese Objekte in YAML zu beschreiben. kubectl wandelt bei der Kommunikation mit dem kube-apiserver diese automatisch zu JSON um.
Der Status eines Objektes muss, wie in Listing 1 zu sehen, beim Anlegen eines Objektes nicht angegeben werden. Er entsteht zur Laufzeit automatisch und bildet den aktuellen Zustand des Objektes im Cluster ab.
Die Menge der Typen wird von Kubernetes nicht beschränkt. Es ist somit möglich, Kubernetes um eigene Typen zu erweitern. Kubernetes bringt jedoch bereits eine definierte Menge von Standardtypen mit, zu denen auch unser Pod gehört.
Pod
Pods stellen die kleinste von Kubernetes verwaltete Einheit dar. Ein Pod bildet eine Hülle um einen oder mehrere Container. Kubernetes garantiert dabei, dass alle Container eines Pods immer auf demselben Knoten laufen. Zudem werden diese Container nicht komplett voneinander isoliert, sondern teilen sich zum Beispiel eine IP und somit auch die zur Verfügung stehenden Netzwerkports. Aus diesem Grund können Container innerhalb eines Pods über localhost miteinander kommunizieren. Außerdem ist es möglich, dass sich mehrere Container ein sogenanntes Volume und somit einen Teil des Dateisystems teilen und auch über dieses miteinander kommunizieren können.
Bevor wir allerdings mehrere Container in einem Pod zusammenfassen, zum Beispiel eine Webanwendung mit ihrer Datenbank, sollten wir darüber noch einmal genau nachdenken. Würden wir dies tun, würde das dazu führen, dass Kubernetes immer beide Container demselben Knoten zuweist. Das hat in diesem Falle zwei Konsequenzen. Zum einen muss auf dem Knoten noch genügend Kapazität frei sein, um beide Container gemeinsam starten zu können. Zum anderen lassen sich nun beide Container nicht mehr unabhängig voneinander skalieren. Wollen wir drei Instanzen unserer Webanwendung haben, werden auch zwingend drei Instanzen der Datenbank entstehen.
Um zu entscheiden, ob mehrere Container zu einem Pod zusammengefasst werden oder ob aus diesen separate Pods werden sollen, sollten wir uns die folgenden drei Fragen stellen:
- Müssen die Container nah beieinander laufen, weil sie sich Dateisystem oder Prozessraum teilen?
- Repräsentieren die Container wirklich nur gemeinsam ein ganzes oder sind es eher unabhängige Komponenten, die miteinander verknüpft sind?
- Muss oder möchte ich die Container unabhängig voneinander skalieren können?
Im Zweifelsfall sollten wir eher dazu tendieren, pro Container einen eigenen Pod zu erstellen.
Bei jedem Pod sorgt das kubelet nach dem Starten dafür, dass alle Container kontinuierlich laufen, selbst wenn der Prozess in einem der Container beendet wird.
Um dies zu simulieren, können wir uns mit kubectl exec server -it -- /bin/sh in den laufen Container einklinken. Führen wir dort nginx -s stop aus und beenden somit den laufenden nginx-Prozess, werden wir aus dem Container geschmissen. Prüfen wir anschließend mit kubectl get pods den Zustand aller Pods im Cluster, sehen wir, dass sich unser server Pod im Status completed befindet und keine Instanz mehr bereit ist. Der Pod scheint sich also beendet zu haben. Doch bereits nach wenigen Sekunden zeigt uns ein erneutes kubectl get pods, dass Kubernetes einen neuen Container gestartet und somit wieder den gewollten Sollzustand hergestellt hat.
In der Praxis hilft uns bereits dieses Verhalten, für eine hohe Verfügbarkeit zu sorgen. Prozesse, die stoppen, werden automatisch neu gestartet. Es kann jedoch auch der Fall auftreten, dass der eigentliche Prozess noch läuft, der Container jedoch trotzdem keine Arbeit mehr verrichten kann. Um diesen Fall zu erkennen, bietet uns Kubernetes die Möglichkeit, eine Liveness Probe im Pod zu hinterlegen, die prüft, ob der Container noch wirklich funktioniert.
Aktuell haben wir dazu drei Arten von Probes zur Verfügung:
- Mit der ExecAction ist es möglich, ein Kommando zu definieren, das regelmäßig im Container ausgeführt wird. Beendet sich dieses Kommando mit dem Exit-Wert 0, wird es als Erfolg gewertet.
- Die TCPSocketAction prüft, ob eine TCP-Verbindung zu einem spezifizierten Port möglich ist.
- Als dritte Variante ist es möglich, mittels der HTTPGetAction einen HTTP GET-Request auszulösen. Dieser muss mit einem HT-TP-Statuscode zwischen 200 und 400 beantwortet werden, um erfolgreich gewertet zu werden.
Bauen wir doch eine solche Probe in unseren Pod ein. Listing 3 zeigt die neue Definition für unseren Pod. Um den Pod mit seiner geänderten Definition zu starten, müssen wir zuerst den aktuell laufenden mit kubectl delete pods server löschen und ihn anschließend mit kubectl create -f server.yaml wieder anlegen.
apiVersion: v1
kind: Pod
metadata:
name: server
labels:
app: server
spec:
containers:
- name: server
image: innoq/k8s-training-webserver
livenessProbe:
httpGet:
path: /health
port: 80
initialDelaySeconds: 15
periodSeconds: 1Wenn wir nun nach etwa einer Minute kubectl get pods ausführen, sehen wir, dass der Pod bereits einige Male neu gestartet wurde.
Schauen wir uns dazu noch mit kubectl describe pods server den aktuellen Zustand an, sehen wir die beiden Events:
- Liveness probe failed: HTTP probe failed with statuscode: 404 und
- Killing container with id docker://server:Container failed liveness probe.. Container will be killed and recreated.
Die Liveness Probe funktioniert also und startet unseren Container regelmäßig neu, da es den Pfad /health nicht gibt. Ändern wir den Pfad des Checks auf /, löschen den Pod und legen ihn neu an, so haben wir einen Pod mit einer validen Liveness Probe.
Wichtig bei der Implementierung einer solchen Probe ist, dass diese nur fehlschlägt, wenn wirklich etwas innerhalb unseres Containers nicht mehr funktioniert, und nicht, wenn es Probleme in einer Abhängigkeit gibt. Sollte dies der Fall sein, wird die Anwendung dauerhaft neu gestartet, ohne dass die Wurzel des Problems, zum Beispiel eine nicht erreichbare Datenbank, gelöst wird.
Sowohl für den Neustart von beendeten Prozessen als auch für die Liveness Probe ist das kubelet auf dem Knoten, auf dem der Pod gestartet wurde, verantwortlich. Wenn nun dieser gesamte Knoten abstürzt, ist auch unser Pod verschwunden. Damit Kubernetes diesen selbstständig auf einem anderen, noch funktionierenden Knoten neu startet, benötigen wir einen ReplicationController.
ReplicationController
Um dafür zu sorgen, dass unser Pod auch läuft, wenn ein Arbeitsknoten ausfällt, legen wir einen sogenannten ReplicationController an. Dessen Aufgabe ist es, dafür zu sorgen, dass immer eine bestimmte Anzahl von Pods innerhalb des Clusters läuft. Listing 4 zeigt die Beschreibung eines ReplicationController für unseren Pod, welcher dafür sorgt, dass immer drei Instanzen laufen.
apiVersion: v1
kind: ReplicationController
metadata:
name: server
spec:
replicas: 3
selector:
app: server
template:
metadata:
name: server
labels:
app: server
spec:
containers:
- name: server
image: innoq/k8s-training-webserver
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 15
periodSeconds: 1Ein ReplicationController besteht aus drei Hauptbestandteilen. Der Wert für replicas gibt an, wie viele Instanzen gleichzeitig laufen sollen.
Den selector nutzt der Controller, um zu prüfen, ob noch genug Instanzen laufen. In unserem Falle stellt der Controller sicher, dass jederzeit drei Instanzen laufen, die ein Label mit den Namen app und dem Wert server besitzen. Dies führt dazu, dass lediglich zwei weitere Instanzen gestartet werden, wenn wir den ReplicationController mit dem Befehl kubectl create -f rc.yaml anlegen. Die vorher bereits laufende Pod-Instanz erfüllt schließlich auch den Selektor und wird damit ab jetzt auch über den Controller verwaltet.
Der letzte Bestandteil, das template, wird vom Controller genutzt, um neue Instanzen zu starten. Das heißt im Umkehrschluss auch, dass Änderungen in diesem Teil des Controllers erst zum Tragen kommen, wenn neue Instanzen benötigt werden.
Fügen wir zum Beispiel ein zweites Label env mit dem Wert prod zum template hinzu, führen anschließend kubectl apply -f rc.yaml aus und schauen uns nun mit kubectl get pods --show-labels die aktuellen Pods an, sehen wir, dass das neue Label an keinen der vorhandenen Pods angehängt wurde. Führen wir nun kubectl scale --replicas=4 replicationcontroller server und anschließend erneut kubectl get pods --show-labels aus, erscheint das neue Label an der neuen, vierten, Instanz.
Neben dem ReplicationController gibt es innerhalb von Kubernetes noch weitere Controller für spezielle Anforderungen, und es ist auch möglich, eigene Controller zu implementieren. Diese funktionieren dadurch, dass Kubernetes einen Control-Loop ausführt, um den Zustand des Clusters zu überwachen. Im Rahmen dieser Schleife ist der kube-controller-manager, der auf den Verwaltungsknoten läuft, dafür verantwortlich herauszufinden, ob und wie der aktuelle Zustand vom gewollten abweicht. Findet er Abweichungen, sorgt er anschließend dafür, dass der gewollte Zustand wiederhergestellt wird.
Aktueller Stand und Ausblick
An dieser Stelle laufen vier Instanzen unseres Pods. Durch Kubernetes’ Bordmittel und den ReplicationController ist zudem sichergestellt, dass im Fehlerfall neue Instanzen gestartet werden.
Obwohl innerhalb des Pods ein Webserver läuft, können wir diesen bisher allerdings nicht per Netzwerk erreichen. Wie sich dieses Problem lösen lässt, wollen wir uns in einer weiteren Kolumne anschauen.
Fazit
Wir haben gesehen, dass ein Kubernetes-Cluster aus zwei Arten von Knoten besteht. Auf den Verwaltungsknoten laufen sowohl Komponenten zur Kommunikation mit und im Cluster als auch Komponenten, die sicherstellen, dass der Cluster-Zustand dem gewollten entspricht. Die eigentliche Arbeit, das Ausführen von Containern, findet dann auf Arbeitsknoten statt.
Außerdem haben wir mit Pod und ReplicationController zwei Kubernetes-Objekte kennengelernt. Ein Pod ist die kleinste von Kubernetes verwaltete Einheit und ein ReplicationController stellt sicher, dass immer eine spezifizierte Anzahl von einem Pod läuft. Im nächsten Teil zu Kubernetes werden wir uns, neben weiteren Arten von Controllern, anschauen, wie wir den hier deployten Pod über das Netzwerk erreichen können.
Literatur und Links
[AKS]
Azure Kubernetes Service, https://azure.microsoft.com/de-de/services/kubernetes-service/
[Docker]
https://www.docker.com
[EKS]
Amazon Elastic Container Service for Kubernetes,
https://aws.amazon.com/de/eks/
[etcd]
https://github.com/etcd-io/etcd
[GKE]
https://cloud.google.com/kubernetes-engine/
[Kubernetes]
https://kubernetes.io








