

Nicht nur, dass in der EU durch den AI Act die Klassifizierung in Risiken bei Anwendung von KI verpflichtend wird und damit einhergehend auch bestimmte Dokumentations- und Nachverfolgungspflichten (wenn nicht sogar das Verbot des Einsatzes) auferlegt wurden, sondern auch um einer negativen Außenwirkung durch den Einsatz von (generativer) KI (zum Beispiel Halluzination und Rassismus) vorzubeugen, haben Unternehmen ein intrinsisches Motiv zum Einsatz von Governance.
Wichtig ist, dass Governance gleich welcher Art möglicherweise von manchen nur als Mehraufwand gesehen wird und deshalb auf Widerstand stößt. Daher ist Governance im Unternehmen nicht nur eine technische Aufgabe, sondern eine strategische Entscheidung und es muss eine entsprechende Kultur im Unternehmen etabliert werden.
Denn nur wenn alle Beteiligten den Mehrwert verstehen und umsetzen, entsteht ein echter Nutzen für das ganze Unternehmen.
Traditionelle Anforderungen an Data Governance
Data Governance soll sicherstellen, dass Daten, die zur Analyse und Unterstützung von Geschäftsprozessen bereitgestellt werden, bestimmte Anforderungen erfüllen wie etwa Auffindbarkeit, Verständlichkeit, Konsistenz und Einhaltung von Regularien [Bha13; Ery21; Maf23], was ebenso für den Zugriff auf diese Daten gilt. Dabei umfasst der Begriff der Data Governance ebenfalls alle Prozesse und Rollen im Unternehmen, die notwendig sind, um diese Eigenschaften sicherzustellen.
Das „Data“ macht es deutlich: In der Anfangszeit der Data Governance waren hauptsächlich analytische Systeme Gegenstand der Betrachtung von Governance. In Abbildung 1 wird veranschaulicht, wie Data Governance alle Ebenen der Datenbereitstellung in einer typischen Architektur für analytische Anwendungen umfasst.
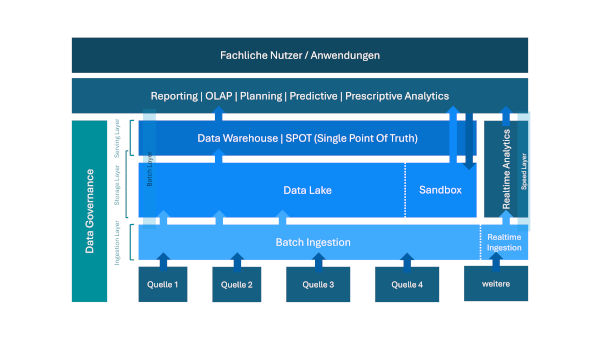
Abb. 1: Data Governance in einer traditionellen Analytics-Architektur
Data Governance endete oft mit der Datenbereitstellung, einige Ansätze inkludierten auch noch die Analyse in Business-Intelligence-Tools. Die erweiterte Analyse (traditionell: „Data Mining“, etwas moderner „Data Science“, aktuell „AI“) spielte für die Data Governance jedoch nur eine untergeordnete Rolle.
Dabei wurde dem Thema Data Governance nicht immer die Aufmerksamkeit geschenkt, die notwendig gewesen wäre. Wer sich schon länger mit analytischen Anwendungen beschäftigt, kennt die Projekte, bei denen sich erst nach Jahren herausstellte, dass Entscheidungen auf völlig falschen Daten getroffen worden waren. Erst mit der Einführung von Regularien wie Basel II (und später Basel III) [Bas04] für Banken beziehungsweise Solvency II [Sol09] für Versicherungen oder dem Sarbanes-Oxley Act [SOA02] für Unternehmen allgemein gab es in diesen Branchen eine erhöhte Nachfrage nach Data Governance, um die Herkunft und Verarbeitung von Daten besser zu dokumentieren. Einige Unternehmen haben dafür die Basis gelegt [Bas21]. Aus eigener Erfahrung lässt sich jedoch sagen, dass längst nicht alle Unternehmen in dieser Hinsicht perfekt aufgestellt sind.
Was macht die traditionellen Anforderungen aus und warum sind sie immer noch gültig?
Analytische Landschaften umfassen vor allem die Datenquellen, die Datenintegration beziehungsweise Datentransformation und die Zielsysteme (Data Warehouse, Data Lake etc.)
Traditionelle Anforderungen an Data Governance setzen an diesen Punkten an:
- Statische Dokumentation: Diese wird während der Entwicklung generiert oder geschrieben. Sie umfasst zum Beispiel die Dokumentation von angebundenen Datenquellen, deren technischen Eigenschaften und der fachlichen Inhalte, außerdem die Zielsysteme, das Datenmodell, die unterstützten Geschäftsprozesse, die Zugriffsregeln und Verantwortlichkeiten (durch Data Stewards) und den kompletten Datenintegrations- und -transformationsprozess über alle Stages hinweg. Einerseits kann diese Dokumentation während der Weiter-/Neuentwicklung sehr hilfreich sein (zum Beispiel durch eine Impact-Analyse oder Lineage), andererseits muss sie während der Weiter-/Neuentwicklung auch kontinuierlich aktualisiert werden.
- Dynamische Dokumentation: Diese entsteht zur Laufzeit beziehungsweise während des Betriebs. Sie umfasst zum Beispiel die Datenqualität inklusive der Ausweisung automatischer Korrekturen oder abgewiesener Datensätze oder die Überwachung der Laufzeiten und der Datenmengen.
- Dokumentation der Prozesse und Rollen im Unternehmen: Sie sorgt dafür, dass Verantwortlichkeiten dokumentiert beziehungsweise Anforderungen, Weiterentwicklungen oder Freigaben kanalisiert werden.
Schlussendlich dienen alle Aktivitäten der Data Governance dem Ziel, eine Datenbasis für Geschäftsprozesse herzustellen, die das Unternehmen dabei unterstützen kann, Entscheidungen zu treffen. Ob und welche Maßnahmen getroffen werden und welches Risiko man einzugehen bereit ist, durch zum Beispiel veraltete Daten fragwürdige Entscheidungen zu treffen, entscheidet jedes Unternehmen selbst. Wichtig in diesem Zusammenhang ist die Betrachtung aller Aspekte und die bewusste Entscheidung für oder gegen entsprechende Aktivitäten.
Damit ist die Argumentation bezüglich des Nutzens der Data Governance auch im Umfeld KI-Governance klar: Jede (noch so künstliche) Intelligenz lebt von der Qualität der ihr zur Verfügung gestellten Daten – und wenn diese nicht gewährleistet ist, ist das Ergebnis per se fragwürdig.
Neue Herausforderungen durch (generative) KI
KI, besonders die für den Menschen teilweise gänzlich intransparente Nutzung, stellt völlig neue Herausforderungen an Governance – und das zusätzlich zu den Maßnahmen der Data Governance. Das hat auch der Gesetzgeber erkannt und mit dem EU-AI Act ein Werkzeug geschaffen, mit dem jedes Unternehmen gezwungen wird, alle KI-relevanten Aktivitäten nach Risiken zu klassifizieren und es entsprechend der Klassifikation entweder komplett zu unterlassen, umfassende Dokumentationen der KI vorzunehmen, oder mindestens die Nutzung für den Anwender erkennbar zu machen.
Ob extrinsisch durch Regulatorik oder intrinsisch durch ethische oder unternehmensinterne Gründe: Grundsätzlich sollen negative gesellschaftliche Auswirkungen durch die Nutzung von KI-Verfahren vermieden werden, wie beispielsweise Benachteiligungen, die aufgrund von Entscheidungen durch die Anwendung eines KI-Modells getroffen werden. Laut [Lu23], die unter dem Titel „Responsible AI“ für verantwortungsbewusste KI argumentieren, soll unter anderem die Fairness der Verfahren, Datenschutz, Zuverlässigkeit und Sicherheit gewährleistet werden. Durch KI beeinflusste Entscheidungen sollen transparent und nachvollziehbar sein, sodass ein negativ Betroffener gegebenenfalls Einspruch erheben kann. KI soll also erklärbar sein. Bias, das heißt Voreingenommenheit oder Befangenheit, soll bei Entscheidungen vermieden werden. Es wird allgemein erwartet und so auch durch den EU AI Act vorgegeben, dass Menschen die KI kontrollieren und verantworten und die von der KI getroffenen Entscheidungen vertrauenswürdig sind. Deshalb wurden Anforderungen aufgestellt wie:
- Es soll nachvollziehbar sein, mit welchen Daten ein KI-Modell trainiert wurde und wann das Training erfolgte. Diese Nachvollziehbarkeit stellt eine Verbindung zu traditioneller Data Lineage und Data Observability her [ChW23].
- Ein neuer Aspekt beim Supervised Learning ist die Nachvollziehbarkeit des Labeling, das heißt des Kennzeichnens der Daten nach verschiedenen Kriterien.
- Da die für das Training vorgesehenen Daten nicht direkt verwendet werden, muss auch die Aufbereitung der Trainingsdaten (verwendete Data Pipelines, Feature Engineering) nachvollziehbar sein.
- Es kommt aber nicht nur auf die Nachvollziehbarkeit an, sondern es muss bei schützenswerten Trainingsdaten auch sichergestellt werden, dass Data Engineers und Data Scientists auf Daten nur in einer Form Zugriff bekommen, die keine gesetzlichen oder Firmenregularien verletzt, gleichzeitig aber auch noch relevante Informationen aus den Trainingsdaten ableitbar sind. Ein Governance-System muss also in der Lage sein, Regelwerke für den Zugriff auf die Trainingsdaten zu definieren und deren Einhaltung zu gewährleisten.
- Ein weiterer Aspekt ist die Nachvollziehbarkeit und Erklärbarkeit des erzeugten und dann verwendeten KI-Modells selbst. Je nach KI-Verfahren ist das einfacher oder schwieriger möglich.
- Ein weiterer Governance-Gesichtspunkt ergibt sich bei der Anwendung des KI-Modells. Die Ergebnisse müssen überprüft werden können, ob etwa Personengruppen benachteiligt werden. Falls ja, werden alle bereits erwähnten Governance-Aspekte genutzt, um die Ursache wie etwa Bias in den Trainingsdaten zu finden.
- Auch die Historie der Anwendungen aller Schritte einschließlich Kontext soll festgehalten werden, um eine nachträgliche Analyse zu ermöglichen.
In Abbildung 2 ist der typische KI-Lebenszyklus mit den verschiedenen Ansatzpunkten für Governance dargestellt.
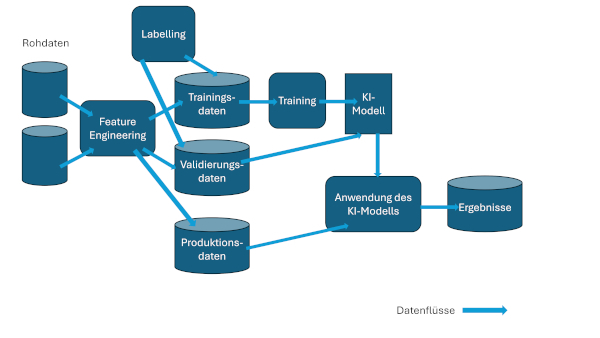
Abb. 2: Governance im KI-Lebenszyklus
Alle Datenflüsse und Verarbeitungsschritte unterliegen der Nachvollziehbarkeit:
- Überwachen
- Automatisieren
- Aufzeichnen
- Zusammenarbeiten
Die angesprochenen Anforderungen an die Governance ergeben sich aus Gesetzen und anderer Regulatorik (zum Beispiel dem EU AI Act [EU24]), internen Vorgaben eines Unternehmens (um vertrauliche Informationen zu schützen oder den Verlust von geistigem Eigentum zu vermeiden), aber auch um die Benutzbarkeit der Systeme für Nutzer zu erhöhen (zum Beispiel die Auffindbarkeit von Modellen zu erleichtern).
Weitere Anforderungen wie Offenheit für eine Vielzahl von Datenarten und Verfahren sowie deren einfache Integration in den Governance-Ansatz gibt es bei KI genauso wie bei traditioneller Datenanalyse.
Besonderheiten der Governance bei generativer KI
In letzter Zeit hat generative KI stark an Bedeutung gewonnen. Im Mittelpunkt stehen bei diesem Ansatz Foundation Models und Large Language Models (LLMs). Dazu wird ein allgemeines Modell mit einer sehr großen Datenmenge zentral trainiert. Zu einem gegebenen sogenannten Prompt findet das Modell dann die passendste Fortsetzung.
Während sich die Governance bei traditioneller KI mit selbsttrainierten Modellen schon deutlich verkompliziert (wenn etwa die Nachvollziehbarkeit von Ergebnissen aus der Anwendung eines Modells je nach verwendeten Verfahren immer schwieriger wird, beispielsweise bei neuronalen Netzen im Vergleich zu Entscheidungsbäumen), kommen bei generativer KI weitere Aspekte hinzu [EnD24]. Auch wenn LLMs, die sich für viele Anwender als Black Box präsentieren, über ihr Verhalten erklärbar sein sollen, gibt es bei generativer KI zusätzliche Gesichtspunkte:
- Mit welchen Daten wurde das LLM trainiert?
- Hat ein Dritter Rechte an den Daten, die zum Trainieren verwendet wurden, und verletzt man diese Rechte, wenn man das LLM nutzt?
- Enthält der erzeugte Text toxische Inhalte wie etwa HAP (Hate, Abuse, Profanity)?
- LLMs neigen zum sogenannten Halluzinieren bei manchen Fragestellungen, das heißt, es werden Antworten gegeben, die sich eigentlich nicht aus den Trainingsdaten ableiten sollten. Governance soll das Erkennen von Halluzinieren unterstützen.
- Damit stellt sich die nächste Frage: Was sind geeignete Metriken zur LLM-Beurteilung?
- Um die Nachvollziehbarkeit zu gewährleisten, sollte ein Zugriff auf die Historie der Prompts und die hier zugehörigen Ergebnisse durch die Governance-Lösung möglich sein.
Ein typischer Einsatz von generativer KI ist der sogenannte RAG-Anwendungsfall (Retrieval Augmented Generation). Dazu werden unternehmensspezifische Daten per sogenannten Embeddings auf Vektoren abgebildet, die in einer Vektordatenbank gespeichert werden. Der Prompt, den man an das LLM übergibt, wird dann mit Daten ergänzt, die durch Ähnlichkeitssuche in dieser Vektordatenbank gefunden wurden. Die Embeddings dienen dazu, ähnliche Konzepte auf ähnliche Vektoren abzubilden.
Diese Embeddings, die typischerweise auch wieder durch die Anwendung von KI gewonnen werden, stellen eigene Governance-Herausforderungen: Auch hier ist Nachvollziehbarkeit erforderlich, da die Embeddings bereits Voreingenommenheiten enthalten beziehungsweise abbilden können. Abbildung 3 zeigt einen typischen Ablauf bei der Nutzung von generativer KI und zeigt auf, wo dabei Governance-Aspekte eine Rolle spielen.
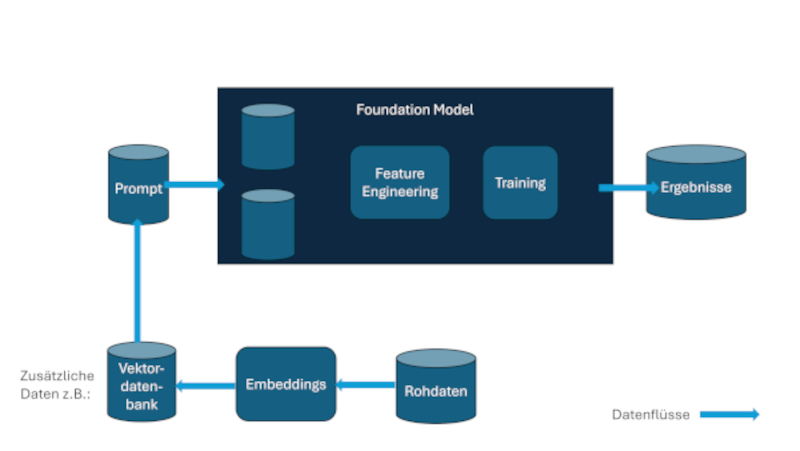
Abb. 3: Governance für generative KI
Im Folgenden werden verschiedene Realisierungsmöglichkeiten einander gegenübergestellt.
Pragmatische Ansätze zur Realisierung mit vorhandenen Office-Anwendungen
Über die Jahre hat sich gezeigt, dass regulatorische Anforderungen an Dokumentationspflichten von Unternehmen oft sehr pragmatisch angegangen werden, um den Mindestanforderungen gerecht zu werden.
So ist der einfachste Ansatz, bestimmte Dokumentationen mit Office-Anwendungen abzudecken, zum Beispiel Textverarbeitung, Tabellenkalkulation oder Werkzeuge zur Kollaboration:
- Risikomanagement: Dokumentation und Selbsteinschätzung, Nachverfolgung
- Anwendungsfälle
- Beschreibung von Datenprodukten
- Dokumentation von Prozessen und Rollen im Unternehmen
- etc.
In anderen Lösungen integrierte Governance-Funktionen
Insbesondere für Data-Analytics-Anwendungen, die sehr umfangreich und möglicherweise schon lange im Unternehmen eingesetzt werden, wurden oft umfassende Softwarepakete eingekauft, die bestimmte Governance-Funktionen inzwischen entweder als integralen Bestandteil enthalten oder für die sie als Option zu erwerben sind. Dabei sind zwei wesentliche Unterschiede zwischen Data Governance und KI-Governance zu beobachten:
- Data Governance: Beispielsweise enthalten viele Datenintegrationswerkzeuge inzwischen (optionale) Funktionalitäten hinsichtlich Datenkatalogen, Prüfung von Datenqualität, Nachvollziehbarkeit und Lineage bis hin zur Dokumentation der Nutzung von Reports und Analysen. Eine umfassende Liste von Datenintegrationswerkzeugen inklusive deren Governance-Funktionalität findet sich beispielsweise im „Gartner Magic Quadrant for Data Integration Tools” [Gar23].
- KI-Governance: Im Umfeld der Entwicklung von Data Science/ML oder KI ist dies nicht unbedingt der Fall, da neben der Nutzung spezieller Werkzeuge („Visuelle Data Science“, inklusive Feature Engineering, Modellentwicklung und teilweise eben auch Governance) vor allem programmatische Ansätze mit Python, Spark, R etc. verfolgt werden, in denen für Governance zusätzlicher, manueller Aufwand erforderlich ist. Eine Liste von möglichen Lösungen für KI-Governance findet sich beispielsweise auf der Website von AIMultiple Research [AIM24].
Lösungen für KI- und Data Governance: umfassende Plattformen
Zusammen mit den zunehmenden Anforderungen an KI- und Data Governance sind spezialisierte Anbieter von zum Beispiel Datenkatalogen, Lineage und Nachvollziehbarkeit auf den Markt gekommen, die teilweise sehr umfassende Lösungen anbieten und sich in vorhandene analytische Infrastrukturen integrieren. Während sich einige Lösungen sehr konkret an bestimmten Fragestellungen orientieren, wie zum Beispiel Lineage oder Nachvollziehbarkeit, haben sich andere im Laufe der letzten Jahre zu Plattformen entwickelt, die alle Aspekte der KI- und Data Governance abdecken wollen.
Bisher orientieren sich die meisten Lösungen an der Data Governance – KI-Governance als integraler Bestandteil einer Lösung findet sich selten. Beispiele für in Data-Governance-Lösungen enthaltene Funktionen sind:
- Datenkataloge: Sie sollen die Metadaten der Daten dokumentieren, oftmals unterschieden in technische und fachliche Metadaten:
Technische Metadaten beschreiben technische Eigenschaften, beispielsweise Tabellen, Spalten, Indizes aus (relationalen) Datenbanken, aber auch Datentransformationen, Verknüpfungen etc. aus Datenintegrationslösungen und Cubes/Würfel, Auswertungsbereiche oder Zieltabellen in Business-Intelligence-Tools. Diese Metadaten lassen sich oft einfach durch enthaltene Parser oder Agenten auf den darunterliegenden Systemen ermitteln.
Fachliche Metadaten können als Data Product dokumentiert sein oder als fachlich beschriebene Eigenschaften bestimmter technischer Metadaten (zum Beispiel zur Spalte SALES in der Tabelle TBL_SALES die Information, wie der Umsatz zu nutzen ist, wie er errechnet wurde, wer fachlich dafür verantwortlich zeichnet). In manchen Lösungen wird der Begriff „Glossar“ für fachliche Metadaten verwendet. Einige moderne Lösungen sind in der Lage, aus den Eigenschaften per KI (oder simplere Methoden) fachliche Metadaten abzuleiten („Profiling“). Das bedeutet: Es ist nicht nur wichtig, eine Governance auch für KI-Anwendungen zu haben, sondern umgekehrt kann KI auch genutzt werden, um die Governance zu verbessern. - Abhängigkeiten, Lineage, Verknüpfungen: Auch hier sind technische Eigenschaften einfacher durch Parser/Agenten zu ermitteln, während fachliche Eigenschaften oft manuell eingegeben werden müssen beziehungsweise durch intelligente Methoden vorgeschlagen werden können.
Technisches Lineage hilft beim Verstehen von Datenintegrationsprozessen, während fachliches Lineage besonders die Herkunft und die Zusammenhänge von fachlichen Prozessen beleuchtet. Ebenso lassen sich in den meisten Lösungen weitere Beziehungen zwischen den verschiedenen Elementen definieren und analysieren. - Datenschutzregeln: Sie reichen einerseits von der reinen Beschreibung bis hin zu vollautomatisierten Funktionen, die basierend auf Eigenschaften den Zugriff auf Daten pro Nutzer steuern, wie ABAC (Attribute-Based Access Control) und RBAC (Role-Based Access Control).
- Datenqualität: Neben der reinen Dokumentation in Katalogen bieten einige Lösungen den automatisierten Vergleich mit Soll-Werten oder mit durch automatisches Profiling erzeugten Annahmen (zum Beispiel 95 Prozent Wahrscheinlichkeit, dass es sich bei den Daten um eine Adresse handelt, der Rest wird als Fehler klassifiziert, oder alle bisherigen Werte pendelten um 365, also wird ein Wert von 1000 als potenzieller Fehler markiert).
- Verantwortlichkeiten/Prozesse: Definition von Data Stewards mit ihren Verantwortlichkeiten inklusive der Freigabe von angefragten Daten-Assets/Datenprodukten.
Eine umfassende Liste von Data-Governance-Plattformen findet sich beispielsweise im Überblick von Tech Target „16 top data governance tools to know about in 2024“ [Tec24].
Hinsichtlich kompletter Data & KI-Governance-Plattformen finden sich derzeit nur wenige Anbieter, die die obigen Funktionalitäten um KI-relevante (beziehungsweise allgemeiner: alles, was nach „Data“ oder „BI“ kommt) Funktionen ergänzen, also zum Beispiel den kompletten Data & MLOps-Prozess unterstützen, wie oben in den Herausforderungen beschrieben.
Bewertung der Lösungsmöglichkeiten
Wenn man sich die verschiedenen Realisierungsmöglichkeiten anschaut, stellt sich natürlich die Frage, wann man welche einsetzen soll. Das hängt stark davon ab, wie die analytische Umgebung ausieht, in der man sich bewegt. Wie viele Benutzer und wie viele unterschiedliche Benutzergruppen arbeiten mit dem System? Wenn nur eine Person für alle Aspekte eines analytischen Systems zuständig ist, dann mag der oben beschriebene pragmatische Ansatz funktionieren. Wenn dagegen viele Arten von Benutzern von Data Engineers über Data Scientists bis zu BI-Endbenutzern aus verschiedenen Organisationseinheiten zusammenarbeiten, dann braucht man eine umfassende Plattform.
Wie komplex ist die Datenlandschaft? Gibt es vielleicht nur einen kleinen Data Mart, eventuell sogar mit nur einem Quellsystem, oder liegt eine komplexe Landschaft mit mehreren Data Warehouses, Data Lakes oder Data Lakehouses vor? Wie viele verschiedene Werkzeuge werden für die Aufbereitung und Analyse der Daten benötigt? Braucht man Data Governance, weil man sich in einer stark regulierten Branche bewegt, oder nutzt man Data Governance hauptsächlich aus intrinsischen Motiven? Hat man einen geringen Komplexitätsgrad, etwa weil man im Wesentlichen nur ein Werkzeug einsetzt, kann die in dieses Werkzeug eingebaute Data Governance durchaus ausreichend sein. Hat man eine mittlere Komplexität, kann eine Punktlösung gegebenenfalls ausreichende Data-Governance-Möglichkeiten bieten. Bei komplexen Situationen ist aber üblicherweise eine umfassende Plattform zu bevorzugen.
Ebenso zeigt sich aber, dass, selbst wenn man mit einem kleinen System mit geringer Komplexität und einer überschaubaren Anzahl an Benutzern startet, analytische Systeme in jeder Hinsicht (Datenquellen, Werkzeuge, Benutzer, Art der Analysen) schnell wachsen können. Wenn man dann eine nicht skalierbare Lösung wie etwa die oben so bezeichnete „pragmatische Lösung“ einsetzt, kann die Data Governance schnell der Flaschenhals beim Wachsen des analytischen Systems werden.
Weitere Informationen
[AIM24] AIMultiple Research. https://research.aimultiple.com/ai-governance-tools/, abgerufen am 2.9.2024
[Bas04] Baseler Rahmenwerk. https://www.bundesbank.de/de/aufgaben/bankenaufsicht/rechtsgrundlagen/baseler-rahmenwerk/baseler-rahmenwerk-598536, abgerufen am 2.9.2024
[Bas21] Bastien, M.: Standardisiertes Datenmanagement schafft Basis für Reporting. https://www.timetoact.de/details/standardisiertes-datenmanagement-schafft-basis-fuer-reportings, abgerufen am 2.9.2024
[Bha13] Bhansali, N.: Data Governance. Auerbach Publications 2013
[ChW23] Christian, A. / Weininger, A.: Datenflüsse besser verstehen. BI-Spektrum 5-2023
[Ery21] Eryurek, E. et al.: Data Governance: The Definitive Guide. O’Reilly 2021
[EnD24] Engler, M. / Dhamani, N.: Introduction to Generative AI. Manning Publications 2024
[EU24] EU AI Act. https://artificialintelligenceact.eu/de/, abgerufen am 2.9.2024
[Gar23] Gartner: Magic Quadrant for Data Integration Tools. 4.12.2023, https://www.gartner.com/doc/reprints?id=1-2FTTBUD8&ct=231205&st=sb, abgerufen am 2.9.2024
[Lu23] Lu, Q. et al.: Responsible AI: Best Practices for Creating Trustworthy AI Systems. Addison-Wesley Professional 2023
[Maf23] Maffeo, L.: Designing Data Governance from the Ground Up. Pragmatic Bookshelf 2023
[SOA02] Sarbanes-Oxley Act.
https://de.wikipedia.org/wiki/Sarbanes-Oxley_Act, abgerufen am 2.9.2024
[Sol09] Richtlinie 2009/138/EG des Europäischen Parlaments und des Rates vom 25. November 2009 betreffend die Aufnahme und Ausübung der Versicherungs- und der Rückversicherungstätigkeit (Solvabilität II).
https://eur-lex.europa.eu/legal-content/DE/ALL/?uri=CELEX%3A32009L0138, abgerufen am 2.9.2024
[Tec24] TechTarget. https://www.techtarget.com/searchdatamanagement/feature/15-top-data-governance-tools-to-know-about, abgerufen am 2.9.2024









