

Die rasante Entwicklung und der zunehmende Einsatz von Large Language Models (LLMs) haben das Potenzial, zahlreiche Anwendungsgebiete grundlegend zu verändern. Diese hochentwickelten Modelle können durch ihre Fähigkeit zur Automatisierung vormals manueller Tätigkeiten zu signifikanten Effizienzgewinnen führen.
So wurden in Bereichen wie dem Kundenservice, der Content-Erstellung und der Datenanalyse bereits beeindruckende Effekte realisiert. Die Modelle sind in der Lage, menschliche Sprache zu verstehen und zu generieren, was sie zu wertvollen Werkzeugen und Assistenten für verschiedenste Aufgaben macht.
Jedoch bedingen die den LLMs zugrunde liegenden Algorithmen immer eine gewisse Fehlerquote. In Szenarien, in denen die Korrektheit der Ergebnisse unabdingbar ist – wie in der medizinischen Diagnostik, der juristischen Beratung oder in der Finanzdienstleistungsbranche – können Fehler schwerwiegende Konsequenzen haben. Hier stoßen LLMs an ihre Grenzen, da die alleinige Anwendung nicht ausreicht, um die notwendigen Qualitätsansprüche zu erfüllen [AyG24; She23].
Um die Effizienzgewinne durch LLMs zu nutzen, ohne die Qualität der Ergebnisse einzubüßen, ist es in vielen Szenarien sinnvoll, eine menschliche Validierung hinzuzuziehen [Yan23; Teh24]. Deshalb integriert der hier vorgestellte Ansatz einen Validierungsprozess der LLM-Ergebnisse unter Nutzung menschlicher Expertise. Durch die nahtlose Einbindung der Validierung wird eine größtmögliche Automatisierung erreicht, ohne die notwendige Genauigkeit und Vertrauenswürdigkeit der Ergebnisse zu gefährden.
Auch die grundlegende Tätigkeit des Data Engineer, oder häufig auch des Data Scientist, der für die spätere Verwendung in Advanced-Analytics-Use-Cases Daten migriert, bietet Herausforderungen hinsichtlich des Qualitätsanspruchs und des Potenzials für den Einsatz von LLMs. Wir schauen dazu auf das Szenario der Datenmigration, bei dem ein umfassender Bestandteil das Mapping der Datenbank-Schemata und die Erstellung der entsprechenden Migrationsskripte ist. Für beide Aktivitäten kann ein LLM Vorschläge generieren [FDT24]. In den Validierungszyklen nutzt der Data Engineer das vollständig in den Prozess integrierte Tool Label Studio, um die von dem LLM generierten Mapping-Vorschläge zu validieren und zu korrigieren. Die weitere Verarbeitung kann daraufhin wieder automatisiert erfolgen [Hao24; XTE23].
Der Datenmigrationsprozess – ohne und mit LLMs
Im Allgemeinen besteht der Prozess der Datenmigration daraus, Daten aus einem oder mehreren Quellsystemen in ein gemeinsames Zielsystem zu übertragen, also zu migrieren. Die Aufgabe des Data Engineer besteht dabei darin, unterschiedlich gespeicherte, aber semantisch identische Informationen aus den verschiedenen Quellsystemen, hier Datenbanken, zu vereinheitlichen und/oder neue Informationen aus den Quellsystemen zusammenzustellen bzw. abzuleiten.
In der Regel durchläuft der Data Engineer bei der Datenmigration die in Abbildung 1 dargestellten Schritte – der Prozess ist also hinreichend komplex.
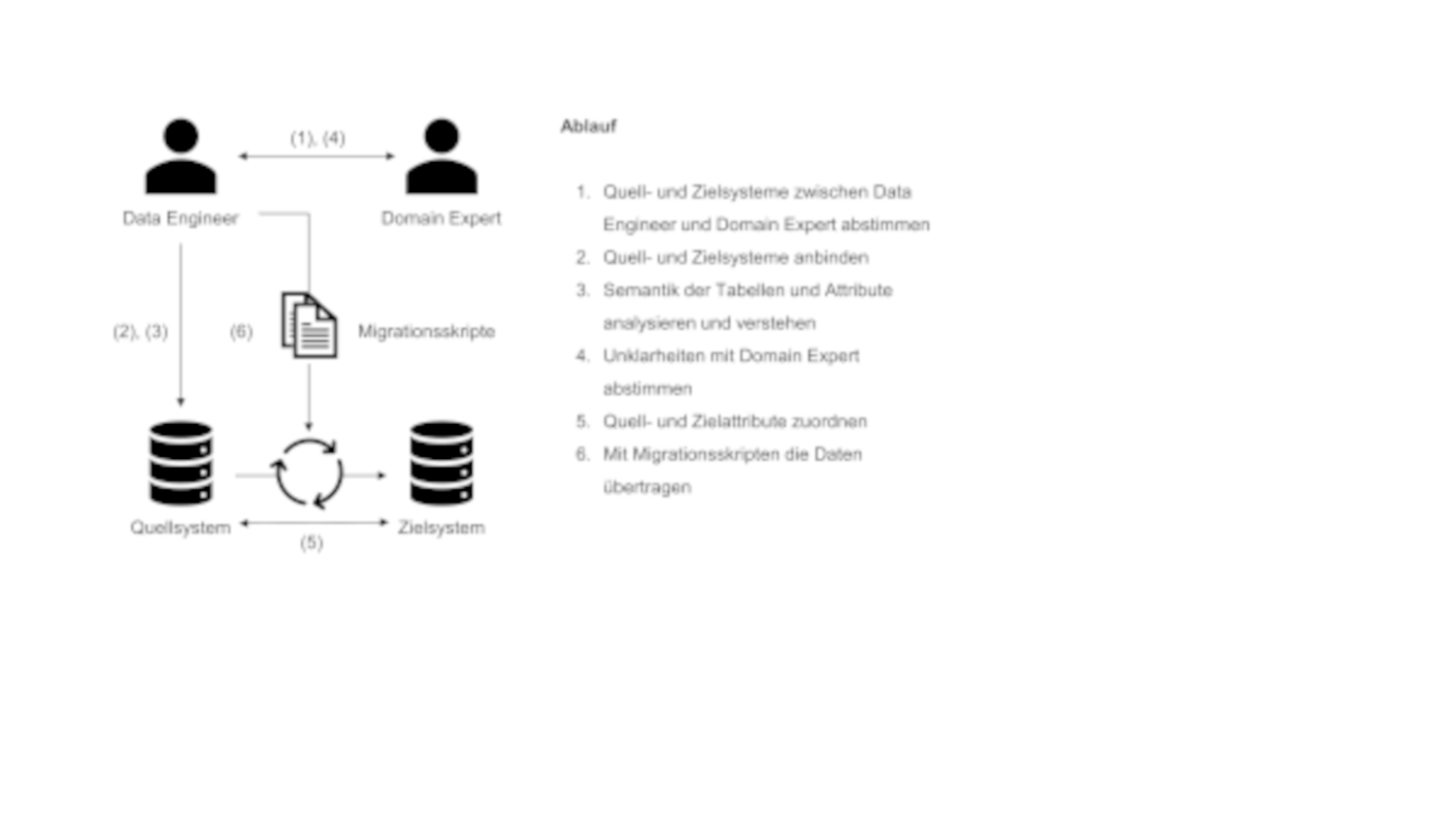
Abb. 1: Klassische Datenmigration
Zunächst müssen die Quell -und Zielsysteme mit dem Domain Expert definiert (Abbildung 1, (1)) und angebunden (2) werden, damit die Daten extrahiert werden können. Im nächsten Schritt (3) muss der Data Engineer die Informationen, die in Tabellen als Attribute abgelegt sind, analysieren und verstehen. Unklarheiten werden anschließend mit dem Domain Expert besprochen (4). Nun ist der Data Engineer in der Lage, die Quell- und Zielattribute einander zuzuordnen (5), um dann die Migrationsskripte zu erstellen (6). Diese beiden Punkte können dabei – je nach Fall – sehr komplex werden, da beispielsweise nicht aussagekräftige Spaltennamen oder inkonsistente Daten in den Spalten die Arbeit für den Data Engineer erheblich erschweren und damit auch die Fehleranfälligkeit bei der Durchführung des Prozesses erhöhen. Die Migrationsergebnisse müssen dann wiederum mit dem Domain Expert auf Fehler überprüft, diskutiert und die Erkenntnisse als Korrekturen in die Zuordnungen beziehungsweise das Migrationsskript eingearbeitet werden.
Durch die Integration von LLMs kann dieser Prozess vereinfacht und teilweise automatisiert werden, wie in Abbildung 2 dargestellt ist.
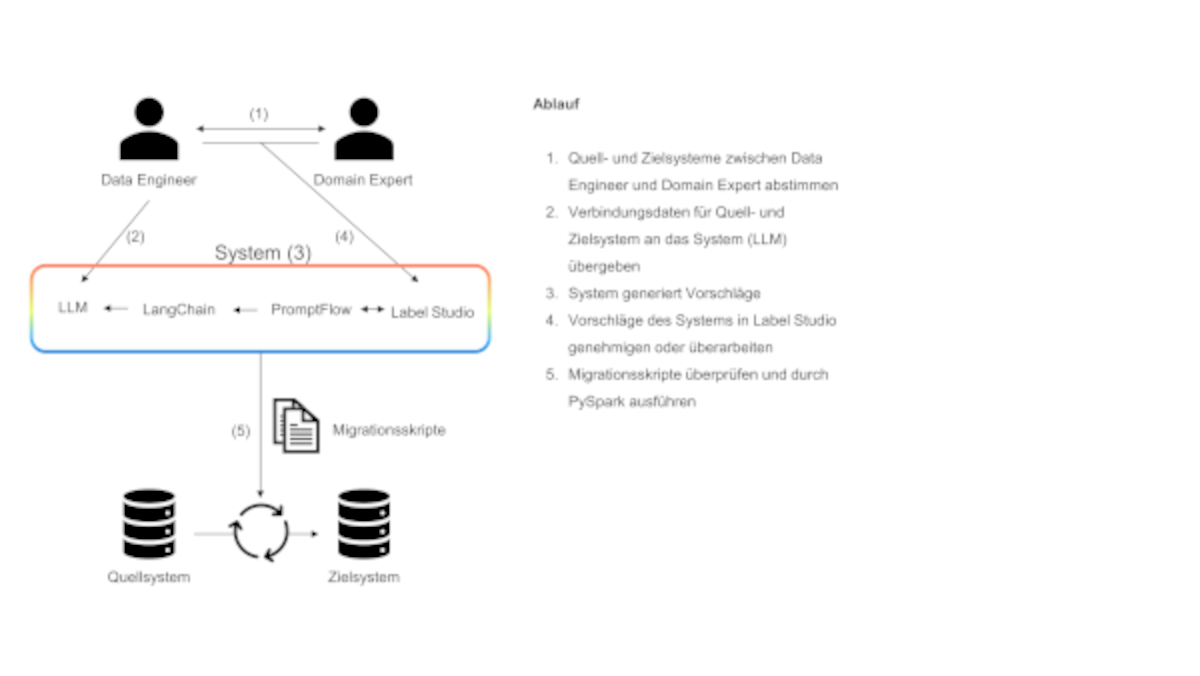
Abb. 2: LLM-unterstützte Datenmigration
Der Prozess beginnt auch hier mit einem Austausch zwischen dem Data Engineer und dem Domain Expert, um zu definieren, welche Informationen im Zielsystem verfügbar sein sollen und welche Quellsysteme dazu benötigt werden (Abbildung 2, (1)). Anschließend werden die Verbindungsdaten über die Quellsysteme und das Zielsystem an das LLM übergeben (2). Das LLM wird damit in die Lage versetzt, die für das Zielsystem relevanten Daten aus den Quellsystemen zu identifizieren und zu analysieren, um Zusammenhänge in den Daten für das Zielsystem zu ermitteln (3). Diese Zusammenhänge und Beziehungen leitet das LLM unter anderem aus den Namen, Beschreibungen und weiteren Metainformationen der Attribute in den Quellsystemen sowie im Zielsystem ab. Zusätzlich werden Ausschnitte der Tabellen- beziehungsweise Spalteninhalte hinzugezogen und analysiert.
Die so gesammelten Informationen und Erkenntnisse über Quell- und Zielsysteme werden genutzt, um dem Data Engineer Vorschläge für die Datenmigration bereitzustellen, die dieser daraufhin strukturiert evaluiert und gegebenenfalls korrigiert (4). Anschließend wird das nun vollständige und korrekte Mapping von einem weiteren LLM genutzt, um den Code für die Migration zu generieren.
Das Outputformat kann dabei an die bestehende Infrastruktur und die verwendeten ETL-Tools angepasst werden (zum Beispiel können Migrationsskripte in Python oder SQL erstellt werden). Abschließend werden die Ergebnisse durch den Data Engineer überprüft und gegebenenfalls Korrekturen am Migrationsskript vorgenommen (5).
Tools im Detail
- Prompt Flow ist ein Framework zur Erstellung und standardisierten Strukturierung von Workflows aus LLM-Aufrufen sowie zur Verwaltung der darin verwendeten Prompts und Prompt-Versionen. Während die eigentlichen Definitionen in Jinja-Dateien liegen, bietet Prompt Flow auch eine grafische Oberfläche zur Bearbeitung der Workflows.
- LangChain ist ein GenAI-Orchestrierungs- und Integrations-Framework, mit dessen Hilfe verschiedene für eine GenAI-Anwendung benötigte Komponenten einfach miteinander integriert werden können. Unter anderem erlaubt es eine einfach austauschbare Anbindung der APIs verschiedener LLM-Anbieter und verschiedener Vektordatenbanken. Weiterhin bietet es vordefinierte Funktionalitäten für komplexere LLM-Abläufe und Agenten.
- Label Studio ist ein Tool zur Annotation von Daten, das es Nutzern ermöglicht, verschiedene Arten von Daten wie Text, Bilder und Videos zu kennzeichnen. Es wird in Bereichen wie maschinelles Lernen und Datenanalyse eingesetzt, um Trainingsdatensätze für KI-Modelle zu erstellen und zu verwalten.
- PySpark ist eine Python-Schnittstelle für Apache Spark, die große Datenmengen schnell und parallel verarbeiten kann. Es ermöglicht die Durchführung von ETL-Prozessen (Extraktion, Transformation und Laden) sowie die Analyse und Bearbeitung großer Datenmengen in Python.
Anbieterunabhängig durch die Verwendung quelloffener Tools
Die Umsetzung dieses Anwendungsfalls kann auf unterschiedliche Arten erfolgen. Zum einen ist es aus Kundensicht möglich, auf die LLM-Plattformen der großen Anbieter wie Microsoft, Google oder Amazon zu setzen, was jedoch die Gefahr birgt, sich von diesen abhängig zu machen. Die rasante Entwicklung im Bereich generative KI hat gezeigt, dass der heutige Vorteil eines Anbieters morgen nicht mehr gegeben sein muss, da stetig neue Modelle und Services angeboten werden.
Die andere Möglichkeit besteht darin, auf freie, aber etablierte Frameworks zu setzen und somit anbieterunabhängig zu bleiben, ohne Einbußen bei der Modellqualität hinnehmen zu müssen. Dieser Ansatz wird im Folgenden durch den Einsatz von Prompt Flow, LangChain, Label Studio und PySpark beschrieben. Dabei handelt es sich um eine beispielhafte Implementierung, die durch Anpassung einzelner Komponenten leicht an die eigene Infrastruktur angepasst werden kann.
Wir nutzen Prompt Flow, um die einzelnen Verarbeitungsschritte zu Prozessen zu modellieren, darunter auch die Aufrufe des angebundenen LLM. Abbildung 3 zeigt einen Ausschnitt des Verarbeitungsprozesses: Dem LLM werden in den drei Verarbeitungsschritten read_example_data, read_target_schemas und read_source_schemas Informationen bereitgestellt, die dieses nutzt, um daraus die Zuordnungen der Quell- und Zielattribute zu erstellen (map_schemas). Die Ergebnisse werden im nachfolgenden Verarbeitungsschritt nach Label Studio exportiert (export_to_label_ studio). Damit ist dieser Teilprozess abgeschlossen.
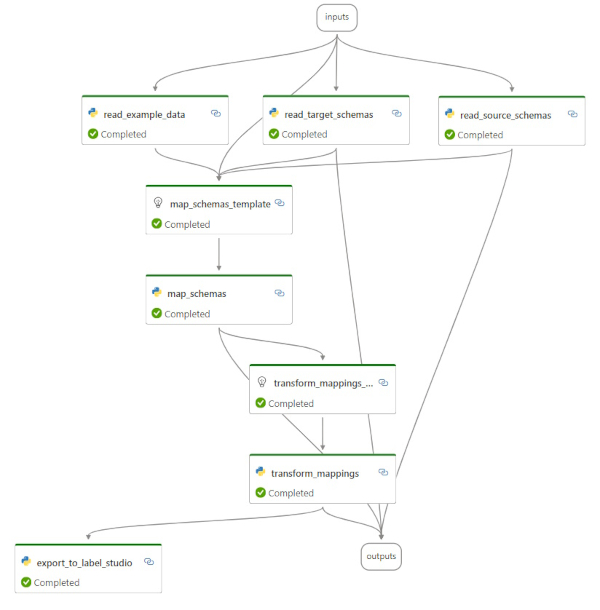
Abb. 3: Visuelle Darstellung eines Teilprozesses in Prompt Flow (Screenshot)
Für die Aufrufe an das LLM werden die API-Integrationen von LangChain genutzt. Dadurch wird die Integration der LLMs anbieterunabhängig und es kann problemlos zwischen Anbietern wie OpenAI, Microsoft, Google und Amazon sowie auch selbst gehosteten Open-Source-Modellen gewechselt werden. Die Schnittstelle zum Human-in-the-Loop stellt in unserem System Label Studio dar. Dort werden die Vorschläge dem Data Engineer und dem Domain Expert präsentiert, die sie auf Korrektheit überprüfen. Am Ende wird PySpark genutzt, um die Daten – gemäß dem Migrationsskript – in das Zielsystem zu transformieren.
Bezeichnungen, Daten und Metainformationen – womit das LLM arbeitet
Für die Vorschläge zur Zuordnung der Attribute der Quellsysteme zum Zielsystem werden vom LLM verschiedene Informationen verwendet. Einige Optionen dafür sind im dargestellten Migrationsszenario für Kundendaten (Abbildung 4) illustriert.
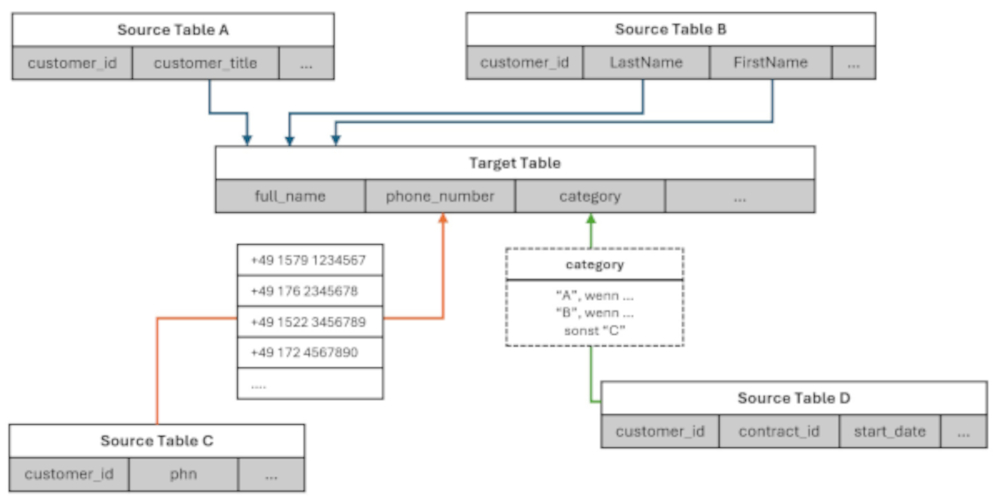
Abb. 4: Illustration der drei Zuordnungsbeispiele (Screenshot)
In der Mitte befindet sich die Zieltabelle (Target Table), die mit Daten zu befüllen ist. Darum verteilt sind vier Quelltabellen (Source Table A, Source Table B, Source Table C, Source Table D) abgebildet, aus denen die Daten extrahiert werden sollen. Diese Tabellen können Teil derselben Datenbank oder aber auch über verschiedene Datenbanken beliebigen Typs verteilt sein. Die farbigen Pfeile stellen die Vorschläge des LLM für Zuordnungen von Spalten aus den Quelltabellen zu Spalten aus der Zieltabelle dar. Anhand dieser Zuordnungen können später, das heißt nach der Validierung durch den Data Engineer, mithilfe eines weiteren LLM die Migrationsskripte generiert werden.
Beispielhaft sind hier drei Spalten der Zieltabelle abgebildet: full_name, phone_number und category. Im Folgenden wird anhand der drei Zielspalten jeweils der Weg der Zuordnung in die Zieltabelle beschrieben.
Beispiel 1: Zielspalte „full_name“
Die erste zu befüllende Spalte in der Zieltabelle ist der vollständige Name des Kunden („full_name“). Die Zuordnung von Quell- zu Zielspalte ist durch die blauen Pfeile illustriert. Dies ist der einfachste Fall, da alle Spaltennamen sinnvoll benannt sind und das LLM somit leicht ableiten kann, dass der vollständige Name aus dem Vornamen („FirstName“) und dem Nachnamen („LastName“) aus Source Table B und dem Titel („customer_ title“) aus Source Table A zusammengesetzt ist. Dass diese Informationen in verschiedenen Tabellen liegen, die anhand von Datenbankschlüsseln zusammengeführt werden müssen, stellt für aktuelle LLMs kein Problem dar, solange die notwendigen Metainformationen wie Tabellen-Relationen – hier die „customer_id“ – vorhanden sind.
Beispiel 2: Zielspalte „phone_number“
Da die zuzuordnende Spalte aus der Quelltabelle (Illustration der Verknüpfung durch orangen Pfeil) “phn“ keinen direkt sprechenden Namen besitzt, kann das Modell hier noch nicht allein aus den Spaltenbezeichnungen eine Verknüpfung ableiten. Hier hilft dem LLM die Hinzunahme von Beispieldaten aus der Spalte „phn“, um zu erkennen beziehungsweise abzuleiten, dass es sich um eine Spalte mit Telefonnummern handelt und diese daher der Zielspalte „phone_number“ zuzuordnen ist. Die Barrierefreiheit in puncto Sprache und Flexibilität in Bezug auf dargestellte Abkürzungen von Attributnamen unterscheidet dabei den Ansatz von herkömmlichen Werkzeugen für das Data-Mapping.
Beispiel 3: Zielspalte „category“
In diesem Fall (Vorschlag LLM siehe grüner Pfeil) ist weder ein sprechender Spaltenname in der Quelltabelle vorhanden noch lässt sich aus den enthaltenen Daten der Quelltabelle eine direkte Bedeutung der Spalte ableiten. Deshalb sind in diesem Fall zusätzliche Metadaten und Informationen notwendig, die die Erzeugungslogik dieser Spalte beschreiben. Mithilfe dieser Informationen, die zum Beispiel automatisiert aus einem Data Catalog gezogen oder manuell mittels beschreibender Regeln durch den Data Engineer ergänzt werden, ist es dem LLM möglich, auch diese Spalte korrekt zuzuordnen.
Die automatisiert erzeugten Zuordnungen des LLM werden anschließend vom Data Engineer und dem Domain Expert auf ihre Korrektheit überprüft. Dazu werden zunächst alle Zuordnungen in einer Gesamtübersicht dargestellt (Abbildung 5).
Abb. 5: Ergebnisse des LLM in Label Studio (Screenshot)
Jede Zeile stellt dabei eine Zuordnung der Quellsysteme dar, die für das Erstellen der Informationen im Zielsystem benötigt werden. Die Zuordnungen können nun vom Data Engineer und vom Domain Expert einzeln durchlaufen und auf ihre Korrektheit überprüft werden.
Anschließend ermöglicht es Label Studio, jede Zuordnung einzeln zu prüfen und zu bewerten (Abbildung 6).

Abb. 6: Beispiel-Zuordnung für Telefonnummern (Screenshot)
Dazu werden dem Data Engineer und dem Domain Expert für jede einzelne Zuordnung die entsprechend benötigten Quellsysteme samt Tabellen- und Attributnamen angezeigt. Sind beide mit der Zuordnung einverstanden, markieren sie diese als Correct, andernfalls als Incorrect. Bei einer als Incorrect klassifizierten Zuordnung wird diese Information mit der Begründung, warum es sich um eine fehlerhafte Zuordnung handelt, für eine Korrektur an das LLM zurückgegeben oder dem Modell wird direkt die korrigierte Zuordnung als Input für das Migrationsskript mitgegeben. Ist die Zuordnung abgeschlossen, wird das Migrationsskript von einem weiteren LLM erzeugt und ausgeführt.
Fazit
Die Zusammenarbeit von Menschen mit LLMs wird die zukünftige Arbeitswelt prägen und verändern. Denn LLMs unterstützen den Menschen, indem sie ihm repetitive und ermüdende Tätigkeiten abnehmen und darüber hinaus diese Tätigkeiten mit wesentlich höherer Skalierung ausführen können. Gleichzeitig bleibt der Mensch ein entscheidender Faktor in diesem Prozess, um die Qualität der Ergebnisse sicherzustellen, zum Beispiel Fehleinschätzungen (Halluzinationen) von LLMs zu korrigieren, fachliche Weiterentwicklung sicherzustellen und auch komplexe Sonderfälle umzusetzen.
Daher sollten LLMs nicht als Ersatz für menschliche Kompetenz betrachtet werden, sondern als kompetenter Helfer beziehungsweise Assistent. Denn erst in Kombination sind sie in der Lage, schnelle, hochwertige und vor allen Dingen vertrauenswürdige Ergebnisse zu liefern.
Der hier beispielhaft umgesetzte Anwendungsfall der Datenmigration verdeutlicht dabei, wie die Stärken beider genutzt werden können, um den bisher rein manuellen Datenmigrationsprozess teilautomatisiert und somit effizient durchzuführen.
Glossar
- Data Catalog: Ein Data Catalog dient als zentrale Informationsquelle, die es Nutzenden ermöglicht, Daten schnell und effizient zu finden. Es handelt sich dabei um eine Art Bibliothek, die Metadaten erfasst. Datenmigration: Im Allgemeinen bezeichnet der Begriff Datenmigration die Übertragung von Daten an andere Standorte, Umgebungen, Speichersysteme, Datenbanken, Rechenzentren, Anwendungen oder in andere Dateiformate.
- Human-in-the-Loop: Beim Human in the Loop nimmt der Mensch eine entscheidende Rolle in der Interaktion einer KI mit dessen Umgebung ein. Das können entweder kontrollierende oder ergänzende Tätigkeiten sein, damit die KI innerhalb produktiver Systeme wirken kann. LLM: Ein großes Sprachmodell (Large Language Model, LLM) ist eine Art von KI-Programm, das neben anderen Aufgaben auch Text erkennen und generieren kann. LLMs werden auf riesigen Datenmengen trainiert – daher der Name.
- Metainformationen: Metainformationen beinhalten die verschiedenen Relationen, aber auch die klingenden Attributwerte und Attribute und dienen dazu, Daten zu beschreiben und die Migration automatisiert durchführbar zu machen.
- Quelloffene Tools: Als quelloffene Software wird Software bezeichnet, deren Quelltext öffentlich ist und von Dritten eingesehen werden kann. Im Gegensatz zu proprietären Tools können wir bei quelloffenen Lösungen Lock-in-Effekte vermeiden und in einem volatilen Technologiefeld maximal flexibel agieren.
- Validierungsprozess: Im Gegensatz zu einem reinen Kontrollprozess fokussiert sich die Validierung auf die lösungsorientierte Anreicherung von Informationen und die Korrektur von Entscheidungen des Modells und erweitert dadurch die grundsätzliche Menge an qualitativen Beispieldaten.
Weitere Informationen
[AyG24] Ayyamperumal, S. G. / Ge, L.: Current state of LLM Risks and AI Guardrails. 2024
[FDT24] Feng, L. / Dong, J. K. / Tse-Husn, C.: When LLM-based Code Generation Meets the Software Development Process. 2024
[Hao24] Haolin, J. et al.: From LLMs to LLM-based Agents for Software Engineering: A Survey for Current Challenges and Future. 2024
[She23] Shengchen, Y. et al.: LLM for Test Script Generation and Migration: Challenges, Capabilities and Opportunities. 2023
[Teh24]Tehrani, B.O. et al.: Evaluating Human-AI Partnership for LLM-based Code Migration. In: Extended Abstracts of the 2024 CHI Conference on Human Factors in Computing Systems, 2024
[XTE23] Xi Rao, S. / Tu, Y. / Egger, P. H.: SAINE: Scientific Annotation and Inference Engine of Scientific Research. 2023
[Yan23] Yang, X. et al.: Human-in-the-loop Machine Translation with Large Language Model. 2023









