

Unter KI-basierten Systemen verstehen wir softwarebasierte Systeme, welche neben klassischen Komponenten auch KI-Komponenten beinhalten. Somit kann sowohl eine mobile App, welche Bilder oder Sprache auf Basis von Deep-Learning-Modellen erkennt, als auch ein intelligent gesteuertes autonomes Fahrzeug als KI-basiertes System verstanden werden.
Was sind KI-basierte Systeme?
In diesem Zusammenhang ist natürlich auch die Frage zu klären, was man unter KI (Künstliche Intelligenz bzw. Artificial Intelligence, AI) versteht. Da es keine eindeutige und universell akzeptierte Definition des Begriffs gibt, wollen wir darunter pragmatisch die Automatisierung von Aufgabenstellungen verstehen, welche menschlicher Intelligenz bedürfen. Diese Definition ist natürlich zeit und kontextabhängig. In den 1980er-Jahren etwa hat man KI primär mit regelbasierten Expertensystemen identifiziert. Heute verstehen wir darunter vor allem lernende Systeme, die auf Machine Learning (ML) und vor allem Deep Learning (DL) beruhen. Insofern verstehen wir hier unter KI-Komponenten primär solche, deren Funktionalität durch ML- oder DL-Verfahren realisiert wird.
Beim ML lernt man in einer Trainingsphase ein stochastisches Modell aus Trainingsdaten, welches dann mit einer bestimmten Genauigkeit Vorhersagen für neue Eingabedaten machen kann. Wenn das Modell auf einem künstlichen neuronalen Netz basiert, dann spricht man von DL.
Moderne KI-Komponenten unterscheiden sich fundamental von traditionellen Softwarekomponenten durch die Eigenschaft, dass sie stochastisch aus Daten lernen und deshalb inhärent nicht-deterministisch und mit statistischer Unsicherheit behaftet sind und sich autonom durch die Bereitstellung neuer Daten weiterentwickeln können.
Aufgrund dieser Unterschiede werden KI-Komponenten (und daraus resultierende Systeme) auch anders entwickelt: Das Aufbereiten von Daten sowie die Auswahl, das Trainieren und Validieren von (ML-/DL-) Modellen erfolgt typischerweise durch Data Scientists oder AI Engineers, welche auch teilweise eine andere Terminologie verwenden als im Softwaretesten. Der Begriff „Regression“ steht im KI-Kontext typischerweise nicht für „Regression Testing“, sondern für statistische Regressionsmodelle. Unter dem Begriff „Testen“ wird im KI-Kontext typischerweise die Bestimmung der Leistung, etwa gemessen durch die Genauigkeit (Accuracy) oder das F-Maß, auf Basis des Testdatensatzes verstanden. Aus diesem Grund verwenden wir im Folgenden nicht den Begriff „Testen“, sondern Qualitätssicherung, um die Sichtweise des Software-Engineering und klassischen Testens auf der einen Seite sowie des AI-Engineering und Data Science auf der anderen Seite zu integrieren und Missverständnisse zu vermeiden [FeRa21].
Klassifikation der Qualitätssicherungstechniken für KI-basierte Systeme
Qualitätssicherungstechniken für KI-basierte Systeme können entlang der drei Dimensionen Artefakttyp, Qualitätseigenschaft und Qualitätssicherungsart (siehe Abbildung 1) klassifiziert werden. Nachfolgend beschreiben wir diese drei Dimensionen genauer.
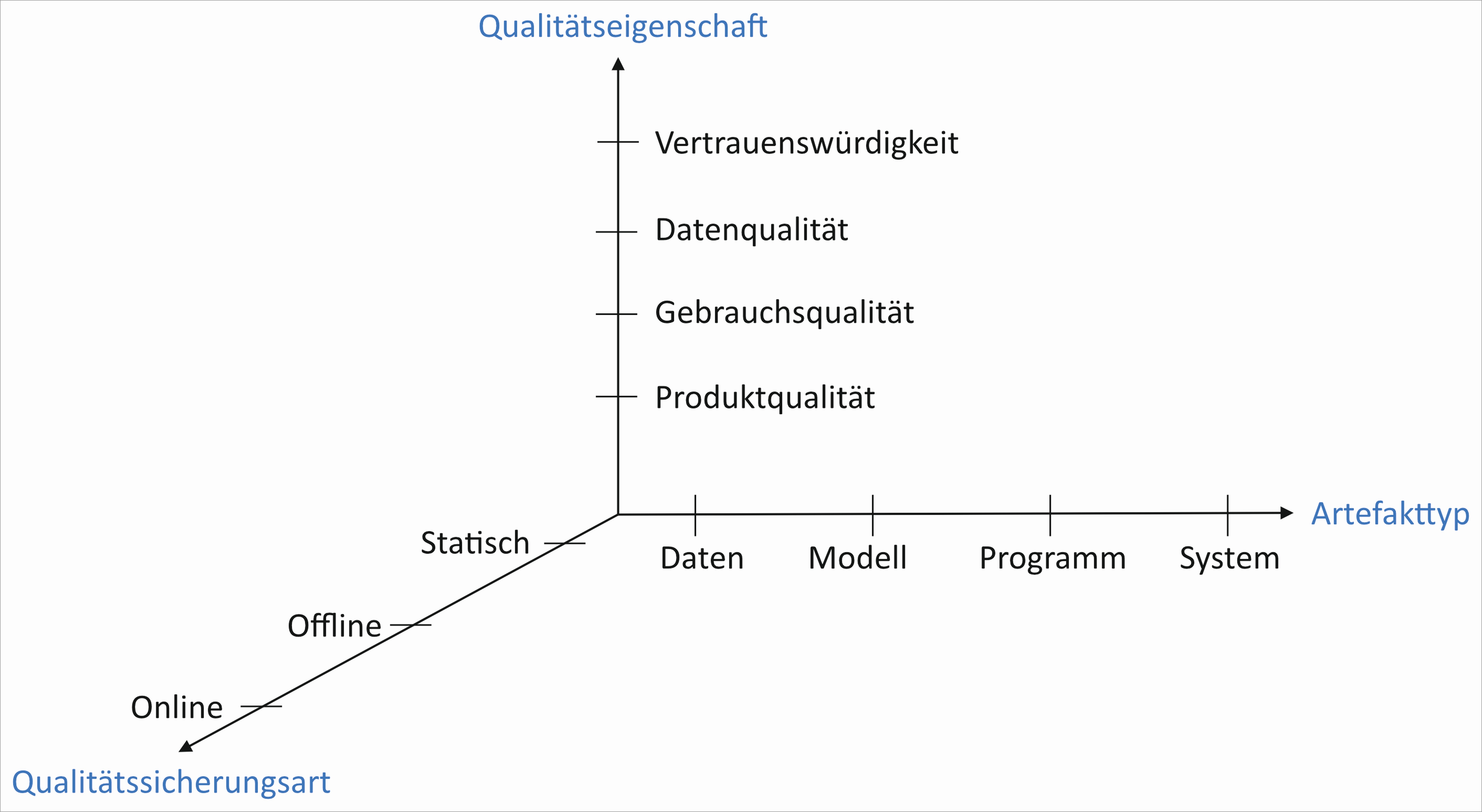
Abb. 1: Dimensionen zur Klassifikation von Qualitätssicherungstechniken für KI-basierte Systeme
Artefakttyp
Das Basisartefakt für KI-Komponenten sind strukturierte und unstrukturierte Daten, die für das Trainieren und Validieren von ML-/ DL-Algorithmen benötigt werden. Diese Daten müssen vorverarbeitet und qualitätsgesichert werden, etwa indem die Konsistenz und Vollständigkeit der Daten geprüft wird. Ein trainiertes ML-/DL-Modell erlaubt Vorhersagen, indem etwa Verkehrsschilder korrekt erkannt werden. Diese Modelle haben immer eine gewisse Genauigkeit, die es zu testen gilt. Darüber hinaus ist es auch wichtig, ihre Robustheit bei unerwarteten Eingaben zu prüfen.
Das Programm umfasst den Quellcode, typischerweise unter Einbindung von Bibliotheken wie Tensorflow, um Daten und Modelle zu integrieren und verarbeiten. Da es sich um Code handelt, spielt hier das klassische Unitund Integrationstesten eine große Rolle. Ein System integriert klassische Komponenten und KI-Komponenten und hat dabei bestimmte funktionale und nicht-funktionale Eigenschaften zu erfüllen, was durch Systemtests geprüft werden muss.
Qualitätseigenschaft
Qualitätseigenschaften legen das Ziel und die Vorgehensweise von Qualitätssicherungsmaßnahmen fest. Da auch KI-basierte Systeme wie klassische Systeme softwarebasiert sind, sind auch für diese zunächst einmal die Charakteristiken für Produkt- und Gebrauchsqualität, welche in ISO/IEC 25010:2011 definiert werden, relevant. Die Produktqualitäts-Charakteristiken umfassen Funktionalität (Functional suitability), Performanz (Performance efficiency), Kompatibilität (Compatibility), Gebrauchstauglichkeit (Usability), Zuverlässigkeit (Reliability), (Informations-)Sicherheit (Security), Änderbarkeit (Maintainability) und Übertragbarkeit (Portability). Die Gebrauchsqualitäts-Charakteristiken umfassen Effektivität (Effectiveness), Produktivität (Efficiency), Zufriedenheit (Satisfaction) und Safety (Freedom from risk).
Darüber hinaus spielt im Gegensatz zu klassischen Systemen auch die Datenqualität eine große Rolle. In der ISO 25000-Standardfamilie gibt es dafür den Standard ISO/ IEC 25012:2008 zur Datenqualität. Dieser unterscheidet inhärente und systemabhängige Datenqualitäts-Charakteristiken. Inhärente Datenqualität betrifft die Daten selbst und systemabhängige Datenqualität die Daten in einem bestimmten Anwendungskontext. Zu den inhärenten Datenqualitäts-Charakteristiken gehören Accuracy, Completeness, Consistency, Credibility, Currentness. Accessibility, Compliance, Confidentiality, Efficiency, Precision, Traceability und Understandability können als inhärente und systemabhängige Datenqualitäts-Charakteristiken verwendet werden. Availability, Portability und Recoverability sind systemabhängige Datenqualitäts-Charakteristiken.
Die Standards der ISO 25000-Reihe decken die datengetriebene Natur von KI-basierten Systemen nicht adäquat ab. Der aufkommende Standard ISO/IEC 24028 definiert deshalb die Vertrauenswürdigkeit (Trustworthiness) als Qualitätseigenschaft solcher Systeme. Die Vertrauenswürdigkeit umfasst Eigenschaften wie die Transparenz (Transparency), Erklärbarkeit (Explainability), Resilienz (Resilience), Kontrollierbarkeit (Controllability), Datenschutz (Privacy) oder Gerechtigkeit (Fairness).
Qualitätssicherungsart
Die Qualitätssicherung kann statisch erfolgen, ohne ein Artefakt auszuführen, etwa wenn Konsistenzprüfungen direkt auf Daten durchgeführt werden oder wenn statische Analyse auf Programme angewendet wird. Die Qualitätssicherung erfolgt offline, wenn ein Artefakt isoliert ausgeführt wird. Unter die Offline-Qualitätssicherung fällt etwa das isolierte Testen von ML-Modellen mit historischen Daten, ohne die Datenverarbeitung oder das Umgebungsverhalten zu berücksichtigen.
Die Qualitätssicherung erfolgt online, wenn Artefakte in einem Anwendungskontext und in Interaktion mit der Umgebung ausgeführt werden. Wenn etwa ein ML-Modell zur Empfehlung von Produkten direkt in einem Online-Shop für ein bestimmtes Kundensegment getestet wird, dann ist das ein typisches Beispiel für Online-Testen. Häufig wird auch das A/B-Testen, bei dem unterschiedliche Varianten der Software, die sich in funktionalen bzw. nicht-funktionalen Eigenschaften unterscheiden, miteinander verglichen werden, als Online-Testverfahren eingesetzt. Auch das Testen von ML-Modellen in Simulationsumgebungen, wie das etwa beim autonomen Fahren der Fall ist, ist eine Online-Qualitätssicherungstechnik.
Alle diese Qualitätssicherungsarten müssen voll- oder teilautomatisiert erfolgen, um effizient und effektiv durchgeführt werden zu können.
Welche Rolle spielt die Risikobewertung?
Für das effiziente und effektive Testen klassischer Softwaresysteme hat sich das risikobasierte Testen als sehr erfolgversprechender Ansatz etabliert [FeSch14]. Dabei wird eine Bewertung der Softwareproduktrisiken durchgeführt, um eine risikobasierte Teststrategie zu entwickeln, die es erlaubt, alle Phasen des Testprozesses, d. h. das Testdesign, die Testautomatisierung, die Testausführung sowie die Bewertung der Testergebnisse, zu steuern. Die Risikobewertung integriert die Fehlerwahrscheinlichkeit von Testelementen (wie Systemkomponenten) mit der Auswirkung bei Eintritt eines Fehlers und erlaubt es, das Testen so zu steuern, dass kritische Fehler früh gefunden werden bzw. die Testressourcen zielgerichtet eingesetzt werden können [FeRa16]. Für komplexe Systeme ist eine risikoorientierte Vorgehensweise die einzige Möglichkeit, das Testen unter gegebenen zeitlichen, budgetären und technischen Randbedingungen zu automatisieren und beherrschbar zu machen.
Die risikobasierte Vorgehensweise ist aber auch sehr hilfreich, um eine Qualitätssicherungsstrategie für KI-basierte Systeme, die etwa die eingesetzten Arten der Testautomatisierung für das Statische Testen sowie das Offline- und Online-Testen regelt, zu entwickeln. Wir wollen hier nur die Risikobewertung für KI-Komponenten genauer betrachten – jene von klassischen Komponenten kann mit klassischen risikobasierten Testansätzen adressiert werden, wofür wir in [FeSch14] eine methodische Vorgehensweise beschreiben.
Abbildung 2 zeigt einen Überblick über die zentralen Qualitätssicherungsaktivitäten (Statisches Testen, Offline-/Online-Testen) für die unterschiedlichen Artefakte (Daten, Modell, Programm, System) in einem KI-basierten System und einen möglichen Risikobewertungsansatz. Dreh- und Angelpunkt der Risikobewertung für KI-Komponenten sind einzelne Merkmale oder Merkmalsgruppen. Diese Merkmale (im ML-Kontext typischerweise „Features“ genannt) sind messbare Eigenschaften, die als unabhängige Eingangsvariablen in ML-Modellen zur Vorhersage abhängiger Variablen oder zur Identifikation von Mustern dienen. Solche Merkmale können etwa Bildeigenschaften wie Farben oder Objekte in bestimmten Bildregionen sein, wenn es um Bilderkennung geht, oder Luftfeuchtigkeit oder Außentemperatur, wenn es um die Wettervorhersage geht.
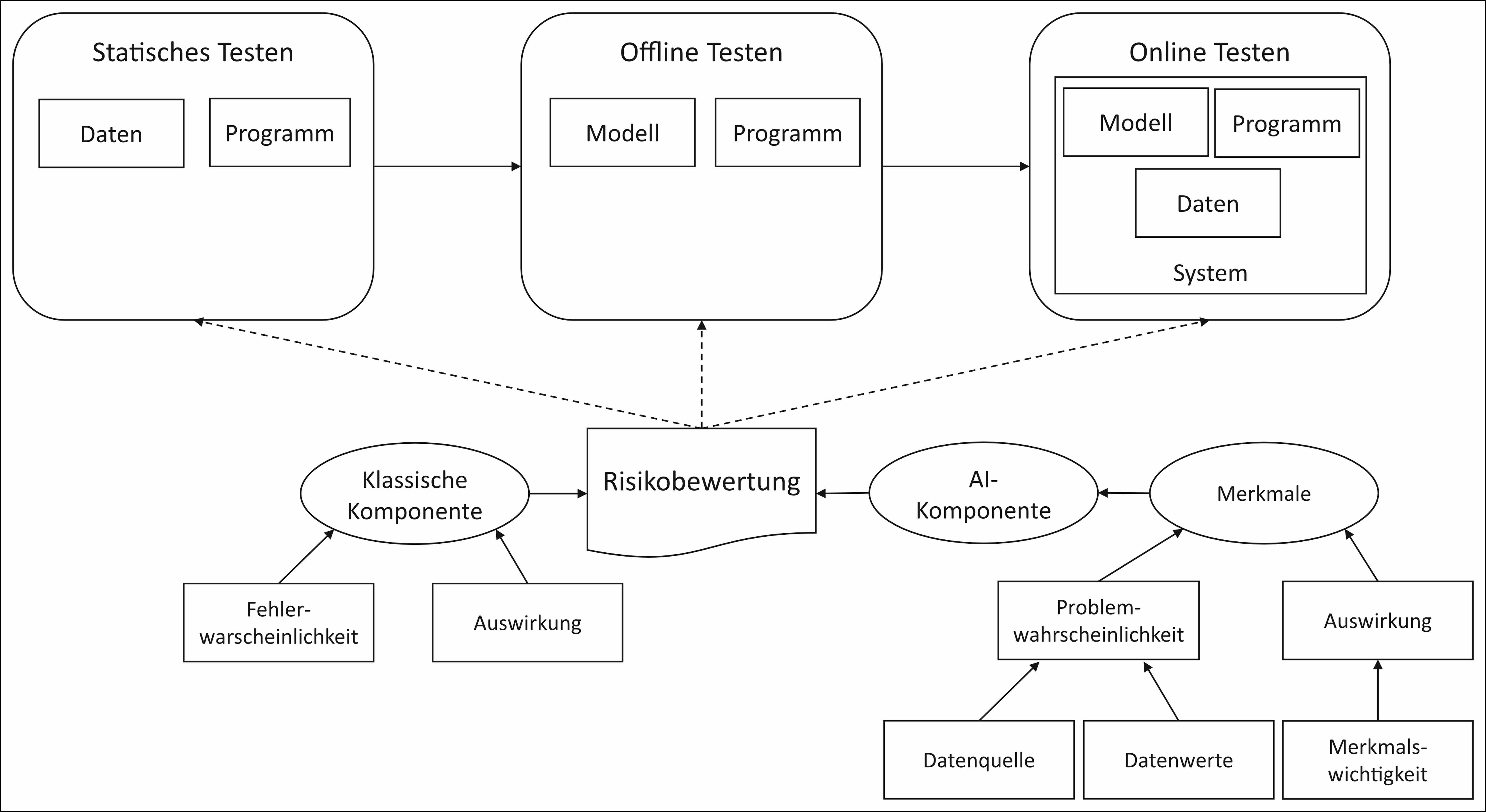
Abb. 2: Überblick über das risikobasierte Testen von KI-basierten Systemen
Merkmale haben konkrete Datenwerte (die mit einem Domänenmodell, welche Wertebereiche welcher Datentypen möglich sind) und stammen aus Datenquellen (etwa Sensoren oder Datenbanken), welche diese Werte kontinuierlich liefern oder abspeichern. Diese Informationen über Merkmale können verwendet werden, um problematische Merkmale oder Merkmalsbereiche zu identifizieren, also etwa Randwerte oder Merkmale, die aus unstabilen Datenquellen stammen. Gemeinsam mit der Wichtigkeit von Merkmalen oder Merkmalsgruppen kann so ein qualitatives oder sogar quantitatives Risikomodell aufgebaut werden. Ein solches Modell für das Online-Testen wird etwa in [FeRa16] vorgestellt.
Wie für klassische Komponenten erlaubt es die Risikobewertung auch für KI-Komponenten, die Qualitätssicherungsmaßnahmen zu steuern. Die Risikobewertung kann etwa zur automatisierten Generierung von positiven und negativen Testdaten für das Offline-Testen der Korrektheit und Robustheit von ML-Modellen verwendet werden. Weiters kann auch die Intensität der automatisierten Prüfung von Datenströmen zur Laufzeit im Online-Test über die Risikobewertung gesteuert werden. Darüber hinaus ist die Risikobewertung auf der Ebene von Merkmalen auch für die Generierung von Testszenarien, etwa für die Simulation von Systemen im Online-Test, sehr nützlich.
Fazit
Die automatisierte Qualitätssicherung von KI-basierten Systeme ist ein hochaktuelles Thema, das sowohl die Forschung als auch die Praxis beschäftigt. Um zur Schaffung einer einheitlichen Terminologie beizutragen, haben wir in diesem Artikel die Qualitätssicherungstechniken für KI-basierte Systeme entlang der drei Dimensionen Artefakttyp, Qualitätseigenschaft und Qualitätssicherungsart klassifiziert. Darauf aufbauend wurde ein Risikobewertungsschema, welches die Eingangsvariablen von ML-Modellen (sog. Merkmale oder Features) in den Mittelpunkt stellt, erläutert und die Ableitung einer risikobasierten Qualitätssicherungsstrategie für KI-basierte Systeme skizziert.
Eine risikobasierte Qualitätssicherungsstrategie ermöglicht es, die Qualitätssicherung für komplexe KI-basierte Systeme an der Schnittstelle zwischen Software-Engineering und Test auf der einen und AI-Engineering und Data Science auf der anderen Seite geeignet zu automatisieren und dadurch beherrschbar zu machen.
Weitere Informationen
[FeRa16]
M. Felderer, R. Ramler, Risk orientation in software testing processes of small and medium enterprises: an exploratory and comparative study, in: Software Quality Journal, 24(3), S. 519 ff., Springer, 2016
[FeRa21]
M. Felderer, R. Ramler, Quality Assurance for AI-Based Systems: Overview and Challenges, in: Software Quality Days 2021 (SWQD 2021), S. 139 ff., Springer, 2021
[FeSch14]
M. Felderer, I. Schieferdecker, Handreichung zur Methodenauswahl - Eine Taxonomie risikobasierter Softwaretests, in: OBJEKTspektrum, Testing, 2014
[FoiFe19]
H. Foidl, M. Felderer, Risk-based data validation in machine learning-based software systems, in: MaLTeSQuE@ESEC/SIGSOFT FSE 2019, S. 13 ff., ACM, 2019
[ISO-a]
ISO/IEC 25012:2008 Software engineering – Software product Quality Requirements and Evaluation (SQuaRE) – Data quality model, 2008
[ISO-b]
ISO/IEC 25010:2011 Systems and software engineering – Systems and software Quality Requirements and Evaluation (SQuaRE) – System and software quality models, 2011
[ISO-c]
ISO/IEC TR 24028:2020 Information technology – Artificial intelligence – Overview of trustworthiness in artificial intelligence, 2020









