

Infrastruktur im Cluster
In Kubernetes dienen Pods zur Ausführung von Containern als zusammengehörige Einheit. Innerhalb eines Pods können einzelne Anwendungen, aber auch Infrastrukturkomponenten laufen. Kubernetes kann diese Pods jedoch nach Belieben erstellen oder zerstören – insbesondere dann, wenn sich etwa die Anzahl der Knoten im Cluster verändert. Anwendungen, die als Pods in Kubernetes bereitgestellt werden, müssen also mit dieser Fluktuation umgehen können. Händische Veränderungen an einer laufenden Anwendung in Kubernetes sind zu vermeiden, da diese im nächsten Moment wieder verschwunden sein könnten. Bereits vor Kubernetes hat sich der Gedanke Cattle, not Pets gerade im Cloud-Umfeld, eingebürgert. Anwendungen (aber auch Infrastruktur) sollten als austauschbare Nutztiere (Cattle) angesehen werden – und eben nicht als geliebte Haustiere (Pets). Falls eine Anwendung mal abstürzen sollte, wird sie einfach emotionslos ersetzt (wie es bei Nutztieren der Fall ist). Der Verlust eines Haustieres hingegen ist mit deutlich mehr Schmerz verbunden. Nicht jedem mag diese Tier-Analogie gefallen, aber die Essenz ist: Anwendungen sollten keine Sonderbehandlung benötigen – schon gar keine, die das spontane Austauschen erschwert.
Viele (Legacy-)Anwendungen, aber vor allem Infrastrukturkomponenten, wie Datenbanken, lassen sich nur schwer als Cattle behandeln. Eine SQL-Datenbank etwa hat oft spezielle Anforderungen, wie etwa die Maschine, auf der sie läuft (z. B. viel RAM, eine bestimmte Festplatte), wie viele Instanzen es geben kann oder die Vermeidung plötzlicher Neustarts. Ganz auf Pets zu verzichten, ist daher oft schwierig oder gar unmöglich.
Inzwischen bietet Kubernetes jedoch Mechanismen, um die Arbeit mit Pets zu ermöglichen. Ohne ins Detail zu gehen: Sowohl Stateful Sets (früher passenderweise als Pet Sets bezeichnet) als auch Persistent Volumes helfen dabei, dass auch Pets sich in Kubernetes wohlfühlen können. Auch wenn die Verwendung dieser Mechanismen bei Weitem nicht trivial ist, können so in vielen Fällen auch Infrastrukturkomponenten als Cattle behandelt werden.
Kubernetes-Operatoren
Um den Umgang mit Pets zu erleichtern, wurden für die meisten bekannten Technologien, wie etwa PostgresQL, Kafka usw., sogenannte Kubernetes-Operatoren entwickelt. Diese verstecken die oft aufwendige Konfiguration der Technologien hinter einer Kubernetes-freundlichen Abstraktion, die aus dem Haustier gewissermaßen ein Nutztier macht. Operatoren überwachen kontinuierlich den Zustand der Komponenten und greifen bei vielen Problemen zeitnah automatisiert ein. Der Benutzer des Operators muss die dahinterliegenden Mechanismen (wie etwa Stateful Sets) glücklicherweise nicht im Detail kennen, da diese letztlich ein Implementierungsdetail darstellen. Ein solcher Operator übernimmt zusätzlich Aufgaben wie Datenreplikation zwischen Instanzen, regelmäßige Backups, Versions-Upgrades sowie Ausfallsicherheit. Eben genau die Sonderbehandlung, die Pets im Vergleich zu normalen, zustandslosen Anwendungen benötigen. Generell verfolgt ein Operator oft etablierte Best Practices für den Einsatz der Technologie in einem Kubernetes-Cluster und basiert nicht selten auf über Jahre gewachsenem Expertenwissen auch außerhalb der Kubernetes-Welt.
In der Praxis definieren Operatoren Custom Resources, die eine einfache Verwendung der Abstraktion in Kubernetes ermöglichen. So kann analog zur Beschreibung eines Anwendungs-Deployments auch in gleicher Weise eine Datenbank, ein Message-Broker usw. bereitgestellt werden. Die Orchestrierung von Anwendung und der benötigten Infrastruktur folgt so also einem einheitlichen Vorgehen, ohne dass ein Technologiebruch entsteht.
Listing 1 zeigt ein Beispiel für eine Custom Resource, die vom Zalando Postgres Operator [GitH] unterstützt wird; sie beschreibt einen Postgres 15-Cluster mit zwei Instanzen, jeweils mit 1 Gi Festplattenspeicher.
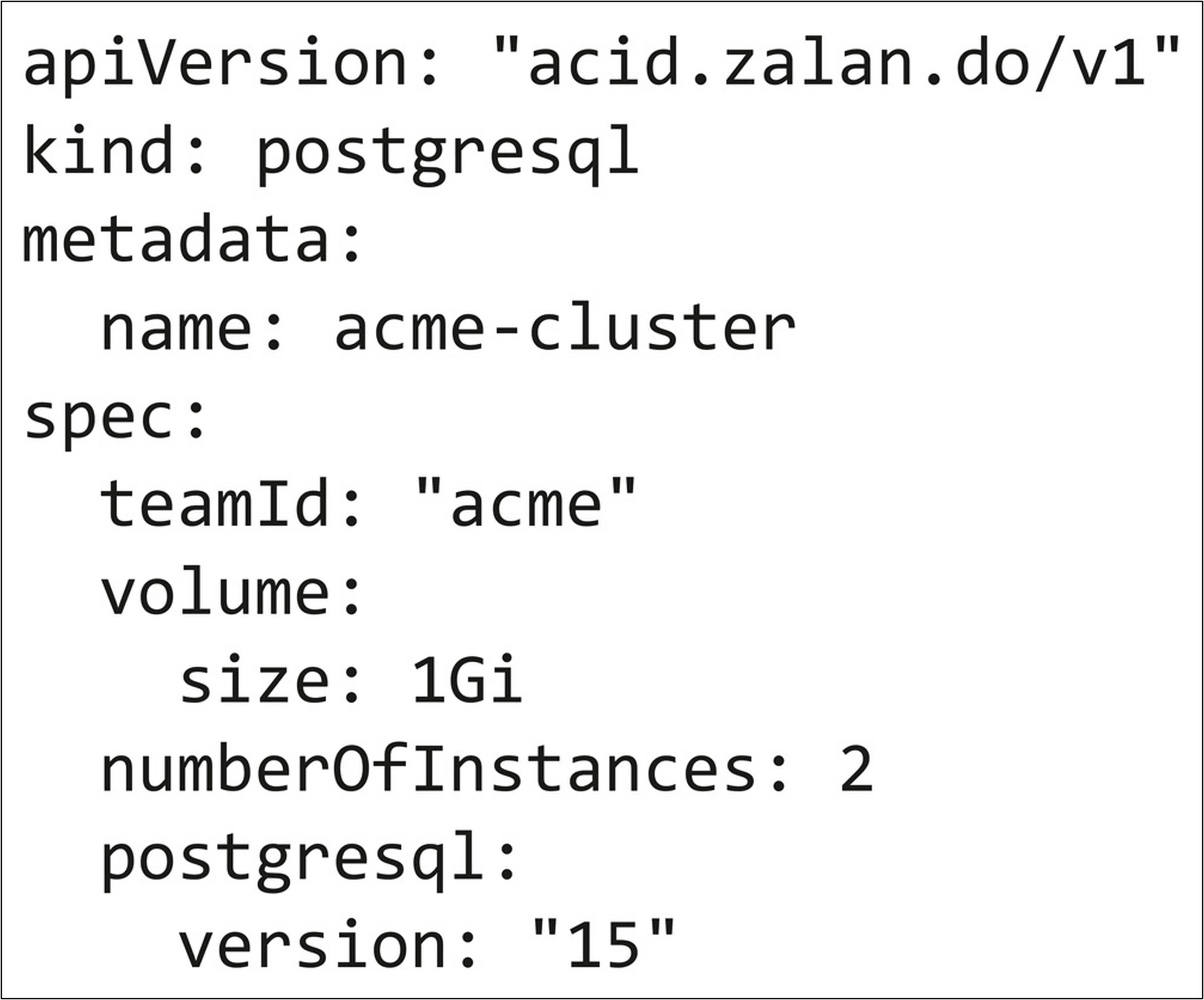
Listing 1: Ausschnitt einer Custom Resource, die einen PostgresSQL-Cluster beschreibt
Alles in Kubernetes?
Ein einheitliches Vorgehen mit Kubernetes bringt die Orchestrierung von Anwendungen und Infrastruktur deutlich näher zusammen. So können Technologiebrüche vermieden werden, indem etwa im Bereich Infrastruktur zu großen Teilen auf Tools wie Terraform, Pulumi und Co. verzichtet werden kann. Gleichzeitig können gängige Kubernetes-Werkzeuge, wie etwa kubectl, sowohl für Anwendungen als auch Infrastruktur verwendet werden.
Die Autonomie von Teams wird erhöht, da Kubernetes-Manifeste als universelle Sprache verwendet werden können und sich Infrastruktur somit gewissermaßen als Self-Service anbieten lässt. Ein mögliches Plattform-Team kann indessen relativ einfach Cloud-ähnliche, aber auf das Unternehmen zugeschnittene APIs in Form von Kubernetes-Ressourcen offerieren, ohne dabei notwendigerweise auf echte Cloud-Services zurückzugreifen; so lässt sich gewissermaßen eine eigene Cloud aufbauen.
Natürlich kommt der Betrieb von Infrastruktur im Kubernetes-Cluster auch mit gewissen Herausforderungen daher. Da Kubernetes-Manifeste deklarativ an den Cluster übergeben werden und dabei ein gewisser zeitlicher Verzug entsteht, gibt es kein direktes Feedback bei Änderungen. Gerade im Bereich Infrastruktur kann dies problematisch sein, insbesondere wenn zuvor auf Tools wie Terraform, Pulumi usw. gesetzt wurde. Ein gutes Monitoring (inklusive Alerting) ist daher absolut notwendig, um weiterhin schnell Infrastrukturprobleme zu erkennen und zu beheben.
Nur weil Teams bereits mit Kubernetes-Manifesten arbeiten, heißt dies jedoch nicht, dass diese uneingeschränkte Kontrolle über die Infrastruktur haben sollten. In einer Welt, in der die Infrastruktur nicht im Cluster lebt, ergibt sich oft eine natürliche Trennung der Verantwortlichkeiten. Im Cluster hingegen gilt es, eine gute Rechteverwaltung zu implementieren, die zwar Teams genug Freiheiten gibt, aber gleichzeitig verhindert, dass unternehmenskritische Infrastruktur aus Versehen gelöscht werden kann. Auch der Bedarf für ein Operationsteam fällt mit dem Einsatz von Kubernetes und Operatoren natürlich nicht weg. Neben dem Betrieb des eigentlichen Clusters bringen auch die meisten Kubernetes-Operatoren eine Menge Komplexität mit. Damit den Teams zuverlässige Infrastruktur angeboten werden kann, bedarf es also immer noch Experten, die nicht nur den Operator richtig konfigurieren, sondern auch bei etwaigen Problemen schnell zu den richtigen Lösungen kommen. In vielen Fällen wird diese Aufgabe vom sogenannten Plattform-Team übernommen, das nicht nur dafür sorgt, dass die Infrastruktur läuft, sondern auch entscheidet, in welcher Form Infrastruktur als Service für Teams angeboten wird.
Was ist mit Cloud-Ressourcen?
Kubernetes ist auch in der Cloud eine sinnvolle Wahl. Mit dem Gang in die Cloud ist oft der Wille nach weniger Verantwortung bezüglich des Betriebs verbunden. Managed Infrastructure, wie etwa Datenbanken, sind daher eine nahe liegende Wahl. Naturgemäß leben Cloud-Ressourcen aber außerhalb des Kubernetes-Clusters. Ein einheitliches Vorgehen für die Bereitstellung der Anwendung und benötigten Infrastruktur ist daher erst mal nicht möglich. Um dies dennoch zu ermöglichen, liegt es nahe, für jede externe Cloud-Ressource eine korrespondierende Kubernetes-Ressource im Cluster zu definieren. Tatsächlich gibt es in Kubernetes sogar die Möglichkeit, genau dies mit der eingebauten Service-Ressource speziell für Cloud-Load-Balancer zu tun. Wird eine Kubernetes-Manifest für ein Service angelegt und der Typ „LoadBalancer“ angegeben, wird im Hintergrund, abhängig vom Cloud-Provider, in dem sich der Cluster befindet, ein entsprechender Managed Load-Balancer angelegt. Bei Amazon Web Services könnte so etwa ein ALB (Amazon Elastic Load Balancing Application Load Balancer) aus Kubernetes heraus erstellt werden.
Für andere Cloud-Ressourcen, wie etwa Datenbanken, haben sich inzwischen Projekte wie Crossplane [CP] etabliert. Diese stellen Kubernetes-Operatoren bereit, die für viele Cloud-Ressourcen ein Pendant als Custom Resource bereitstellen. Wird so eine Custom Resource im Cluster erstellt, wird auch automatisch die korrespondierende Ressource in der Cloud angelegt. Veränderungen in Kubernetes führen ebenso zu Veränderung an der Cloud-Ressource. Genauso wie es auch bei Infrastrukturkomponenten, die im Cluster leben, zu erwarten wäre.
Das Monitoring muss sich hier möglicherweise sowohl auf den Kubernetes-Cluster als auch auf alle externen Ressourcen beziehen. Ein Nachteil gegenüber der eigenen Infrastruktur im Cluster. Auf der anderen Seite werden viele Aspekte (Backups, Replikation, Ausfallsicherheit usw.) vom jeweiligen Cloud-Provider übernommen, die ansonsten im Kubernetes-Operator umgesetzt werden oder gar händisch erfolgen müssen.
Fazit
Abschließend lässt sich sagen, dass Infrastrukturkomponenten im Kubernetes-Cluster keine Seltenheit mehr sind. Die einheitliche Plattform mit ihren zahlreichen Werkzeugen bietet viele Mehrwerte. Die Grenze zwischen Anwendungen und Infrastruktur verschwimmt zunehmend durch Kubernetes-Manifeste als universelle Sprache. Ob das gut oder schlecht ist, lässt sich nur schwer objektiv beurteilen. Ich persönlich bin begeistert, wie einfach es ist, mithilfe von Operatoren auch komplexe Infrastruktur auf deklarative Weise zu beschwören. Genauso sehr fürchte ich mich jedoch davor, dass ein Operator mal nicht das tut, was er soll. Die Erfahrung zeigt, dass Probleme in Kubernetes nicht immer trivial zu analysieren sind und durchaus fundiertes Wissen benötigen.








