

Seit Data Lakes beim Lösen von analytischen Aufgabenstellungen an Bedeutung gewonnen haben, hat auch die Bedeutung von offenen Dateiformaten zugenommen. Offene Dateiformate erlauben es verschiedenen Werkzeugen, auf die gleichen Daten zuzugreifen, ohne die Daten vorher transformieren zu müssen. Neben dem schon lange genutzten textbasierten Dateiformat CSV wurden neue Formate wie beispielsweise Parquet, ORC und Avro entwickelt. Diese standardisieren nicht nur ein Format, sondern ermöglichen eine optimierte Speicherung der Daten für verschiedene Anwendungsfälle. Auch Datenbanksysteme mit proprietären eigenen Formaten bieten nun häufig die Möglichkeit, Daten in diesen offenen Formaten zu lesen und zu schreiben. Diese offenen Dateiformate werden für Daten benutzt, die sowohl auf dem Hadoop File System (dem traditionellen Dateisystem von Data Lakes) liegen können als auch auf Object-Storage- oder POSIX-Dateisystemen.
Beim Gebrauch dieser offenen Dateiformate hat sich herausgestellt, dass verschiedene Probleme im Vergleich zu den traditionell in Data-Warehousing-Systemen genutzten Formaten bestehen. Die in den letzten Jahren aufgekommenen Data Lakehouses versuchen diese Probleme durch offene Tabellenformate zu adressieren. Beispiele für diese offenen Tabellenformate sind Iceberg, Delta Lake und Hudi.
In diesem Artikel werden die drei recht weit verbreiteten Tabellenformate näher vorgestellt und mit ihren Gemeinsamkeiten und Unterschieden einander gegenübergestellt. Weiterhin wird untersucht, welche neuen Möglichkeiten sich durch diese offenen Tabellenformate im Vergleich zu reinen Dateiformaten ergeben. Anhand von Beispielen wird aufgezeigt, wie sich deutliche Vorteile durch die Anwendung dieser offenen Tabellenformate ergeben.
Offene Dateiformate
Datenbanksysteme verwendeten meist proprietäre Formate zur Speicherung der Daten. Nur die passende Datenbank-Engine konnte diese Daten lesen und schreiben. Externe Dateiformate dienten dem Austausch der Daten zwischen Systemen. Die Dateiformate CSV (Comma Separated Values) oder FWF (Fixed Width File) waren und sind die gängigsten Austauschformate. Mit der Entwicklung von Hadoop und der damit einhergehenden Flexibilisierung der Datennutzung wurde deutlich, dass diese Formate für die neuen Anforderungen nicht hinreichend sind. Wesentliche Probleme waren die fehlende Unterstützung für Datentypen, der Platzbedarf und die Effizienz bei der Verarbeitung.
Dies führte zu einer Entwicklung von neuen offenen Dateiformaten, die diese Probleme adressieren und für viele Tools verwendbar sind. Das Dateiformat (Apache) Avro [AVR23; Whi15] entstand 2009 im Kontext von Hadoop und erlaubt die Serialisierung von Daten. Die Daten werden in einem festen Schema binär gespeichert. Die Daten werden zeilenweise abgelegt und können komprimiert werden. Avro erlaubt Schema-Änderungen und unterstützt Vorwärts- sowie Rückwärts-Kompatibilität. Das heißt, ein Leser kann mit einem neuen Schema auch Daten lesen, die mit einem alten Schema geschrieben wurden (Rückwärts-Kompatibilität), und ein Leser kann Daten mit einem alten Schema lesen, die mit einem neuen Schema geschrieben wurden (Vorwärts-Kompatibilität). Leser und Schreiber von Avro-Daten können also auf einem unterschiedlichen Stand sein.
Avro-Daten können sehr effizient gelesen und geschrieben werden, haben aber durch die zeilenweise Speicherung Nachteile, wenn nur wenige Spalten für eine Analyse benötigt werden. Dies führte zu zwei weiteren Dateiformaten, die die Daten spaltenweise ablegen: Parquet und ORC. Diese unterstützen beide I/O-Optimierungen durch eingebettete Indexinformationen, die während des Lesen ausgenutzt werden können. Schema-Evolution und Komprimierung werden, wie bei Avro, ebenfalls unterstützt.
Welches Dateiformat am besten geeignet ist, hängt sehr von den Daten und der Nutzung ab. Generell wird daher empfohlen, die Dateiformate mit ihren Konfigurationsmöglichkeiten (zum Beispiel Art der Komprimierung) mit dem eigenen Anwendungsszenario zu verproben.
Da für die offenen Dateiformate eine große Zahl von Bibliotheken für unterschiedlichste Anwendungen bereitstehen (unter anderem für Python, Spark und Java) und diese auch von vielen Werkzeugen unterstützt werden, ist deren Einsatz weit verbreitet. Für jeden Anwendungszweck kann somit das am besten geeignete Werkzeug ausgewählt werden, ohne Daten erneut kopieren zu müssen. Ein typisches Beispiel ist die Verwendung von unterschiedlichen Werkzeugen für die Transformation und Analyse von Daten.
Bei Analysen sind häufig Tabellen im Fokus, daher werden Operationen auf Tabellenebene benötigt. Dies kann durch die Dateiformate nicht gelöst werden, da sich diese nur auf eine einzelne Datei beschränken. Tabellen müssen aus unterschiedlichsten Gründen auf mehrere Dateien aufgeteilt werden (zum Beispiel zwecks Partitionierung). So ist es häufig die Aufgabe des Data Engineering, die Tabellen aus Dateien zu bilden. Dies wird durch die offenen Tabellenformate deutlich vereinfacht.
Grundlagen offener Tabellenformate
Die offenen Dateiformate haben aber einen gravierenden Nachteil: Sie wurden geschaffen und hauptsächlich eingesetzt auf Storage, der das Ändern von Dateien nicht unterstützt (HDFS, Object Storage). Das heißt, dass Dateien, wenn sie einmal angelegt sind, zwar vergrößert und gelöscht, aber nur durch Anhängen zusätzlicher Daten modifiziert werden können. Da Daten sich aber typischerweise ändern, müssen die Änderungen über eigene Dateien oder neu zu schreibende Dateien realisiert werden. Dies führt zu einer Unzahl an Dateien, die zu einer Tabelle gehören. Die verwendeten Storage-Systeme haben typischerweise ein Problem, wenn auf sehr viele sehr kleine Dateien zugegriffen werden muss.
Dies adressieren nun die hier besprochenen offenen Tabellenformate. Sie definieren Metadaten, die den effizienten Zugriff auf die zu einer Tabelle gehörenden Dateien – auch wenn dies sehr viele sind – ermöglichen. Neben diesem Grundanliegen der offenen Tabellenformate bieten sie aber häufig noch die Möglichkeit, Änderungen in einer bestehenden Tabelle durchzuführen, auf ältere Versionen einer Tabelle zuzugreifen und Eigenschaften von Transaktionen wie Atomicity und Durability zu unterstützen. Auch wird die Weiterentwicklung der Tabellenschemata im Lauf der Zeit unterstützt.
Außerdem ermöglichen die offenen Tabellenformate Funktionalitäten, die man bisher in der Datenbankenwelt der Data Warehouses, aber nicht in der Heimat der offenen Dateiformate bei Data Lakes gefunden hat, wie die Möglichkeit, Partitionen, die für die Ergebnisberechnung nicht benötigt werden, bei Abfragen zu überspringen, ohne die Partitionierungsspalte explizit referenzieren zu müssen.
Im Folgenden werden wir die drei aktuell am meisten verbreiteten offenen Tabellenformate näher betrachten: Iceberg, Delta Lake und Hudi. Es gibt Ansätze, mehrere Formate gleichzeitig zu unterstützen: So leistet Presto die Unterstützung für alle drei Formate und Delta Lake 3.0 macht eine Umsetzung in die beiden anderen Formate zukünftig verfügbar [Dat23].
Iceberg
Das Tabellenformat Iceberg [ICE23; Shi24; Gop22] wurde von Netflix entwickelt und 2018 als Open Source veröffentlicht. Inzwischen wird dieses offene Tabellenformat von vielen Werkzeugen unterstützt. Iceberg nutzt mehrstufige Metadaten. Abbildung 1 zeigt den Aufbau von Iceberg.
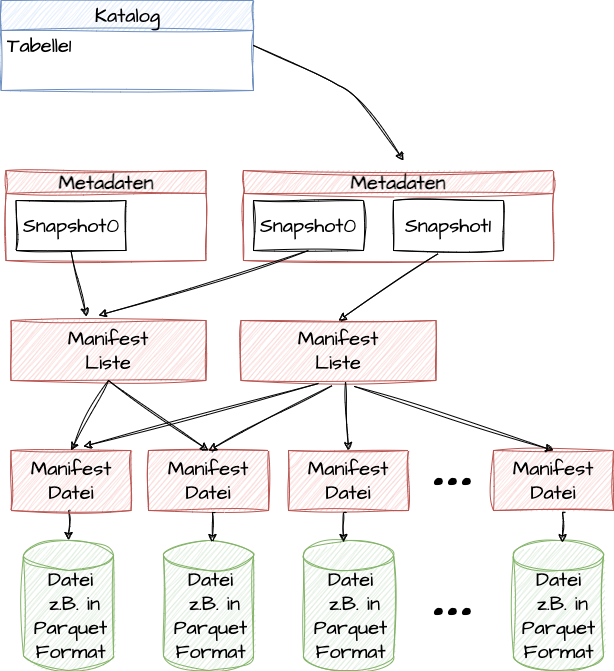
Abb. 1: Iceberg-Metadatenstruktur
Zu jeder eigentlichen Datendatei, die in einem offenen Dateiformat wie Parquet gespeichert sein kann, gibt es eine sogenannte Manifest-Datei, die Metadaten zur eigentlichen Datei enthält. So werden in dieser Datei zum Beispiel die größten und die kleinsten Werte, die für die einzelnen Spalten in der entsprechenden Daten-Datei auftreten können, gespeichert. Diese Information kann genutzt werden, um bei einer Abfrage ganze Dateien ausschließen zu können, da sie keine relevanten Werte enthalten können. Die schnellste Art, eine Datei zu lesen, ist schließlich, sie nicht zu lesen. Welche Dateien zu einem bestimmten Zeitpunkt (Snapshot) zu einer Tabelle gehören, findet man in den Manifest-Listen-Dateien. Durch diese Manifest-Listen vermeidet man Probleme, die man sonst bei HDFS oder Object Storage mit einer großen Anzahl an zu einer Tabelle gehörenden Dateien hat.
Ältere Snapshots erlauben es, frühere Zustände einer Tabelle abzufragen. Ein Katalog oder Dictionary wie der Hive-Metadatenkatalog hat dann für jede Tabelle einen Eintrag auf die Metadaten mit den aktuell gültigen Snapshots.
Delta Lake
Das Tabellenformat Delta Lake [DEL23; KuZ21; Gop22] wurde ursprünglich von Databricks für Spark entwickelt, wird aber zumindest lesend inzwischen von weiteren Produkten unterstützt [HaD23]. In Abbildung 2 ist der Aufbau einer Delta-Lake-Tabelle zu sehen.
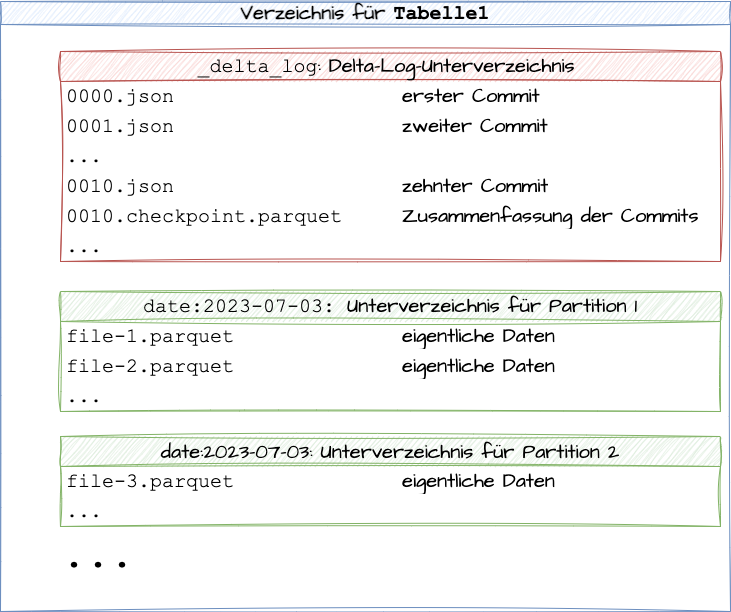
Abb. 2: Aufbau einer Delta-Lake-Tabelle
Alle zu einer Tabelle gehörigen Daten und Metadaten werden im Delta-Lake-Format in einem Verzeichnis und seinen Unterverzeichnissen gespeichert. Die eigentlichen Datenobjekte werden als Parquet Files abgelegt. Soll eine Tabelle partitioniert werden, werden die zu einer Partition gehörigen Dateien in einem Unterverzeichnis abgelegt, wie die Abbildung zeigt.
Die wichtigste Struktur von Delta Lake ist das Delta-Log, das in einem eigenen Unterverzeichnis liegt. Für jeden Commit von Dateien wird eine eigene durchnummerierte JSON-Datei in diesem Unterverzeichnis abgelegt, die Daten und Metadaten enthält. Für den effizienten Lesezugriff werden in gewissen Abständen Log-Checkpoints geschrieben, die mehrere dieser JSON-Dateien zusammenfassen und damit die Änderungen bis zu einem bestimmten Zeitpunkt enthalten.
Hudi
Hudi [HUD21; Gop22] wurde ursprünglich von Uber entwickelt und ist jetzt als Open Source verfügbar. Die Ziele beim Entwurf von Hudi waren die effiziente Unterstützung von Upserts, die Möglichkeit, einfach und schnell zu erkennen, welche Daten sich seit einem gewissen Zeitpunkt geändert haben, und der Wunsch, sehr aktuelle Daten (in Bezug zu ihrem Entstehungszeitpunkt) zur Verfügung zu stellen. Wie die anderen Tabellenformate möchte Hudi auch unterstützen, dass ein Schema für eine Tabelle erzwungen oder zumindest überprüft werden kann und dass sich das Schema im Lauf der Zeit auch weiterentwickeln kann (etwa wenn in einer Tabelle neue Spalten hinzukommen). Auch wird eine Transaktionssemantik, wie man sie von relationalen Datenbanken kennt (ACID-Eigenschaften), zumindest für einzelne Tabellen angestrebt.
Hudi bietet zwei Arten von Tabellen, um unterschiedliche Workloads gut unterstützen zu können:
- Copy-on-Write
- Merge-on-Read
Bei Copy-on-Write wird bei Änderungen eine komplette neue Datei geschrieben, die die alten Daten und die neuen Daten enthält. Dies ist optimal für Tabellen, die sich wenig ändern im Verhältnis zu den Lesezugriffen, da dann der Lesezugriff einfach und effizient ist. Bei Merge-on-Read werden dagegen Änderungen in eigenen Dateien abgelegt und diese Änderungen erst beim Lesen mit dem bisherigen Datenbestand zusammengeführt. Diese Vorgehensweise ist deshalb besser für Tabellen geeignet, die viele Schreibzugriffe im Vergleich zu den Lesezugriffen haben, da Schreibzugriffe verhältnismäßig günstig, Lesezugriffe aber teuer sind.
In Abbildung 3 ist der Aufbau der Strukturen von Hudi für eine Tabelle zu sehen. Man hat wie bei Delta Lake Unterverzeichnisse für die verschiedenen Partitionen einer Tabelle. Für jede Partition kann es mehrere sogenannte File Groups geben, die jeweils eine File-Id haben. Wenn festgelegte Größen überschritten werden, werden neue File Groups in einer Partition angelegt. Innerhalb der File Groups gibt es nun sogenannte File Slices, die aus einer Basisdatei im spaltenorientierten Parquet-Format und Logfiles bestehen, die die nachfolgenden Änderungen enthalten.
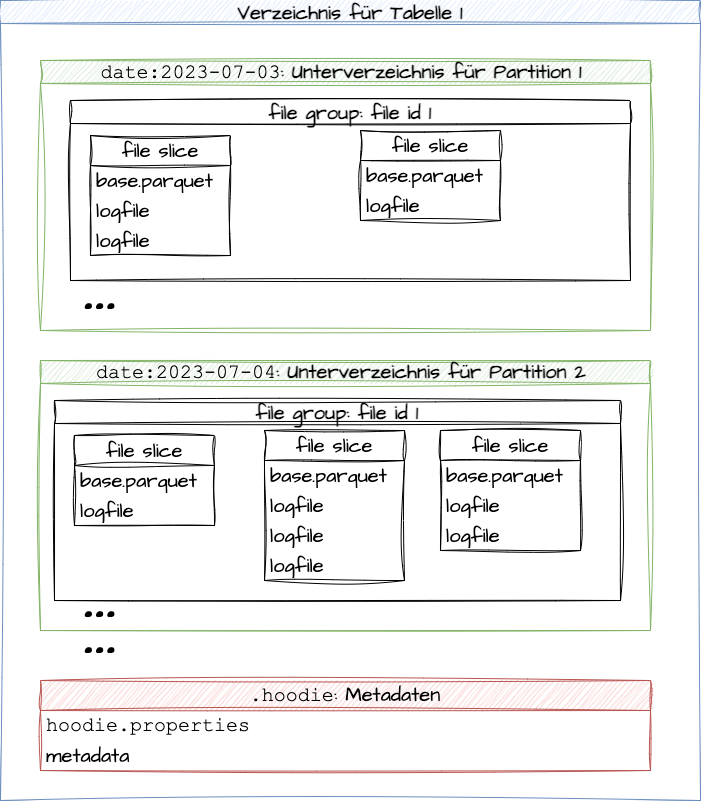
Abb . 3: Hudi-Verzeichnisstruktur
Neben den Unterverzeichnissen für die Partitionen hat eine Tabelle auch ein Unterverzeichnis mit Namen .hoodie, das Metadaten enthält.
Hudi kennt drei Arten von Leseoperationen:
- Snapshot-Abfragen: Damit wird der Zustand der Tabelle zu einem bestimmten Zeitpunkt (dem Snapshot) abgefragt.
- Delta-Abfragen: Diese dienen dazu zu ermitteln, welche Daten in einer Tabelle sich in einem bestimmten Zeitintervall geändert haben. Dies ist insbesondere für Streaming-Anwendungen nützlich.
- Leseoptimierte Abfragen: Diese sind nur für Merge-on-Read-Tabellen relevant. Für eine bessere Performance werden nur die schon verdichteten Daten gelesen, nicht aber die Änderungen aus den darauffolgenden neueren Logfiles.
Kostenreduktion durch offene Tabellenformate
Durch die offenen Tabellenformate wird die Trennung von Compute, Storage und insbesondere Technologie bei der Analyse strukturierter Daten auf effektive Art möglich. Gleichzeitig unterstützen sie Möglichkeiten, die man aus der Data-Warehousing-Welt kennt, wie die Atomarität von Operationen, um auch bei gleichzeitigem Zugriff von verschiedenen Werkzeugen inkonsistente Daten zu vermeiden, oder die für eine Abfrage transparente Elimination von Partitionen oder Dateien. Daraus ergibt sich ein Potenzial zur Kostenreduktion in mehreren Bereichen:
- Durch diese Trennung von Compute und Storage ist es möglich, bei Bedarf den Datenspeicher zu erweitern, ohne auf der Compute-Seite etwas zu ändern. Umgekehrt kann, wenn der Workload steigt und die Datenmenge sich nicht vergrößert, die Anzahl der Rechenressourcen erhöht werden, ohne dass der Storage vergrößert werden muss.
- Durch die Eigenschaften der offenen Tabellenformate kann der in der Regel günstige Object Storage verwendet werden.
- Die Trennung der Technologie von Compute und Storage ermöglicht die Verwendung optimierter Werkzeuge für unterschiedliche Workloads.
- Offene Tabellenformate bilden die zentrale Komponente der Data-Lakehouse-Architektur [HaD23], da sie deren Ziel, die Vorteile von Data Warehouses und Data Lakes zu vereinen und gleichzeitig deren Nachteile zu vermeiden, unterstützen.
- Die verschiedenen Werkzeuge und Daten in einem Data Lakehouse werden durch die offenen Tabellenformate integriert. Dadurch wird es möglich, einem Werkzeug, das gerade nicht benötigt wird, zeitweilig keine Rechenressourcen zuzuordnen und sie ihm nach einer gewissen Zeit, wenn das Werkzeug wieder benötigt wird, wieder zu geben. Dadurch ist insbesondere in einer Cloud-Umgebung eine Kostenersparnis zu erzielen.
- Daten, die nicht häufig abgefragt werden (kalte Daten), können aus einem bestehenden Data Warehouse in offenen Tabellenformaten ausgelagert werden. Durch den Zugriff über ein Data Lakehouse oder erweiterte Fähigkeiten des Data Warehouse lassen sich diese Daten (integriert) abfragen.
Vergleich der offenen Tabellenformate
Alle vorgestellten offenen Tabellenformate bieten Möglichkeiten an, Transaktionen abzubilden, über Snapshots ältere Versionen der Daten abzufragen und das Schema einer Tabelle zu verändern. Sie eignen sich daher alle für die Realisierung der oben herausgestellten Vorteile. Der Unterschied zwischen den Formaten liegt im Detail:
- Hudi und Delta Lake unterstützen nur das offene Dateiformat Parquet. Iceberg ermöglicht auch die Verwendung von ORC oder Avro, was je nach Anwendungsfall Vorteile bringen kann.
- Hudi, Delta Lake und Iceberg implementieren die Koordination von mehreren Lese- oder Schreiboperationen auf eine Tabelle auf unterschiedliche Weise. Optimistische Methoden der Synchronisation erlauben die gleichzeitige Ausführung mehrerer Schreiboperationen. Dies kann zu einer höheren Leistung beim Schreiben führen, birgt aber das Risiko von Inkonsistenzen oder Abbrüchen.
- Die Pflege der Dateien, die eine Tabelle ausmachen, ist unterschiedlich gelöst. Hudi und Iceberg unterstützen beide Verfahren, Merge-on-Read und Copy-on-Write. Delta Lake unterstützt nur Copy-on-Write. Hudi und Delta Lake können eine Datenverdichtung automatisch durchführen. Bei Iceberg muss dies manuell getriggert werden.
Alle offenen Tabellenformate sind eine gute Grundlage für kosteneffiziente und flexible Analysen. Sie werden ständig weiterentwickelt, und neue Funktionen des einen Formats werden in ähnlicher Weise auch in den anderen Formaten implementiert. Es erscheint daher sinnvoll, nach der breitesten Unterstützung für ein Format zu schauen, um sicherzustellen, dass die benötigten Werkzeuge verwendet werden können.
Weitere Informationen
[AVR23] Apache Avro: Apache Avro – a data serialization system. 2022,
https://avro.apache.org/, abgerufen am 9.9.2023
[Dat23] Databricks: Announcing Delta Lake 3.0 with New Universal Format and Liquid Clustering. 29.6.2023,
https://www.databricks.com/blog/announcing-delta-lake-30-new-universal-format-and-liquid-clustering, abgerufen am 9.9.2023
[DEL23] Delta Lake: Documentation.
https://docs.delta.io/latest/index.html, abgerufen am 9.9.2023
[Gop22] Gopalan, R.: The Cloud Data Lake. O’Reilly 2022
[HaD23] Haelen, B. / Davis, D.: Delta Lake: Up and Running: Modern Data Lakehouse Architectures With Delta Lake. O’Reilly 2023, Early Release bereits verfügbar
[HUD21] Apache Hudi: Overview. 2021,
https://hudi.apache.org/docs/overview, abgerufen am 9.9.2023
[ICE23] Apache Iceberg: Documentation.
https://iceberg.apache.org/docs/latest/, abgerufen am 9.9.2023
[KuZ21] Kukreja, M. / Zburivsky, D.: Data Engineering with Apache Spark, Delta Lake, and Lakehouse. Packt Publishing 2021
[Shi24] Shiran, T. et al.: Apache Iceberg: The Definitive Guide. O’Reilly, Februar 2024, Early Release bereits verfügbar
[Whi15] White, T.: Hadoop: The Definitive Guide. 4. Auflage, O’Reilly 2015









