

Ausgangspunkt ist der Wunsch des Kunden, eine bisherige monolithische Applikation „in die Cloud“ zu bringen. Die Gründe, warum Kunden so etwas tun wollen, sind vielfältig:
- Ablösung einer abgekündigten Laufzeitumgebung,
- Erhöhung der Flexibilität bei der Feature-Entwicklung durch kleinere Komponenten,
- Verbesserung der Skalierung der Anwendung im Betrieb (Operating),
- Erfüllung einer Vorgabe des Unternehmens im Rahmen der IT-Strategie,
- …
In welcher softwaretechnischen Form die Applikation dann „in der Cloud“ vorliegen soll, ist meist nicht exakt vorgegeben. Man hat dabei grundsätzlich die Wahl zwischen einer nur Cloud-nativen Anwendung und einer echten serviceorientierten Architektur mit Microservices, wobei letztere Form ein stärkeres Refactoring erfordert.
Begriffsdefinition: Cloud-native versus Microservices
Ein Microservice wird häufig als Cloud-native Anwendung erstellt. Aber nicht alle Cloud-nativen Anwendungen sind notwendigerweise Microservices. Eine ausgereifte Cloud-native Anwendung sollte sich an die Prinzipien der „Twelve-Factor App“ (vgl. [TFA]) halten, und sie ist nicht abhängig von einem bestimmten Container-Format. In einer solchen Anwendung sind alle Unterstützungsdienste („Backing-Services“) von der eigentlichen Anwendung entkoppelt und werden erst zur Laufzeit dazugebunden. Außerdem sollte eine Cloud-native Anwendung leichtgewichtig sein, das heißt, eine kurze Start- und Ausschaltzeit haben. Aufgrund dieser Eigenschaften kann eine Cloud-native Anwendung von einer Cloud-basierten Containerplattform profitieren, und zwar durch die Fähigkeit der Skalierbarkeit und Deploybarkeit unabhängig von anderen Anwendungen.
Ein Microservice weist eine gewisse systemimmanente Komplexität auf. Nicht jede Anwendung ist dazu geeignet, in einen Microservice verwandelt zu werden. Per Definition sollte ein Microservice nichts mit anderen Anwendungen teilen, auch keine Datenbank oder Bibliotheken. Der Übergang von einer monolithischen Anwendung direkt in ein Microservice-Modell ist ein mit hohem Risiko und hohem Aufwand verbundenes Unterfangen. In vielen Fällen besteht daher der ideale Transformationspfad für eine monolithische Anwendung darin, sie zunächst in kleinere Cloud-native Anwendungen zu unterteilen und später, falls passend, in Microservices. Abbildung 1 zeigt diesen Pfad.
Abb. 1: Transformationspfad in zwei Stufen
Das Transformationsrezept
Das Aufbrechen einer monolithischen Anwendung ist keine triviale Übung. Die meisten Teammitglieder empfinden es möglicherweise als entmutigend. Nachdem wir mehrere Applikationstransformationsprojekte durchgeführt und am Anfang auch einige Irrwege eingeschlagen hatten, insbesondere was den korrekten Domänenschnitt und seine zeitliche Ansiedelung innerhalb des Transformationsprozesses anbetrifft, hat sich inzwischen ein wiederholbares Vorgehensmodell für solche Transformationen herauskristallisiert, das das Risiko begrenzt. Dabei wird in iterativen Stufen vorgegangen, wobei alle Stufen parallel ausgeführt werden können und sollen, mit Ausnahme von Stufe 1. Die Stufen sind wie folgt:
- Stufe 1: Den Monolithen außerhalb des aktuellen Containers zum Laufen zu bringen.
- Stufe 2: Den Monolithen in der Cloud zum Laufen zu bringen.
- Stufe 3: Aufteilen des Monolithen in kleinere Anwendungen oder Microservices.
- Stufe 4: Virtualisierung („Lift and Shift“) interner gehosteter Dienste.
Die Transformation – eine Reise
Lassen Sie uns eine hypothetische Transformationsreise mit einer Anwendung durchlaufen, die auf verschiedenen realen Projekten basiert. Die Ausgangssituation: Die anfängliche, monolithische Anwendung besteht aus einer öffentlich erreichbaren, Java-basierten Webanwendung. Dieser Monolith stellt mehrere REST- und SOAP-basierte APIs zur Verfügung. Die primäre Datenbank unserer Anwendung ist eine Microsoft SQL Server-Datenbank. Für die Nachrichtenwarteschlange (das „message queuing“) wird Apache ActiveMQ verwendet.
Das Ziel dieser hypothetischen Transformation ist es, den Monolithen in kleinere Cloud-native Anwendungen zu zerlegen und diese dann auf einer Plattform, die auf der Cloud Foundry-Technologie basiert, zu deployen. Die Plattform selbst wird auf einer beliebigen Cloud, wie Amazon Web Services (AWS), Google Cloud Platform (GCP) oder Microsoft Azure, gehostet.
Stufe 1: Den Monolithen außerhalb des aktuellen Containers zum Laufen zu bringen
Diese Stufe erfolgt in mehreren Phasen, die helfen, die Prinzipien der „Twelve-Factor App“ (vgl. [TFA]) zu erfüllen.
Codebasis (Faktor I)
Die erste Phase besteht darin, die Codebasis in das gewünschte Quellcodeverwaltungs-Repository zu migrieren. Ein neuer Branch muss für die Cloud-Transformationsbemühungen erstellt werden. In den meisten Fällen kann die laufende Entwicklung nicht gestoppt werden, und somit wird eine Strategie für die Codesynchronisation benötigt.
Es ist hilfreich, wenn für den Original-Code und den transformierten Code dasselbe Versionsverwaltungssystem verwendet wird (z. B. GIT zu GIT). Dies ist jedoch nicht immer möglich. Es kann vorkommen, dass der aktuelle Quellcode in einem SVN (Subversion) verwaltet wird und das gewünschte Zielquellensystem möglicherweise GIT ist. In diesem Fall gibt es „Brücken“ wie gitsvn, die beim Zusammenführen des Codes helfen können.
Abhängigkeiten (Faktor II)
Abhängigkeiten von Ihrem Code sollten über einen internen Artefakt-Repository-Manager verfügbar sein, zum Beispiel in einem Nexus oder Artifactory. Im Rahmen dieser Aktivitäten müssen Sie möglicherweise alle Abhängigkeiten über Ihren unternehmensweiten Artefakt-Repository-Manager zur Verfügung stellen.
Sie müssen auch Abhängigkeiten von Ihrem Code auslagern, falls dies noch nicht geschehen ist. In Java-Anwendungen kann dies mithilfe von Gradle-Build-Dateien oder Maven POM (Project Object Model)-Dateien erreicht werden. Gradle ermöglicht es, vorhandene Maven POM-Dateien sehr einfach in Gradle-Build-Dateien zu konvertieren. Gradle und Maven verfügen über gleichwertige Fähigkeiten. Gradle wird häufig bevorzugt, da es ein kompakteres Format (Groovy-basiert) als Maven (XML-basiert) verwendet.
Vom aktuellen Container entkoppeln
Ein großer Schritt in dieser Phase besteht darin, die monolithische Anwendung außerhalb des aktuellen Containers zum Laufen zu bringen. In diesem Beispiel wird die Anwendung mit Apache Tomcat gehostet, wodurch sich das Entkoppeln vom bisherigen Container relativ einfach gestaltet. Spring Boot wurde eingeführt und Apache Tomcat als Abhängigkeit hinterlegt. Außerdem musste die Konfiguration aus der web.xml-Datei der Anwendung (z. B. URL-Mappings) in entsprechende Spring-Annotationen umgewandelt werden.
In anderen Projekten kann ein Monolith auf WebSphere- oder WebLogic-Anwendungsservern gehostet sein. Ein kompletter Java EE-Applikationsserver bietet mehr Containerdienste, manchmal auch proprietäre, was die Arbeit erschwert, die Anwendung von einem solchen Container zu lösen. Im Fall von IBM existieren auch Tools, die vorhandene Anwendungen analysieren und eine Liste der erforderlichen Änderungen bereitstellen (vgl. [WAMT]). Das WebSphere Liberty-Profil ist ein guter Übergangspfad zur Cloud, da es in den meisten Cloud-Containern läuft, einschließlich auf denen der Pivotal Platform und von Red Hat OpenShift.
Zur statischen Codeanalyse werden üblicherweise weitere Tools eingesetzt, wie etwa das Migration Toolkit von Red Hat (vgl. [RHMT]) oder eigene Analysetools, welche für spezielle Kundenframeworks, die im Enterprise-Umfeld häufig anzutreffen sind, schnell angepasst werden können.
Mögliche Schwierigkeiten können entstehen, wenn Softwarekomponenten eingesetzt werden, die eine starke Abhängigkeit zur bisherigen Laufzeitumgebung beinhalten. In einem solchen Fall kann man entweder den Applikationscode entsprechend abändern oder eine Ersatzkomponente erstellen, die der Applikation die bisherigen Schnittstellen bietet, sich aber intern an der neuen Laufzeitumgebung orientiert.
Konfiguration externalisieren (Faktor III)
In der Phase „Konfiguration externalisieren“ werden Eigenschaftswerte, die bisher in der Datei „web.xml“ gespeichert wurden, in sogenannte YAML-Dateien (Yet another Markup Language) umgezogen. Es sind häufig Codeänderungen erforderlich, damit die bisherigen Klassen mit der Spring-Injected Konfiguration (lesen aus YAML-Dateien) funktionieren.
Stufe 1 abgeschlossen
Am Ende von Stufe 1 sollte eine monolithische Spring Boot-Anwendung lokal ausgeführt werden. Die Anwendung könnte in einen Cloud-Container installiert werden und teilweise funktionsfähig sein, solange die meisten Backing-Services (z. B. Datenbank) von der Cloud-Plattform aus erreichbar sind (s. Abb. 2).
Das Flussdiagramm in Abbildung 3 zeigt einen typischen Zeitrahmen für diese Phase (1 bis 2 Monate).
Abb. 2: Transformation nach Stufe 1
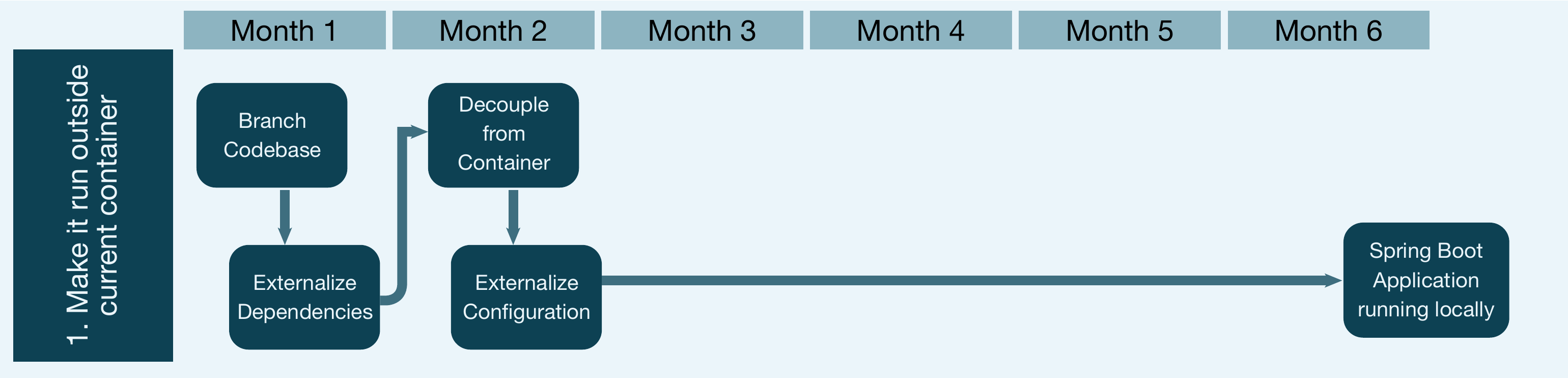
Abb. 3: Zeitrahmen für Stufe 1
Stufe 2: Den Monolithen in der Cloud zum Laufen zu bringen
Ersetzen der vom Container bereitgestellten Dienste
Ein Anwendungsserver bietet Mehrwertdienste. Durch die Entkopplung vom Anwendungsserver müssen nun diese bisherigen Dienste durch gleichwertige andere Dienste ersetzt werden. Ein Beispiel für einen solchen Dienst ist das Datenbankverbindungspooling. Um dieses zu ersetzen, wurde HikariCP (vgl. [HIKA]) eingeführt, eine beliebte Bibliothek, die für das Pooling von Datenbankverbindungen in getrennten Containern verwendet wird.
Externalisierung der Konfiguration – Teil 2
Die Konfiguration wurde zuerst in Stufe 1 in YAML-Dateien der Anwendung ausgelagert. Sie muss jetzt für unsere Anwendung in der Cloud verfügbar gemacht werden. Dies kann mithilfe von Spring Cloud Config und durch Konfiguration eines Spring Cloud Config-Servers zum Lesen umgebungsspezifischer Dateien aus einem GIT-Repository erreicht werden. Zur Laufzeit stellen die Anwendungsinstanzen eine Verbindung zur Cloud her und rufen die Konfigurationsdatei im Rahmen der Spring Boot-Initialisierung ab.
Unterstützungsdienste (Faktor IV)
In einer Cloud-nativen Anwendung müssen alle Unterstützungsdienste (z. B. Datenbank, System für message queuing) für die Anwendung bereitgestellt und zur Laufzeit gebunden werden. Das Ändern der Anwendung zur Behandlung von Diensten auf diese Weise ist im Allgemeinen nicht mit großem Aufwand verbunden. Es kann jedoch schwierig sein, die Dienste für die Cloud-Plattform verfügbar zu machen, insbesondere dann, wenn diese nicht über den entsprechenden Servicekatalog der Cloud-Plattform verfügbar sind.
Hier einige Beispiele für Unterstützungsdienste („backing services“) und Strategien, um diese als angehängte Ressourcen in der Cloud verfügbar zu machen:
Speicher für Websitzungsdaten (Web session storage): In den meisten älteren Anwendungen wird die Websitzung im Speicher gehalten und die Benutzersitzungen werden erhalten, indem man den Benutzer immer an denselben Server (mithilfe von „sticky sessions“, also Sitzungen, die an einem Server kleben bleiben) weiterleitet. In einer Cloud-nativen Anwendung muss diese Websitzung aus dem Speicher entladen werden. Eine beliebte Lösung zum Auslagern von Websitzungen ist Redis. Redis bietet einen hochverfügbaren und leistungsstarken Sitzungsspeicher, der problemlos mit Spring integriert werden kann. Darüber hinaus ist Redis in der Regel auf dem Marketplace guter PaaS-Plattformen verfügbar und kann somit zur Laufzeit an Anwendungen gebunden werden.
Datenbank: Es gibt mehrere Datenbanken, die über den Servicekatalog der jeweiligen Cloud-Plattform bereitgestellt werden können. Zum Beispiel: MySQL, MongoDB und PostgreSQL sind auf den meisten PaaS-eigenen Marketplaces verfügbar. Wegen des Lizenzmodells kann zum Beispiel ein Microsoft SQL Server einmal nicht auf einem Marketplace verfügbar sein. In einem solchen Fall müsste so eine Datenbank über eine andere Lösung (zum Beispiel virtuelle GCP-Instanz) zur Verfügung gestellt werden.
Dateifreigabe: Der Zugriff auf Dateifreigaben ist nicht der ideale Weg, um Informationen in der Cloud zu übertragen, aber die meisten älteren Anwendungen verlassen sich darauf und das Ersetzen kann ein großer Aufwand sein. Glücklicherweise gibt es einige Optionen, um den Zugriff auf Dateifreigaben in der Cloud zu ermöglichen. Eine besteht einfach darin, NFS (Network File System) für die Cloud verfügbar zu machen. Dies kann ein NFS sein, das in mehreren virtuellen Instanzen in der Cloud gehostet wird. Als generelle Regel für die Dateifreigabe in Cloud-nativen Anwendungen empfehlen wir die Verwendung eines Objektspeichers, zum Beispiel S3 Buckets (AWS) oder Cloud Storage Buckets (GCP), anstelle der Nutzung von NFS-Dateifreigaben.
Erstellen und Bereitstellen von Pipelines (Faktor V - Build, Release, Run)
Zu diesem Zeitpunkt haben wir eine Anwendung, die in mehreren Instanzen in der Cloud ausgeführt werden kann. Als Nächstes wird ein Weg benötigt, den Code zu bauen und ihn in der Cloud zu deployen. Jenkins ist ein beliebtes CI/CD-Tool, um dies zu erreichen. Zusammen mit Jenkins kommt auch gern Concourse für Pipeline-Services zum Einsatz. Jenkins-Pipelines lösen dabei den Build aus (nach einem Commit auf dem develop-Zweig in unserem Git-Repository) und deployen in die verschiedenen Umgebungen (Entwicklung, Qualitätssicherung und Produktion). Code sollte nur einmal gebaut und dieselbe gebaute Version in allen Umgebungen installiert werden.
Stufe 2 abgeschlossen
Am Ende dieser Phase sollte die Anwendung in der Cloud mit mehreren Instanzen ausgeführt werden und nahezu voll funktionsfähig sein (s. Abb. 4), je nachdem, ob alle von der Anwendung verwendeten internen Dienste in der Cloud verfügbar sind.
Abb. 4: Transformation nach Stufe 2
Das aktualisierte „swim lane“-Diagramm in Abbildung 5 zeigt, wie Aufgaben parallel ausgeführt werden können.
Sollte das Migrationsprojekt an dieser Stelle, aus welchen Gründen auch immer, gestoppt werden, so hat man zumindest zwei wichtige Dinge erreicht:
- die Laufzeitumgebung wurde ersetzt (inkl. der Externalisierung der Konfiguration),
- der Build- und Deploymentprozess wurde modernisiert, was die Qualität erhöht.
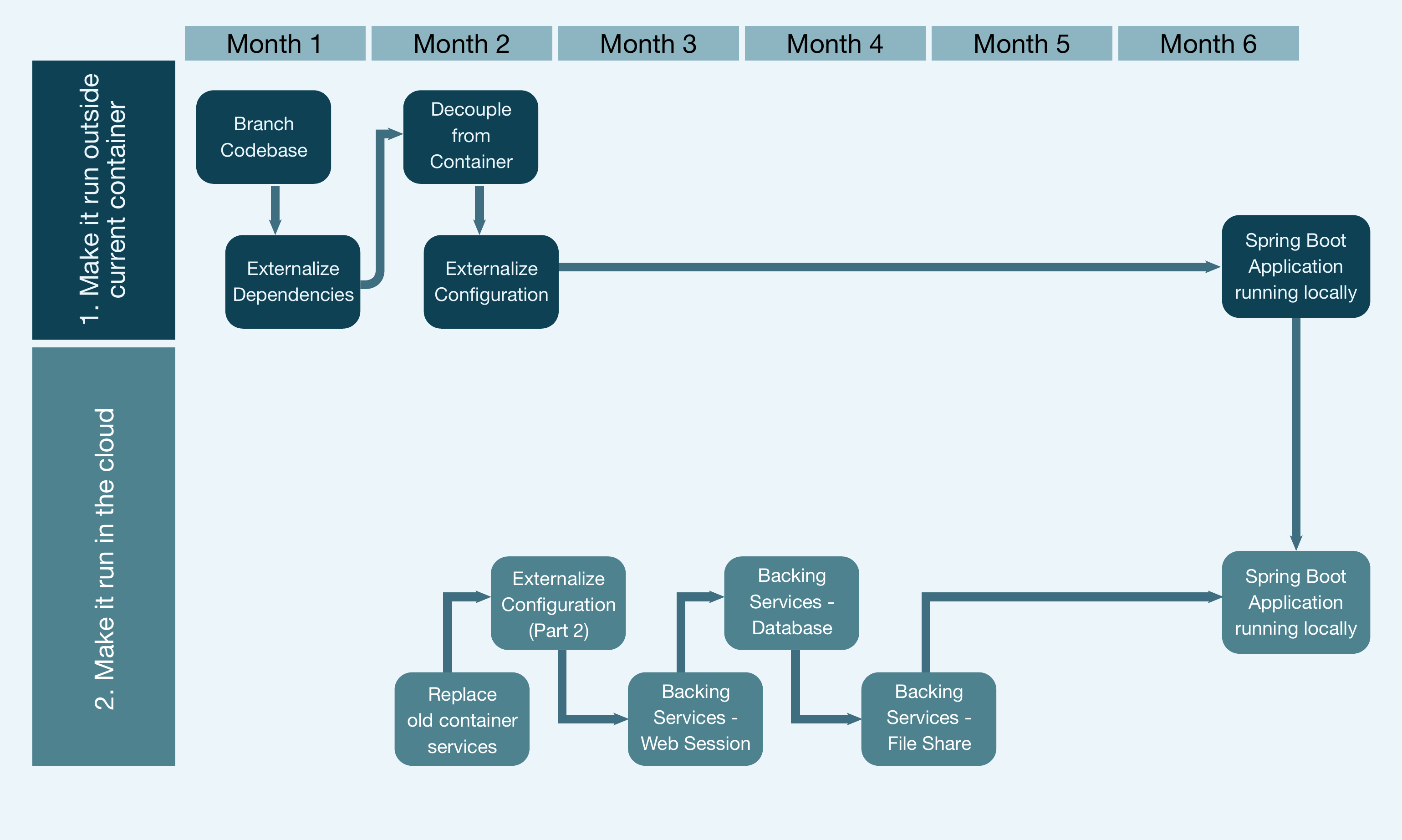
Abb. 5: Zeitrahmen für die Stufen 1 und 2
Stufe 3: Aufteilen des Monolithen in kleinere Anwendungen oder Microservices
Eine monolithische Anwendung besteht normalerweise aus einer Anwendung, die mehrere benutzerdefinierte Anwendungsbibliotheken enthält (s. Abb. 6).
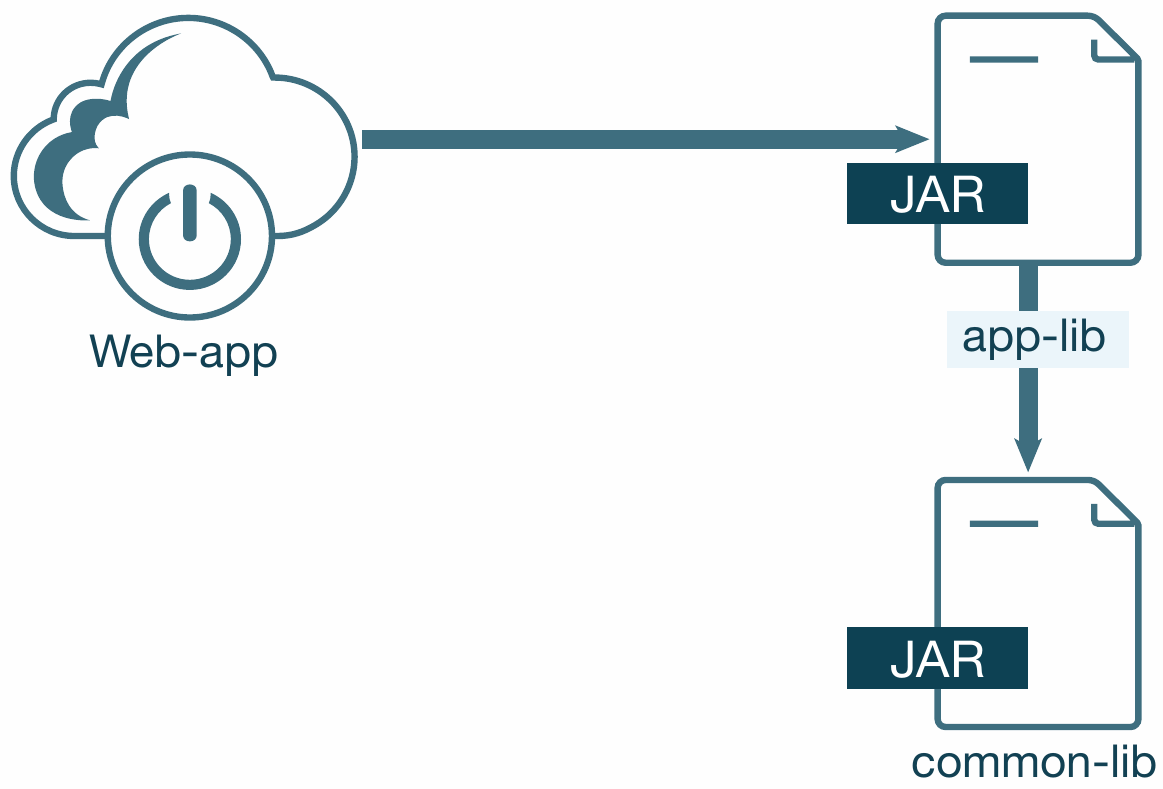
Abb. 6: Bibliotheken vor Stufe 3
Auch wenn Ihr Endziel nicht darin besteht, auf Microservices zu setzen, so empfiehlt es sich, monolithische Anwendung nach dem Ansatz des „Anwendungskontinuums“ (vgl. [App01]) in einzelne Anwendungen und Komponenten zu zerlegen.
Im ersten Schritt suchen wir nach Kandidaten dafür, zu einer neuen eigenständigen Anwendung zu werden. Überprüfen Sie alle Einstiegspunkte zu Ihrer Anwendung: Web-Benutzeroberfläche, REST-APIs, Konsumenten der message queues und geplante Aufgaben (scheduled tasks) sind gute Kandidaten. Neben dem Anwendungskontinuum gibt es noch weitere Strategien für Microservices. Gern werden hierzu verstärkt DDD-Techniken (Domain-Driven Design) wie Event Storming und Domain Storytelling eingesetzt. Identifizieren Sie während dieses Vorgangs auch Möglichkeiten, gemeinsam genutzte Bibliotheken in kleinere Bibliotheken aufzuteilen, um dadurch neue Codegrenzen und mögliche weitere Kandidaten für Microservices zu identifizieren.
In Abbildung 7 werden zwei neue Anwendungen aus unserem Monolithen herausgearbeitet – eine Warteschlangen-Consumerund eine REST-API-Anwendung. Diese beiden neuen Anwendungen werden ebenfalls als Spring Boot-Anwendungen implementiert und können unabhängig von der Hauptwebanwendung installiert werden. Sie lassen sich auch unabhängig voneinander skalieren. Die neuen Anwendungen haben kurze Start- und Ausschaltzeiten, da weniger Komponenten initialisiert werden. Sie sind so auch schneller zu deployen, da die gebauten Binärdateien dieser Anwendungen kleiner ausfallen und weniger Abhängigkeiten aufweisen.
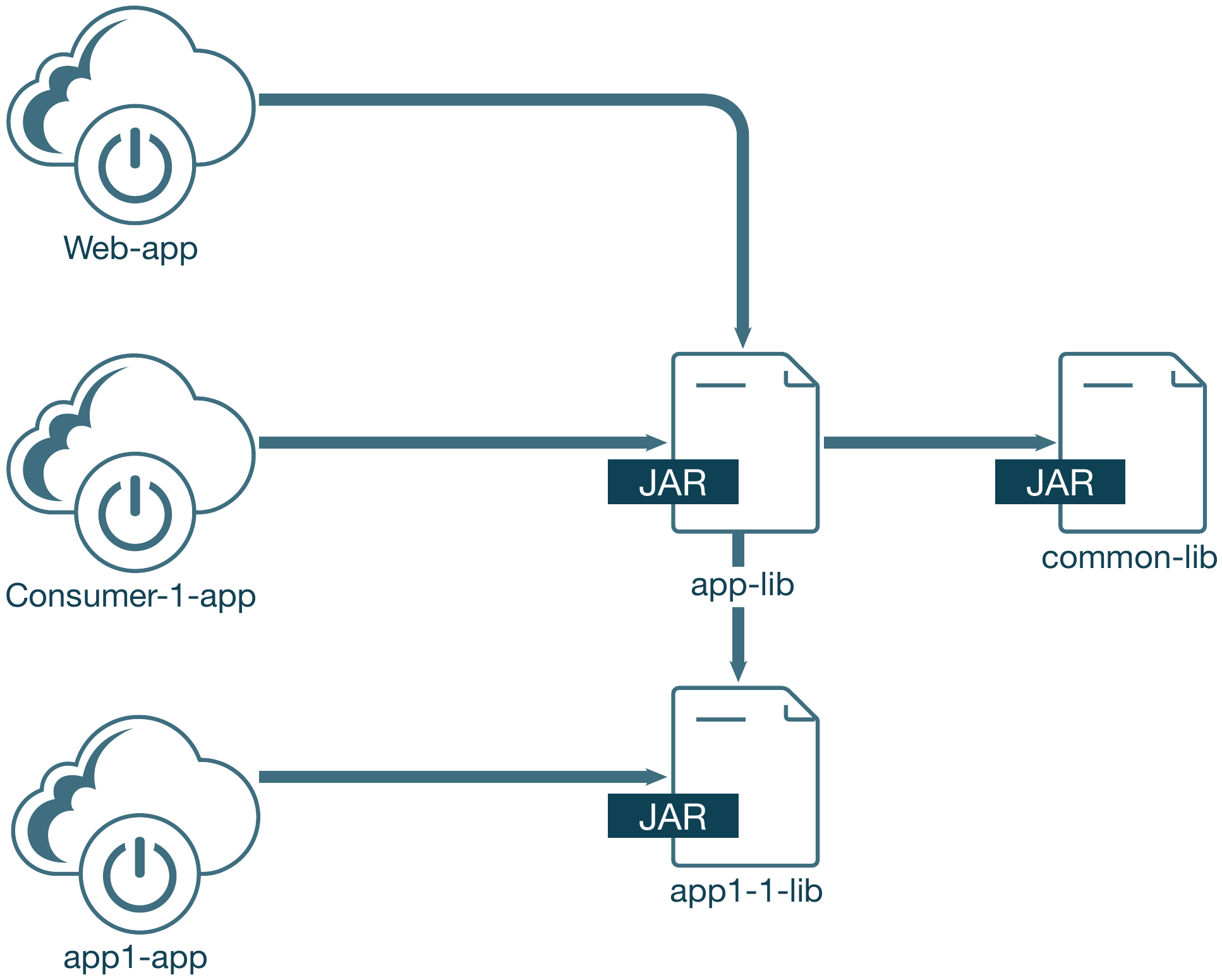
Abb. 7: Bibliotheken während der Stufe 3
Innerhalb der Anwendungen ist es empfehlenswert, die Entwicklung agil zu gestalten, auf Pair-Programming zu setzen, ein Vorgehen wie Test-Driven Design (TDD) einzusetzen und die gängigen Patterns (vgl. [GoF94]) und Anti-Patterns (vgl. [Fow18]) zu betrachten. All dies führt zu einer höheren Softwarequalität. Darüber hinaus ist eine gute Testabdeckung eine der Voraussetzungen für ein funktionierendes DevOps-Vorgehen.
Wird dieser Prozess fortgesetzt, entstehen daraus in Summe acht Anwendungen (s. Abb. 8):
- vier Anwendungen als Konsumenten einer message queue,
- eine REST-API-Anwendung und
- zwei Anwendungen für geplante Aufgaben (scheduled tasks).
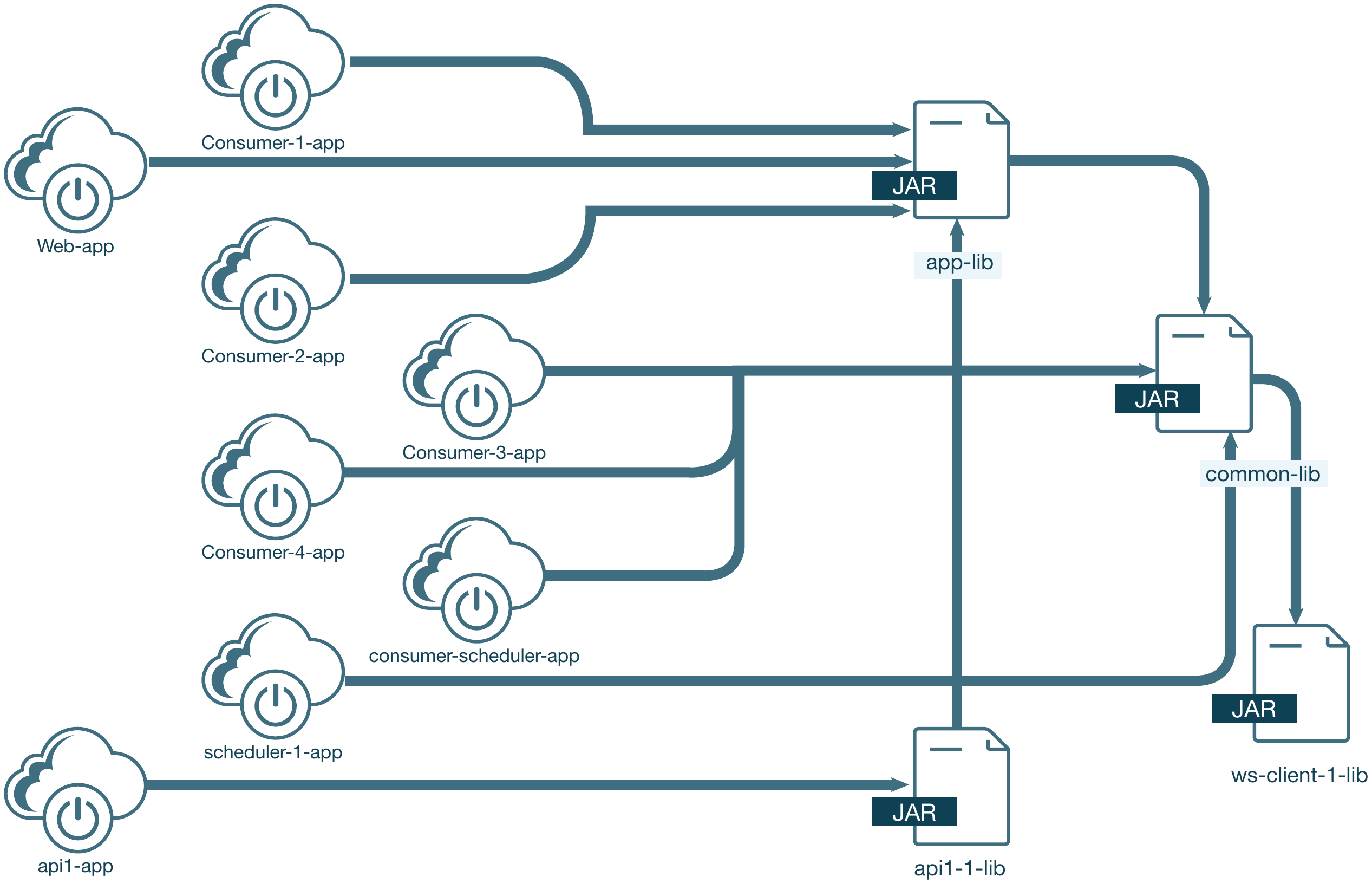
Abb. 8: Bibliotheken nach Stufe 3
Die monolithische Anwendung ist jetzt wesentlich kleiner und auch ausschließlich eine Webanwendung ohne unnötige Einstiegspunkte.
Diese neuen, kleineren Anwendungen sind alle cloud-friendly und können unabhängig voneinander deployt und skaliert werden. Sie teilen sich jedoch weiterhin eine gemeinsame Bibliothek und eine gemeinsame Datenbank, weswegen sie nicht als Microservices bezeichnet werden können. Wenn in einer der allgemeinen Bibliotheken ein Fehler gefunden wird, müssen Sie möglicherweise alle Anwendungen, die diese Bibliothek nutzen, erneut bauen und deployen.
Diese Transformation kann in relativ kurzer Zeit durchgeführt werden, sodass Anwendungen schneller in die Cloud-Laufzeitumgebungen migriert werden können und es Ihrem Unternehmen ermöglicht wird, früher und häufiger neue Versionen zu veröffentlichen. Die Bibliotheken können schrittweise in kleinere Bibliotheken aufgeteilt werden und ermöglichen es dadurch, dass die Anwendungen schließlich zu Microservices werden.
Abbildung 9 zeigt, dass am Ende von Stufe 3 jetzt mehrere Spring Boot-Anwendungen in der Cloud laufen, die unabhängig voneinander deployt werden könnten, vorausgesetzt, alle externen Systeme sind erreichbar. Es zeigt auch die Parallelität zwischen den drei Stufen.
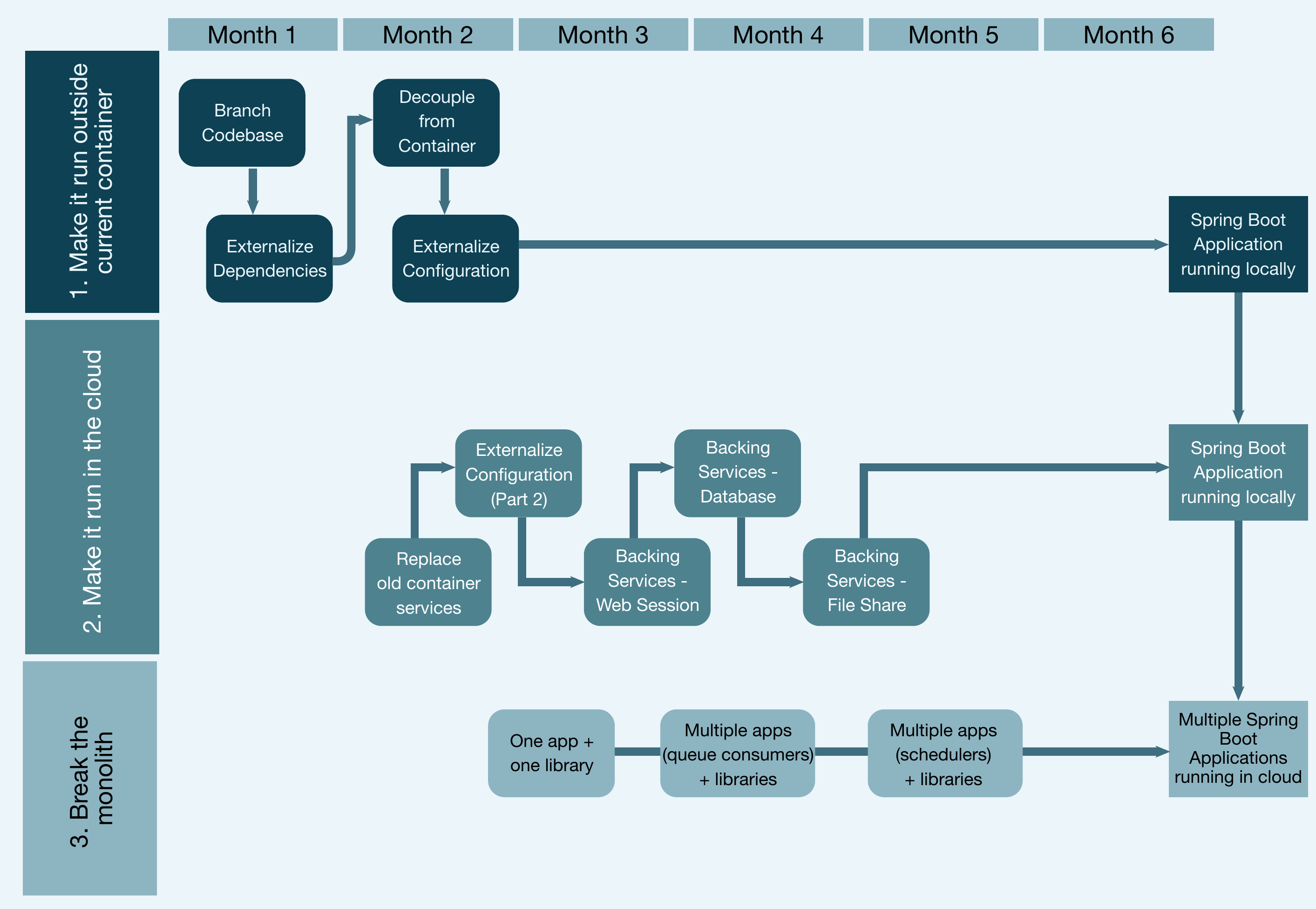
Abb. 9: Zeitrahmen für die Stufen 1 bis 3
Sollte das Migrationsprojekt an dieser Stelle, aus welchen Gründen auch immer, gestoppt werden, so kann man die Vorteile der neuen „Cloud“ für die eigene Anwendung bereits nutzen. Um die volle Funktionsfähigkeit der Applikation sicherzustellen, ist es jedoch zwingend erforderlich, dass in Stufe 4 die Erreichbarkeit der benötigten intern gehosteten Dienste gewährleistet wird.
Stufe 4: Virtualisierung („Lift and Shift“) interner gehosteter Dienste
Diese Phase ist oft die am wenigsten aufregende, dennoch ist sie wichtig. Der Monolith kann von Systemen im Unternehmen abhängen, die nicht in eine Cloud-Infrastruktur bewegt werden. Es ist sehr wichtig, diese Themen so früh wie möglich im Projekt zu identifizieren und eine Strategie für diese Systeme zu planen.
Da diese Phase normalerweise die meiste Zeit erfordert, ist es entscheidend, sie frühzeitig und parallel zu den anderen Phasen zu beginnen, denn möglicherweise sind Änderungen an der Infrastruktur erforderlich oder es gibt Auswirkungen auf Systeme, über die Sie weniger Kontrolle haben. Der erste Schritt in dieser Phase besteht darin, diese gemeinsam genutzten Anwendungen zu identifizieren und eine der folgenden Strategien festzulegen:
- Können sie in der Cloud virtualisiert werden („Lift and Shift“)?
- Dies ist dann der Fall, wenn alle abhängigen Anwendungen in der Cloud gehostet werden.
- Kann die gemeinsam genutzte Anwendung über die Cloud erreichbar werden? Dies kann eine gute Option für Anwendungen sein, die von Cloud- und Nicht-Cloud-gehosteten Anwendungen gemeinsam genutzt werden.
Sobald alle abhängigen Anwendungen von der Cloud-Plattform verfügbar sind, sind die neuen transformierten Anwendungen in der Cloud voll funktionsfähig und können veröffentlicht werden. Abbildung 10 zeigt den Zeitrahmen für alle vier Stufen.
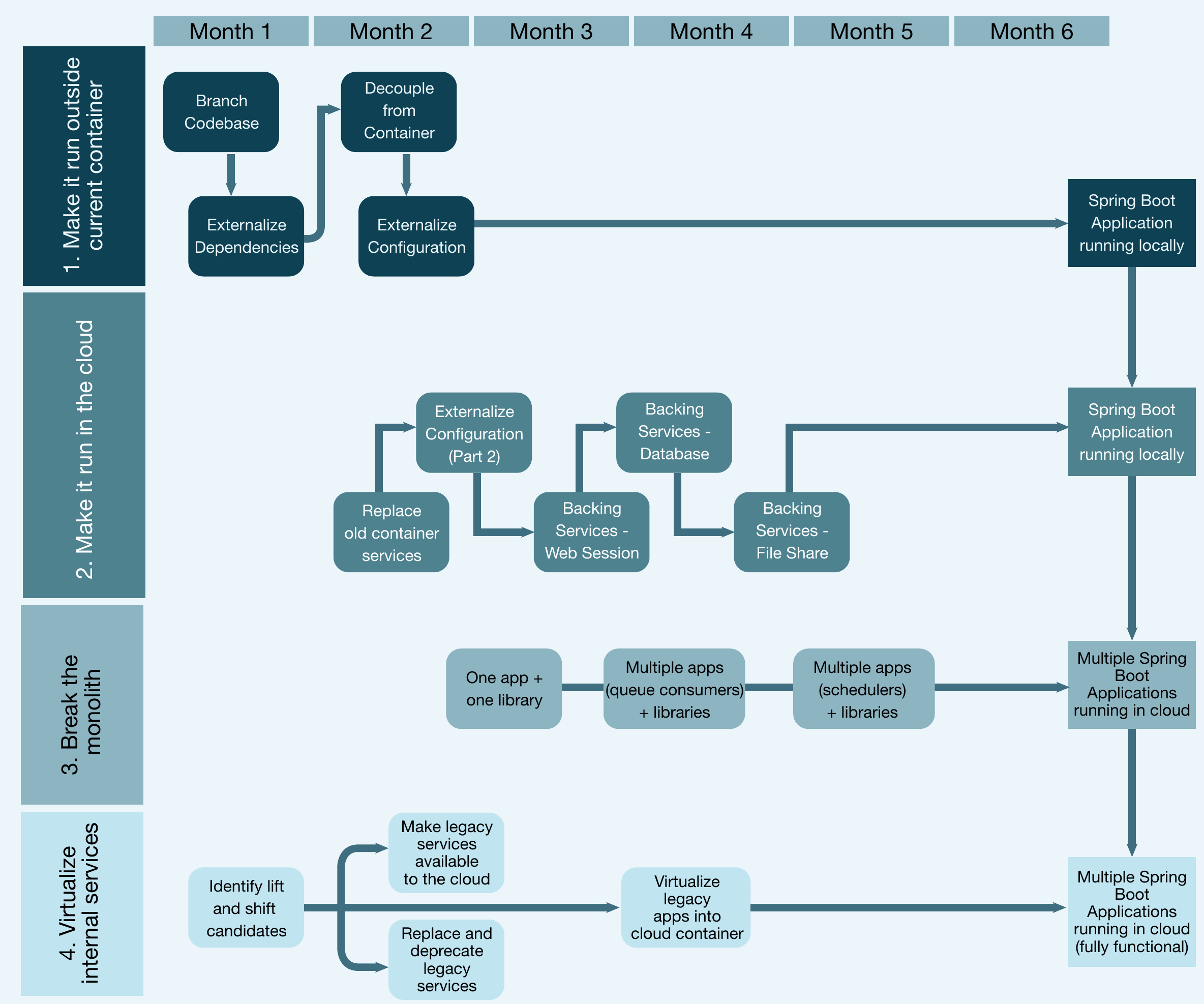
Abb. 10: Zeitrahmen für alle vier Stufen
Fazit
Wie dargestellt gibt es eine Menge zu tun und zu beachten, um eine monolithische Anwendung in eine Cloud-native Anwendung, bestehend aus mehreren Microservices, zu transformieren. Mit der nötigen Disziplin, einem klaren und schrittweisen Vorgehensmodell und einer Portion Enthusiasmus ist es jedoch eine beherrschbare Aufgabe.
In diesem Sinne „Keep the code coming“.
Weitere Informationen
[App01] https://www.appcontinuum.io
[Fow18] M. Fowler, Refactoring: Improving the Design of Existing Code, Pearson Addison-Wesley, 2018
[GoF94] E. Gamma, R. Helm, R. Johnson, J. Vlissides, Design Patterns – Elements of Reusable Object-Oriented Software, Addison-Wesley, 1994
[HIKA] B. Wooldridge, HikariCP, https://github.com/brettwooldridge/HikariCP
[RHMT] Red Hat Migration Toolkit, https://developers.redhat.com/products/rhamt/overview
[WAMT] IBM, WebSphere Application Server Migration Toolkit, https://developer.ibm.com/wasdev/downloads/#asset/tools-WebSphere_Application_Server_Migration_Toolkit








