

Künstliche Intelligenz (KI) befindet sich – obgleich schon seit Jahrzehnten in der Forschung – in den vergangenen Jahren auf einem sehr medienwirksamen Siegeszug. Alle Aufgaben scheinen lösbar, jede menschliche Intelligenz unnötig, die möglichen Folgen kontrollierbar. Es gibt sehr viele überzeugende Demonstrationen, zum Beispiel sind KI-gesteuerte Computerspieler, die in Form von Alpha GO den weltbesten GO-Spieler Lee Sedol besiegen. GO ist übrigens deutlich komplexer als Schach und die Spielabläufe sind hier daher ungleich schwieriger vorherzusagen. Andere KI-Anwendungen können zielsicher die Inhalte von Bildern erkennen mit unterschiedlichsten Anwendungszwecken von der frühzeitigen Diagnose von gefährlichen Krankheiten bis hin zur Überwachung des öffentlichen Raumes. Aber ist es so einfach?
Selbstverständlich wirken die präsentierten Ergebnisse sehr überzeugend. Doch ist der Weg, den die KI zum Erreichen des Ergebnisses gewählt hat, immer wirklich intuitiv? Einige Untersuchungen haben gezeigt, dass einige Bilder beispielsweise nicht anhand der eigentlich abgebildeten Pferde als Pferdebild klassifiziert wurden, sondern anhand des ebenfalls auf vielen Pferdebildern vorhandenen Stückchen Walds oder anhand der Signatur des Fotografen (der eben öfter Pferde fotografiert). Somit wurde das Wunder der KI an einigen mit verfrühten Lorbeeren versehenen Beispielen entzaubert, und Erinnerungen an das Pferd „Kluger Hans“ wurden wach, das nur zum Schein zählen konnte.
Darüber hinaus wurden auch Fehlschläge wie der Unfall eines UBER-Fahrzeugs medial ausgeschlachtet, sodass man autonome Fahrzeuge schon bald für eine Gefahr halten musste. Man übersieht dann leicht, dass allein in Brandenburg pro Woche durchschnittlich 2 bis 3 Menschen bei Verkehrsunfällen ums Leben kommen und dass auch eine nicht ganz perfekte KI hier durchaus Vorteile bieten könnte. Entsprechend wird diese Technologie mal übertrieben in den Himmel gehoben und mal verdammt, bevor die Zusammenhänge klar sind.
Wir sehen hier also sowohl im Guten als auch im Schlechten eine Übertreibung. Entsprechend sind wir der Überzeugung, dass hier lediglich der Hype zuschlägt, und dass KI sehr viel Potenzial bietet, auch in sicherheitskritischen Anwendungen eingesetzt zu werden. Die Voraussetzung dafür ist natürlich, dass diese Technologie gut abgesichert werden kann.
In diesem Zusammenhang kann man sich etliche Fragen stellen. Wir reißen im Folgenden ein paar davon zu verschiedenen Teilthemen an und bieten somit einen Einstieg – zu tiefergehenden Fragen ist die Wissenschaft wie gesagt seit Jahrzehnten mit Fragen rund um dieses Thema beschäftigt.
Bewertung der KI
Zunächst spielt Statistik hier eine große Rolle und wird zur internen Bewertung von Situationen, Bildern usw. herangezogen. Mithilfe der Konfusionsmatrix können Vorhersage und Realität für binäre Klassifikatoren bewertet werden: Was wird korrekt vorhergesagt? Wo und wie irrt die KI?
Für die Bewertung dieser Resultate gibt es verschiedene Mittel wie zum Beispiel das harmonische Mittel aus Genauigkeit und Sensitivität, auch F1-Score genannt. In jedem Fall ist klar, dass die dem Ergebnis beigemessene Bedeutung je nach Domäne unterschiedlich ausfällt: So ist beispielsweise die fehlerhafte Diagnose auf Existenz eines (tatsächlich nicht vorhandenen) Tumors nicht so schlimm für die Lebenserwartung des Patienten wie das Nichterkennen eines (tatsächlich vorhandenen) Tumors.
Test-Know-how
Weiterhin stellt sich dem geübten Tester natürlich die Frage, welche der ihm bereits seit vielen Jahren bekannten Bordmittel aus dem Bereich der Qualitätssicherung hier anwendbar sind.
- Sind White-Box-Testverfahren überhaupt sinnvoll oder ähnelt das eher den noch umstrittenen Versuchen zur Bestimmung von menschlicher Intelligenz?
- Ist es sinnvoll, den Test in verschiedene Teststufen zu unterteilen, wie wir es vom V-Modell kennen? Für komplexe Systeme, die einen oder mehrere auf KI basierende Algorithmen im Inneren verbergen, ist dies durchaus sinnvoll. Ist das auch für das Maschinenlernen mit einer Vielzahl an Zwischenschichten sinnvoll? Das führt in Richtung Erklärbarkeit der Implementierung.
- Worauf achten wir beim Test eigentlich? Geht es nur darum, dass der Algorithmus bessere Ergebnisse erzeugt als der Vorgänger oder unterteilen wir etwas genauer? Nach funktionalen Tests und nicht-funktionalen? Wie sieht es mit IT-Security aus? Schon minimale Änderungen an der Gestaltung von Verkehrszeichen führten dazu, dass ein autonomes Fahrzeug die Aufschrift „30“ an einem Geschwindigkeitsbegrenzungsschild als „80“ interpretierte und entsprechend schwungvoller durch die Stadt fahren wollte. Ebenso katastrophal können Auswirkungen von inkonsistenten Situationen wie das Stoppschild auf der Autobahn sein.
- Weiterhin stellt sich die Frage, wann das selbstlernende System eigentlich wirklich lernen darf? Permanent im Einsatz? Dann könnte ein selbstfahrendes Fahrzeug eines Pendlers sehr bald auf die Eigenheiten der täglichen Strecke trainiert sein und den Rest „vergessen“. Oder sollte die KI doch eher nur im Service oder in der Entwicklung lernen dürfen? Was sind Beschränkungen in Abhängigkeit von der Anwendungsdomäne?
KI für den Test
Auf der anderen Seite verlockt uns Tester natürlich der Gedanke, die scheinbar unbegrenzten Möglichkeiten der Künstlichen Intelligenz auch für den Softwaretest selbst zu nutzen. Auch hierfür gibt es interessante Entwicklungen. Als ein Anwendungsbereich sticht der Performanztest ins Auge, bei dem die KI in Abhängigkeit der Eingabedaten Auffälligkeiten im Systemverhalten und der Systemlast erkennen kann. Diese Beobachtungen könnten genutzt werden, um das System näher und näher an die Belastungsgrenze zu führen oder darüber hinaus.
Das Finden von Ähnlichkeiten und Gemeinsamkeiten kann in vielen weiteren Feldern Anwendung finden: für Fehlermeldungen, Testspezifikationen, Log-Dateien des Testobjekts, die Generierung von Testdaten basierend auf Datenformatbeschreibungen oder Testabläufen basierend auf der Codeanalyse. Ein weiteres spannendes Thema ist der Einsatz einer KI als Testorakel. Hierbei stellt sich wie so oft die Frage, ob eine KI, die als Testorakel dienen kann, nicht auch gleich als zu testendes System genutzt werden kann und sogar besser als das Original ist? Darüber hinaus stellt sich auch gleich die Frage nach den Grenzen: Welche Entscheidungen können und wollen wir einer KI überlassen? Manch einer fühlt sich hier an das Trolley-Problem erinnert, das schon für Menschen unlösbar oder zumindest meist nur schwer rechtfertigbar ist: Wenn ein tödlicher Unfall unvermeidlich ist und man den Ausgang noch minimal beeinflussen kann – wer darf leben und wer muss sterben?
Wir haben unsere Gedanken dazu in ein Poster einfließen lassen (siehe Abbildung 1), auf dem wir auch weitere Verweise und Quellen aufgeführt haben. Diese und weitere Gedanken sind ein Einstieg in diese hochinteressante Thematik, die gerade wirtschaftlich interessant wird und noch viele spannende Jahre vor sich hat.
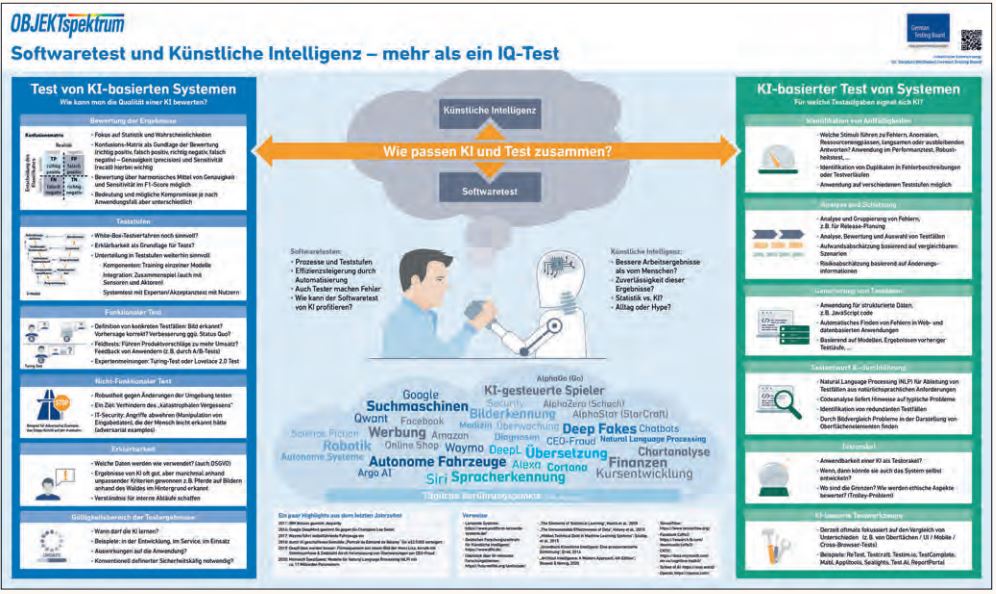
Abb. 1: GTB-Poster (Leser des German Testing Magazin können das Poster kostenfrei unter der folgenden URL nach Hause bestellen: https://bit.ly/39v016M)









