

Oracle hat Anfang 2018 angekündigt, die Java Platform, Enterprise Edition (Java EE) nicht mehr weiterzuführen. Stattdessen soll das Projekt unter dem Namen Jakarta EE von der Eclipse Foundation übernommen werden. Mitte 2019 sind die Verhandlungen zwischen der Eclipse Foundation und Oracle zur Weiterentwicklung des Namespace javax im Kontext des Java EE-Nachfolgers Jakarta EE jedoch gescheitert [Mil19]. Nun steht die Jakarta Community vor einem Scherbenhaufen.
War bisher Jakarta EE als neue Ziel-Technologie augenscheinlich die naheliegendste Lösung, stellt es nun ein schwer kalkulierbares Risiko dar. Eine Alternative, die sich im Enterprise-Umfeld bewährt hat, ist Spring Boot.
Nach und nach werden Unternehmen, die JEE-Applikationsserver wie JBoss/Wildfly oder IBM WebSphere nutzen, sich der Realität eines auslaufenden Supports und der fehlenden Update-Fähigkeit stellen müssen. Die Konsequenz daraus: ein Migrationsprojekt. Dabei steht ein Qualitätsziel immer im Vordergrund: Sicherung des Betriebs. Im Enterprise-Umfeld haben wir es meist mit heterogenen und oft unübersichtlichen Systemlandschaften zu tun, bei denen der Ausfall einzelner Komponenten zu wesentlichen Störungen im Betrieb führen kann.
Notwendige Kriterien für erfolgreiche Migration
Der Erfolg der Migration ist daher von folgenden Kriterien abhängig:
- Iterativität: Umsetzung in kleinen Schritten, da die Größe und Unübersichtlichkeit des vorhandenen Systems eine „Big Bang“-Ablösung verhindert.
- Kompatibilität: Die „alte“ und „neue“ Welt müssen jederzeit kompatibel zueinander bleiben.
- Testabdeckung: Vorher/Nachher-Tests reduzieren die Wahr-scheinlichkeit für eine Beeinträchtigung des Betriebs.
Da Spring Boot alle Kriterien einer Twelve-Factor App (gem. Adam Wiggins [Wig17, Vos19]) erfüllt und sich als De-facto-Industriestandard etabliert hat, wird es für diesen Artikel als Migrationsziel gewählt. Das hier präsentierte Vorgehensmodell lässt sich jedoch auch problemlos auf andere Ziel-Technologien anwenden.
Im Folgenden werden die wichtigsten Schritte bei der Migration einer umfangreichen Enterprise-Java-Anwendung beschrieben. Die Systemlandschaft, die abgelöst werden soll, wird im Folgenden Legacy-Umfeld genannt.
Durchführung
Ein elementarer Schritt der Migration ist die zielgerichtete Dokumentation des aktuellen Zustands des Systems, denn um ein System ändern zu können, muss man es erst verstehen.
Zielgerichtete Dokumentation
Erfahrungsgemäß sind viele Systeme nicht ausreichend dokumentiert (oder die Dokumentation ist nicht aktuell genug), um eine reibungslose Migration zu garantieren. Die Dokumentation muss dabei insofern zielgerichtet sein, als dass sie dem Zweck der Sicherung des Betriebs während der Migration und der Gewährleistung von Kompatibilität zwischen bereits migrierten und noch nicht migrierten Komponenten dient.
Um eine Idee davon zu bekommen, welches Abstraktionsniveau für die Dokumentation angemessen ist, hilft es, sich für jede zu migrierende Komponente folgende Frage zu stellen: Welche anderen Komponenten sind von diesem Migrationsschritt betroffen? Daraus lassen sich folgende Dokumentationsziele ableiten:
- Komponenten identifizieren: Was sind die derzeit vorhandenen in sich geschlossenen Artefakte? -> Wer?
- Abhängigkeiten identifizieren: Welche Komponenten kommunizieren miteinander? -> Mit wem?
- Kommunikationskanäle identifizieren: Wie kommunizieren die Komponenten miteinander (Technologie, Routing, ...)? -> Wie?
Als Mittel zur grafischen Darstellung der Dokumentation wird die EIP-Notation von Gregor Hohpe und Bobby Woolf [Hoh19] empfohlen. Dabei handelt es sich um eine Visualisierungsbibliothek, die sich für die Darstellung von Enterprise Integrations Patterns (EIP, Kommunikationsstrategien innerhalb einer heterogenen Systemlandschaft) eignet.
Abbildung 1 zeigt ein Beispiel für einen Dynamic Router in der EIP-Notation. In dem Bild werden für die betrachteten Komponenten alle drei relevanten Fragen beantwortet:
- Wer? Komponenten A, B, C und der Dynamic Router
- Mit wem? A, B und C erhalten Nachrichten vom Dynamic Router
- Wie? Messaging (z. B. eine Queue)Die Komponenten A, B und C lassen sich in diesem Beispiel relativ gefahrlos migrieren, da sie lediglich Nachrichten empfangen (nur auf den Control Channel muss geachtet werden). Bei der Migration des Dynamic Routers muss hingegen mit potenziellen Auswirkungen auf A, B und C gerechnet werden.
In diesem Beispiel sind die Komponenten A, B und C lose (via Messaging) über den Dynamic Router gekoppelt. Das heißt, eine Suche nach Referenzen in einer IDE hätte diese Abhängigkeit nicht aufgedeckt.
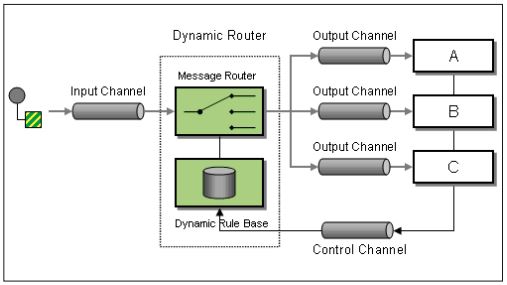
Abb. 1: Dynamic Router dargestellt in EIP-Notation (CC BY 4.0)
Vorbereitungsarbeiten in der Legacy-Umgebung
Nachdem die Beziehungen innerhalb des Systems offengelegt wurden, kann nun mit der eigentlichen Migration begonnen werden. Dafür muss das System zunächst in einen Zustand gebracht werden, der den Umzug einzelner Komponenten in die neue Laufzeitumgebung erlaubt und dabei Kompatibilität mit dem Legacy-Umfeld gewährleistet, indem die zu migrierenden Komponenten in API und Implementierung aufgeteilt werden.
Das Ziel der Unterteilung in API- und Impl-Artefakte ist in Abbildung 2 dargestellt. Die Komponenten für Auftragsverwaltung und Banking wurden jeweils in zwei Artefakte aufgeteilt: API und Implementierung. Dabei ist zu beachten, dass Implementierungsartefakte zur Compile-Zeit lediglich auf die APIs anderer Komponenten zugreifen dürfen. Erst zur Laufzeit wird dann die Implementierung aufgerufen. Dadurch wird eine Entkoppelung der Laufzeitbelange erzielt, was wiederum einen Umzug von Banking ermöglicht, ohne dass die Auftragsverwaltung davon direkt betroffen ist, da die Schnittstelle (das API) unangetastet bleibt.
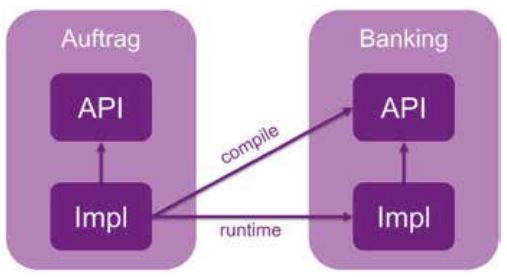
Abb. 2: Unterteilung in API und Impl
Wie ein Implementierungsartefakt zur Laufzeit aufgerufen wird, hängt von der Beschaffenheit der Legacy-Umgebung ab. In den meisten Fällen wird der IoC-Container des verwendeten JEE-Applikationsservers den Aufruf der Implementierung (z. B. einer Enterprise-Java-Bean) steuern. Im Folgenden wird erläutert, welche Inhalte ein API- beziehungsweise ein Implementierungs-Artefakt hat.
In der Implementierung wird die eigentliche Geschäftslogik hinterlegt. Um sie aus dem Legacy-Umfeld herauszutrennen, muss sie zunächst über Interfaces abstrahiert werden.
Beispiel: Banking wird von Auftragsverwaltung verwendet, indem Letztere eine Methode im Banking direkt aufruft. Daraus folgt, dass Banking vor Auftragsverwaltung migriert werden muss. Allerdings ist das im ursprünglichen Zustand gar nicht möglich, da API und Implementierung noch nicht getrennt sind.
Die Geschäftslogik von Banking lässt sich so nicht in die neue Laufzeitumgebung migrieren, da sie sonst in der Auftragsverwaltung fehlen würde. Wenn Letztere jedoch nur auf ein Interface des Bankings verweist, kann die Implementierung ausgetauscht werden (z. B. durch einen HTTP-Call auf die neue Laufzeitumgebung, dazu später mehr), ohne dass die Geschäftslogik der Auftragsverwaltung dafür geändert werden muss.
In diesem Kontext muss eine wichtige Entscheidung getroffen werden: Wie groß ist ein Migrationsschritt? Entsprechend sollten nämlich auch die Interfaces des Bankings geschnitten werden. Der Inhalt eines Migrationsschritts ist somit die Implementierung hinter einem dieser Interfaces. Die Geschäftslogik landet letztlich im Implementierungs-Artefakt, die Interfaces dazu im Banking-API.
Wichtig: Rein technische Belange (besonders solche, die nur im Legacy-Umfeld lauffähig sind) haben in der Geschäftslogik nichts zu suchen. Falls also zum Beispiel DataSources, Queue-Connections, JNDI-Kontexte oder Ähnliches direkt in der Geschäftslogik vorhanden sind, müssen diese auch über Interfaces abstrahiert und im Legacy-Umfeld sowie in der neuen Laufzeitumgebung implementiert werden. Diese Handlungsempfehlung ist weithin als „Separation of Concerns“ bekannt [CCD].
Im Kontext von JEE-Anwendungen besteht das Application Programming Interface (API) aus Local- beziehungsweise Remote-JEE-Interfaces und Transfertypen. Mit Transfertypen sind dabei die Ein- und Rückgabeparameter aus den Methoden-Signaturen der zu migrierenden Komponenten gemeint. Dabei ist zu beachten, dass die Transfertypen im Rahmen der Migration via Jackson in das JSON-Dateiformat serialisiert werden (mehr dazu im Abschnitt zum Strangler-Pattern). Bei umfangreichen Objektbäumen (die ggf. auch Zyklen oder Selbstreferenzen enthalten) müssen die Transfertypen also entweder um Jackson-Annotationen erweitert (z. B. @JsonIdentityInfo) oder auf einfache POJOS abgebildet werden.
Nach der Unterteilung in API- und Impl-Artefakte kommen wir nun zum 2. Schritt der Vorbereitung der Legacy-Umgebung, der Extraktion eines Shared-Kernels. Die Erfahrung hat gezeigt, dass viele Legacy-Umgebungen unter einer sehr unübersichtlichen Verstrickung vorhandener Komponenten leiden (s. Abb. 3). Systeme in einem solchen Zustand werden oft „Big Ball of Mud“ genannt und haben gemein, dass sie schwer änderbar sind. Änderungen oder gar das Herauslösen einzelner Komponenten bringen das gesamte System in Gefahr, da die Auswirkungen aufgrund der unübersichtlichen Struktur nicht absehbar sind.

Abb. 3: Big Ball of Mud
Zum Zweck einer Migration müssen die Abhängigkeiten in die Form eines gerichteten Graphen übertragen werden. Eine Möglichkeit hierzu ist das Herauslösen eines gemeinsamen Kerns (Shared-Kernel), der aus Elementen besteht, die von mehreren Komponenten genutzt werden. Dieser Shared-Kernel wird während der Migration sowohl vom Legacy- als auch von der neuen Laufzeitumgebung verwendet, muss also mit beiden Umgebungen kompatibel sein. Das Ziel ist in Abbildung 4 dargestellt.
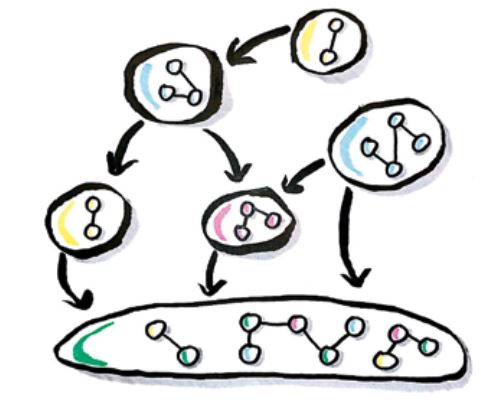
Abb. 4: Shared-Kernel
Nun kann zum einen eine sinnvolle Reihenfolge für die Migration der Komponenten ermittelt (s. nächster Abschnitt zum Strangler-Pattern) und zum anderen besser abgeschätzt werden, welche abhängigen Komponenten vom aktuellen Migrationsschritt betroffen sind.
Nach Abschluss der Migration sollte dieser Shared-Kernel aufgelöst werden, indem die beinhalteten Elemente in die Ziel-Komponenten integriert werden. Sollte der Shared-Kernel die Migration zu lange überleben, führt er zu einer engen Kopplung zwischen den einzelnen Komponenten, verschlechtert damit die Wartbarkeit und führt letztlich wieder zu einem Big Ball of Mud.
Aufstellen der Ziel-Umgebung mithilfe des Strangler-Musters
Alle bisherigen Schritte fanden in der Legacy-Umgebung statt. Mit Dokumentation und Aufteilung der zu migrierenden Komponenten in API und Implementierung sind die wesentlichen Voraussetzungen für die eigentliche Migration geschaffen. Nun muss die Ziel-Umgebung aufgestellt werden. Wie bereits gesagt, handelt es sich dabei in diesem Beispiel um eine Spring Boot-Anwendung.
Sobald eine leere Spring Boot-Anwendung in allen Stufen (Test, Qualitätssicherung, Prod) läuft, korrekt konfiguriert ist und per Continuous-Integration-Pipeline ausgerollt werden kann, beginnt die schrittweise Migration. Martin Fowler schlägt ein allgemeines Vorgehensmodell dafür vor: das Strangler-Pattern [Fow04]. Kurz gesagt ist mit Strangler=Würger ein graduelles „Umschlingen“ der neuen Umgebung um die alte gemeint, solange bis die alte Umgebung nicht mehr benötigt wird und abgeschaltet werden kann.
Der größte Vorteil dieses Vorgehensmodells ist ein reduziertes Risiko. Ein kleinschrittiges, sukzessives Ablösen der Legacy-Umgebung gefährdet den Betrieb weniger als größere Migrations-Schritte oder gar ein Cut-Over in einem einzigen Schritt. Die Unterteilung in kleine Arbeitspakete fördert darüber hinaus auch eine Umsetzung im Kontext eines agilen Projekts. Im Folgenden wird das Strangler-Pattern in einzelnen Schritten vorgestellt.
Ausgangszustand und Schritt 1
Der Ausgangszustand ist die zu migrierende Legacy-Umgebung, deren Komponenten bereits in API und Implementierung unterteilt wurden. In Abbildung 5 wird ein Beispiel skizziert, welches RMI zur Kommunikation zwischen den Komponenten verwendet.
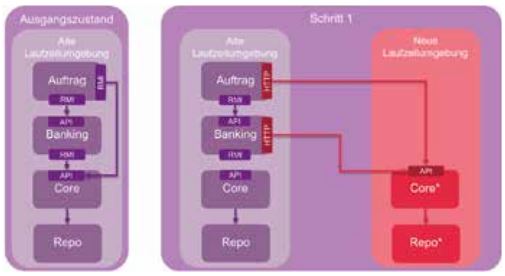
Abb. 5: Strangler-Pattern, Schritt 1
Als Erstes wird die Core-Komponente (genauer: das entsprechende Implementierungs-Artefakt) migriert. Core wurde ausgewählt, da keine Abhängigkeiten zu anderen Komponenten vorhanden sind (Core persistiert lediglich Daten in das Repository).
Als Kommunikationskanal zwischen Legacy- und neuer Laufzeitumgebung wird in diesem Beispiel SOA over HTTP verwendet. Da die Programmierschnittstelle, die hier per HTTP aufgerufen wird, aus Kompatibilitätsgründen so nah wie möglich den Signaturen der einzelnen Methoden der Java-Interfaces der alten Komponenten angeglichen werden sollte, entspricht das Ergebnis eher einer allgemeinen serviceorientierten Architektur (SOA) als dem spezifischen REST-Stil. Implementiert werden kann das API in der neuen Laufzeitumgebung beispielsweise als Spring-RestController, der eingehende Aufrufe an die eigentliche Implementierung von Core delegiert.
Diese HTTP-Schnittstelle kann nun in der Legacy-Umgebung von den Komponenten Auftragsverwaltung und Banking verwendet werden, die bisher noch nicht umgezogen wurden. Um höchstmögliche Kompatibilität zu gewährleisten, kann die „alte“ Core-Komponente als Fassade verwendet werden, welche, anstatt wie bisher die Geschäftslogik selbst auszuführen, den Aufruf per HTTP (z. B. via Spring-RestTemplate) an die neue Laufzeitumgebung weiterleitet.
Schritt 2
Im nächsten Schritt (s. Abb. 6) wird die Banking-Komponente migriert. Dies ist nun möglich, da sie lediglich auf die Core-Komponente verweist, welche ja bereits migriert wurde.
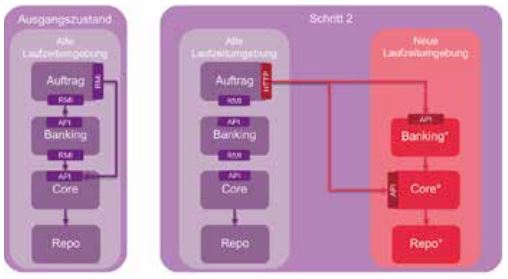
Abb. 6: Strangler-Pattern, Schritt 2
In der neuen Laufzeitumgebung kann Banking direkt auf Core verweisen. Im Kontext von Spring-Boot sind Banking und Core jeweils Spring-Beans. Für Banking wird wieder eine HTTP-Schnittstelle angelegt, die in der Legacy-Umgebung verwendet werden kann.
Zielzustand
Im letzten Schritt wird die Auftragsverwaltung migriert. Statt die Banking- und Core-Komponenten weiter per HTTP aufzurufen, kann die Auftragsverwaltung nun auch direkt die Spring-Beans verwenden (s. Abb. 7). Die HTTP-Schnittstellen werden damit überflüssig. Wenn es keine weiteren externen Systeme gibt, welche die Schnittstellen benötigen, können sie nun zurückgebaut werden.
API und Impl-Artefakte von Auftragsverwaltung, Banking und Core können zu einem einzelnen Artefakt zusammengefasst werden, welches als WAR deployt oder direkt als Fat-JAR gestartet werden kann. Damit ist die Legacy-Umgebung nun überflüssig und kann abgeschaltet werden.
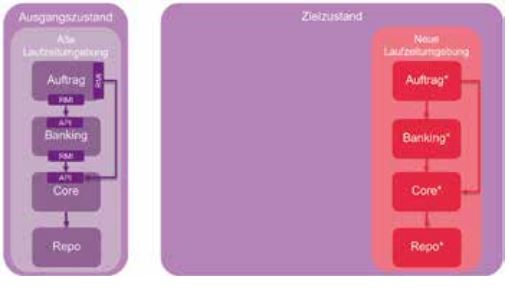
Abb. 7: Strangler-Pattern, Zielzustand
Fallstricke
Bei der Migration sind einige Fallstricke zu beachten.
Geringe Testabdeckung/Gefahr für den Betrieb
Wie eingangs erwähnt, ist eine ausreichende Testabdeckung kritisch für den Erfolg der Migration. Ist diese vor der Migration nicht ausreichend vorhanden, muss dies nachgeholt werden. Allerdings sollte man sich dabei nicht der Illusion hingeben, dass hier eine ausreichende Pfadabdeckung erreicht werden kann, um Migrations-bedingte Fehler auszuschließen.
Eine Möglichkeit, hier mehr Sicherheit zu erlangen, ist die Einführung eines „Schalters“, mit dem zur Laufzeit zwischen Legacy- und neuer Laufzeitumgebung gewechselt werden kann. Dieser Schalter muss in der Legacy-Umgebung implementiert und genutzt werden. Mögliche Realisierungsalternativen sind JNDI-Property, REST-Endpunkt oder Datenbank-Flag. So kann im Legacy-Umfeld bei jedem Zugriff auf eine Komponente die derzeitige Einstellung dieses Schalters geprüft (nutze neue Laufzeitumgebung: ja/nein) und dementsprechend gehandelt werden. Dadurch kann in einem Migrations-bedingten Fehlerfall ohne Rollback wieder die ursprüngliche Implementierung verwendet werden.
Dies bedeutet allerdings, dass, solange ein Schalter für eine Komponente benötigt wird, die Geschäftslogik für diese Komponente gedoppelt werden oder in einem Artefakt abgelegt werden muss, welches in der Legacy- und neuen Laufzeitumgebung nutzbar ist. Daher sollte nach Verifizierung der Lauffähigkeit in der neuen Laufzeitumgebung der Schalter und der Code in der Legacy-Umgebung entfernt werden.
Inkompatible Thirdparty-Libraries
Während der Migration wird es sich nicht vermeiden lassen, dass Komponenten sowohl mit der Legacy- als auch in der neuen Laufzeitumgebung kompatibel sein müssen. Dies gilt insbesondere für den Shared-Kernel und die API-Projekte.
Um potenzielle Versionskonflikte (unter anderem auch durch transitive Abhängigkeiten in Thirdparty-Libraries) zu vermeiden, wird die Verwendung einer Bill-of-Materials (BoM) empfohlen. Diese kann in Maven beispielsweise in Form einer POM realisiert werden, in der für alle relevanten Abhängigkeiten eine Version vorgegeben wird. Diese BoM kann dann im Dependency-Management der POMs aller betroffenen Artefakte im Scope „Import“ referenziert werden. Dies führt dazu, dass alle genutzten Abhängigkeiten (auch transitive) mit der vorgegebenen Version verwendet werden.
Seiteneffekt-behaftete Methoden
In Java werden Parameter generell via Pass-by-Value übergeben. Allerdings gibt es dabei eine Besonderheit: Im Falle von nicht-primitiven Datentypen wird nicht das Objekt selbst als Wert übergeben, sondern eine Kopie der Referenz-Variable. Sowohl die originäre als auch die kopierte Referenz-Variable zeigen jedoch auf das gleiche Objekt im Heap-Space. Wenn dieses Objekt im aufgerufenen Kontext geändert wird, ist die Änderung somit auch beim Aufrufer sichtbar.
Dieses Verhalten geht verloren bei der Verwendung von HT-TP, da hier lediglich JSON-Dokumente übertragen werden (quasi „hartes“ Pass-by-Value). Wenn in der neuen Anwendung ein übertragener Transfertyp geändert wird, geht diese Änderung verloren, wenn sie nicht explizit in der Response einbezogen wird.
Das heißt, ein aufrufender Kontext, der bisher Änderungen in Objekten erwartet hat, die einer aufgerufenen Methode als Eingabeparameter übergeben werden (Seiteneffekt-behaftet), wird keine Änderungen mehr sehen, wenn diese Methode nun migriert wird. Diese Seiteneffekt-behafteten Objekte müssen somit der Response hinzugefügt und beim Aufrufer explizit gemappt werden.
Migration als entwicklungsbegleitende Maßnahme
Es bleibt festzuhalten, dass Migrationen niemals im luftleeren Raum geschehen. Sie sind meist langwierig und müssen mit der laufenden Entwicklung in Einklang gebracht werden. Daher sollten neben dem hier vorgestellten Vorgehensmodell folgende Punkte beachtet werden:
- Während der ganzen Migration muss die Legacy-Umgebung kontinuierlich deploy- und (noch wichtiger) im Fehlerfall zurückrollbar bleiben.
- Die Anwendung wird während der Migration sowohl in der Le-gacy- als auch in der neuen Laufzeitumgebung weiterentwickelt. Das Team sollte sich dessen bewusst sein und sich dementsprechend koordinieren. Arbeitspakete müssen klar kommuniziert und Migrationsschritte transparent gemacht werden, sodass niemand sich die Frage stellen muss: „Wo muss ich mein neues Feature nun eigentlich implementieren? In der alten oder der neuen Welt?“
- Eine Fülle an Integrationstests zur Sicherstellung des Betriebs ist von elementarer Bedeutung.
- Nicht-funktionale Anforderungen dürfen nicht ignoriert wer-den. In hoch-performanten Systemen ist die Verwendung von HTTP für die Kommunikation zwischen Legacy- und neuer Laufzeitumgebung ggf. nicht schnell genug. Hier muss nach einer Alternative gesucht werden.
- Agile Methoden eignen sich besonders gut für die Umsetzung der Migration. Sie ist von Natur aus iterativ und kann daher in einzelne Sprints und kurze Feedback-Zyklen unterteilt werden.
Links
[CCD15]
https://clean-code-developer.de/die-grade/orangener-grad/#Separation_of_Concerns_SoC
[Fow04]
M. Fowler, StanglerFigApplication, 29.6.2004,
https://martinfowler.com/bliki/StranglerFigApplication.html
[Hoh19]
G. Hohpe, Enterprise Integration Patterns, 2019,
https://www.enterpriseintegrationpatterns.com/
[JP15]
Java Pass By Value and Pass By Reference, javapapers, 8.7.2015,
https://javapapers.com/core-java/java-pass-by-value-and-pass-by-reference/
[Mil19]
M. Milinkovich, Update on Jakarta EE Rights to Java Trademarks, 03.05.2019,
https://blogs.eclipse.org/post/mike-milinkovich/update-jakarta-ee-rights-java-trademarks
[Vos19]
T. Voß, Java EE ist tot – es lebe Spring (Boot)!, viadee, 13.9.2019,
https://blog.viadee.de/java-ee-ist-tot-es-lebe-spring
[Wig17]
A. Wiggins, The Twelve-Factor App, 2017,
https://12factor.net/








