

Beim letzten JVM Language Summit (JVMLS) im August 2024 hat Brian Goetz ein vielversprechendes Update gegeben, mit viel Humor, aber noch mehr beeindruckendem Inhalt. Sowohl Valhalla als auch Brian sind im Vergleich zu 2015 deutlich reifer geworden.
Dass die zehn Jahre in der Java-Welt wie im Flug vergangen sind, liegt nicht nur am beschleunigten Release-Zyklus mit vielen neuen Features und Verbesserungen, sondern auch an der Beschleunigung im Ökosystem der Softwareentwicklung von Cloud-basierten Architekturen, konsequenten CI/CD-Ansätzen und Entwicklungsumgebungen, die es Entwicklerinnen und Entwicklern auf vielfältige Art und Weise leichter machen, neue Sprachfeatures auch zu entdecken und umzusetzen. Valhalla hat in dieser Zeit unter verschiedenen Namen und sehr vielen Experimenten (sechs Prototypen) für die verschiedenen Aspekte von Konzeption, Typsystem, Migration, Sprachdesign und Implementierung in der Sprache und der JVM langsam Fortschritte gemacht.
In den letzten zwei Jahren hat sich aus zwei eigentlich tangentialen Ideen ein Denkansatz ergeben, der viele der bisherigen Komplexitäten und Probleme in sich selbst auflösen lässt. Da sind zum einen die Sichtbarkeit von teilweise initialisierten Objekten und zum anderen die Vermeidung von Null-Werten.
Brian vergleicht die Phasen der Entwicklung mit dem Hype-Zyklus von Gartner, wo man sich am Ende fragt: „Das ist doch alles ganz einfach und sinnvoll, warum hat das jetzt so lange gedauert?“
In diesem Artikel werden wir das Thema mit den neuen Erkenntnissen beleuchten und einen kleinen Test von Valhalla vornehmen. Listing 1 gibt einen kurzen Vorgeschmack, wie eine Value-Klasse (oder ein Value-Record) aussehen könnte.
value record Rectangle(double width, double height)
extends Shape {
@Override double area() { return width*height; }
@Override double circumference() { return 2*(width+height); }
}Eierpackung – Speichereffizienz in Java
Die Herausforderung, in Java speichereffizient zu arbeiten, gibt es seit den Anfängen in der Mitte der 90er. „Alles ist ein Objekt“ funktioniert nur dann performant, wenn die darunterliegende Implementierung es schafft, den Verschnitt durch Objekt-Header und -Zeiger bei Bedarf zu eliminieren.
Leider ist das in Java bisher nicht der Fall, sodass selbst reine Daten wie Zahlen oder Wahrheitswerte als Objekte mit sehr viel „Wasserkopf“ (16 Byte-Objekt-Header plus Verschnitt für Speicherausrichtung, 32- oder 64-Bit-Zeiger) repräsentiert werden müssten. Das ist auch der Grund, warum in der sonst so objektorientierten Sprache primitive Typen wie byte, int, float, booleanusw. als damals einzige Möglichkeit eingeführt werden mussten, um (numerische) Informationen kompakt abzulegen und effizient zu verarbeiten. Das hatte eine ganze Menge Sonderfälle zur Folge, von primitiven Arrays, Boxing, keine Generics für primitive Typen bis zu der unsäglichen Explosion von Interfaces für primitive Lambda-Functional Interfaces DoubleToIntFunctionund primitive Streams wie IntStream.
Somit wurde mit zweierlei Maß gemessen, auf der einen Seite hübsch objektorientiert und wartungsfreundlich mit Vererbung, Delegation, Interfaces, Konstruktoren usw., auf der anderen Seite effizient mit primitiven int-, byte - oder float-Arrays, ByteBufferund anderen low-level APIs, die die Rohdaten in einer effizienten Form für die Massendatenverarbeitung repräsentierten [2],[3]. Zwischen den beiden Welten muss aufwendig konvertiert werden und stets die Abwägung getroffen werden, wofür jeder Teil der Anwendung optimiert werden soll.
Mit einer effizienteren Repräsentation wird nicht nur Speicher für den Overhead gespart, durch den Verzicht auf Heap-Pointer, die auf mehr oder weniger zufällige Speicherbereiche zeigen, können die Daten in einem fortlaufenden Bereich abgelegt werden, was für Lade-, Aktualisierungs- und Cacheverhalten sehr vorteilhaft ist.
In anderen Sprachen wird die Objektorientiertheit für Werttypen nur simuliert, sodass sie unter der Haube keine Objekte sein müssen und die enthaltenden Container können als Sprachkonstrukt eines struct-Typs abgelegt werden, der auch keine Objekt-Identität benötigt.
Das ist auch die Idee für Java. Wie können wir Werttypen elegant der Sprache hinzufügen, sodass die meisten Features von Java erhalten bleiben und die JVM trotzdem ein effizientes Speicherlayout und Verarbeitung umsetzen kann? Dass Werttypen nicht dasselbe sind wie Objekte, ist hier der Grundgedanke. Einige der Eigenschaften von Objekten sind nicht immer notwendig und könnten bei Wegfall viele Optimierungen erlauben.
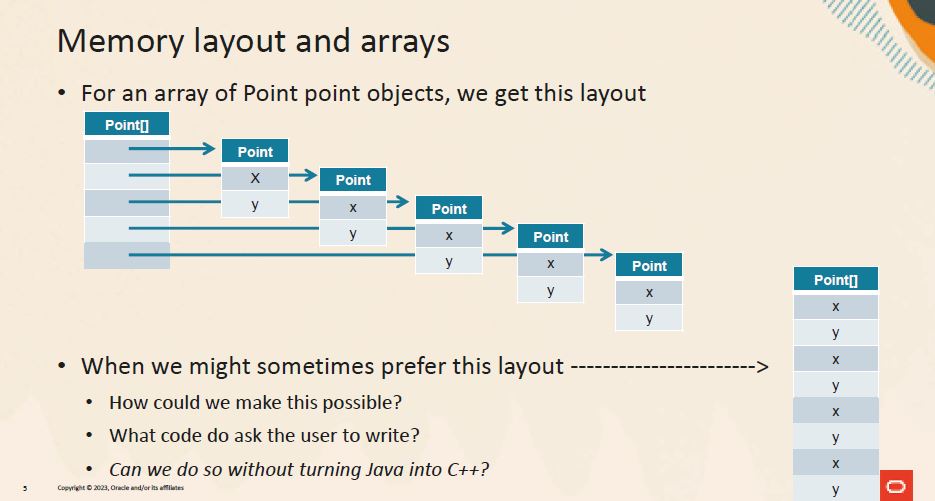
Abb. 1: Speicherlayout, Quelle: B. Goetz, DEVOXX
Wie auch in „Domain-Driven Design“, wo zwischen „lebendigen“ Entitäten mit Identität, Lebenszyklus und Verantwortlichkeiten und den skalaren, unveränderlichen Werttypen, die keine Identität besitzen und nur durch ihre Inhalte bestimmt sind, unterschieden wird.
Ein Vorteil von Werttypen ist, dass ihre Instanzen zum Beispiel in einem Array gar nicht mehr gespeichert werden müssen, nur noch die enthaltenen Werte, das wird auch als „Heap flattening“ bezeichnet, sowohl bei der Speicherung als auch bei Aufrufen, wo sie dann auf dem Stack oder noch effizienter in Registern landen können. Solche Optimierungen werden zum Beispiel auch vom Graal-Compiler als Teil der aggressiven JIT-Kompilierung vorgenommen.
Was bisher geschah – wichtigste Aspekte der Werttypen
Die genannte Inkonsistenz von Java war den Sprachdesignern schon immer ein Dorn im Auge, und die mangelnde Speichereffizienz gab Java lange den Ruf, langsam und verschwenderisch zu sein. Daher wird seit Langem untersucht und experimentiert, wie das Problem gelöst werden kann, ohne dass die Rückwärtskompatibilität von Java gefährdet wird und ohne Neuimplementierung des JDK für Werttypen und der Beibehaltung von Generics.
In den letzten zehn Jahren wurden im Rahmen des Valhalla-Projekts mehrere Aspekte in diversen Prototypen untersucht. Insgesamt gilt es, eine Reihe von Problemen zu lösen:
- Welche Objekteigenschaften sind wirklich wichtig oder könnten optional sein, zum Beispiel Identität, Veränderlichkeit?
- Was geschieht mit Null-Werten?
- Wie sieht die Initialisierung von Werttypen aus, besonders auch von Arrays?
- Wie können existierende Typen wie
IntegeroderLocalDatekompatibel migriert werden? - Welche Optimierung kann die JVM unter der Haube vornehmen?
- Wie verhält es sich mit Generics?
- Was ist mit Serialisierung?
- Gibt es weitere Themen, wie Operator Overloading?
- Was passiert mit dem Speichermodell und atomarem Zugriff?
Dabei wurde sowohl mit komplexen Änderungen an JVM, Sprache, Compiler und Laufzeitumgebung (VLOAD/VLSTORE-Bytecodes), Typsystem (L-World – angeglichene Typdeskriptoren) und einem schnellen, aber komplexen Programmiermodell (jeweils zwei Typen Class.val und Class.ref), das auch die Migration existierenden Codes sehr schwierig gemacht hätte, experimentiert. In anderen Prototypen wurde untersucht, wie sich Werttypen auf das Typsystem und Generics auswirken würden. Jeder Schritt brachte neue Erkenntnisse, aber keinen wirklichen Durchbruch.
Das Ziel war ja schließlich ein sauberes Programmiermodell, das kompatibel zu existierendem Code ist und trotzdem all die notwendigen Optimierungen möglich macht.
Wohin mit den Objekten?
Wie schon erwähnt, haben Objekte eine Reihe von Eigenschaften, die nützlich, aber nicht immer notwendig sind.
Identität oder nicht, das ist die Frage,
Das Hauptproblem stellt Identität dar, eine Entität mit Identität muss man stets nachverfolgen können und ihre Einzigartigkeit bewahren. Identität wird nicht nur zum Zugriff und Vergleich von Referenzen genutzt, auch für Objektlayout, Speicherposition, Garbage Collection, Veränderlichkeit, Polymorphismus und Synchronisation/Locks ist sie vorteilhaft. Daher sind auch die Instanz/ Wert- (equals) und Referenzgleichheit (==) nicht dasselbe. Ersteres bezieht sich auf den Zustand (also meist die Werte), aber Zweiteres auf die Identität.
Aber benötigen Werttypen all dies? Was wäre möglich, wenn es diese Garantien nicht mehr gäbe. Dann hätte die JVM viel mehr Möglichkeiten, die Objekte als identitätsfreie Container von Werten zu betrachten, zu kopieren und auseinanderzunehmen. Objektreferenzen wären nur noch virtuell und soweit es möglich ist, würden Werte direkt gespeichert, bei Erzeugung, Methodenaufrufen oder Rückgaben direkt in Registern oder im Stack abgelegt, ohne den Objektrahmen zu benötigen.
Bei Instanzen von Werttypen sind Instanz- und Referenzgleichheit dasselbe, da sie keine Identität mehr haben und nur ihre Werte für den Vergleich relevant sind. Das heißt aber nicht, dass Werttypen nur dumme Container darstellen müssen, man kann sie trotzdem mit Methoden, Konstruktoren, Vererbung, Interfaces und mehr versehen, das sind ja Sprachkonstrukte, die zur Laufzeit dann nur über die Werte gestülpt werden können. Damit können auch existierende Typen im JDK ihre API behalten (z. B. Zahlen, Strings, Zeitwerte, Cursors, Netzwerkinformationen) und trotzdem effizient zu Werttypen migriert werden.
Im aktuellen Prototyp [4] kann man mit dem Schlüsselwort value vor Klassen und Records auf die Objektidentität verzichten und damit einige der genannten Vorteile schon erhalten. Es werden trotzdem Konstruktoren, Vererbung (vonObject oder abstrakten Werttypen) und Interfaces unterstützt. Aber Objekte sind ja auch noch veränderlich.
Konstante Ansichten – Unveränderlichkeit
Das heißt, Feld-Werte können einmal geschrieben werden und sind dann in allen Referenzen des Objekts aktuell (nach den Sichtbarkeitsregeln des Java-Speichermodells natürlich). Unveränderliche Werte wären viel besser, diese könnten beliebig kopiert werden, dann ergibt sich die Notwendigkeit nicht mehr, allen „Instanzen“ einen aktualisierten Wert bereitzustellen.
Ein Problem für das Flachklopfen im Heap, Stack und in Registern stellen auch veränderliche Instanzen dar, die auf unveränderliche Instanzen zeigen, und vice versa. Daher wäre es notwendig, an diesen Stellen durchgängig Unveränderlichkeit zu garantieren. Des Weiteren haben unveränderliche Werte den Vorteil, dass sie nicht von Race-Conditions beim Laden von Werten betroffen sind, die größer als die atomaren Garantien des Prozessors sind (Tearing) (heute meist 64 Bit, früher nur 32 Bit, was zu Problemen bei long- und double-Werten führte). Durch Vermeidung von Objekt-Allozierungen für den Objekt-Container können unveränderliche Werte trotzdem hochperformant „erzeugt“ werden.
Ein Beispiel von Brian Goetz ist ein Cursor, der eine Referenz auf ein Feld und einen Offset speichert, welcher bei Iteration unveränderlich erhöht wird, indem ein neuer Cursor erzeugt wird, siehe Listing 2.
value record ArrayCursor<T>(T[] base, int offset) {
boolean hasNext() { return offset < base.length; }
ArrayCursor<T> advance()
{ return new ArrayCursor(base, offset+1);}
T get() { return base[offset]; }
}
for (var c = new ArrayCursor<>(arr, 0);
c.hasNext(); c = c. advance()) {
T value = c.get()
}Wohin mit der Null – Nullability & Null Restricted Types
Im Vortrag beim JVMLS hat Brian Goetz von einem Durchbruch berichtet, der aus einer etwas unerwarteten Ecke kam und plötzlich viele Herausforderungen vereinfachte. Ein Thema, das die Software Community seit Längerem beschäftigt, sind Null-Pointer, von ihrem Erfinder Tony Hoare auch als „Billion Dollar Mistake“ bezeichnet. Da Werttypen keine Identität und Referenzen haben, kann man auch keinen Null-Pointer für sie speichern, sie sind ja durch den Inhalt ihrer Werte bestimmt und der ist eben nicht Null. Wie verhält es sich nun aber, wenn die Instanz noch nicht existiert? Gibt es das überhaupt, und was müsste man dann anstatt Null benutzen? In einem früheren Prototypen wurde versucht, Null komplett zu verbieten, aber das hatte zu viele Einschränkungen bei der Kompatibilität und Migration. Gegebenenfalls müsste man ein Extra-Bit für diesen Zustand reservieren, das dann bei vielen Typen zu einer Verdopplung des Speicherbedarfs führen würde. Da Speicher auf 32 oder 64 Bit aligned sein sollte, müssten dann 64 statt 32+1 oder 128 statt 64+1 Bits belegt werden.
Für die primitiven Typen werden die Standardwerte wie 0 oder false benutzt, aber diese tragen ja auch eine Bedeutung im Wertebereich. Es ist aber schwierig, diese für komplexere Typen automatisch zu inferieren, da deren „Standardwert“ an einem anderen Punkt der Wertebereiche liegen kann.
Daher ist der Vorschlag des JVM-Teams jetzt, dass Initialwerte für Werttypen immer vom Nutzer mit anzugeben sind, sodass die Initialisierung sofort mit diesen vorgenommen wird und keine inferierten Defaultwerte nötig sind [5]. Dasselbe soll auch für Felder von Werttypen gelten, diese können dann über ein neues Konstrukt mit einem Initialwert oder einem Lambda-Ausdruck befüllt werden, siehe Listing 3.
String![] labels;
labels = new String![]{ "x", "y", "z" };
labels = new String![100]{ "" }; // suggested syntax
labels = new String![100]{ i -> "x"+i }; // suggested syntaxDas zweite große Thema, das mit den Annotationen @Null und @NotNull schon einmal vorsichtig angefangen wurde, ist generell die Nullability (Optionalität) von Feldern, Parametern und Variablen. Hier ist jetzt der Vorschlag [6], dass neben dem bisherigen Typ name auch explizit Null-fähige Deklarationen mit einem Fragezeichen Typ? name und explizites Verbot von Null mit einem Ausrufezeichen Typ! name möglich sein sollen. In anderen Sprachen gibt es ähnliche Konstrukte, original kommen diese Quantifier aus regulären Ausdrücken.
Dieser Ansatz soll es erlauben, auch existierende Software und Bibliotheken weiterzuverwenden, ohne sie neu zu übersetzen oder zu aktualisieren (dann ohne die Vorteile), sodass die Migration schrittweise erfolgen kann. Initial soll das allgemein für alle Typen erfolgen, in einem zweiten Schritt speziell für Werttypen [5].
Damit haben die JVM (Verifier) und die Runtime dann die Möglichkeit, die notwendigen Verifikationen, Inferenzen und auch Optimierungen (wie der Verzicht auf das Extra-Bit für Werttypen und Möglichkeit des Zerlegens) vorzunehmen.
Initialisierung und Sichtbarkeit
Die Initialisierung von Objekten kann in Java je nach geforderten Invarianten schwierig sein. Während ein Objekt initialisiert wird, entspricht es nur teilweise den geforderten Invarianten. Die Sichtbarkeit dieser partiell initialisierten Objekte wird von der Sprache und Runtime beschränkt, ist aber nicht wasserdicht. Um die Initialwerte für nicht-nullfähige Werttypen zuzuweisen, muss das erfolgen, bevor der Superklassen-Konstruktor aufgerufen wird.
Das Thema wird auch in JEP 482 [7] relevant, der sich mit mehr Möglichkeiten von Konstruktoren (Code vor den Superklassen-Konstruktor-Aufrufen) beschäftigt. Die Idee ist zum einen, die Sichtbarkeit dieser unvollständigen Objekte zu verhindern (mittels DA-Analyse, „Definite Assignment“) beziehungsweise sie vorzeitig zu befüllen. Felder, für die Null keinen erlaubten Wert darstellt, dürfen nie mit Null sichtbar sein, selbst wenn die JVM sie temporär so initialisiert. Auch bei der Deserialisierung stellt das ein Problem dar, da hier zuerst Objekte ohne initialisierte Felder erzeugt und diese dann nachträglich befüllt werden, sodass „illegale“ Zustände möglich sind.
Es gibt zurzeit Arbeit an Serialisierung, diese wird sich aber noch hinziehen. Bis dahin werden Werttypen nicht serialisierbar sein.
Mit diesen neuen Bedingungen konnten viele der vorher notwendigen Änderungen entfernt werden, wie die neuen Bytecodes oder Typdeskriptoren. Notwendig bleiben nur ein ACC_VALUE-Flag für Klassen und ein ACC_STRICT-Bit sowie ein NullRestricted -Attribut für Instanzvariablen.
Integration mit Objekten und Garbage Collection
Werttypen können trotzdem in Objekten enthalten sein. Im ersteren Fall werden ihre Werte in das Objekt hineingeschrieben und nicht als Referenz gehalten. Das heißt, wenn das Objekt vom Garbage Collector entfernt wird, muss für die Wertobjekte, wie heute schon für primitive Werte, keine Extra-Arbeit vorgenommen werden. Da jedes Wertobjekt nur relativ klein ist, macht es minimalen Platzunterschied innerhalb eines Objekts. Listen oder Felder von Wertobjekten werden wie schon heute als Referenzen gehalten, aber dann innerhalb des Felds flach geklopft und internalisiert. Sie können auch Referenzen zu Objekten enthalten, also nur den Pointer auf das Objekt. Es hat erst einmal für das Wertobjekt keine Bedeutung, welche Bedeutung dieser 32- oder 64-Bit-Wert hat.
Für den Garbage Collector bedeutet es schon einen Mehraufwand, weil er ja potenziell an mehr Stellen und durch größere internalisierte Datenmengen durchlaufen muss, was bisher nur bei objektbasierten Strukturen (Feld von Strings mit Zeiger auf char[]-Felder) notwendig war und dementsprechend teuer. Für primitive Werte gab es diesen Fall ja nicht (int[]). Daher denke ich, ist eher davon abzuraten, in Werttypen Referenzen auf Objekte zu halten.
Der letzte Streich – JDK-Klassen und Migration
InJEP 402 wird diskutiert, wie die existierenden Kandidaten für Werttypen im JDK angepasst werden können, wahrscheinlich in mehreren Schritten. Das sind zum einen Partnerklassen für primitive Werte wie Integer! oder Double! , für die würde das Boxing als spezifische Operation wegfallen, sie würden direkt durch ihre konstituierenden Werte dargestellt.
Wie die Zukunft der primitiven Typen aussieht, ist ungewiss, aber es ist unwahrscheinlich, dass sie je aus Java verschwinden werden, jedes Java-Programm enthält viel zu viele davon. Aber gegebenenfalls werden sie in Zukunft nur noch Aliase für die Werttypen sein.
Andere geplante Migrationen sind, die Nullfähigkeit an Signaturen und für Instanzvariablen zu vermerken, zum Beispiel für Klassen, die heute schon NotNull-Überprüfungen für Parameter vornehmen und damit sicherstellen, das diese Werte nicht Null werden können. Diese würden dann manuell oder per Inferenz transient durch das JDK und die JVM propagieren. Null für so deklarierte Werte zu nutzen, würden dann entweder zu einem Compiler-Fehler oder zu Null-Pointer Exceptions zur Laufzeit führen. Wie immer ist in Java binäre und Quelltextkompatibilität sehr kritisch, daher wird dies nur in Schritten erfolgen.
Offene Fragen sind noch Kovarianz (Zuweisbarkeit) von Feldern int[] vs. Integer![] , wie primitive Typen als Methodenempfänger agieren können und wie generische Typargumente abgebildet werden.
Ein kleiner Test
Laut Brian Goetz ist die erreichte Performance-Verbesserung schon beeindruckend:
- Matrix-Multiplikation ist 6x schneller bei einer Reduktion der Speicherallokation um einen Faktor 100.
- Iteration über ein Array ist im for-loop 3-x schneller, mit Streams sogar 12x.
- Besonders hat Brian die 8x schnellere Berechnung von Aggregaten mit einem unveränderlichen Akkumulator (also Neuerzeugung und Zuweisung) hervorgehoben.
Da der Valhalla-Build von Java 23 jetzt verfügbar ist, können wir auch zumindest einen kleinen Performancetest machen. In Erinnerung an den Beginn meiner Programmierkarriere vor fast 40 Jahren (autsch) in Basic und Maschinencode nehme ich eine Liste von geometrischen Figuren und lasse deren Flächeninhalte berechnen, wir lassen ihre Größe wachsen, bis wir 100 Millionen neuer Objekte abgeleitet haben, siehe Listing 4 und 5.
class ValhallaTest {
interface Shape {
double area();
double circumference();
Shape derive(double multiplier);
}
// das Schlüsselwort *value* ist hier der einzige Unterschied
// im Quelltext, sonst muss nichts geändert werden
value record Rectangle(double width, double height)
implements Shape {
Override
public double area() {
return width*height;
}
@Override
public double circumference() {
return 2*(width+height);
}
@Override
public Rectangle derive(double multiplier) {
return new Rectangle(width*multiplier, height*multiplier);
}
}
public static void main(String...args) {
// warmup
for (int i=0;i<10;i++) {
benchmark(PrintStream.nullOutputStream());
}
benchmark(System.out);
}public static final int SIZE = 100_000_000;
public static final double MULTIPLIER = 1;
// 1.001; Multiplikation dominiert Erzeugung
private static void benchmark(OutputStream os) {
var printStream = new PrintStream(os);
var start = System.currentTimeMillis();
Shape[] shapes = new Rectangle[SIZE];
shapes[0]=new Rectangle(Math.E,Math.PI);
for (int i = 1; i< SIZE; i++) {
shapes[i]=shapes[i-1].derive(MULTIPLIER);
}
var time = System.currentTimeMillis();
printStream.printf("Creating %d shapes took %d ms%n",
SIZE, time - start);
start = System.currentTimeMillis();
double res = Stream.of(shapes).mapToDouble(
s -> s.area() + s.circumference()).sum();
printStream.printf(
"Stream Computing area and circumference of %d shapes took %d ms sum is
%.2f%n",
SIZE, time - start, res);
start = System.currentTimeMillis();
res = 0;
for (int i = 0; i< SIZE; i++) {
res += shapes[i].area();
res += shapes[i].circumference();
}
time = System.currentTimeMillis();
printStream.printf(
"Computing area and circumference of %d shapes took %d ms sum is
%.2f%n",
SIZE, time - start, res);
start = System.currentTimeMillis();
boolean same = false;
for (int i = 1; i< SIZE; i++) {
same |= shapes[i] == shapes[i-1];
}
time = System.currentTimeMillis();
printStream.printf(
"Comparing %d shapes took %d ms are any of them the same %s%n",
SIZE, time - start, same);
start = System.currentTimeMillis();
same = false;
for (int i = 1; i< SIZE; i++) {
same |= shapes[i].equals(shapes[i-1]);
}
time = System.currentTimeMillis();
printStream.printf(
"Comparing %d rectangles took %d ms are any of them the
equal %s%n",
SIZE, time - start, same);
printStream.println("recs[SIZE-1] = " + shapes[SIZE - 1]);
}Das Ganze wird einmal mit Wert-Records und einmal mit regulären Objekt-Records implementiert, sodass wir den Geschwindigkeitsunterschied beim Erzeugen und Berechnen sehen können.
In den Ergebnissen in Listing 6 wird Folgendes deutlich:
- Erzeugung von Werttypen ist etwas schneller, das ist aber abhängig vom Typ des Felds, beim konkreten Werttyp
Rectangle[]ist es schneller, bei dem Interface-TypShape[]nicht. - Multiplikation dominiert die Erzeugung, das heißt, wenn der Multiplier != 1 also nicht herausoptimiert werden kann.
- Stream-Verarbeitung ist etwas schneller für Werttypen, die For-Schleife ist ungefähr genauso schnell.
- Referenz und Wertvergleich bei Wertobjekten ist dieselbe OpeOperation, dauert also dieselbe Zeit und sie sind immer gleich, wenn sie dieselben Werte haben.
- Bei regulären Objekten ist der Referenz-Vergleich (Pointer) viel schneller und niemals gleich. Beim deutlich langsameren Wertvergleich ist das anders.
// Value type record:
Multiplier: 1
Creating 100000000 shapes took 540 ms
Stream Computing area and circumference of 100000000 shapes took 510 ms
sum is 2025948318,68
Computing area and circumference of 100000000 shapes took 190 ms sum is
2025948315,82
Comparing 100000000 shapes took 117 ms are any of them the same true
Comparing 100000000 rectangles took 116 ms are any of them the equal
true
recs[SIZE-1] = Rectangle[width=2.718281828459045,
height=3.141592653589793]
// Regular Records (reference equality faster than value equality)
Multiplier: 1
Creating 100000000 shapes took 654 ms
Stream Computing area and circumference of 100000000 shapes took 575 ms
sum is 2025948318,68
Computing area and circumference of 100000000 shapes took 193 ms sum is
2025948315,82
Comparing 100000000 shapes took 19 ms are any of them the same false
Comparing 100000000 rectangles took 267 ms are any of them the equal
true
recs[SIZE-1] = Rectangle[width=2.718281828459045,
height=3.141592653589793]Ein weiterer interessanter Test wäre die Baseline-Implementierung der 1 Billion Row Challenge aus einer der letzten Folgen mit den Valhalla-Werttypen umzusetzen und die Leistungsänderung zu bewerten. Ich habe das mit Gunnar Morlings Code gemacht, eigentlich nur das Schlüsselwort value für die Measurement -, ResultRowund und MeasurementAggregator-Records genutzt. Im Ergebnis hat sich die Laufzeit von 3:24 Minuten zu 3:36 Minuten verändert, also nicht wirklich verbessert.

Abb. 2: Peak of Complexity, Quelle: B. Goetz, DEVOXX
Fazit
Ich freue mich, dass das Team jetzt einen Durchbruch erreicht hat, und hoffe, dass wir Werttypen als Preview Feature in Java 24 bekommen, vielleicht sogar schon mit einigen der weiterführenden Aspekte in den (Draft) JEPs. Dies würde viele Verbesserungen sowohl für die JDK-eigenen Typen als auch Massendatenverarbeitung ermöglichen, man denke nur einmal an Datenbanken (Neo4j, Cassandra, Elastic) und DV-Systeme (Databricks, Spark, Flink, Kafka, Hadoop), die in Java implementiert sind.
Mich erinnert die Valhalla-Geschichte etwas an die Entwicklung von LINQ (Language INtegrated Query) in .NET, die Anders Hejlsberg mal bei einer JAOO so zusammengefasst hat: Wir haben zehn individuell nützliche Sprachfeatures nach und nach entwickelt, sodass LINQ zum Schluss nur aus der Anwendung dieser Bausteine zusammengesetzt werden konnte. Brian Goetz fasst es so zusammen: Leistung kommt von klarer Struktur und Semantik, dann können die Optimierungen sicher unter der Haube erfolgen. Es hilft, auf unnötigen Freiheiten zu verzichten, um Optimierungspotenzial zu erhalten (Beschränkungen sind oft hilfreich).
Mit dem verfügbaren Build kann man jetzt schon selbst testen, was für Auswirkungen ein kompaktes Speicherdesign für die eigenen Anwendungen haben kann. In fernerer Zukunft stehen noch Themen wie Operator-Overloading an. Da soll Java einen konzeptionell besseren Ansatz erhalten als andere Sprachen, zum Beispiel mittels Typklassen, die die Operatoren gruppieren.
Literaturverzeichnis
[1] M. Hunger, Value Types in Java 10, in: JavaSPEKTRUM, 3/2017
[2] M. Hunger, Kompakte Datenstrukturen in Java, in: JavaSPEKTRUM, 5/2020, s. a. www.sigs.de/artikel/kompakte-datenstrukturen-in-java/
[3] M. Hunger, Massenverarbeitung in Java – Teil 1: Einstieg, in: JavaSPEKTRUM, 3/2024, s. a. www.sigs.de/artikel/massenverarbeitung-in-java-der-einstieg/
[4] JEP 401, Value Classes and Objects (Preview), openjdk.org/jeps/402
[5] Draft JEP – Null-Restricted Value Class Types (Preview), bugs.openjdk.org/browse/JDK-8316779
[6] Draft JEP – Null-Restricted and Nullable Types (Preview), bugs.openjdk.org/browse/JDK-8303099
[7] JEP 482: Flexible Constructor Bodies (Second Preview)
[8] Projektseite von Valhalla, openjdk.org/projects/valhalla









