

Wer ist noch nicht im eigenen Code oder im Repository des Teams über Passwörter im Klartext gestolpert? Das führt zu der Frage: Wo und wie lassen sich solche Credentials sicher ablegen?
Dass Klartextpasswörter in Code-Repositorys ein großes Problem darstellen können, wird schnell klar: Stehen sämtliche Passwörter zur produktiven Server-Infrastruktur im Repo, hat entsprechend jeder Kollege mit Zugriff auf dieses Repo potenziell die Möglichkeit, auf diese Produktiv-Infrastruktur zuzugreifen. Das widerspricht den grundlegenden Sicherheitskonzepten „Least Privilege“ und „Need to Know“. Und nutzt das Projekt gar ein öffentliches Repo, beispielsweise auf GitHub, ist es wahrscheinlich, dass die Server dann auch kompromittiert werden. Ein Blick auf Presseartikel wie „Haufenweise geheime AWS-Schlüssel auf GitHub entdeckt“ [Sche14] zeigt, dass solche Szenarien durchaus vorkommen.
Ein Grund hierfür ist, dass Softwareprojekte Build und Deployment stetig weiter automatisieren. Server werden nicht mehr manuell konfiguriert, sondern durch Skripts. Und diese liegen dann für eine flexible und unkomplizierte Handhabe durch die Entwickler im Repository – inklusive aller nötigen Passwörter, wenn darauf nicht geachtet wird.
Neben der Frage, wie das Team die Vertraulichkeit sensibler Daten wie Credentials gewährleistet, sollte es den Build-Prozess zudem so ausgestalten, dass die Integrität der gebauten Software nicht gefährdet ist. Zum einen müssen dazu Manipulationen bei der Auslieferung der Build-Artefakte möglichst ausgeschlossen sein. Und zum andern sollte das Einbinden bösartigen Codes verhindert werden. Letzteres ist vor allem durch das Einbinden vieler kleiner Bibliotheken (die dann wiederum unbekannte weitere Bibliotheken nachladen) über Paketmanager wie npm ein immanentes Sicherheitsproblem, wie viele Berichte von Malware in Paketen dort zeigen (z. B. [Cim17] und [Schi18-b]). Aber auch ein kompromittierter GitHub-Account kann dazu führen, dass bösartiger Code im Repo landet (Real-World-Beispiele finden sich in [Schi18-a] und [Wit19]).
Dieser Artikel betrachtet also die primären Schutzziele Vertraulichkeit und Integrität innerhalb einer klassischen Build-Chain: Welche Fragestellungen dabei relevant sind und welche Ansätze zur Gewährleistung dieser Schutzziele existieren.
Vertraulichkeit von sensiblen Daten in Repos und Artefakten
Neben Passwörtern für Datenbanken und Ähnlichem gehören unter anderem auch API-Tokens, Zertifikate und deren private Schlüssel zu den besonders schützenswerten Daten, die nicht im Entwicklungs-Repository auftauchen sollten. Im Optimalfall erkennt das Team diese Fälle schon beim Spezifizieren neuer Anforderungen und kann sichere Alternativlösungen finden, noch bevor solch sensible Daten im Repo landen. Oft läuft das Projekt allerdings schon länger und hat bereits eine große Codebasis aufgebaut. Dann fällt der Überblick, ob und wo Passwörter im Code auftauchen, oft schwer.
Identifikation von sensiblen Daten in Repos
Dennoch sollte sich das Team im ersten Schritt einen Überblick darüber verschaffen, wo sensible Daten verwaltet werden. Gängige Code-Qualitäts-Tools oder auch spezifische Werkzeuge zum Erkennen von Passwörtern können dabei unterstützen, meist mittels vorkonfigurierter Regulärer Ausdrücke. In der laufenden Entwicklung bietet es sich auch an, solche Checks als Commit-Hook zu integrieren, um das versehentliche Einchecken von Passwörtern zu verhindern.
Identifikation von sensiblen Daten in Artefakten
Dass sensible Daten wie Passwörter unter Umständen auch in Build-Artefakten auftauchen, darf dabei nicht außer Acht gelassen werden. Der hart-codierte Datenbank-Connection-String, zum Beispiel, steht sicherlich auch in der compilierten Software, die der Kunde später auf einem Server deployt. Und je nachdem, wie Projektinfrastruktur und -prozesse aussehen, landet die kompilierte Software nicht direkt auf dem Zielserver, sondern zunächst in einem Software-Repository.
Entsprechend sollte das Team stets einen Überblick über sensible Daten haben, die in der compilierten Software stehen, analog zu Passwörtern im Quelltext. Gelingt das nicht, wäre ein Worst-Case-Beispiel, dass eine App in die Appstores gelangt, die API-Tokens oder Ähnliches enthält, welche Zugriff auf schützenswerte Ressourcen ermöglichen.
Abschätzen der Exponiertheit
Die zwei Extremfälle „Die eigene App mit sensiblem API-Token steht im Appstore“ und „Das Datenbankpasswort landet auf dem eigenen Server“ unterscheiden sich natürlich in der Anzahl der Personen, die darauf zugreifen können. Im besten Fall nur eine Handvoll vertrauenswürdiger Kollegen, im schlechtesten Fall die gesamte Welt.
Einschränken der Exponiertheit
In vielen Fällen lässt sich diese Exponiertheit bereits unkompliziert einschränken. Vor allem der Zugriff auf Repositorys, sowohl für den Quelltext als auch für Artefakte, sollte streng geregelt sein.
Im Optimalfall sind Credentials sogar für Entwickler gar nicht direkt verfügbar – nur im Build oder zur Laufzeit für die Systeme, welche diese unbedingt benötigen. Zudem sind die Credentials auf einem vertrauenswürdigen, streng zugangsbeschränkten System verschlüsselt abgelegt.
Sicherstellung der Nachvollziehbarkeit
Neben der Möglichkeit von Zugangsbeschränkungen muss ein System zur Speicherung von Credentials sämtliche Zugriffe und Änderungen loggen können, um potenzielle Sicherheitsprobleme aufklären zu können.
Einrichten von Reaktionsmechanismen
Sollte doch mal ein Schlüssel kompromittiert sein, muss dessen Austausch leicht umsetzbar sein, optimalerweise ohne einen Neustart des Systems, das diesen Schlüssel nutzt. Generell empfiehlt sich eine solche Key-Rotation sogar präventiv in regelmäßigen Abständen.
Zusammenfassung: sichere Passwörterverwaltung
Entsprechend sollte ein konzeptionell sicheres System zur Verwaltung von Passwörtern und Ähnlichem in der Build-Chain folgende Möglichkeiten bieten:
- A Verschlüsselung/Nichtverfügbarkeit der Credentials
- B Audit-Logs
- C Schlüsselrotation
Lösungsansatz A – Credentials Injection @ Build Time
Gängige CI/CD-Server bieten die Möglichkeit, Passwörter und Ähnliches sicher in einem Credentials Store abzulegen. Dort liegen sie meist verschlüsselt vor (solange der Service nicht läuft bzw. die Passwörter nicht benötigt werden) und können von Nutzern nicht direkt eingesehen werden. Im Build-Skript werden diese Passwörter dann über einen Identifikator referenziert und beim Bauen der Software vom CI/CD-Server ersetzt (s. Abb. 1 und Listing 1).
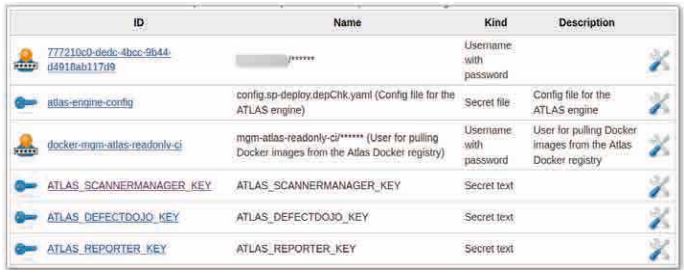
Abb. 1 : Credentials Injection @ Build Time am Beispiel von Jenkins
pipeline {
stages {
stage('ATLAS') {
steps {
withCredentials([usernamePassword(
credentialsId: 'docker-mgm-atlas-readonly-ci',
usernameVariable: 'UNAME',
passwordVariable: 'PASSWD')]) {
//do something with $UNAME and $PASSWD
}
...Je nach eingesetztem Tool erfüllt diese Lösung bereits zentrale Anforderungen, vor allem die Nichtverfügbarkeit der sensiblen Daten im Code-Repo. Auch ein Austausch von Passwörtern zentral im Build-Server kann deutlich einfacher sein. Allerdings liefert eine solche Lösung in der Regel keine Audit-Logs.
Lösungsansatz B – Credentials Injection @ Run Time
Der Lösungsansatz, der alle aufgestellten Anforderungen erfüllt, ist das Injizieren von Credentials zur Laufzeit durch einen zentralen Server, der diese verwaltet. Neben Projekten wie HashiCorp Vault [Vault] bieten auch große Cloud-Anbieter dezidierte Server für genau diese Aufgabe.
Sämtliche Passwörter liegen dabei auf einem Credentials-Server – in verschlüsselter Form, solange sie nicht benötigt werden. Benötigt ein Webserver zur Laufzeit beispielsweise das Passwort, um sich auf eine Datenbank zu verbinden, fragt er den Credentials-Server nach dem entsprechenden aktuellen Passwort für diese Datenbank (s. Listing 2). Der Webserver authentifiziert sich dabei individuell am Credentials-Server, was Letzterem erlaubt, den Zugriff auf Credentials einzuschränken. Der Webserver wird also das Passwort zur produktiven Datenbank bekommen, während ein Entwickler im Team lediglich Passwörter zu Testdatenbanken abrufen können sollte. Die individuelle Authentifikation eines Systems am Credentials-Server geschieht mittels Nutzernamen und Passwort, welche diesem initial mitgeteilt werden müssen. Das kann entweder manuell geschehen (geeignet z. B. für Entwicklersysteme) oder per „Injection at Build Time“ durch den CI/CD-Server.
$ export VAULT_ADDR="https://localhost:8200"
$ ./vault operator init
Key 1:
7149c6a2e16b8833f6eb1e76df03e47f6113a3288b3093faf5033d44f0e70fe701
Key 2:
901c534c7988c18c20435a85213c683bdcf0efcd82e38e2893779f152978c18c02
Key 3:
03ff3948575b1165a20c20ee7c3e6edf04f4cdbe0e82dbff5be49c63f98bc03a03
Key 4:
216ae5cc3ddaf93ceb8e1d15bb9fc3176653f5b738f5f3d1ee00cd7dccbe926e04
Key 5:
b2898fc8130929d569c1677ee69dc5f3be57d7c4b494a6062693ce0b1c4d93d805
Initial Root Token: 19aefa97-cccc-bbbb-aaaa-225940e63d76...
Secrets secrets = new Secrets();
secrets.username = "username";
secrets.password = newSecret;
vaultOperations.write("secret/myApp", secrets);
VaultResponseSupport<Secrets> response =
vaultOperations.read("secret/myApp", Secrets.class);
System.out.println(response.getData().getUsername());
...Durch die zentrale Verwaltung und das Abrufen der Credentials erst zur Laufzeit lässt sich eine Schlüsselrotation recht problemlos umsetzen. Ebenso kann der Credentials-Server zuverlässig jeden Zugriff und alle Änderungen an Passwörtern loggen.
Sonderfall: Team KeePass
Die oben beschriebenen technischen Lösungen zum Injizieren von Credentials behandeln jedoch einen Fall noch nicht: Passwörter, die Menschen zugänglich sein müssen, zur Build- oder Laufzeit nicht benötigt werden, oder aber in Backups aufgenommen werden sollten.
Für diese Fälle bietet sich eine verschlüsselte Passwortdatei an, die im Team geteilt wird, beispielsweise indem sie auf einem File-Share synchronisiert wird. Das entsprechende Passwort zu dieser Datei mit höchst schützenswerten Inhalten muss im Team kommuniziert werden, sollte aber natürlich ausreichend gut sein und von den Kollegen auch sicher verwahrt werden – möglichst in ihrem eigenen Passwortmanager.
Integrität von Artefakten
Nun ist die Vertraulichkeit sensibler Daten im gesamten Entwicklungsprozess bis hin zur Provisionierung und zum Deployment der Software möglichst gewährleistet. Aber ist dieser Prozess auch gegen Manipulationen gefeit? Wie kann der Kunde verifizieren, dass die Software während des Prozesses vom Build bis hin zur Auslieferung nicht verändert und unter Umständen mit bösartiger Funktionalität angereichert wurde?
Signieren?!
Eine sichere Lösung, um unerkannte Manipulationen auszuschließen, sind digitale Signaturen. Aus diesem Grund verlangen unter anderem die großen Appstores, dass sämtliche dort veröffentlichte Software digital signiert ist. In anderen Anwendungsfällen ist das Signieren von Software und Code allerdings noch nicht weit verbreitet. Hauptproblem an dieser Stelle ist neben minimalem Extraaufwand die Frage, ob eine solche Signatur überhaupt auf Empfängerseite geprüft wird. Trotzdem sollte das Signieren der eigenen Software immer angestrebt werden!
Hierbei sind aus dem in diesem Artikel behandelten Blick auf konzeptionelle Sicherheitsprobleme in der Build-Chain etliche Detailfragen relevant:
- Wer kann die Software signieren? Wer sollte das dürfen?
- Mit welchem Zertifikat? Persönliches vs. Organisationszertifikat?
- Wo liegen dieses Zertifikat und der zugehörige private Schlüssel?
- Wie exponiert ist das Zertifikat bezüglich seines Schutzbedarfs?
Prozess wenig angreifbar machen!
Unabhängig davon, ob man Software signieren kann oder möchte, sollte darauf geachtet werden, den Prozess vom Build bis zur Auslieferung möglichst wenig angreifbar zu machen. Diese Aufgabe ist im Detail natürlich von Projekt zu Projekt unterschiedlich, beinhaltet aber immer ein Erwägen unter anderem der folgenden Aspekte:
- Wer kann die Software bauen? Wer kann sie ausliefern? Wer kann sie theoretisch zwischen Build und Auslieferung manipulieren? Berechtigungen prüfen!
- Vor dem Hintergrund des Sicherheitsprinzips „Least Privilege“: Zahl der Berechtigten senken!
- Sichere Freigabeprozesse, zum Beispiel per 4-Augen-Prinzip!
Vertrauen in Quellen
Während Vertrauen in den Prozess der Software-Provisionierung oft relativ zuverlässig aufgebaut werden kann, ist ein weiterer, meist deutlich unübersichtlicherer Aspekt essenziell für die Integrität der Software-Artefakte: Vertrauen in die eingebundenen Quellen.
Hier gilt es, folgende Problemszenarien zu beachten und durch vorbeugende Maßnahmen zu vermeiden.
Kompromittierter Entwickler-Account
Dieser Fall tritt durchaus häufig auf, vor allem natürlich in öffentlich erreichbaren Code-Repositorys, wie unter anderem Beispiele bei großen Linux-Distributionen zeigen [Schi18-a, Wit19].
Um das möglichst unwahrscheinlich zu machen und im Worst Case die Auswirkungen gering zu halten, bieten sich folgende Maßnahmen an:
- Multifaktorauthentifizierung (z. B. in GitHub problemlos möglich)
- Commits signieren (von git via PGP Out-of-the-Box unterstützt)
- Angriffsfläche verringern: Repo im Intranet, keine überflüssigen Nutzer, restriktive Berechtigungen, ...
Einbinden kompromittierter Software
Praktisch jedes Entwicklungsprojekt verwendet auf mehreren Ebenen Drittsoftware, vom Nutzen vorkonfigurierter Container-Images oder Ähnlichem bis hin zum Einbinden vieler kleiner Bibliotheken. Um sichere Software auszuliefern, muss nun sichergestellt werden, dass sämtliche eingesetzte Drittsoftware frei von Schwachstellen ist. Leider gestaltet sich dies selbst dann schwierig, wenn man solche Software aus etablierten Quellen bezieht.
Präventive Ansätze
Beim Herunterladen von Container-Images von DockerHub beispielsweise sollte für jedes Image eine individuelle Risikoabschätzung durchgeführt werden, da durchaus bisweilen Images mit Schadcode und Hintertüren gefunden werden (z. B. [Cim18]). Für solche Images und andere zentrale Software, die nicht täglich geändert wird, empfiehlt sich also eine präventive Lösung! Eine solche Lösung kann zum Beispiel einen Firmen-internen Proxy für Container-Images beinhalten, in welchem Images nur nach einem Freigabeprozess aufgenommen werden, ab dann aber intern beliebig verwendet werden können.
Reaktive Ansätze
Während die Anzahl verschiedener eingesetzter Container-Images vermutlich gering ist, sprengt die Zahl der durch Paketmanager wie npm eingebundenen Bibliotheken auf Codeebene meist Dimensionen, in denen man noch jede Bibliothek auf Malware oder bekannte Schwachstellen hin prüfen könnte.
Dennoch wäre eine solche Prüfung durchaus wichtig, da beispielsweise regelmäßig Schadcode in npm-Paketen (siehe z. B. [Cim17] und [Schi18-b]), aber ebenso in Bibliotheken anderer Paketmanager gefunden wird. In der Praxis relevanter als bewusst eingeschleuster Schadcode ist darüber hinaus, dass regelmäßig unabsichtlich eingebaute Schwachstellen in solchen Bibliotheken gefunden und veröffentlicht werden. Entsprechend sollte das Team vermeiden, solche Softwareversionen mit bekannten Schwachstellen einzubinden.
Eine präventive Lösung mittels Proxy und Freigabeprozess, wie oben für Container-Images skizziert, ist hier zwar für Projekte mit sehr hohem Schutzbedarf denkbar, jedoch für die breite Masse sicherlich nicht verhältnismäßig. Ein solcher Ansatz würde den Entwicklungsprozess meist über Gebühr verlangsamen.
Stattdessen wird für das Erkennen von Sicherheitsrisiken in Softwarebibliotheken meist auf reaktive Ansätze gesetzt. Dazu finden sich viele Tools (z. B. OWASP DependencyCheck [OWASP]), welche eingesetzte Libraries automatisiert enumerieren und diese gegen Schwachstellendatenbanken abgleichen, ob zur jeweils eingebundenen Version Risiken bekannt sind. Diese Werkzeuge sollten dann so in den Build-Prozess eingebaut werden, dass Sicherheitsrisiken zeitnah erkannt und vermieden werden können. Ergebnisse müssen also auch analysiert werden und bei Bedarf Aktionen nach sich ziehen.
Selbst wenn ein solcher Dependency-Scan nur einmal am Tag läuft, erlaubt dieser reaktive Ansatz dem Team meist, Sicherheitsrisiken in eingesetzten Bibliotheken zu beheben, bevor es die Software an den Kunden ausliefert.
Fazit
Der wichtigste Schritt, um potenzielle konzeptionelle Sicherheitsprobleme in den eigenen Build-Prozessen in den Griff zu bekommen, ist dabei, sich damit auseinanderzusetzen. Dieser Artikel skizziert übliche Probleme und einige Lösungsansätze, konkrete Lösungen müssen dann jedoch für das eigene Projekt individuell ausgearbeitet und angepasst werden. Gelingt das, ist ein wichtiger Schritt getan, um die Vertraulichkeit von Passwörtern und ähnlich sensiblen Daten zu gewährleisten und um das Vertrauen in die Integrität der eigenen Software zu stärken.
Weitere Informationen
[Cim17]
C. Cimpanu, 4.8.2017,
https://www.bleepingcomputer.com/news/security/javascript-packages-caught-stealingenvironment-variables/
[Cim18]
C. Cimpanu, 13.6.2018,
https://www.bleepingcomputer.com/news/security/17-backdoored-dockerimages-removed-from-docker-hub/
[GitH]
https://github.com/spring-projects/spring-vault
[OWASP]
https://owasp.org/www-project-dependency-check/
[Sche14]
F. A. Scherschel, Haufenweise geheime AWS-Schlüssel auf GitHub entdeckt, heise, 25.3.2014, https://heise.de/-2154407
[Schi18-a]
D. Schirrmacher, Hacker entern Github-Dienst von Gentoo Linux, heise, 29.6.2018,
https://heise.de/-4094422
[Schi18-b]
D. Schirrmacher, NPM-Paket EventStream mit Schadcode zum Stehlen von Bitcoins infiziert, heise, 27.11.2018, https://heise.de/-4233171
[Vault]
https://www.vaultproject.io/
[Wit19]
T. Wittenhorst, GitHub-Konto von Canonical gehackt, heise, 8.7.2019, https://heise.de/-4465112









