Ausgangslage
Alles begann im auslaufenden Jahr 2019 mit der Anforderung, einen Service bereitzustellen, der es Führungskräften ermöglicht, unkompliziert und anonym Feedback zum eigenen Führungsverhalten zu sammeln und dieses Feedback der eigenen Selbsteinschätzung gegenüberzustellen.
Wie in jedem „guten“ Projekt kamen ein knappes Budget und eine ambitionierte Zeitleiste zusammen mit einem komplexen und langwierigen Prozess zur Infrastrukturbereitstellung. Um diesen Prozess abzukürzen und die nötige Flexibilität in der Architektur zu gewährleisten, stellte sich schnell der Weg in die Public Cloud als mögliche und favorisierte Lösung heraus. Aufgrund der zahlreichen Infrastrukturzertifizierungen [TISAX] und der organisatorischen Nähe zur Partnerschaft [MHP] lag die Nutzung von Amazon Web Services (AWS) als Cloud-Anbieter nahe. Somit begannen wir unsere Reise als erfahrene (Web-)Entwickler, die ihre ersten (produktiven) Schritte in die Cloud unternahmen.
Dies ist ein Szenario, dass immer mehr Entwicklern und Organisationen bevorsteht oder diese bereits beschäftigt. Bei immer komplexeren Anforderungen an Hochverfügbarkeit, Skalierbarkeit und Flexibilität von Lösungen führt kaum ein Weg an den großen Cloud-Anbietern vorbei. Vor diesem Hintergrund sind die hier getroffenen Abwägungen und Entscheidungen stellvertretend für die gesamte Branche.
Architekturabwägung
Die erste Herausforderung bestand für uns, wie für alle angehenden Cloud-Entwickler, darin, uns einen ersten Überblick über die Möglichkeiten, die uns AWS bietet, zu verschaffen. Bei über 200 Services (Stand 2021) ist dies allein bereits eine große Aufgabe, die einiges an Recherche bedarf. Zum Glück gibt es zahlreiche Quellen für Informationen, auf die man sich beziehen kann. Dazu gehört beispielsweise das Angebot von Learning-Plattformen wie LinkedIn Learning, Pluralsight oder die von AWS bereitgestellten Referenzarchitekturen, aber auch freie Videos auf YouTube oder Erfahrungsberichte und Lösungsvorschläge auf Stackoverflow. Weitere Quellen für Informationen sind natürlich die Erfahrungsberichte und Empfehlungen von Kollegen.
Bei all diesen Quellen wird man schnell mit einer Menge von Begriffen bombardiert, wie beispielsweise Lift-and-Shift, Platform as a Service, Infrastructure as a Service oder Serverless. Hier stellte sich für uns als Team die Frage, wie wir eine moderne Architektur aufbauen können, die die Vorteile der Cloud nutzt und es gleichzeitig dem Entwicklungsteam ermöglicht, bereits bekannte Frameworks und Skills einzusetzen, um die Entwicklung zu beschleunigen. Dabei haben wir grob in zwei Lösungsansätze unterschieden, die im Folgenden betrachtet werden sollen. Diese stehen stellvertretend für die Abwägungen vieler Entwicklungsteams zu Projektstart.
Der Cloud-Provider als IaaS – So viel Cloud wie nötig
Die in der Entwicklung einfachste Variante für die Entwickler besteht darin, auf gewohnte Technologien zurückzugreifen und die Nutzung der Cloud auf die dynamische Bereitstellung von Infrastruktur zu reduzieren. In Reinform würde das bedeuten, dass lediglich virtuelle Maschinen provisioniert werden, auf denen alle benötigten Komponenten, wie beispielsweise Applikations- oder Datenbankserver, bereitgestellt werden. Abgesehen von einigen Grundkonzepten, wie der Autorisierung der Entwickler auf der Cloud-Plattform, hält sich der Einarbeitungsaufwand in diesem Szenario in Grenzen.
Ein einfaches Beispiel für dieses Szenario zeigt Abbildung 1. Hier werden zwei Applikationsserver bereitgestellt und auf einem weiteren Server eine Datenbank gehostet. Als Endpunkt für die Applikation dient ein weiterer Server, auf dem ein Load Balancer, wie beispielsweise ngingx, installiert wird. In unserem Fall kennt sich das Entwicklungsteam sehr gut mit der Entwicklung von Webapplikationen mit Spring Boot und Angular aus. Entsprechend wären in einem solchen Szenario diese Frameworks gesetzt.
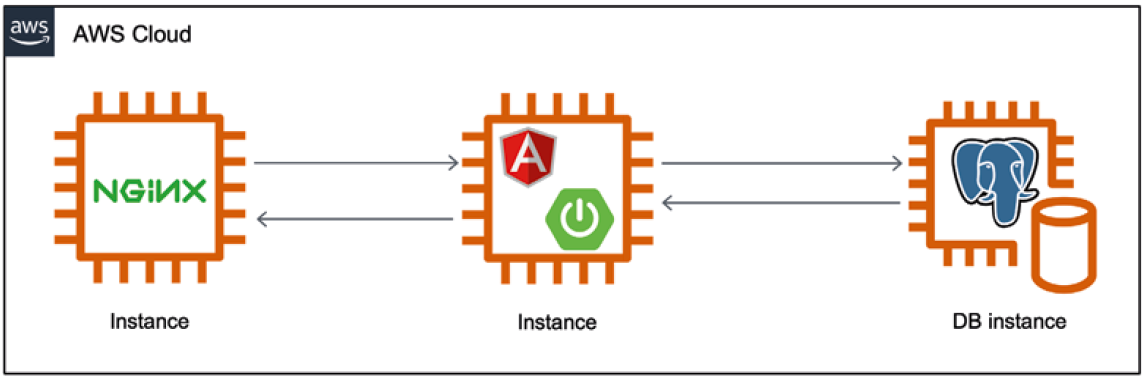
Abb. 1: Iaas – der Cloud-Provider stellt nur die Infrastruktur
Vorteile einer solchen Lösung sind, dass das Entwicklerteam sich komplett im eigenen wohlbekannten Tech-Stack bewegen kann und kaum Wissen über die Spezifika der Cloud-Plattform benötigt. Die Nachteile dieser Lösung sind, dass sich der Aufwand, den man bei der Entwicklung einspart, später in hohen Betriebs-Aufwänden heimzahlt. Beispielsweise müssen in einem solchen Fall alle Betriebssystem-Patches, Softwareaktualisierungen und Monitoring-Lösungen selbst ausgeführt und betrieben werden.
Der Cloud-Provider als PaaS – Go Full Serverless
Wer die Vorteile des Cloud-Providers nutzen möchte und dabei den (kosten-)effizientesten Weg sucht, muss sich allerdings tiefer in das Ökosystem des Anbieters begeben. Für ein Projekt, das auf der viel beschworenen grünen Wiese startet, lohnt es sich in jedem Fall, einen Blick auf die Serverless-Dienste zu werfen. Der berühmteste ist dabei sicherlich AWS Lambda. Bei Lambda handelt es sich um einen Dienst, der es dem Entwickler ermöglicht, Code auszuführen, ohne einen dedizierten Server bereitzustellen. Der Code kann dabei entweder als Archiv oder Docker Container bereitgestellt werden.
Als Auslöser für diesen Code fungiert dann ein Event, wie beispielsweise der Empfang einer (Kafka-)Message, der Empfang einer E-Mail, das Eintreten eines bestimmten Zeitpunkts, eine andere Lambda-Funktion, das Auftreten eines Alarms im Monitoring oder die Ablage eines neuen Objekts im Simple Storage Service. Diese Liste kann noch sehr lang weitergeführt werden. Der für diesen Anwendungsfall interessanteste Auslöser ist das Eintreffen eines http-Requests an einem API-Gateway. Die Request-Behandlung wird komplett in die Services ausgelagert und der Entwickler kann sich darauf konzentrieren, die gewünschte Funktionalität im Code zu implementieren. Natürlich bietet einem AWS auch gerne Datenbanken an, die dem Serverless-Modell folgen. Die bekannteste ist sicherlich DynamoDB, welche als vollständig verwaltete NoSQL-Schlüssel-/ Wert-Datenbank betitelt wird. Auf diese Weise lässt sich eine RESTful CRUD-API realisieren, ohne einen eigenen Server zu betreiben. Ein Beispiel für ein solches Szenario zeigt Abbildung 2.
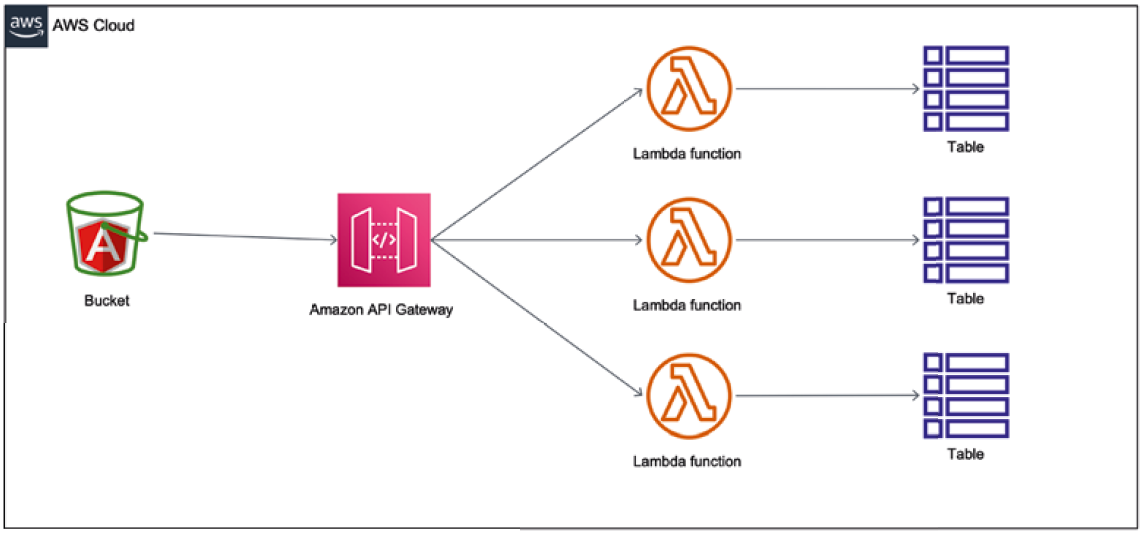
Abb. 2: PaaS – durch den Serverless-Ansatz entfallen die Server
Der größte Vorteil eines solchen Vorgehens ist sicherlich das Wegfallen jeglicher Betriebs-Aufwände an den Servern, da diese ja entfallen. Darüber hinaus ist sicherlich zu nennen, dass auf diese Weise die Applikationen sehr (kosten-)effizient betrieben werden können. Es entstehen nur dann Kosten, wenn die Applikation auch genutzt wird, und der monatliche Free-Tier ist großzügig genug bemessen, um kleine Applikationen nahezu kostenlos in der Cloud zu betreiben.
Negativ an einer solchen Lösung ist, insbesondere in unserem Fall, dass sich das Team in komplett neue Technologien einarbeiten muss und ein umfangreiches Know-how über die AWS Cloud benötigt. Zusätzlich zu nennen ist, dass man sich durch die Verwendung dieser Technologien selbst in einen Vendor-Lock-in begibt, da diese Technologien Amazon spezifisch sind und ein Wechsel zu einem anderen Anbieter nicht ohne erhebliche Mehraufwände möglich ist.
Hin und her gerissen – Der Weg zur tatsächlichen Lösung
Kommen wir zurück zu unserer Feedback-Applikation, die wir in der Cloud betreiben wollen, aber vorher erst einmal entwickeln und uns dafür auf einen Technologie-Stack festlegen müssen. Hier waren wir hin und her gerissen. Auf der einen Seite wollten wir natürlich gerne „richtig“ in die Cloud gehen und die Gelegenheit nutzen, uns mit den neuen Technologien vertraut zu machen. Andererseits fürchteten wir die großen Aufwände, die unbekannte Frameworks und CI/CD-Tools bedeuten würden.
So entschieden wir uns für eine Art hybriden Ansatz: Um unsere Erfahrungen mit bekannten Frameworks einsetzen zu können, entschieden wir uns, eine klassische Spring Boot-Applikation zu entwickeln und diese auf einer EC2-Instanz bereitzustellen und im Frontend auf eine Angular App zu setzen. Gleichzeitig wollten wir dennoch so viele Vorteile der Cloud wie möglich nutzen und entschieden uns, die Frontend-App auf einem Simple Storage Service (S3)-Bucket mit aktiviertem Web Hosting bereitzustellen und über das AWS Cloud Delivery Network namens CloudFront abrufbar zu machen. Auch für die weiteren Anforderungen an die Applikation haben wir uns kräftig bei der AWS-Plattform bedient.
Bei der Datenpersistierung haben wir uns aufgrund der großzügigen Kapazität im Free-Tier und der geringen Betriebs-Aufwände für die DynamoDB entschieden. In dieser haben wir alle unsere Daten abgelegt. Da es sich hierbei auch um teils sensible personenbezogene Daten handelt, war es klar, dass wir diese verschlüsselt ablegen müssen. Hierfür sind wir schnell im Baukasten fündig geworden und haben uns für den Key Management Service (KMS) entschieden und sowohl die Verschlüsselung für die betroffenen Tabellen insgesamt aktiviert als auch die entsprechenden Felder mit einem individuellen Schlüssel verschlüsselt. Für den Programmfluss ist auch der Versand von E-Mails an den Nutzer und entsprechende Feedbackgeber relevant. Auch hier bietet AWS mit dem Simple Email Service eine Lösung, die dem Namen gerecht wird. Nach der Validierung der Domäne, die im Falle einer über Route53 bezogenen Domäne voll automatisch stattfindet, erfolgt der E-Mail-Versand über einen einfachen API-Aufruf über das AWS SDK für Java.
Damit sind alle funktionalen Anforderungen an die Applikation abgedeckt. Im Bereich der Infrastruktur haben wir einen Application Load Balancer vor die Applikationsinstanzen platziert, um eine gewisse Verfügbarkeit zu garantieren und ein Ziel für unsere Clients zu bieten, die mit dem Backend interagieren wollen. Um standardmäßig nur TLS verschlüsselte Verbindungen zuzulassen, haben wir die entsprechenden Zertifikate direkt über den Amazon Certificate Manager bezogen und im Load Balancer sowie der Cloud-Front-Distribution hinterlegt. Das Routing auf die entsprechenden Ressourcen haben wir über entsprechende DNS-Einträge in Route53 realisiert. Somit ergibt sich als initiale Architektur unserer Gesamtlösung die Gesamtarchitektur in Abbildung 3.
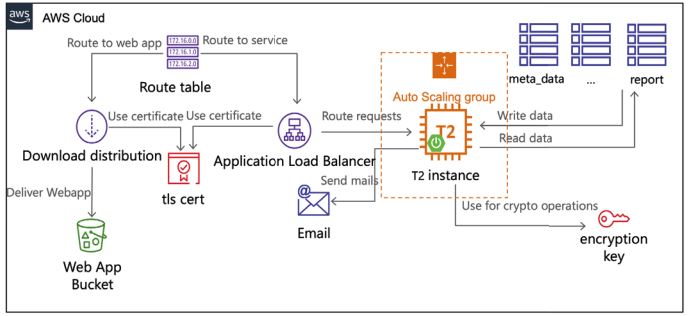
Abb. 3: Gesamtarchitektur der Lösung
Zusätzlich haben wir uns auch für die CI/CD-Lösung im AWS-Baukasten für Entwicklungslösungen bedient und den Code in CodeCommit, einem verwalteten Git-Repository in der Cloud, abgelegt. Das Bauen der Artefakte haben wir über CodeBuild und die Bereitstellung über CodeDeploy gelöst. Die Orchestrierung dieser Dienste, wie das automatische Bauen und Bereitstellen nach einem neuen Commit auf dem Main-Branch, haben wir über CodePipeline gelöst. Damit umfasst unsere Lösung bereits stolze 15 Services und damit immerhin etwas über 7 Prozent des gesamten AWS-Service-Portfolios.
Bis hierhin sieht alles gut aus
An diesem Punkt unserer Geschichte waren wir sehr zufrieden mit uns. Wer das Gefühl kennt, ein Projekt trotz ambitionierter Zeitleiste rechtzeitig auf einer Prod-Stage bereitzustellen, kann das sicher nachvollziehen. Die letzten Tests mit der Testgruppe waren auch sehr vielversprechend und das, obwohl wir so viele neue Technologien in so kurzer Zeit beherrschen lernen mussten.
Der Leser fragt sich bestimmt nun, worin genau der Fuck-up lag. Kommen wir nun dazu, wie sich die Ruhe und das Gefühl des Sieges über die neuen Technologien schnell in hektische Fehleranalyse und ein Gefühl der Panik wandelten.
Doch nicht alles so gut?
Bereits wenige Tage, nachdem die Massen auf unsere Applikation losgelassen wurden, erhielten wir von unserem Kunden eine E-Mail, die sinngemäß wie folgt lautete: „Die App ist viel zu langsam! Was ist hier los? Bitte schnell schneller machen!“
Damit war es mit der Ruhe schlagartig vorbei und wir begaben uns in die Fehleranalyse. Zunächst einmal hatten wir drei Verdächtige identifiziert:
- die CPU-Auslastung unserer sehr klein gewählten EC2-Instanzen,
- die Netzwerklatenz zwischen den einzelnen Komponenten unserer Applikation,
- ein Problem beim Lesen und Schreiben in die Datenbank.
Ein Blick auf das EC2-Dashboard hat die erste Theorie schnell verworfen. Trotz der geringen Größe der Instanz gab es hier keinerlei Probleme, selbst in Momenten mit vielen Anfragen ging die CPU-Auslastung eigentlich nie über 10 Prozent, was nicht sonderlich überraschend ist, da die Applikation im Wesentlichen aus CRUD-Anfragen besteht, die an die DB ausgelagert werden.
Genauso schnell konnten wir Latenzen zwischen den einzelnen Services ausschließen. Wenig überraschend konnten wir das Problem nicht einfach auf einen Fehler im Netzwerk des größten Cloud-Providers am Markt abschieben. Entsprechend bleibt nur noch ein Fehler, der höchst wahrscheinlich bei uns selbst liegt.
Ein Blick in das DynamoDB-Dashboard brachte auch hier schnell Klarheit. Wir hatten mehrere aktive Alarme, die besagten, dass unsere zur Verfügung stehende Lesekapazität weit überschritten würde (s. Abb. 5). Wichtig für das Verständnis ist hier, dass im Jahr 2019 die freien (sprich kostenlosen) Lese- und Schreibkapazitäten bei 5 lagen. Ein weiterer Blick verrät, dass das ausreicht, um pro Sekunde 5 Lese- oder Schreibvorgänge abzubilden. Das müsste laut Marketing für mehrere Millionen Anfragen im Monat reichen. Unsere Applikation kam, sofern sie nicht gerade zu langsam war, sehr gut beim Nutzer an, aber aufgrund der eingeschränkten Nutzerbasis waren wir davon weit entfernt.
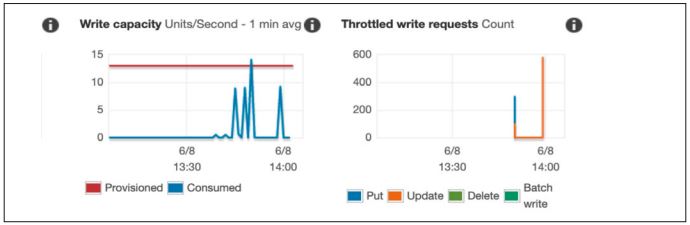
Abb. 5: Verbrauchte Lesekapazität und gebremste Requests in DynamoDB
Aber immerhin hatten wir das Problem nun identifiziert, denn jede Anfrage, die über die zur Verfügung gestellte Kapazität hinaus geht, wird gebremst, und zwar in einem Maße, dass sie für unseren Use-Case nicht mehr zu verwenden ist. Als Hotfix auf der Produktionsumgebung blieb uns fürs Erste nur, die Lesekapazitäten von dem fest konfigurierten Wert auf On-Demand-Skalierung umzustellen. Damit konnten wir die Performanzprobleme auf der Produktivumgebung sofort eliminieren und das flüssige Nutzererlebnis sicherstellen.
Auf der Suche nach dem Ursprung des Problems
Wenn die Lesekapazität in dem gleichen Maße, wie in Abbildung 5 dargestellt, bei bis zu 15 Einheiten geblieben wäre, hätte man die Lösung komplett so belassen können. Die Kosten für ein solches Überschreiten der Lesekapazität sind im Vergleich zu den Entwicklungskosten zu vernachlässigen und würden heute im Herbst 2021 ohnehin im Free-Tier des Service liegen. Leider blieb es dabei nicht: Die benötigte Lesekapazität schien eher exponentiell zu steigen, und auch bei den Kosten kam es zu dem, was wir einen leichten Anstieg nennen. Gleichzeitig war der Anteil, den die DynamoDB an den Gesamtkosten ausmachte, mit 94 Prozent überwältigend (s. Abb. 4). Damit stieg die Motivation, die Kosten zu senken, erheblich.
Um die genaue Ursache des Fehlers nachvollziehen zu können, müssen wir etwas tiefer in die verwendeten Technologien auf der Backend-Seite eintauchen. Wie bereits beschrieben, haben wir hier auf das uns bekannte Spring-Framework gesetzt und bei der Suche nach einem Framework, um mit der DynamoDB zu interagieren, sind wir auf eine Spring Data-Erweiterung [GitH] gestoßen, die sich großer Beliebtheit und Verlässlichkeit erfreut. Dieses erlaubt uns, die bereits bekannten Repository-Konstrukte von Spring Data weiter zu verwenden, ohne uns große Sorgen um die tatsächliche Query-Mechanik der DynamoDB zu machen.
Alles funktioniert super, solange man nur auf Grundlage der Schlüssel suchen muss, wie es auch das gesamte Konzept der DynamoDB ist. Problematisch wurde es für uns, als wir, aufgrund einer kurzfristigen Anforderungsänderung, eine Suche auf einem Attribut einer Unterklasse umsetzen mussten. Aufgrund der Einfachheit, mit der diese im Code umzusetzen war (s. im Code-Snippet in Listing 1 die zweite Repository-Methode), ist uns dabei durch die Lappen gegangen, dass dies bei jeder Interaktion mit den Daten ein komplettes Abfragen der Daten nach sich zieht, da dies nicht durch eine Abfrage der Tabellenindizes gelöst werden kann.
@Data
@DynamoDBTable(table = "package")
public class Package {
@DynamoDBHashKey
@DynamoDBAutoGeneratedKey
private String id;
@DynamoDBAttribute
private String addressLine;
private Item item;
}
@DynamoDBDocument
public class Item {
private String category;
private String description;
}
@EnableScan
public interface PackageRepository
extends CrudRepository<Package, String> {
List<Package> findByAddressLine(String addressLine);
List<Package> findByItem_Category(String category);
}Um im Beispiel aus dem Code-Snippet zu bleiben, mussten wir in einer Lagerhalle nicht mehr nur an jedem Paket vorbeigehen und von außen draufschauen, um das richtige zu finden, sondern jedes einzelne Paket öffnen und dessen Inhalt durchsuchen. Dies lässt den Aufwand im Beispiel mit jedem weiteren Paket enorm steigen. Genau dies ist uns in unserer Applikation mit jedem weiteren Nutzer geschehen. So hat eine kleine Zeile Java-Code die Kosten unserer Cloud-Anwendung völlig explodieren lassen.
Der Weg aus der Misere
Die anfängliche Euphorie über unsere in Betrieb genommene Cloud-Applikation ist so schnell in Frustration umgeschlagen, allerdings kann man die Schuld dafür auch nicht an AWS und die DynamoDB schieben. In diesem Fall sind einfach zwei Modelle aufeinandergetroffen, die sich gegenseitig verstärken: Zum einen gab es ein Problem in unserem Datenmodell, das nicht perfekt auf den (sich verändernden) Anwendungsfall gepasst hat und deshalb zu einem sehr ineffizienten Leseverhalten auf der Datenbank geführt hat. Dieses ist dann mit dem Pay-As-You-Go-Konzept zusammengekommen, nämlich, dass man (nur) für die Kapazitäten, die man tatsächlich nutzt, zahlen muss. In diesem konkreten Fall hat das zu höheren Kosten geführt, da unsere Applikation zu verschwenderisch mit der bereitgestellten Kapazität umgegangen ist.
Zur Lösung des Problems gab es nun im Wesentlichen zwei Möglichkeiten: Entweder ein Refactoring der Anwendung, damit das Datenmodell besser zur verwendeten Datenbank passt, oder das Austauschen der Datenbank, damit das Datenmodell zusammen mit dem Spring Data-Framework weiterverwendet werden kann. Wir haben uns für Letzteres entschieden, um die Aufwände in diesem Fall möglichst gering zu halten, die Änderungen schnell umsetzen zu können und weil wir, ehrlich gesagt, etwas vorsichtig mit uns unbekannten Technologien geworden sind. Wir haben uns für eine Postgresql-Datenbank entschieden, welche im Relational Database Service (RDS) gehostet und weitestgehend von AWS gemanagt wird. Dadurch konnten wir die geringen Betriebs-Aufwände eines Managed Service mit unserem bereits vorhandenen Knowhow kombinieren.
Durch diese Änderungen konnten wir die monatlichen Kosten für den Betrieb der Applikation schnell um 90 Prozent senken, ohne die Nutzererfahrung zu beinträchtigen.
Was kann jeder aus diesem Erfahrungsbericht mitnehmen
Ich möchte jedem Leser, der den gesamten Erfahrungsbericht gelesen hat, gerne noch ein paar meiner wesentlichen Learnings mit auf den Weg geben:
- Bei jeder persönlichen Reise in die Cloud können verschiedene Dinge schief gehen, dabei kann es wie in diesem Fall um Mehrkosten gehen, aber auch andere Probleme können auftreten. Wichtig ist es, hier einen offenen Umgang mit diesen Erfahrungen zu leben und diese nicht aufgrund von falschem Stolz zurückzuhalten, sondern den offenen Umgang mit diesen zu suchen und das dabei gewonnene, sehr wertvolle Wissen innerhalb der eigenen Organisation zu streuen. Dabei können Formate wie Fuck-Up-Talks, neben den regulären Trainings und Zertifizierungen, einen wesentlichen Bestandteil bilden, um die eigene Expertise zu steigern.
- Im Gegensatz zur On-premise-Welt konfrontieren die Cloud-Provider jeden Entwickler direkt mit den Kosten seiner Architekturentscheidungen. Deshalb ist es für jeden wichtig, ein Verständnis von den Abrechnungsmodellen der einzelnen Services zu haben. Wichtig ist es, sich nicht von den vermeintlichen Mehrkosten abschrecken zu lassen, sondern die richtigen Vorkehrungen zu treffen, diese frühzeitig zu erkennen. Dabei können die zahlreichen Alarme, die beim Überschreiten eines gewissen Werts ausgelöst werden, helfen. Dafür müssen sie allerdings auch konfiguriert werden.
- Die Fehler, die passieren, sind immer ein Nebeneffekt von Innovationen. Sie müssen nur als Möglichkeit begriffen werden. Diese Möglichkeiten liegen nicht nur in dem tieferen Verständnis der eingesetzten Technologien, sondern auch darin, andere vor den gleichen Fehlern zu bewahren oder in einigen Fällen davon auf Konferenzen oder in Beiträgen wie diesem berichten zu dürfen.
Weitere Informationen
[GitH]
https://github.com/derjust/spring-data-dynamodb
[TISAX]
Trusted Information Security Assessment Exchange,
https://aws.amazon.com/de/compliance/tisax/