

Dass Image Mining – besser bekannt als Computer Vision oder Image Analytics – ein Teilbereich der KI ist, ist mittlerweile im breiten Markt angekommen [IBM21]. Seit die bahnbrechenden Entwicklungen ab 2012 das Forschungsfeld in Breite und Tiefe angefeuert haben, ist ein schierer Hype entstanden, der sich positiv auf das gesamte Themenfeld ausgewirkt hat [Alo17]. Im Anschluss an die großen Performance-Sprünge bei bekannten Challenges wie ImageNet [Ima21] kam es zu weiteren Fortschritten, die zu dem heutigen Status quo beitrugen.
Kostengünstige Hardware inklusive Speichermöglichkeiten zusammen mit einem immensen Aufkommen an Bilddaten zeigen, wie einfach heutzutage Bilder verarbeitet werden können. Durch die Verwendung von Graphical Processing Units (GPUs) und dem Trend zur Auslagerung von Rechenoperationen in die Cloud ist es nochmals einfacher geworden, Computer-Vision-Lösungen lauffähig zu machen. Außerdem führt der Open-Source-Grundgedanke der Community und neuartige Modell-Architekturen zu ungeahnten Möglichkeiten. Diese werden zunehmend ausgeschöpft, indem für vielfältigste Anwendungsfälle Speziallösungen entwickelt werden. Ein prominentes Beispiel vergangener Pandemie-Monate sind Modelle, die das Vorhandensein einer Gesichtsmaske sowie das korrekte Tragen überprüfen [PaB17].
Die Lücke zwischen dem, was jeweils theoretisch möglich und praktisch tatsächlich umsetzbar ist, wird immer kleiner, je mehr Branchen und Bereiche sich mit dem Thema auseinandersetzen. Die Entwicklungen der vergangenen Jahre haben zur Gründung einer Reihe hochspezialisierter Start-ups geführt, die einzelne Unteraufgaben in Computer-Vision-Projekten oder ganze alleinstehende Lösungen anbieten.
Für überwachte Lernverfahren wird oft ein zeitund kostenintensiver Labelling-Prozess benötigt. Unter dem Bild-Labelling oder Bild-Annotieren wird das strukturierte Versehen der Bilder mit den Informationen, die vom Neuronalen Netz erlernt werden sollen, verstanden. Dieser Prozess kann semi-automatisiert mit Hilfe von KI-Modellen und dadurch teilweise mit besserer Performance als von Menschen ausgeführt werden. Einer dieser vielen neuen Anwendungsfälle stammt aus der Chemie- und Reinigungsbranche und steht im Blickpunkt dieses Artikels. Das Vorprojekt hat die PTC gemeinsam mit einem Hersteller chemischer Reinigungsmittel durchgeführt.
KI zieht in die Waschstraße ein
Das besondere Verhältnis vieler Deutscher zu ihrem Auto unterstreicht die regelmäßige Autowäsche – in vielen Haushalten steht sie sogar wöchentlich auf dem Plan. Das Bedürfnis nach Sauberkeit steht allerdings dem Nachhaltigkeits- und Umweltgedanken gegenüber. Angesichts dieser Megatrends soll zukünftig auch in Waschstraßen deutlich weniger Wasser verbraucht und Chemie eingespart werden. Oberstes Ziel in der Waschstraße ist es, das Auto zu reinigen und von einem schmutzigen in einen sauberen Zustand zu überführen. Dazu sind – je nach Automatisierungsgrad der Waschstraße – mehrere Arbeitsschritte notwendig. Der größtenteils standardisierte Prozess sieht wie folgt aus: Zuerst wird Vorreiniger auf die Fahrzeugoberfläche aufgetragen, um größere und intensivere Verschmutzungen auf den Waschvorgang vorzubereiten. Im Anschluss daran kommen Schaum und Shampoo auf das Fahrzeug und die eigentliche Reinigung wird durchgeführt. Nach dem Trocknen wird Konservierungsmittel auf das Fahrzeug gegeben und gegebenenfalls poliert. Alle Arbeitsschritte folgen einem Standard-Prozedere, wobei einige bereits einen hohen Automatisierungsgrad besitzen. Die erste Phase – die Vorreinigung – wird noch weitgehend manuell ausgeführt. Daher kann der Waschvorgang genau in diesem Schritt weiter automatisiert werden. Die Idee ist, genau so viel Chemie als Vorreiniger beizumischen, dass das Fahrzeug abhängig vom Verschmutzungsgrad sauber wird.
Eine mögliche Lösung besteht darin, eine visuelle Schmutzerkennung basierend auf Deep Learning und Computer-Vision-Methoden zu entwickeln. Diese Lösung soll verschiedenartige Schmutzarten klassifizieren und zusätzlich eine Indikation über den Grad der Verschmutzung geben. Diese Informationen wurden bisher vom Personal beim Einfahren in die Waschstraße aufgenommen und der Vorreiniger in entsprechender Dosis und Dauer aufgetragen. Mit Unterstützung durch eine visuelle Schmutzerkennung können die geeigneten Chemikalien ausgewählt sowie Zugabe und Dosierung gesteuert werden. Die Autowäsche wird dadurch intelligent und individuell für jedes einfahrende Fahrzeug gestaltet. Die Lösung zur visuellen Schmutzerkennung kann einerseits zu Beginn eingesetzt werden, um das schmutzige Auto zu analysieren, und im Nachgang zur Qualitätssicherung verwendet werden. Ist die Qualität nicht ausreichend, kann ein erneuter Durchlauf gestartet werden.
Der Standard-Waschvorgang verbraucht häufig zu viel chemische Mittel. Ein in der Garage stehendes, leicht verstaubtes Auto wird bis dato mit dem gleichen Programm gereinigt wie ein Geländefahrzeug, das auf einer matschigen Forststraße unterwegs war. Zudem gibt es deutliche Unterschiede, wie beispielsweise Baumharze oder Blütenstaub in Kombination mit Vogelkot oder Insekteneinschlag auf der Fahrzeugfront zu behandeln sind. Dabei kann eine KI-gestützte visuelle Schmutzerkennung unterstützen.
Zusätzlich erreicht das bei der Autowäsche verwendete Wasser bei verringertem Einsatz folglich auch weniger chemisches Reinigungsmittel. Das sogenannte Brauchwasser kann somit einfacher aufbereitet und in den Waschprozess zurückgeleitet werden. Insgesamt sinkt dadurch der Verbrauch an Frischwasser inklusive Kosten, auf der anderen Seite steigt die Nachhaltigkeit.
Herausforderungen typischer Image-Mining-Projekte
Aufgrund des fehlenden Know-hows und eines ausreichenden Prozessverständnisses werden Image-Mining-Projekte bei erstmaligem Entwicklungszyklus häufig als Proof-of-Concept (POC) durchgeführt. Dabei wird das Problem heruntergebrochen, sodass man mit begrenzten Ressourcen zu einer tragfähigen Machbarkeitseinschätzung kommt. Man testet in iterativen Zyklen aus, was möglich und machbar ist.
Diese Projektform – man spricht auch von Vorprojekt – eignet sich besonders gut, wenn zu Beginn noch nicht klar ist, wie eine konkrete Ziellösung aussieht. Auch viele klassische Themen aus der IT wie der Betrieb oder die Wartung werden zunächst vernachlässigt – der Fokus liegt initial klar auf dem Lösen des eigentlichen Problems. Begonnen wird oftmals mit Hospitationen; und zwar dort, wo das Problem besteht. Expert*innen aus verschiedenen Bereichen treffen sich, um ein gemeinsames Prozessverständnis zu entwickeln. Hier werden Anforderungen aufgenommen, Probleme erörtert sowie ggf. auch Einschränkungen festgelegt, um den Rahmen für das Projekt abzustecken.
Sobald die Ziele klar sind, beginnt die eigentliche Umsetzung. Data Scientists und Data Engineers arbeiten grundsätzlich mit Daten. Bei Image-Mining-Projekten liegen die Daten nicht strukturiert (zum Beispiel in einer Tabelle), sondern unstrukturiert in Form einer Ansammlung von Bildern vor. Falls kein Bild-Datensatz vorhanden ist, wird dieser gemeinsam oder unter Anleitung erstellt. Weiter ist eine Strategie zum Annotieren der Bilder notwendig, und wenn diese erstellt ist, kann das Labelling starten.
Häufig wird der Aufwand für die Erstellung eines geeigneten Datensatzes unterschätzt, obwohl dies ein immens wichtiger Schritt in Datenprojekten ist. In der Data-Science-Welt ist das Prinzip „Garbage in, garbage out“ mittlerweile weit verbreitet. Es bedeutet, dass Modelle, die bestimmte Vorhersagen durchführen sollen, nur so gut sind wie die Input-Daten, mit denen sie trainiert wurden.
Sobald die Datengrundlage für den POC vollständig ist, können die Bild-Vorverarbeitung und das eigentliche Modellieren & Modelltraining beginnen. Dafür werden künstliche Neuronale Netze verwendet, die Zielfunktionen minimieren, um die definierten Größen und Werte so genau wie möglich vorherzusagen. Im Zuge dessen werden die Bilder mit den tatsächlichen Annotationen – quasi als Anleitung – wieder und wieder dem Modell gezeigt, bis sich dessen Parameter so angepasst haben, dass auch ein neues Bild ausreichend gut prognostiziert wird. Aufgrund der großen und stetig wachsenden Open-Source-Gemeinschaft für Image Analytics wird das Rad typischerweise nicht jedes Mal neu erfunden. Stattdessen werden bereits existierende und etablierte Modell-Architekturen als Basis verwendet und auf einen neuen Datensatz feinjustiert. Am Ende steht eine Beurteilung der Machbarkeit und Handlungsanweisungen zu weiteren möglichen Ausbaustufen werden vorgestellt.
Viele Unternehmen – gerade im Mittelstand – versuchen einerseits den Anschluss an den Wettbewerb zu halten und andererseits die Investitionssumme in überschaubarem Rahmen zu halten. Auch lässt sich zu Beginn eines Projekts weder exakt sagen, wie gut ein Ansatz funktioniert, noch können aus Sicht der Durchführenden konkrete Zusagen zu Ziel-Performances gemacht werden. Das hängt wie bei allen Projekten aus dem Bereich der KI in großem Maß von den verwendeten Inputdaten ab. Oft werden diese erst im Projekt erhoben oder lediglich die Annotationen für die Bilder neu erstellt.
All diese Unsicherheiten führen in vielen Fachbereichen oder bei Domänenexperten dazu, dass eine pessimistische Grundhaltung eingenommen wird. Nichtsdestotrotz steht dem der positive und innovative Grundgedanke gegenüber, bestehende Probleme von Grund auf neu zu denken. Beide Seiten halten sich insgesamt die Waage.
Eine Zusammenfassung typischer Herausforderungen in Computer-Vision-Projekten:
- Initial fehlendes Know-how und Prozessverständnis
- Nicht vorhandener Bild-Datensatz inklusive Unterschätzung zeitintensiver Annotationen
- Beschränktes Budget und Ressourcen
- Pessimistische Grundhaltung der Beteiligten durch anfängliche Unsicherheiten
- Zeitliche Restriktionen (Kapazität beim Fachpersonal, bestimmte Bedingungen für Bild-Aufnahme)
- Ungenaue Angaben zu KI-Leistungsfähigkeit aufgrund der Natur datengetriebener Projekte
- Schwieriges Veränderungsmanagement durch wechselnde Anforderungen iterativer Projektzyklen
Vorgehen und technische Aspekte
Für die Hospitationen tauschten KI-Expert*innen von PTC ihren Büroarbeitsplatz gegen Waschstraßen ein. Genauer gesagt: den Bereich davor. Hier soll das Problem, unterschiedliche Schmutzarten auf einem Fahrzeug visuell zu erkennen, gelöst werden. Mit einfachen Mitteln und handelsüblichen Smartphones wird über mehrere Monate ein Bild-Datensatz erstellt, sortiert und vorverarbeitet.
Weil möglichst alle – je nach Jahreszeit unterschiedlichen – Schmutzarten in den Bildern auftauchen sollen, dauert diese Phase besonders lange. Die Abhängigkeit vom Wetter zeigt sich in folgendem Beispiel: Blütenstaub und Pollen treten vor allem im Frühling und Sommer auf, Insekteneinschlag und Vogelkot in der warmen Jahreszeit und Winterschmutz wie Reste von Streusalz lediglich im Winter. Zusätzliche Faktoren wie Wind, Regen, Schnee oder das Fahren mit höheren Geschwindigkeiten erhöhen die Varianz der Schmutzarten in den Bildern. Jeder Computer-Vision-Datensatz benötigt eine Strategie, die festlegt, wie die Bilder für den Anwendungsfall annotiert werden sollen. Überlegungen wie „Wie markiere ich Vogelmist in meinen Fahrzeugbildern?“ spielen im Anwendungsfall tatsächlich eine wichtige Rolle. Die Merkmale und deren Ausprägungen leiten sich aus dem Ziel und dem vorhandenen Datensatz ab. Generell ist es Standard, die spätere Erweiterbarkeit um zusätzliche Attribute, also Schmutzklassen, zu ermöglichen.
Das Labelling mehrerer tausend Bilder wird mit dem browserbasierten Open-Source-Tool Via (VGG Image Annotator) durchgeführt [DGZ21]. Bei mehreren am Annotationsprozess beteiligten Personen ist es wichtig, dass alle ein klares Verständnis der konkreten Aufgabe bekommen. Jede Person besitzt eine eigene subjektive Wahrnehmung und damit ein anderes Verständnis, wie eine bestimmte Schmutzklasse aussieht. Dabei erweisen sich regelmäßige Meetings, in denen Unklarheiten oder Spezialfälle (wie Überlagerungen einzelner Schmutzklassen) erörtert werden, als nützlich.
Als Modellbasis werden zwei bekannte Modellarchitekturen verwendet: HRNet [Wan19] zur Semantischen Segmentierung sowie EfficientNet [Min19] zur Bildklassifikation. Diese werden auf mehreren GPUs auf Azure-Servern mit dem erstellten Datensatz trainiert. Eine Herausforderung bei großen und komplexen Architekturen ist die Konvergenz der Modelle. Darunter wird die Fähigkeit verstanden, dass sich Fehlerraten bis zu einem Minimum verringern und dort einpendeln. Dies kann über die Konfiguration der Modellparameter erreicht werden und bedarf einer sauberen Auswahl. Die kleinteilige Konfiguration sowie die große Anzahl zu lernender Modellparameter können zu langwierigen Trainingsläufen oder ganz ausbleibender Konvergenz führen.
Des Weiteren ist die Unterscheidbarkeit der unterschiedlichen Schmutzarten sehr variabel. Während kreisförmiger Vogelkot auf einer dunklen Oberfläche gut ermittelt werden kann, ist dies bei großflächigem Staub oder Blütenstaub schwieriger. Auch Überlappungen sind kritisch und damit schwieriger zu differenzieren. Nach einer Vielzahl von Trainingsläufen hat die EfficientNet-Architektur zu erfolgversprechenden Ergebnissen geführt (vgl. Abbildung 1). Für das Modelltraining wird aus dem Gesamt-Datensatz eine Trainings- und eine Testmenge – meist im Verhältnis 80:20 Prozent – erstellt. Die Trainingsdaten dienen dem Modell dazu, die Parameter – man spricht auch von Gewichten – zu lernen. Die Testdaten werden dann nach erfolgtem Training zur Bewertung des Modells verwendet. Wichtig ist, dass das Modell die Testdaten noch nicht kennt.
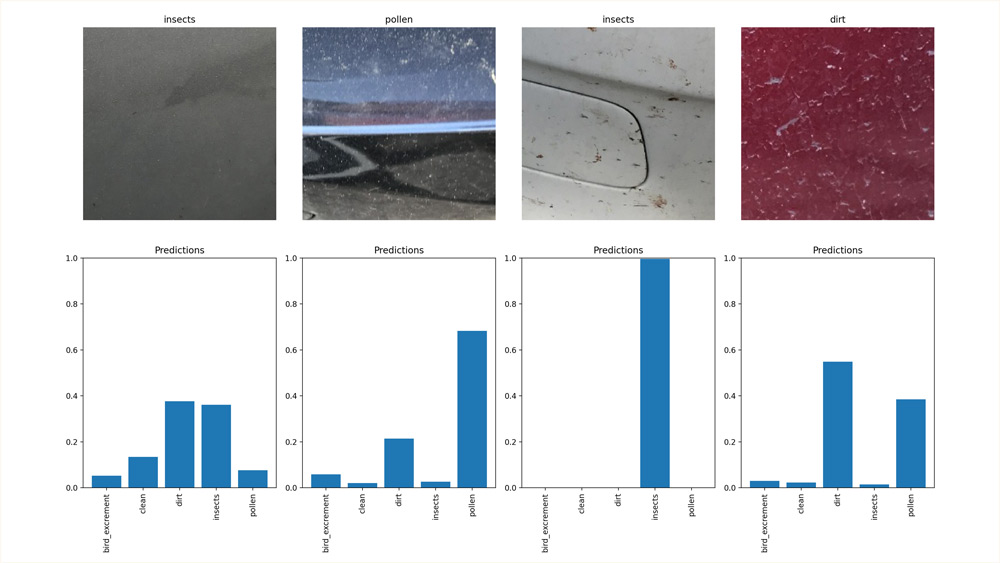
Abb. 1: Beispielbilder (oben) und vom Modell ermittelte Wahrscheinlichkeiten einzelner Schmutzklassen als Balkendiagramm (unten)
Abbildung 1 zeigt beispielhafte Modell-Outputs (unten) für unterschiedliche Inputbilder (oben). Jede Modellprognose liefert dabei Wahrscheinlichkeiten, mit denen die definierten Schmutzklassen im Bild auftreten. In manchen Bildern ist die Modellentscheidung eindeutig (mittlere Abbildungen), in anderen nicht (äußere Abbildungen). Durch eine an die Modellbewertung nachgelagerte Logik kann weiteres Fachwissen in den Prozess eingebaut werden. Ist auf einem Fahrzeug beispielsweise in einem Mindestmaß Insektenschmutz vorhanden, kann eine erforderliche Grundmenge an chemischem Reinigungsmittel bei der Vorreinigung hinzugegeben werden.
Das finale Modell (EfficientNet Version B3) liefert auf dem Testdatensatz eine Vorhersagegenauigkeit von 0,65 und als Maß für die Modellgüte einen AUC-Wert von 0,87 [Bra97]. Die Aufgabe der Semantischen Segmentierung (Vorhersage auf Pixelebene) wird zu einer Bildklassifikation (Vorhersage auf Bildebene) vereinfacht, wobei fünf Schmutzklassen verwendet werden.
Fazit
Am Ende runden Überlegungen zu möglichen Anschaffungen zusätzlicher Hardware für eine Pilotierungsphase sowie eine Machbarkeitseinschätzung das Projekt ab. Insgesamt konnte gezeigt werden, dass eine visuelle Schmutzerkennung mit Methoden der Künstlichen Intelligenz durchaus machbar ist. Während die initial hochgesteckten Ziele im Projektverlauf angepasst sowie das zu lösende Problem vereinfacht wurde, konnte mit der entwickelten Computer-Vision-Lösung ein neuartiger Anwendungsfall erstmalig bearbeitet werden. Zusätzlich wurde wichtiges Grundlagenverständnis und ein wiederverwendbares KI-Modell zur Schmutzerkennung auf Bildebene geschaffen.
Das Vorprojekt hat zu einer sehr guten Ausgangssituation für weitere Ausbaustufen geführt. Der Reifegrad kann in einer folgenden Pilotierungsphase weiter erhöht werden. In Zukunft soll neben der Schmutzart auch der Grad der Verschmutzung mittels KI-gestützter visueller Schmutzerkennung erfolgen. Dadurch kann weitere Chemie bei der Vorreinigung eingespart werden. Langfristiges Ziel ist es, das gesamte Geschäftsmodell in Richtung „Pay-per-Wash“ weiterzuentwickeln, sodass jeder Waschvorgang individuell je nach Fahrzeugverschmutzung durchgeführt wird.
Weitere Informationen
[Alo17] Alom, Z. et al.: The History Began from AlexNet: A Comprehensive Survey on Deep Learning Approaches. 2017, https://arxiv.org/ftp/arxiv/papers/1803/1803.01164.pdf, abgerufen am 8.11.2021
[Bra97] Bradley, A. P.: The use of the area under the ROC curve in the evaluation of machine learning algorithms. In: Pattern Recognition, Vol. 30, Issue 7, 1997
[DGZ21] Dutta, A. / Gupta, A. / Zisserman, A.: VGG Image Annotator, https://www.robots.ox.ac.uk/~vgg/software/via, abgerufen am 8.11.2021
[IBM21] IBM: What is computer vision? https://www.ibm.com/topics/computer-vision, abgerufen am 8.11.2021
[Ima21] ImageNet: ImageNet Large Scale Visual Recognition Challenge. https://www.image-net.org/challenges/LSVRC/index.php, abgerufen am 8.11.2021
[Min19] Mingxing, T.: EfficientNet: Improving Accuracy and Efficiency through AutoML and Model Scaling. Google AI Blog, 29.5.2019, https://ai.googleblog.com/2019/05/efficientnet-improving-accuracy-and.html, abgerufen am 8.11.2021
[PaB17] Patterson, J. / Basu, K.: Solving real-world business problems with computer vision. Juli 2017, O’Reilly, 7.9.2017, https://www.oreilly.com/radar/solving-real-world-business-problems-with-computer-vision, abgerufen am 8.11.2021
[Wan19] Wang, J. et al.: Deep High-Resolution Representation Learning for Visual Recognition. 2019, HRNet for Semantic Segmentation, https://github.com/HRNet/HRNet-Semantic-Segmentation, abgerufen am 8.11.2021









