

Das Fraunhofer-Institut für Produktionstechnik und Automatisierung IPA hat unter den Gesichtspunkten der aufkommenden Regulierung von KI die ML-Komponente eines Datenverarbeitungsprodukts des Informationsdienstleisters Experian, das zur Online-Betrugsbekämpfung eingesetzt werden kann, hinsichtlich einer gesetzeskonformen Entwicklung und der Nachvollziehbarkeit der Ergebnisse untersucht.
Ein großes wirtschaftliches Problem in der Online-Betrugsbekämpfung ist, die Betrugsversuche zuverlässig zu erkennen. Die meisten technischen Systeme, die hier zum Einsatz kommen, sind regelbasiert und so programmiert, dass sie eher zu viele Transaktionen als Betrug klassifizieren als zu wenig. Das heißt, sie ordnen viele valide Transaktionen fälschlicherweise als Betrug ein. Diese „False Positives“ sind wirtschaftlich nachteilig, weil sie zu vermehrten manuellen Kontrollen und Umsatzverlusten führen. Laut Payment-Beratung CMSPI lagen 2020 die Umsatzverluste durch gezielten Kartenbetrug in Europa bei etwa 2 Milliarden Euro, die Verluste durch False Positives hingegen bei rund 23 Milliarden Euro. Zur zuverlässigen Betrugserkennung und zur signifikanten Reduktion von False Positives kommen verstärkt KI-basierte Lösungen zum Einsatz. Allerdings ist hierbei sicherzustellen, dass eine solche Lösung gesetzeskonform ist und nachvollziehbare Ergebnisse liefert. Dies kann durch ein Audit erfolgen, bei dem die verschiedenen Phasen des Entwicklungsprozesses (siehe Abbildung 1) sowie die fertige KI-Lösung selbst von Fachleuten geprüft werden.
Die Zielsetzung und der Ablauf eines Audits wird im Folgenden am Beispiel des Transaction Miner beschrieben. Beim Transaction Miner handelt es sich um die Machine-Learning-Komponente der Betrugspräventionslösung AI:drian, die von Experian in Deutschland entwickelt wurde. Das Audit erfolgte 2021 durch das Fraunhofer IPA.
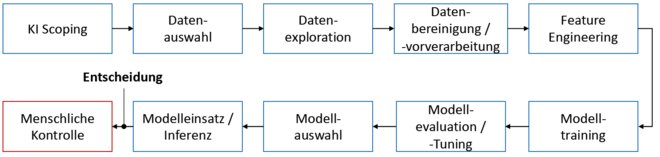
Abb. 1: Typische Entwicklungsphasen einer ML-basierten KI-Lösung. Bei jeder Phase, von der Auswahl der zu lösenden Problemstellungen unter technologischen wie auch wirtschaftlichen Kriterien (sogenanntes KI-Scoping) bis zur Art und Weise der Einbindung des Menschen, stehen maßgebliche Entwicklungsentscheidungen an.
Wie prüfen?
Bisher bestehen keine genauen Vorgaben für die Überprüfung eines ML-Systems, von offiziellen Standards ganz zu schweigen. Die wichtigsten Ansätze zur Entwicklung eines verbindlichen Regelwerks kommen vom TÜV Austria, dem Fraunhofer-Institut für Intelligente Analyse- und Informationssysteme IAIS und der Europäischen Kommission. Mit ihrem Entwurf für ein „Gesetz über Künstliche Intelligenz“ [Eur2021] versucht die Europäische Kommission aktuell, allgemeine Leitlinien für die Entwicklung von KI-Anwendungen zu schaffen. Diese sind jedoch oftmals zu abstrakt und enthalten kaum konkrete Anforderungen an Unternehmen und Entwickler.
Der TÜV Austria geht zusammen mit dem Institute for Machine Learning der Johannes Kepler Universität Linz in dem White Paper „Trusted Artificial Intelligence: Towards Certification of Machine Learning Applications“ weiter. Das Dokument stellt erste Ansätze zur Zertifizierung von ML-Systemen vor. Ein wesentlicher Bestandteil des Papiers ist ein Katalog zur Auditierung eines ML-Systems, der bestehende Kriterien aus der Softwareentwicklung einfließen lässt und auch ethische Fragen adressiert. Der Katalog beschränkt sich auf bestimmte Problembereiche wie überwachte Lernverfahren und weitgehend unkritische Anwendungen, legt aber einen Grundstein für weitergehende Zertifizierungsbemühungen.
Den zurzeit ausführlichsten Vorschlag für das Audit eines ML-Systems stellt der „Leitfaden zur Gestaltung vertrauenswürdiger Künstlicher Intelligenz“ [IAIS2021] des Fraunhofer IAIS dar. Dieser Leitfaden beinhaltet unter anderem Vorgaben für die strukturierte Identifikation KI-spezifischer Risiken in Hinblick auf die sechs Dimensionen der Vertrauenswürdigkeit: Fairness, Autonomie und Kontrolle, Transparenz, Verlässlichkeit, Sicherheit und Datenschutz. Darüber hinaus bietet er eine Anleitung zur strukturierten Dokumentation von technischen und organisatorischen Maßnahmen entlang des Lebenszyklus einer KI-Anwendung, die dem aktuellen Stand der Technik entsprechen. Alle drei Werke, der Entwurf der Europäischen Kommission, das White Paper des TÜV Austria und der Universität Linz wie auch der Leitfaden des Fraunhofer IAIS, haben wichtige Orientierungspunkte für das Audit des Transaction Miner gegeben.
Technische Erklärbarkeit
Der Gedanke liegt nahe, dass sich rein technisch beurteilen lassen müsste, ob ein System wie der Transaction Miner nachvollziehbare und faire Entscheidungen trifft. Es mangelt auch nicht an technischen Verfahren für eine solche Beurteilung. So hat sich beispielsweise die Anwendung sogenannter „Surrogatmodelle“ bewährt. Ein Surrogatmodell ist strukturell greifbarer, simuliert das ursprüngliche Modell und trifft weitgehend gleiche Vorhersagen. Für das Ausgangsmodell werden die wesentlichen Treiber damit nachvollziehbarer. Eine andere Methode besteht in kontrafaktischen Erklärungen. Es wird analysiert, welche leichten Veränderungen an den Eingabedaten zu einem anderen Ergebnis führen würden. Die Abhängigkeit des Ergebnisses von den Eingabedaten wird somit verständlicher. Darüber hinaus ist der aus der Spieltheorie stammende SHAP-Ansatz (Shapley Additive exPlanations) zu nennen. In der Spieltheorie wird mit SHAP beispielsweise die Vorhersage eines bestimmten Wertes erklärt, indem der gerechte Beitrag jedes Merkmals zur Vorhersage berechnet wird.
Empfehlenswert ist rund um die Erklärbarkeit auch, zwei Blickwinkel anzusetzen: die globale Erklärbarkeit eines Modells zur Darstellung der wichtigsten Treiber und Wirkzusammenhänge sowie die lokale Erklärbarkeit, die zu dem Ergebnis in einem bestimmten Fall führt. Einen Überblick über die Erklärbarkeit bietet [BuH2021].
Derartige technische Methoden sind aber in der Praxis oft nicht ausreichend, weil sie immer nur Aussagen für ein bestimmtes Modell treffen können. Bei einem kommerziellen Produkt wie dem Transaction Miner kommen aber je nach Kunde unterschiedliche Modelle zum Einsatz. Darüber hinaus müssen die Modelle beim Transaction Miner regelmäßig erneuert werden, um sie an die sich schnell verändernden Vorgehensweisen der Betrüger anzupassen.
Das Audit des Transaction Miner hat sich deshalb auf vier Komponenten entsprechend dem Entwicklungsprozess konzentriert, die der eigentlichen Modellentwicklung zugrunde liegen. Fairness und Erklärbarkeit werden später bei der Modellauswertung im Audit-Report adressiert.
Komponente 1: Feature Engineering
Bei der Beurteilung des Feature Engineering geht es vor allem darum, gängige Fehlerquellen auszuschließen. Gängige Fehlerquellen beim Feature Engineering sind Target Leaks oder Trainingsdaten, die versehentlich im Testset vorhanden sind, oder undurchsichtige Feature-Transformationen. Bei einem Target Leak sind Informationen der Zielvariablen bereits direkt in den Features vorhanden (beispielsweise soll die Lebensdauer einer Batterie in Jahren berechnet werden, die Features enthalten allerdings schon die Lebensdauer in Wochen).
Das Fraunhofer IPA sah in diesem Fall weder eine Gefahr von Target Leaks noch die Gefahr von Leaks der Trainingsdaten ins Testset. Auch die angewendeten Feature-Transformationen hat das Fraunhofer IPA als transparent bewertet.
Komponente 2: Modellauswahl und Training
Wie erwähnt stehen beim Transaction Miner regelmäßig die Auswahl, das Training und die Kalibrierung eines aktualisierten Modells an, damit das System die jeweils neuesten Betrugsmuster zuverlässig erkennen kann. Bei der Modellauswahl standen ursprünglich drei verschiedene Modelle zur Auswahl, deren Hyperparameter durch einen evolutionären Algorithmus bestimmt werden. Hyperparameter sind die Parameter des Modells, die zur Steuerung des Trainingsalgorithmus verwendet werden und deren Werte im Gegensatz zu anderen Parametern vor dem eigentlichen Training des Modells festgelegt werden müssen. Am Ende der Modellauswahl wird die Hyperparametereinstellung weiterverwendet, die die genauesten Ergebnisse liefert. Im Anschluss finden das Training des finalen Modells mit den ermittelten Hyperparametern sowie eine Kalibrierung statt. Dabei meint Kalibrierung die Justierung des Modellergebnisses auf eine aussagekräftige Betrugswahrscheinlichkeit.
Beim Training und der Modellauswahl ist zu beachten, dass nach Möglichkeit aktuelle, bekannte Frameworks verwendet werden und die Optimierung bezüglich sinnvoller Metriken stattfindet. Der Einsatz aktueller, bekannter Frameworks sorgt für die notwendige Transparenz und Nachvollziehbarkeit in diesem Schritt. Beim Transaction Miner wurde festgestellt, dass es sich bei allen eingesetzten Methoden um etablierte Verfahren und Frameworks handelt, abgesehen von einer eigens von Experian entwickelten Teilkomponente. Beim Einsatz selbstentwickelter Methoden ist eine entsprechende Dokumentation und Begründung für die Wahl der Methode besonders wichtig. Diese Dokumentation und Begründung wurden im Audit geliefert.
Komponente 3: Modellevaluation
Nach allen Trainings- und Kalibrierungsschritten erfolgt eine abschließende Evaluation des fertigen Modells auf dem Testdatenset. Am Ende eines vollständigen Trainingszyklus wird die „Konfusionsmatrix“ für das jeweilige Klassifikationsproblem erstellt. Aus dieser Matrix lässt sich beispielsweise die False-Positive-Rate ablesen. Zudem wird ein Kalibrierungsreport in Form eines Plots erzeugt.
Der Kalibrierungsreport liefert den Kunden, die AI:drian bzw. den Transaction Miner einsetzen, wichtige wirtschaftliche Kennzahlen. Dazu gehören etwa die Märkte und Anwendungsszenarien des jeweiligen Kunden mit Gewinn- und Verlustrechnungen. Darüber hinaus ist der Report wichtig, weil er Fairness in Form von Fehlerraten bezüglich sensibler Gruppen berücksichtigt. In einem ersten Schritt werden mittels einer Evaluation entlang unterschiedlicher Gruppen etwaige Benachteiligungen ausgeschlossen beziehungsweise identifiziert. Je nach Ergebnis können dann weitere Schritte eingeleitet werden. Zudem informiert der Report über den Einfluss der einzelnen Features auf die Resultate nach dem Training. Diese Information sorgt für höhere Transparenz beziehungsweise Nachvollziehbarkeit von Entscheidungen.
Komponente 4: Menschliche Kontrolle
Das Unbehagen an Künstlicher Intelligenz und Machine Learning beruht zu einem guten Teil auf der Vorstellung, technische Systeme würden sich – weitgehend menschlicher Kontrolle entzogen – in permanenten Selbstoptimierungsschleifen weiterentwickeln. Die Experten des Fraunhofer IPA sahen in diesem Fall jedoch keine Probleme. Bei der Modellentwicklung und Modellevaluation sind menschliche Experten und Risikoprüfer beteiligt und prüfen das Modell auf die Plausibilität der Ausgaben.
Weitere Informationen
[BuH2021]
Burkart, N. / Huber, M. F.: A Survey on the Explainability of Supervised Machine Learning. In: Journal of Artificial Intelligence Research (JAIR), 70, 2021, S. 245–317.
https://doi.org/10.1613/jair.1.12228, abgerufen am 10.9.2022
[Eur2021]
Europäische Kommission: Verordnung des Europäischen Parlaments und des Rates zur Festlegung harmonisierter Vorschriften für Künstliche Intelligenz (Gesetz über Künstliche Intelligenz) und zur Änderung bestimmter Rechtsakte der Union. 21.4.2021, https://eur-lex.europa.eu/legal-content/DE/TXT/HTML/?uri=CELEX:52021PC0206&from=EN, abgerufen am 10.9.2022
[IAIS2021]
Fraunhofer-Institut für Intelligente Analyse- und Informationssysteme IAIS: Leitfaden zur Gestaltung vertrauenswürdiger Künstlicher Intelligenz. Juli 2021,
https://www.iais.fraunhofer.de/content/dam/iais/fb/Kuenstliche_intelligenz/ki-pruefkatalog/202107_KI-Pruefkatalog.pdf, abgerufen am 10.9.2022
[TÜV2021]
TÜV Austria / Institute for Machine Learning der Johannes Kepler Universität Linz, Trusted Artificial Intelligence: Towards Certification of Machine Learning Applications. 17.3.2021,
https://arxiv.org/ftp/arxiv/papers/2103/2103.16910.pdf, abgerufen am 10.9.2022









