

In Abbildung 1 lässt sich erkennen, welche Tätigkeiten notwendig sind, um ein Machine-Learning-Modell zu pflegen.
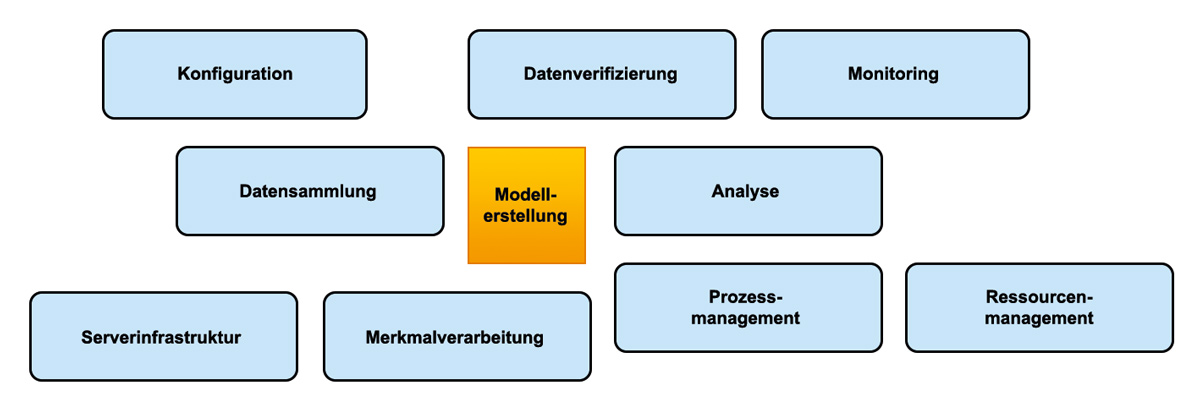
Abb. 1: Das Modellieren und Erstellen eines ML-Models ist nur ein kleiner Teil in der Kette eines ML-Projekts/Produktes.
Konzepte wie „Continuous Integration“ und Kubernetes
IT-Systeme wie soziale Netzwerke oder Streamingdienste, die schnell und in Echtzeit auf neue Gegebenheiten reagieren müssen, sind in den letzten Jahren enorm populär geworden. Die Architekturen dahinter sind dank Cloud-Technologien wie Kubernetes sehr skalierbar geworden, und neue Frameworks wie Kubeflow bringen das ganze Machine-Learning-Projekt auf einen internen oder externen Kubernetes-Cluster.
Das wird in folgendem Beispiel verdeutlicht: Ein Smartphone sammelt Bewegungsdaten und sendet diese unstrukturiert an einen zentralen Server. Je nachdem, wie reaktiv ein solches System auf neue Daten reagieren soll, muss zeitnah die Machine-Learning-Pipeline (s. Abb. 2) neu gestartet werden.

Abb. 2: Eine typische Machine-Learning-Pipeline
In Abbildung 3 ist zu erkennen, wie in unserem Beispiel der Machine-Learning-Ablauf umzusetzen ist.
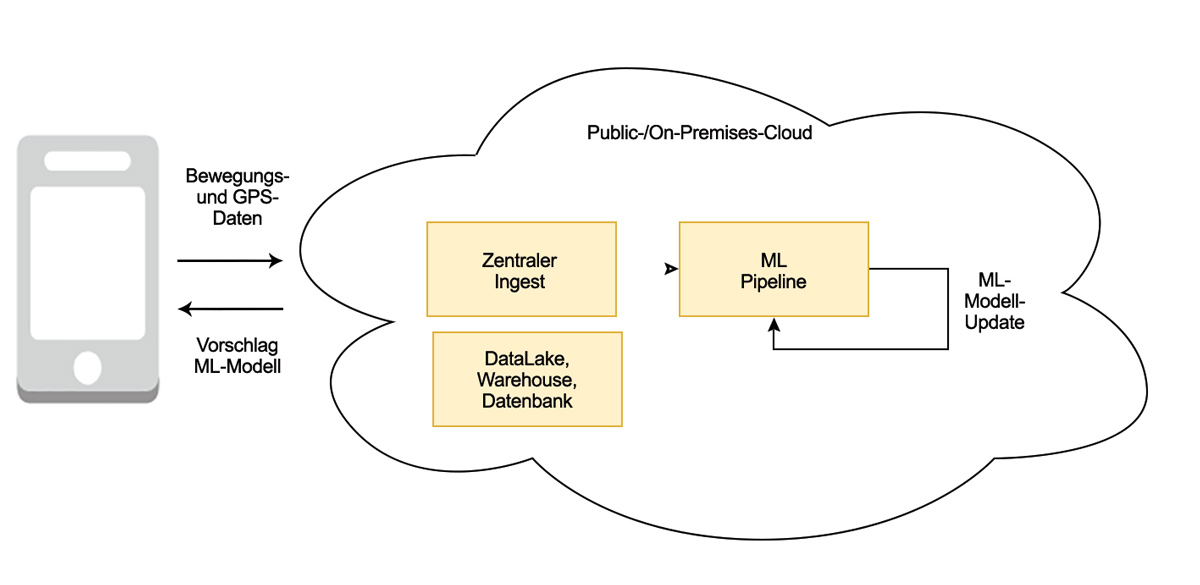
Abb. 3: Das mobile Endgerät sendet kontinuierlich Daten für das maschinelle Lernen.
Der Übergang zur vollen Softwarearchitektur
Vor allem in Echtzeit-Szenarien laufen Daten aus verschiedenen Quellen (IoT, Finanzen usw.) in der IT-Infrastruktur ein, sodass die KI neu trainiert und im Produkt auch wieder neu zur Verfügung gestellt werden muss. Dies ist eine hohe Anforderung an das Software-System.
Je nach Produkt und Szenario kann eine Cloud-Lösung durchaus sinnvoll sein. Es gibt aber auch triftige Gründe wie den Datenschutz, vor Ort im Rechenzentrum zu bleiben. Glücklicherweise erlauben Cloud-Technologien wie Kubernetes, dies neutral umzusetzen. Der Wechsel von einer öffentlichen zu einer privaten Cloud oder umgekehrt ist somit jederzeit möglich.
Einführung in Apache Airflow
Zentrale Steuereinheit für unseren Workflow ist Apache Airflow [Apa], ein auf Python basierendes Orchestrierungs-Framework. Wie in Abbildung 4 zu erkennen, kommuniziert Airflow mit den anderen Systemen, um den Ablauf zentral zu steuern.
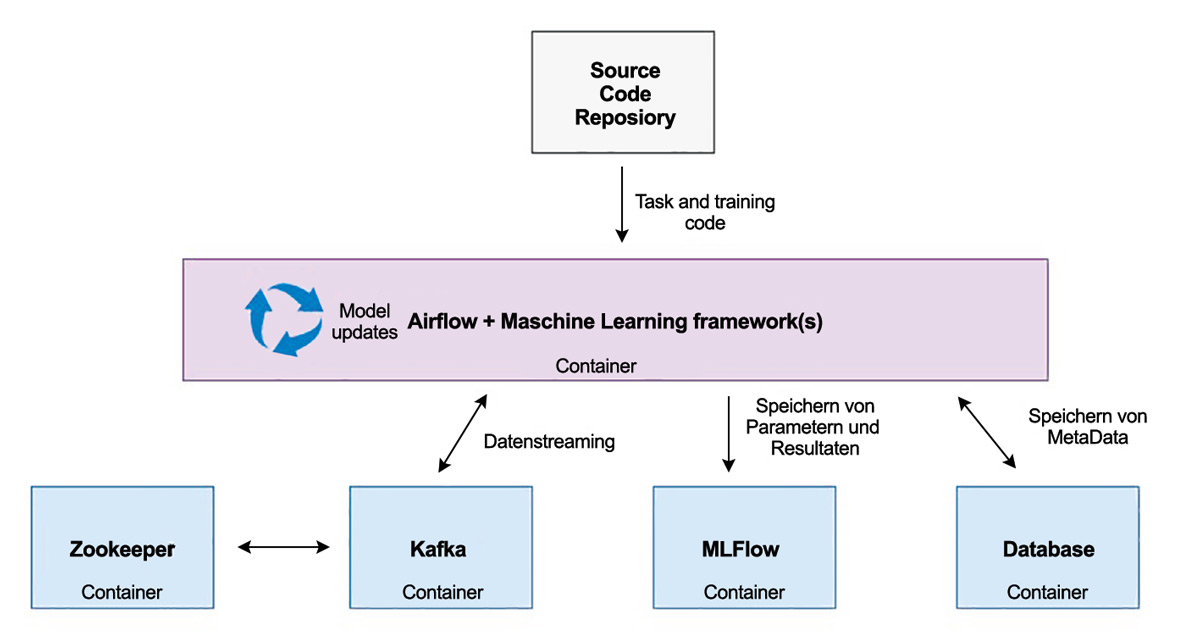
Abb. 4: Echtzeit-Machine-Learning in der Produktion
Das Hauptkonzept in Airflow sind sogenannte Directed Acyclic Graphs (DAGs) mit direktionalen Abhängigkeiten der einzelnen Tasks. Ein programmierter Task in einem DAG kann zwei Kategorien angehören:
- Operator: Es wird eine spezielle Operation ausgeführt, die selbst zum Beispiel ein Python-, Bash-, E-Mail- oder auch ein Datenbankoperator sein kann.
- Sensor: Der Task kann auf einen speziellen Zustand in Prozess oder Datenstruktur „hören“ und reagieren.
Ein DAG besteht aus mindestens einem Task, kann aber auch zu einem komplexen Geflecht verschiedener Tasks werden. In Abbildung 5 ist zu sehen, dass Airflow die Daten der gesamten Ausführung aller Workflows in einer eigenen Metadatenbank ablegt und dass ein „Executor“ für die Ausführung der Tasks zuständig ist.
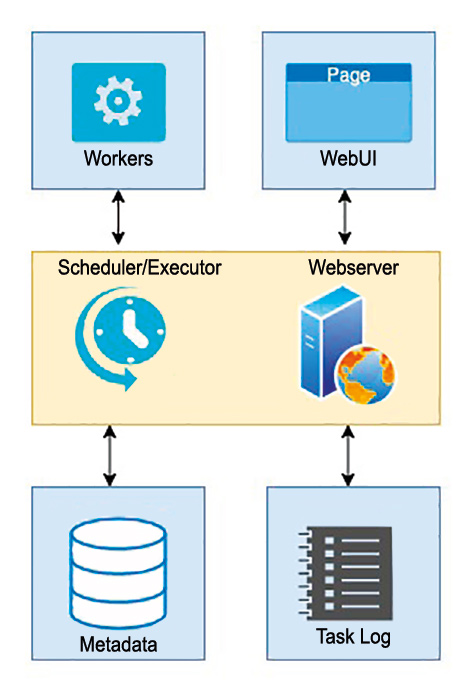
Abb. 5: Die Architektur von Airflow
Der „Scheduler“ ist in der Lage, die Workflows zu beliebig geplanten Zeiten – auch wiederholt – auszuführen. Im Prinzip steht hier ein flexibel programmierbarer Cron-Job in Python zur Verfügung.
Dass die Workflows in Airflow mittels Code umgesetzt werden, macht es sehr einfach, Praktiken des Software-Engineering wie Versionierung, Testen und Wartung umzusetzen.
Einführung in MLFLow
Das Framework MLFLow [MLf], ursprünglich von der Firma Databricks erstellt und inzwischen Open Source, erlaubt es, unser Modell zu protokollieren und zu verwalten. Hierzu stellt uns MLFLow drei Hauptbestandteile zur Verfügung:
- Tracking-API: Ergebnisse, Parameter und alle Metadaten eines ML-Modells können hier abgelegt und später verfolgt werden. So lässt sich zum Beispiel schnell feststellen, welchen Einfluss neue Hyperparameter oder Änderungen der Datenstruktur auf unser Modell haben.
- Projects-API: Damit lassen sich ML-Projekte einheitlich paketieren und alle erforderlichen Abhängigkeiten (zum Beispiel Python-Bibliotheken) beschreiben. So wird es zum Beispiel möglich, ML-Projekte zu teilen und von einem zentralen Ort wiederzuverwenden – MLFLow kümmert sich um die Abhängigkeiten.
- Models-API: Diese Programmierschnittstelle ermöglicht es, ML-Modelle in einem Standardformat zu speichern und später einfach ein Deployment zur Verfügung zu stellen, zum Beispiel per REST-Service. Es ist zu betonen, dass MLFLow alle gängigen Machine-Learning-Frameworks unterstützt, zum Beispiel SciKit, TensorFlow, Keras, Spark oder PyTorch.
Data-Streaming mit Kafka/Zookeeper
Nun braucht es eine Komponente, die mit Echtzeitdaten umgehen kann. Das Open-Source-basierte Apache Kafka ist eine verteilte Echtzeit-Streaming-Plattform, über die sich auch sehr große Datenmengen mittels einer „Producer-API“ an sogenannte „Topics“ verschicken lassen. Dieser „Publish&Subscribe“-Mechanismus erlaubt es Konsumenten, mit einer „Consumer-API“ auf neue Daten zu hören und diese dann zu verarbeiten.
Die „Producer“ und „Consumer“ kennen sich in der Regel nicht, die beiden Enden des Datenflusses sind somit entkoppelt. Dies erlaubt es der Plattform, sehr schnell und flexibel horizontal auf große Datenmengen zu skalieren.
Ein Kafka-Cluster besteht in der Regel aus mehreren „Brokern“. Apache Zookeeper ist eine Komponente im Kafka-Setup zur Koordination dieser „Broker“. Kafka/Zookeeper ist somit perfekt geeignet, um unsere Input-Daten von den Mobilgeräten zu verarbeiten.
Aufsetzen der Plattform
Nun kann mittels Docker das Container-Gerüst erstellt werden. In Listing 1 ist die „Docker-Compose“-Datei aufgelistet, welche die Installation der Komponenten abdeckt.
version: '1.0'
services:
postgres:
image: Postgres:9.6
container_name: postgres_container
airflow:
build: './airflow_docker'
container_name: airflow_container
restart: always
depends_on:
postgres
volumes:
./dags:/usr/local/airflow/dags
./dags:/usr/local/airflow/data
./models:/usr/local/airflow/models
ports:
"8080:8080"
command: webserver
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper_container
ports:
"2181:2181"
kafka:
image: wurstmeister/kafka
container_name: kafka_container
ports:
"9092:9092"
mlflow:
build: './mlflow_docker'
conainer_name: mlflow_container
ports:
"5000:5000"
command: 'mIn der Airflow-Konfiguration sieht man die Verzeichnisfreigaben, damit auf die lokalen DAGs, die in Python implementiert sind, zugegriffen werden kann.
Diese implementierten DAGs sind in Listing 2 zu sehen, wo ein DAG ein Keras-Modell mit neuen Daten aus Kafka versorgt, die Daten lädt und vorbereitet.
dag = DAG(
dag_id='update_Mobile_data_DAG',
default_args=args,
schedule_interval='@daily',
catchup=False,
)
task1 = PythonOperator(
task_id='get_data_from_kafka',
python_callable=get_data_from_kafka
dag=dag,
)
task2 = PythonOperator(
task_id='load_data',
python_callable=load_data,
dag=dag,
)
task3 = PythonOperator(
task_id='preprocessing',
python_callable=preprocessing,
dag=dag,
)
task4 = PythonOperator(
task_id='update_model',
python_callable=update_model,
op_kwargs = {'num_classes': NUM_CLASSES,
'epochs': EPOCHS,
'batch_size': BATCH_SIZE
},
dag=dag,
)
task1 >> task2 >> task3 >> task4Am Schluss wird das Modell neu trainiert. Hierzu werden „Python-Operatoren“ für die einzelnen Tasks benutzt.
Im letzten Task „update model“ wird mittels MLFLow unser Keras-Modell protokolliert und danach neu trainiert.
mlflow.set_tracking_uri('http://mlflow:5000')
with mlflow.start_run():
model = mlflow.keras.load_model(model:uri)
current_score = model.evaluate(x_test, y_test, verbose=0)
model.fit(x_new, y_new,
batch_size=kwargs['batch_size'],
epochs=kwargs['epochs'],
verbose=1,
validation_data=(x_test, y_test))
update_score = model.evaluate(x_test, y_test, verbose=0)
mlflow.log_metric('Epochs', kwargs['epochs'])
mlflow.log_metric('Batch size', kwargs['batch_size'])
mlflow.log_metric('test accuracy - current model', current_score[1])
mlflow.log_metric('test accuracy - updated model', updated_score[1])
mlflow.log_metric('loss - current model', current_score[0])
mlflow.log_metric('loss - updated model', updated_score[0])
mlflow.log_metric(
'Number of new samples used for training', x_new.shape[0])
if updated_score[1] - current_score[1] > 0:
mlflow.set_tag('status',
'the model from this run replaced the current version')
updated_model_name = 'model_' + str(time.strftime("%Y%m%d_%H%M"))
mldlow.keras.save_model(model, model_uri)
else:
mlflow.set_tag('status',
'the model from this run did not replace the current version')








