

In diesem Artikel wird zunächst eine Auswahl an aktuellen Java-Frameworks beschrieben. Im Anschluss zeigen wir eine Reihe von ML-Anwendungsfällen, welche mit den beschriebenen Frameworks umgesetzt werden können. Diese exemplarischen Anwendungsfälle stammen aus verschiedenen Branchen und verdeutlichen, welch enormes und vielfältiges Potenzial ML besitzt. Im dritten Abschnitt folgt eine Beispielimplementierung eines konkreten Anwendungsfalls: eine Clusterisierung auf historischen Flugdaten mittels ML.
Aktuelle Java-Frameworks
Hier werden die TOP10 der Java-Frameworks beschrieben.
Mahout
Mahout ist ein Open-Source-Framework, welches von der Apache Foundation entwickelt wird. Es ist vor allem für Statistiker, Data-Scientists und Mathematiker gedacht, um ihre eigenen ML-Algorithmen entwickeln zu können. Dies wird mit einer extensiven, verteilten Bibliothek für lineare Algebra erreicht. Mahout wirbt mit hoher Performanz, Skalierbarkeit und Flexibilität sowie mit dem Label, Enterprise-Ready zu sein, das heißt, nicht nur zur prototypischen Entwicklung von Algorithmen zu dienen, sondern diese auch in Produktion einsetzen zu können [Mahout].
Weka
Weka steht für Waikato Environment for Knowledge Analysis und wird von der Waikato Universität in Neuseeland gepflegt. Es ist ein besonders auf Data-Mining ausgelegtes Open-Source-Framework und unterstützt mit Schwerpunkt auf Klassifizierung auch Clusterisierung, Assoziationsanalyse, Zeitreihenvorhersage, Merkmalsauswahl und Erkennung von Anomalien. Weka kommt mit einem grafischen Interface, welches die Benutzbarkeit der mitgelieferten Algorithmen vereinfachen soll. Das Hauptsystem besteht aus Algorithmen für Lineare Algebra, Implementierung von ML-Algorithmen und einem Paketmanager, durch den das System erweitert werden kann [Waik].
JavaML
JavaML ist eine Sammlung an ML-Algorithmen, die auf Softwareentwickler und Forscher zugeschnitten ist. Sie kommt mit klar definierten Schnittstellen, die es erlauben, Gruppen von Algorithmen auf ähnliche Weise anzusprechen. Die Bibliothek kommt mit einer gut dokumentierten Codebasis und bietet viele Beispiele und Tutorien [JavaML].
Massive Online Analysis (MOA)
MOA ist eine Open-Source-Bibliothek, die sich auf Echtzeit-Daten-Analytics spezialisiert. Daher kann sie ML und Data-Mining auf Datenstreams besonders zeit- und speichereffizient durchführen. Im Zeitalter von wachsenden Datensets/-streams und dem Internet der Dinge (Internet of Things, kurz IoT) wird MOA als gute Lösung angeboten.
Das Framework ist in Java implementiert und stammt wie Weka von der Waikato Universität. Dadurch ist eine Interoperabilität gewährleistet und es kann auf Weka zurückgegriffen werden, wenn eine Skalierung nötig wird.
Darüber hinaus ist ein einfach erweiterbares Framework für neue Algorithmen vorhanden, welches im Moment eine starke Nutzung in der Data-Science-Community genießt [MOA, Waik].
Eclipse Deeplearning4j
Eclipse Deeplearning4j ist ein von Skymind entwickeltes Open-Source-Projekt und wurde 2017 der Eclipse Foundation gespendet. Es handelt sich um eine Deep-Learning(DL)-Bibliothek in Java und Scala mit dem Ziel, DL mit Mustererkennung und im Business-Bereich einzusetzen und verschiedene Daten zu verarbeiten (Sprache, Bild und Text). Als interessante Anwendungsfälle werden Anomalie-Erkennnug in Zeitreihendaten bei zum Beispiel Finanztransaktionen beworben. Der Fokus soll auf Business-Lösungen liegen und nicht auf Forschung. Dafür kommt Deeplearning4j mit einer GUI zum Training von Modellen und mit Hadoop-Unterstützung [DL4J].
TensorFlow
TensorFlow ist eine Open-Source-Bibliothek (Apache 2.0), die von Google entwickelt und sowohl intern für Forschung als auch für Produkte wie Gmail und Google-Fotos eingesetzt wird. Es handelt sich um eine in Python und C++ implementierte Bibliothek, was sie besonders performant machen soll. Google setzt intern darüber hinaus auf Spezialhardware, sogenannte Tensor Processing Units (TPUs), auf Machine-Learning ausgelegte Chips. Java kann über eine experimentelle Programmierschnittstelle genutzt werden, diese ist jedoch noch nicht stabil und weist im Moment Lücken auf [TensorFlow].
ELKI
ELKI steht für „Environment for Developing KDD-Applications Supported by Index Structures“ und ist eine Open-Source-Data-Mining-Software. Der Fokus liegt auf Forschung mit Blick auf unüberwachte Methoden in Cluster-Analysen, Datenbank-Indexierung und Ausreißererkennung. Sie erlaubt unabhängige Evaluierung von Data-Mining-Algorithmen und Datenmanagement-Aufgaben (einzigartig unter Data-Mining-Bibliotheken). Die implementierten Algorithmen bieten einen hohen Grad an Konfigurierbarkeit, was besonders der Forschung zugutekommt. Dies erlaubt auch einfache Evaluierungen und Performanz-Messungen von Algorithmen. Beispiele, in denen ELKI eingesetzt wurde, umfassen Clusterisierung von Pottwal-Vokalisationen, Weltraumflugoperationen, Fahrrad-Sharing, Verteilungen und Verkehrsvorhersagen [Elki].
JSAT
JSAT steht für „Java Statistical Analysis Tool“ und ist eine Open-Source-Java-Software (GPL3), um schnell Machine-Learning-Probleme zu lösen. Sie ist ohne externe Abhängigkeiten implementiert und wirbt mit einer der größten Sammlungen an Algorithmen im Vergleich zu vergleichbaren Frameworks. Einsatzgebiete sind zum Großteil Forschung und spezialisierte Anwendungen [JSAT].
Spark ML
Spark ML hat das Ziel, eine skalierbare und einfach zu nutzende Machine-Learning-Bibliothek zu schaffen. Neben Standard-ML-Algorithmen, wie Klassifizierung, Regression oder Clusterisierung, bietet sie Werkzeuge zum Umgang mit Daten, wie Featurization, Pipeline und Tools zur Persistierung von Modellen [MLlib].
MALLET
MALLET steht für „MAchine Learning for LanguagE Toolkit“ und ist eine spezialisierte Open-Source-Bibliothek, entwickelt von Andrew McCallum und Studenten von UMASS und UPenn. Die Bibliothek ist spezialisiert auf statistische NLP (Verarbeitung natürlicher Sprache), Cluster-Analyse, Themenmodellierung, Dokumentenklassifizierung und andere ML-Anwendungen auf Text [Mallet].
Anwendungsfälle
Im Folgenden werden fünf Anwendungsfälle beschrieben, in denen hervorgehoben wird, inwiefern klassische Methoden an ihre Grenzen stoßen und welches Potenzial ML in dem jeweiligen Beispiel bietet.
Vorhersageorientierte Polizeiarbeit (Predictive Policing)
Beim Predictive Policing geht es darum, potenzielle Verbrechen im Vorfeld zu verhindern oder auch vorherzusagen, wann und wo ein Täter erneut zuschlagen wird. Auf Basis dieser Schlüsse können Polizeistreifen bevorzugt in Gegenden geschickt werden, in denen eine erhöhte Wahrscheinlichkeit für eine bevorstehende Straftat besteht [Kras18, Krem18].
Anomalie-Erkennung
Der Ansatz der Anomalie-Erkennung basiert darauf, dass Cyber-Angreifer sich deutlich anders verhalten als berechtigte Nutzer. Durch den Einsatz von ML können die zugrunde liegenden Muster und dadurch potenzielle Angriffe erkannt werden [OmNJ13].
Vorausschauende Wartung (Predictive Maintenance)
Um Ausfällen vorzubeugen, werden Produktionsmaschinen in regelmäßigen Abständen gewartet. Dabei gilt es, die Personalkosten für die Wartung sowie gegebenenfalls die Kosten für den Stillstand der Maschine während der Wartung abzuwägen gegen die Kosten bei Ausfall der Maschine. Um diese Entscheidung zu optimieren und genau dann Wartungen durchzuführen, wenn ein Ausfall bevorsteht, hat beispielsweise Thyssenkrupp eine Software entwickelt, welche die Daten aller Aufzüge des Unternehmens analysiert und Muster erkennt, wann ein Ausfall bevorsteht [Müll18].
Echtzeit-Versicherungsprämien
Klassischerweise beruhen Versicherungsprämien auf der Risikobewertung historischer Daten. Dabei können aktuelle Trends entweder gar nicht oder nur durch menschliche Arbeit berücksichtigt werden. In Zeiten von immer größerer Datenverfügbarkeit ist es jedoch möglich, Versicherungsprämien in Echtzeit auf Basis einer Vielzahl von Parametern anzupassen [IBM15, Mies18].
Malaria-Ausbruchsprognose
Malaria ist eines der größten Probleme der öffentlichen Gesundheit in Indien und die weltweit häufigste Infektionskrankheit. Die frühzeitige Vorhersage eines Malaria-Ausbruchs ist der Schlüssel zur Kontrolle der Ausbreitung und damit der Reduzierung von Infizierten und Toten. Forscher aus Indien haben es geschafft, mit dem Klassifikationsalgorithmus „Support Vector Machine“ den Ausbruch von Malaria bereits 1 bis 20 Tage im Voraus vorherzusagen [Sha15].
Clusterisierung von historischen Flugdaten
Als beispielhafte Implementierung eines konkreten Anwendungsfalls stellt der dritte Teil des Artikels eine Implementierung des Clustering-Algorithmus K-Means vor. Als Grundlage wurden aus historischen Flugdaten aus den Jahren 1996 – 2018 Abflugort, Zielort, Datum und Preis verwendet. Die Daten stellt das U.S. Department of Transportation bereit und diese können direkt in verschiedenen Formaten geladen werden [USDoT].
Da uns keinerlei Zusammenhänge in den Daten bekannt sind, liegt unser Ziel in der explorativen Datenanalyse. Sie dient zur Aufdeckung von Mustern oder Zusammenhängen in diesen Daten und erfolgt mittels unüberwachtem Lernen (Unsupervised Learning). Eine sehr bekannte Methode ist die Clusterisierung, einer der bekanntesten Vertreter des Algorithmus K-Means. In diesem Beispiel setzen wir das Framework Deeplearning4J ein. Es liefert eine Implementierung von K-Means mit.
Im ersten Schritt laden und parsen wir die JSON-Daten. Da derartige Daten relativ groß sind (in unserem Fall 50 MB), ist für die explorative Datenanalyse grundsätzlich der Einsatz von Streaming angebracht. Anderenfalls müssten alle Daten auf einmal in den Speicher geladen werden. Das Framework Jackson bietet ein JSON-Streaming-API, dessen wir uns für das Laden und Parsen der Daten bedienen (s. Listing 1).
double[][] features = new double[limit][5];
JsonFactory jfactory = new JsonFactory();
try (JsonParser parser = jfactory.createParser(
new File("data/airfares/rows.json"));) {
JsonToken currentToken = parser.nextToken();
while (currentToken != null) {
if (currentToken == JsonToken.START_ARRAY &&
"data".equals(parser.getCurrentName())) {
int row = 0;
while ((currentToken = parser.nextToken()) ==
JsonToken.START_ARRAY) {
if (row == limit) { break; }
boolean processRow = true;
...
int col = 0;
while (processRow) {
currentToken = parser.nextToken();
if (col == 8) {
// year
features[row][0] = Integer.valueOf(parser.getText());
} else if (col == 9) {
// quater
features[row][1] = Integer.valueOf(parser.getText());
...
}
col++;
...
}
row++;
}
}
currentToken = parser.nextToken();
}
} catch (Exception e) {
...
}Im nächsten Schritt müssen die Daten in ein für Deeplearning4J vorgesehenes Format transformiert werden (s. Listing 2). Deeplearning4J nutzt hierfür den für lineare Algebra optimierten Datentyp INDArray, welcher aus der Bibliothek ND4J für wissenschaftliche Datenverarbeitung stammt.
double[] flat = ArrayUtil.flattenDoubleArray(features);
int[] shapeFeatures = new int[] { limit, 5 };
int[] shapeLabels = new int[] { limit, 1 };
INDArray dFeatures = Nd4j.create(flat, shapeFeatures, 'c');
Nd4j.shuffle(dFeatures, 1);
int[] shapeSubFeatures = new int[] { limit, 4 };
INDArray subFeatures = dFeatures.get(NDArrayIndex.all(),
NDArrayIndex.interval(1, 5));Anschließend kann die Clusterisierung erfolgen (s. Listing 3). Dem Algorithmus K-Means wird eine Distanzfunktion, in unserem Fall die Manhattan-Distanz, übergeben. Sie gibt den Abstand zwischen zwei Punkten als Summe der absoluten Differenzen ihrer Einzelkoordinaten an. Die Verwendung der Manhattan-Distanz gilt in K-Means als robuster als die der euklidischen Distanz. Wennnämlich zwei Punkte in den meisten ihrer Koordinaten nahe beieinanderliegen, bei einer Koordinate jedoch nicht, fällt diese eine Koordinaten-Abweichung bei der euklidischen Distanz schwer ins Gewicht, während die Manhattan-Distanz diese Abweichung nicht „überbewertet“, denn hier wird die Distanz durch die überwiegende Nähe/Übereinstimmung der anderen Koordinaten beider Punkte beeinflusst. Die unterschiedlichen Abstandsfunktionen und deren Eigenschaften sowie der Nachteil der euklidischen Distanz, dass ein „Ausreißer“ in den Koordinaten die anderen Koordinaten dominiert, ist in der mathematischen Fachliteratur [Loo12], [Wil97] näher beschrieben.
INDArray cSubFeatures = Nd4j.create(shapeSubFeatures);
INDArray cLabels = Nd4j.create(shapeLabels);
int maxIterationCount = 5;
int clusterCount = 5;
String distanceFunction = "manhattan";
KMeansClustering kmc = KMeansClustering.setup(
clusterCount, maxIterationCount, distanceFunction);
List<Point> vectors = Point.toPoints(subFeatures);
ClusterSet cs = kmc.applyTo(vectors);
List<Cluster> clsterLst = cs.getClusters();
int clusterNum = 0;
int i = 0;
for (Cluster c : clsterLst) {
for (Point p : c.getPoints()) {
cSubFeatures.putRow(i, p.getArray());
cLabels.putScalar(i, clusterNum);
i++;
}
clusterNum++;
}
DataSet dataSet = new DataSet();
dataSet.setFeatures(cSubFeatures);
dataSet.setLabels(cLabels);Das Ergebnis der Clusterisierung ist in Abbildung 1 in Form eines Scatterplots und in Abbildung 2 in einer dreidimensionalen Ansicht dargestellt. Die Visualisierung wurde mit dem Framework Jzy3d, eine auf OpenGL basierende Open-Source-Bibliothek für wissenschaftliche Visualisierungen, umgesetzt. Es sei angemerkt, dass auch die zweidimensionale Ansicht letztlich mittels Jzy3d umgesetzt wurde – das hatte ausschließlich Performanzgründe. Im ersten Versuch wurden die 2D-Scattercharts mit dem Framework JfreeChart implementiert, welche jedoch für eine sehr große Punktmenge nicht skalierte. Jzy3d bietet auch ein API für 2D-Scattercharts und ist dank der OpenGL-Unterstützung in der Datenvisualisierung hoch skalierbar.
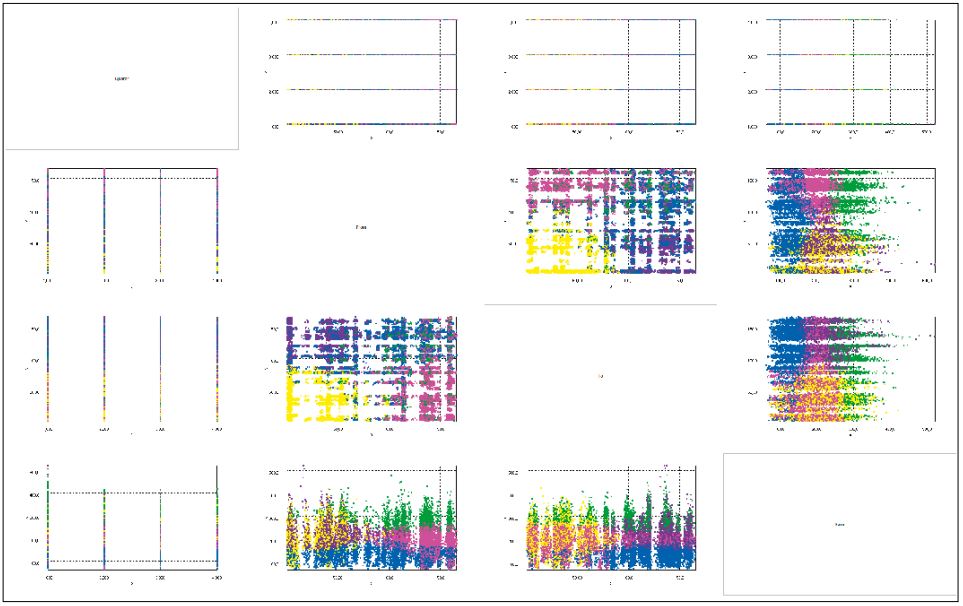
Abb. 1: 2D-Clustering: Scatterplot
Im Scatterplot sind die Beziehungen zwischen allen Parametern Quartal, Start, Ziel und Preis zu sehen. Die fünf vom Algorithmus gefundenen Cluster geben Flüge mit Ähnlichkeiten zwischen den Parametern an. Es kann grob zwischen den drei Preissegmenten niedriges Preissegment/Billigflüge, mittleres Preissegment und hochpreisiges Segment unterschieden werden. Die Flughäfen werden von ID-Nummern repräsentiert und lassen sich grob in zwei Hälften teilen (untere Hälfte: bis ungefähr ID-Nummer 80, obere Hälfte: ab ungefähr ID-Nummer 80).
Gelb sind Flüge, die von Flughäfen in der unteren Hälfte starten und an Flughäfen im gleichen Cluster landen. Diese Flüge finden sich in jedem Preissegment. Blau sind Billigflüge, die von Flughäfen nahezu überall starten und primär an Flughäfen in der oberen Hälfte landen. Rosa sind Flüge aus dem mittleren bis teilweise niedrigen Preissegment, die von Flughäfen der oberen Hälfte starten und nahezu überall landen. Grün startet und landet analog zu Rosa, befindet sich jedoch im hochpreisigen Segment. Lila Flüge befinden sich im mittleren Preissegment. Sie starten von Flughäfen der unteren Hälfte und landen an Flughäfen der oberen Hälfte.
Beim Vergleich von Quartal und Preis erkennt man, dass es über alle Quartale hinweg Flüge in allen Preisklassen gibt und dass sich die gefundenen Cluster in allen Quartalen wiederfinden (vgl. Abb. 2). Es existieren also in keinem der Quartale Auffälligkeiten beim Preis, bis auf die Ausnahme, dass gegenüber den anderen Quartalen im vierten deutlich höhere Flugpreise auftreten.
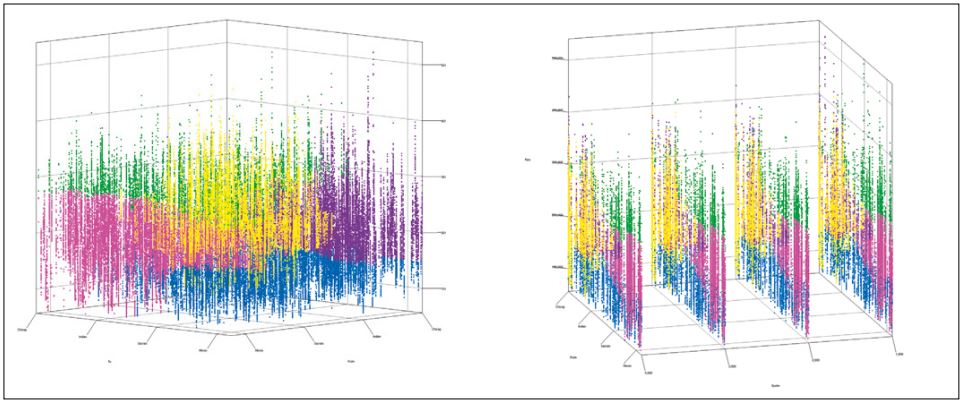
Abb. 2: 3D-Clustering: From – To/Quartal – Preis
Literatur und Links
[DL4J]
Deeplearning4j: Deep Learning for Java,
https://deeplearning4j.org/
[Elki]
Elki Project, Github,
https://elki-project.github.io
[IBM15]
IBM Corporation, Harnessing the power of data and analytics for insurance, IBM Analytics, 2015,
https://www.the-digital-insurer.com/wp-content/uploads/2016/06/715-IMW14672USEN.pdf.
[JavaML]
Java Machine Learning Library,
http://java-ml.sourceforge.net/
[JSAT]
E. Raff, Github JSAT: Java Statistical Analysis Tool,
https://github.com/EdwardRaff/JSAT
[Kras18]
Prof. Dr. S. Krasmann: Forschungsprojekt – Predictive Policing, Universität Hamburg, https://www.wiso.uni-hamburg.de/fachbereich-sowi/professuren/hentschel/forschung/predictive-policing.html
[Krem18]
St. Krempl, Predictive Policing: Die Polizei arbeitet verstärkt wie ein Geheimdienst, heise online, 29.3.2018,
https://www.heise.de/newsticker/meldung/Predictive-Policing-Die-Polizei-arbeitet-verstaerkt-wie-ein-Geheimdienst-4008214.html
[Loo12]
R. Loohach, K. Garg, Effect of Distance Functions on K-Means Clustering Algorithm, in: Int. J. of Computer Applications, 49 (6), s. https://www.researchgate.net/publication/269670685_Effect_of_Distance_Functions_on_ Simple_K-means_Clustering_Algorithm
[Mahout]
The Apache Software Foundation,
https://mahout.apache.org
[Mallet]
MAchine Learning for LanguagE Toolkit, UMASS AMHERST,
http://mallet.cs.umass.edu/
[Mies18]
D. Miessler, The Future of Insurance is Real-time Auto-Adjusted Premiums, 5.12.2018, https://danielmiessler.com/blog/the-future-of-insurance-is-real-time-auto-adjusted-premiums
[MLlib]
Machine Learning Library (MLlib) Guide,
https://spark.apache.org/docs/latest/ml-guide.html
[MOA]
MOA (Massive Online Analysis),
https://github.com/waikato/moa
[Müll18]
B. Müller, Vorausschauende Wartung in der Industrie 4.0 – Der größte Störfaktor ist der Mensch, in: WirtschaftsWoche, 13.4.2018,
https://www.wiwo.de/unternehmen/mittelstand/hannovermesse/vorausschauende-wartung-in-der-industrie-4-0-der-groesste-stoerfaktor-ist-der-mensch/21166908.html
[OmNJ13]
S. Omar, A. Ngadi, H. H. Jebu, Machine Learning Techniques for Anomaly Detection – An Overview, in: Int. J. of Computer Application, 79 (2), s.
https://pdfs.semanticscholar.org/0278/bbaf1db5df036f02393679d485260b1daeb7.pdf
[Sha15]
V. Sharma u. a., Malaria Outbreak Prediction Model Using Machine Learning, in: Int. J. of Advanced Research in Computer Engineering & Technology (IJARCET), 4 (12), s.
https://pdfs.semanticscholar.org/2ce3/631949498f6f40cf3b9ab4096c082f1d0047.pdf
[TensorFlow]
www.tensorflow.org
[Waik]
Machine Learning at Waikato University, Weka,
https://www.cs.waikato.ac.nz/ml/index.html
[Wil97]
D. R. Wilson, T. R. Martinez, Improved Heterogeneous Distance Functions, in: J. of Artificial Intelligence Research, 6 (1997)









