

Der „Hype“ um Lean- und Agile-Methodik in der Softwareentwicklung ist seit Jahren ungebrochen und wird von Fachbereichsseite und Management, in vielen Unternehmen, zum Teil mit überzogenen Erwartungen und zum Teil unter kritischer Beobachtung begleitet. Es wird oft verkannt, dass in agilen Vorgehensmodellen Mechanismen genutzt werden, die aus dem klassischen Qualitätsmanagement abgeleitet sind. Bei genauer Betrachtung ist zu erkennen, dass der Deming-Zyklus [Wiki] aus Plan – Do – Check – Act (PDCA) bereits in agilen Methoden integriert ist.
Als Lean Quality Management unterstützen wir die Entwicklungsteams, indem wir die Bereitstellung von Kennzahlen und Auswertungen automatisieren und somit die notwendige Transparenz für die Weiterentwicklung und Optimierung unserer Prozesse herstellen.
Weshalb überhaupt messen und nachverfolgen – passt das zu Agile?
Die Komplexität hinter Kennzahlen muss zielgruppengerecht aufgeschlüsselt, vermittelt und visualisiert werden.
Im Zuge eines der größten IT-Konzernprogramme der Deutschen Bahn [DB17] wurde eine Dashboard-Lösung umgesetzt, welche sich abhebt vom bisherigen klassischen Reporting und uns Kennzahlen und Visualisierungen auf Agile-Enterprise-Ebene liefert. Es war eine große Herausforderung, die richtige Balance zwischen einem übergreifenden Regelwerk und förderlichen Freiheitsgraden von über 30 Agile-Teams zu finden.
Agile Forecasting mit Dashboard-Lösungen
Das Management will auf der einen Seite, dass agile Methodik umgesetzt und gelebt wird – auf der anderen Seite längerfristige Schätzungen, Meilensteine und Verbindlichkeit. Kurzfristig betrachtet bieten agile Vorgehensmodelle wie Scrum zum Beispiel Burndown Charts als Lösung an – wie sieht es jedoch mit den genannten längerfristigen Zielen und Schätzungen aus?
Wir glauben, eine innovative Lösung für diese Herausforderung gefunden zu haben, welche sich nun seit Jahren bewährt hat. Die gesamten Entwicklungsschritte sind feingranular auf verschiedenen Detailstufen in einem Ticket-System abgebildet. Angefangen bei der Portfolioebene hin zu Entwickleraufgaben. In den höheren Ebenen werden Aufgaben nicht geschätzt, sondern nach WSJF (Weighted shortest Job first) priorisiert. In den Ebenen darunter können wir auf Quartalsebene unsere Programminkremente planen. Dieses Vorgehen ist im Rahmen von SAFe (Scaled Agile Framework) bereits länger bekannt.
Mithilfe des Business Intelligence-Tools Qlik Sense [Qlik] haben wir eine Lösung implementiert, welche uns ein Forecasting auf Quartalsebene ermöglicht – mit einer Abweichung von rund 10 Prozent pro PI (Program Increment). Diese Lösung ermöglicht es, faktenbasiert und nachvollziehbar die Entwicklung zu verfolgen.
Die Kennzahlen beispielsweise für die Anzahl der Story Points werden automatisiert aus den Quellsystemen geladen und können in verschiedenen Aggregationsstufen dargestellt werden, zum Beispiel die Gesamtsicht oder pro Team und Sprint. Sämtliche Bereiche des SDCL (Software Development Life Cycle) sind kennzahlentechnisch abgebildet.
Agile Forecasting kann nur dann gut funktionieren, wenn eine gewisse Menge an Erfahrung bezüglich der Leistungs- und Schätzfähigkeit in den Teams vorhanden ist und eine ausreichende Anzahl von Datensätzen über die geleistete Arbeit vorliegt. Ein weiterer Aspekt ist das Umfeld und die Art der Softwareentwicklung. Neue Softwareprodukte, welche maximale Agilität benötigen, da man zeitnah auf Ereignisse am Markt oder Feedback reagieren will, werden weniger von einer langfristigen Sicht profitieren können. Je dynamischer die erwartete Zukunft, desto ungenauer wird diese.
Klassisches Reporting fand in regelmäßiger Taktung statt, das Agile Reporting ermöglicht durch die Automatisierung jederzeit Zugriff auf die aktuellen Zahlen. Ebenfalls können die Informationen im Dashboard durch die Nutzer individuell auf ihren Informationsbedarf angepasst werden – statt sich mühsam durch Reports mit bis zu 100 Seiten durchzuarbeiten. Durch eine Datenindexierung können Beziehungen zwischen Kennzahlen über verschiedene Dimensionen verstanden werden und neue Erkenntnisse fördern, die auch durch Machine Learning-Algorithmen unterstützt werden. Bisherige Reports oder Dashboards waren eine Ansammlung von statischen Daten und Visualisierungen.
Im Rahmen des Konzernprogramms wird eine Architekturerneuerung für die bestehende Vertriebsplattform durchgeführt. Daraus ergibt sich, dass ein Teil des Scope fix und im Backlog hinterlegt ist. Die zugehörigen Epics sind bereits grob geschätzt. So kann unter anderem auf Basis der Velocity der letzten Programminkremente rollierend ein Forecast erstellt werden, wann die Teams diesen
Scope bearbeitet haben. Ziel ist es, dass der errechnete Termin vor dem voraussichtlichen Programmende liegt und noch einen Puffer für die Integration von notwendigen fachlichen Weiterentwicklungen bietet. Als Ableitung aus diesem Forecast können Rückschlüsse über das notwendige Sizing der einzelnen Entwicklungsteams gezogen werden. Dies ermöglicht eine Diskussion mit den zuständigen Scrum Mastern und gegebenenfalls eine Anpassung der Planung.
Klassische Projektkennzahlen spielen weiterhin eine wichtige Rolle
Das Konzernprogramm läuft über mehrere Jahre und beschäftigt viele verschiedene Teams und Stakeholder. Entsprechend sind auch die klassischen Projektkennzahlen zu Scope, Budget, Time, Quality und Risk abgebildet. Diese werden nicht mehr als Statusreport verteilt, sondern sind in einem Dashboard transparent einsehbar und individuell auswertbar. Ein großer Vorteil dieser Lösung ist die Interaktion mit den Daten beziehungsweise Kennzahlen. Durch intelligente Filterund Suchmöglichkeiten können neue Erkenntnisse von den Nutzern selbst erlangt werden.
Auf dem Weg zur Definition eines einheitlichen Leistungsbegriffs hatten wir fruchtbare Diskussionen in den Teams und mit der Programmleitung. Diese waren wichtig, um ein gemeinsames Verständnis herzustellen, und haben das Interesse, die Leistung feingranular aufzuschlüsseln, gezeigt. Die Leistung der Teams messen wir nun nicht nur an der reinen Scope-Bearbeitung nach Plan, sondern erfassen auch weitere Leistungsfaktoren wie die Arbeit an nichtfunktionalen Anforderungen und Innovationsthemen sowie die Korrektur von Defects.
Was waren die wichtigsten Erkenntnisse auf technischer Ebene?
Die Auswertung von historischen Daten in Bestandssystemen ist hochkomplex und muss gut geplant werden. Teilweise werden sehr große Datenmengen verarbeitet, welche die Schnittstellen von angebundenen Systemen schnell an ihre Grenzen bringen können. Entsprechend wichtig ist die Einbindung der jeweiligen Fachabteilungen sowie das Abstimmen von Vorgaben und angepassten Schnittstellen. Darüber hinaus sind auch die Anforderungen des Datenschutzes zu beachten, sodass die Auswertung von Daten einzelner Mitarbeiter in den Dashboards ausgeschlossen ist. Um dies zu gewährleisten, sollten diese sensiblen Daten erst gar nicht exportiert werden.
Je nach Beschaffenheit der Systeme und des Umfelds stellt sich oft die Frage: Data Warehouse oder Data Lake? Wir haben einen Hybrid-Weg gewählt und nutzen beide Technologien im Parallelbetrieb. So können wir von den Vorteilen aus beiden Welten profitieren (siehe Abbildung 1).
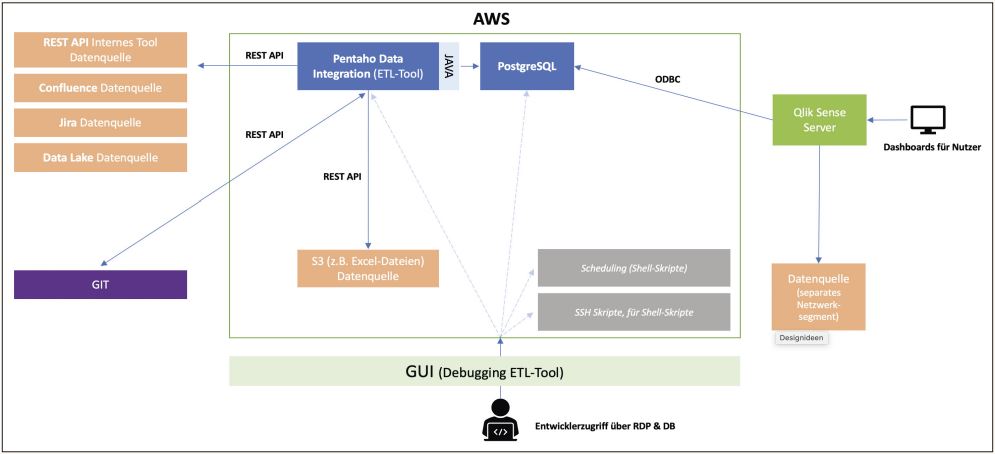
Abb. 1: Systemlandschaft ETL-Strecke (Data Lake als Datenquelle)
Im Verlauf des Projekts haben wir die Erkenntnis gewonnen, dass es im Rahmen des Reportings wenig Gründe gibt, vollständig auf einen Data Lake zu setzen, sofern man nicht deutlich mehr Datenquellen (und Daten) verarbeiten muss. Besonders interessant wird der Einsatz erst dann, wenn Daten aus verschiedenen Systemen parallel durchsucht und verarbeitet werden müssen, beispielsweise für die dynamische Erstellung von Dashboards. Ein weiterer Punkt ist der erhöhte Aufwand, die Daten in einer heterogenen Systemumgebung mit spezifischen Anforderungen an Sicherheit und Datenschutz zusammenzuführen.
Anfänglich war die Systemperformanz kein Thema. Jedoch sollten die Anforderungen und Kapazitäten der Datenquellen beachtet werden. Gegebenenfalls entstehen Mehrkosten, wenn diese ausgebaut werden müssen. Ein Refactoring kann dazu beitragen, diese Kosten zu minimieren. Durch Anpassungen der Abfragen konnten wir die Ladezeit verkürzen und die Last auf die Datenquellen oder APIs deutlich reduzieren.
Welches waren die wichtigsten Erkenntnisse auf fachlicher Ebene?
Eine vergleichende Performanzmessung zwischen verschiedenen Agile Teams ist nicht zielführend und ohne Rahmenbedingungen wie der Normalisierung von Story Points auch nicht sinnvoll möglich. Eine Alternative bietet die Orientierung am geschaffenen Geschäftswert, jedoch muss zwingend die unterschiedliche Komplexität von Technologien beachtet werden – ansonsten vergleicht man Äpfel mit Birnen. Je schneller funktionierende Software beim Endkunden landet, desto schneller kann man geleisteten Entwicklungsaufwand ins Verhältnis zum geschaffenen Geschäftswert stellen!
Die Nivellierung von geleisteten Story Points über mehrere Programminkremente, respektive generell Zeitintervalle, ist eine Methode, welche in klassischen Wasserfall-Projekten (mit Personentagen) Orientierung bieten kann, jedoch in einer agilen Umgebung und einem dynamischen Markt mit stetig neuen Herausforderungen nicht angewendet werden sollte, um Aussagen zur Performanz zu treffen. Davon ausgenommen ist die Verwendung solcher Daten für Prognosen und Schätzungen – mit entsprechender Unschärfe. Letztere benötigen entsprechend eine saubere Datenbasis – je weniger strukturiert und konsistent die Datenbasis gepflegt wurde, desto höher die Aufwände für die Datenanalyse und spätere Extraktions- und Transformationsprozesse auf technischer Ebene.
Diverse Faktoren müssen berücksichtigt werden, die folgenden drei sind Beispiele:
- Wie hat sich die Velocity in den letzten Monaten entwickelt? Wir haben einen Algorithmus entwickelt, welcher neben der Anzahl der geleisteten Story Points beziehungsweise der Velocity auch statistische Methoden zur Korrektur nutzt. Ein Beispiel ist die Korrektur der Normalabweichung.
- Wie ist das Verhältnis von Mitarbeiteranzahl zur Velocity? Werden Feiertage oder Innovations-Sprints berücksichtigt?
- Sollte eine Normierung von Story Points, im Zuge einer besseren Vergleichbarkeit, durchgeführt werden?
Ein weiterer essenzieller Aspekt bei der Betrachtung von Entwicklungsteams ist eine Reihe von Kennzahlen, welche sich in der Praxis bewährt haben:
- Deployment-Frequenz
- Lead-Time für Anpassungen/Änderungen,
- Rückrollgeschwindigkeit von Releases und Fixes (MTTR),
- Verhältnis von Änderungen zu Fehlern (Change Failure Rate).
Um die Motivation der Entwicklungsteams längerfristig zu gewährleisten, ist die Empfehlung, sich nicht ausschließlich auf quantitativ zu erhebenden Maßeinheiten zu fokussieren, sondern den Teams abstrakte, aber klare Ziele vorzugeben – die Lösungen sollten von den Teams kommen. Eine Empfehlung wäre hier die Nutzung von Objektive Key Results mit den genannten Kennzahlen.
Fazit
Es ist essenziell, bestehende Kennzahlen, Prozesse und Ergebnisartefakte immer wieder strukturiert zu hinterfragen. Das Mindset steht hier im Vordergrund. Entsprechend zielen die Maßnahmen hinter unserer PD-CA-Implementierung nicht auf Kontrolle ab, sondern basieren einerseits auf Vermittlung von Konzepten zur Verbesserung der Leistungsfähigkeit, andererseits auf Transparenz der eigentlichen Leistung. Diese Maßnahmen betrachten jedoch immer die Gesamtleistung. Im Fokus stehen Qualität und Lieferversprechen.
Referenzen
[DB17]
https://digitalspirit.dbsystel.de/so-wird-der-vertrieb-fit-fuer-die-zukunft-gemacht









