In den letzten 10 Jahren haben A/B-Tests Einzug in die Produktentwicklung gefunden. Allerdings stellen wir als Autoren fest, dass immer öfter in unserem Umfeld A/B-Tests in Organisationen angstvoll und mit hohem Aufwand getrieben werden, ohne dass dies zu besseren Ergebnissen führt. Immer häufiger stellen wir fest, dass A/B-Tests als Rückversicherung genutzt werden, um ja nicht das Falsche zu tun, und somit schleichend zur Verhinderung von Innovationen in der Produktentwicklung führen.
Habt Mut, Entscheidungen zu treffen, nur Stillstand ist schädlich. Aus falschen Entscheidungen kann man lernen, wer keine Entscheidungen trifft, steht automatisch still.
Daher glauben wir als Autoren, dass es Zeit ist, etwas aufzuräumen. Dazu gehen wir zunächst kurz auf die allgemeine Methodik von A/B-Tests an dem hypothetischen Beispiel von naschwerk.de ein, beschreiben dann einige erfolgreiche und erfolglose A/B-Tests aus der realen Welt, um am Ende unser Fazit mit Kritik und Tipps für bessere A/B-Tests zu ziehen.
Die Methodik von A/B-Tests
Beispielfirma naschwerk.de
Zur Beschreibung betrachten wir die hypothetische Webseite „naschwerk.de”. Auf dieser Webseite gibt es Produktinformationen und Nutzerbewertungen rund um Schokolade, und es werden erlesene Schokoladen im Abonnement verkauft. Es gibt eine Premium-Mitgliedschaft, die monatlich 10 € kostet und die dem Kunden jeden Monat eine besondere Tafel Schokolade sichert.
Außerdem gibt es eine Basis-Mitgliedschaft, in der die Nutzer Informationen zu Schokolade, Nutzerbewertungen und Auskünfte zur Produktion und Nachhaltigkeit abrufen können. Diese Basis-Mitgliedschaft wird rege besucht und es gibt auf der Website aktuell einen Teaser, auf dem der Upsell zur Premium-Mitgliedschaft beworben wird.
naschwerk.de: Test von Varianten
Nun sollen verschiedene neue Varianten zum Upsell zur Premium-Mitgliedschaft getestet werden. Ziel ist es dabei, eine möglichst hohe Konversion von Basis auf Premium zu erreichen. Dazu wird eine neue Variante der Upsell-Seite gegen die bestehende Variante getestet.
naschwerk.de: Vorgehen
Beide Upsell-Seiten (UF1 und UF2) werden live gestellt und jeweils 50 Prozent des Besucherstroms werden zufällig auf jeweils eine Upsell-Seite geleitet. Es wird gemessen, wie viele Nutzer täglich die Seite besuchen und wie häufig auf den Seiten der Upsell-Link auf die Premium-Mitgliedschaft geklickt wird.
naschwerk.de: Ergebnisse
In unserem hypothetischen Fall lassen wir den Vergleich der beiden Seiten über 20 Tage laufen und versuchen herauszufinden, ob eine Variante signifikant besser konvertiert als die andere. Dabei gehen wir, wie landläufig üblich [Wiki], davon aus, dass „signifikant” ein Konfidenzlevel von 95 Prozent bedeutet. Das heißt im Klartext, wir irren uns nur mit maximal 5 Prozent Wahrscheinlichkeit, weil wir genügend statistische Daten gesammelt haben. Hier der Vollständigkeit halber die Daten, ein kurzer Blick auf Abbildung 1 reicht.
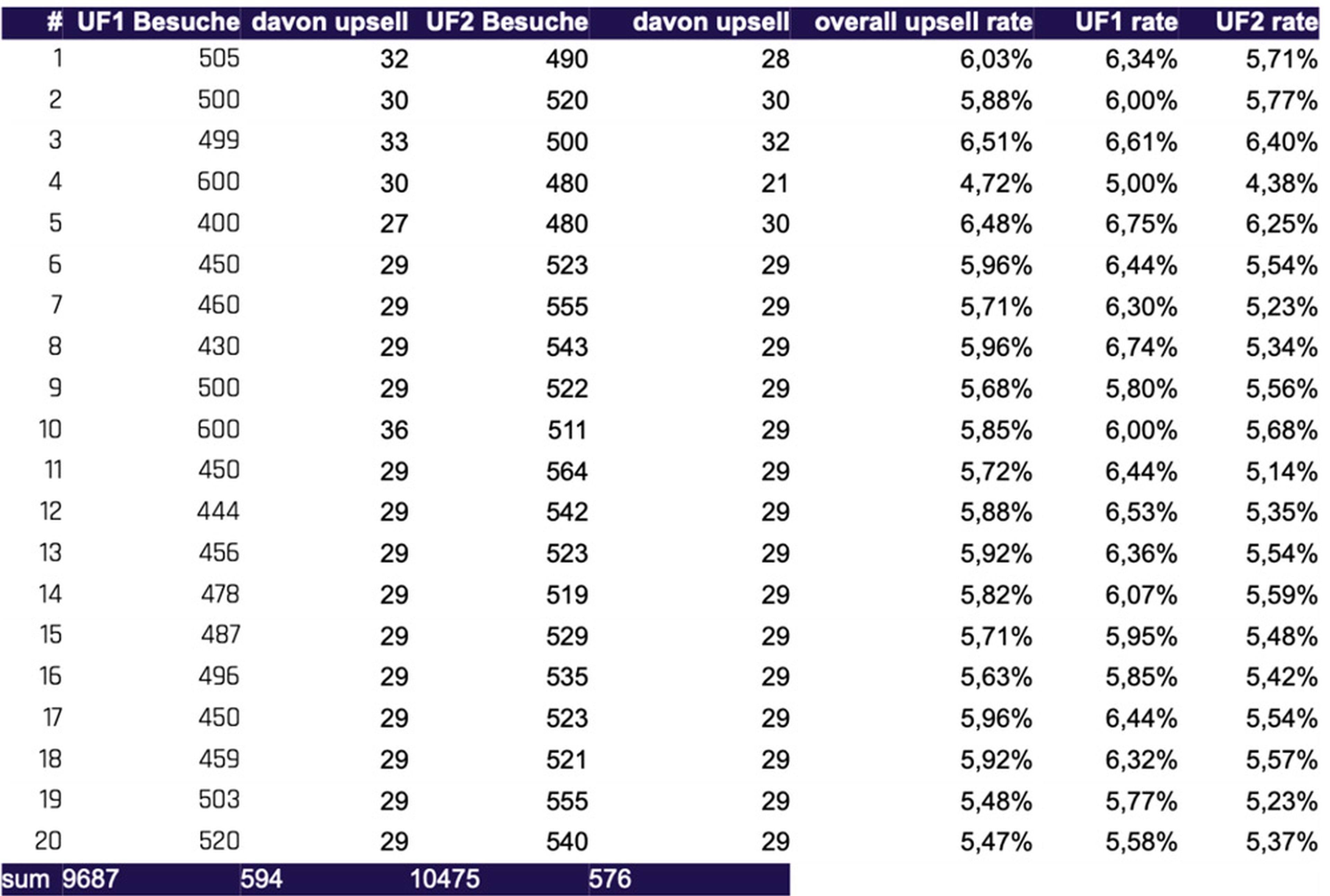
Abb. 1: Beispiel-Tabelle und Grafik naschwerk.de [ABT]
In Abbildung 2 sieht es so aus, als ob UF1 systematisch deutlich besser performt als UF2.
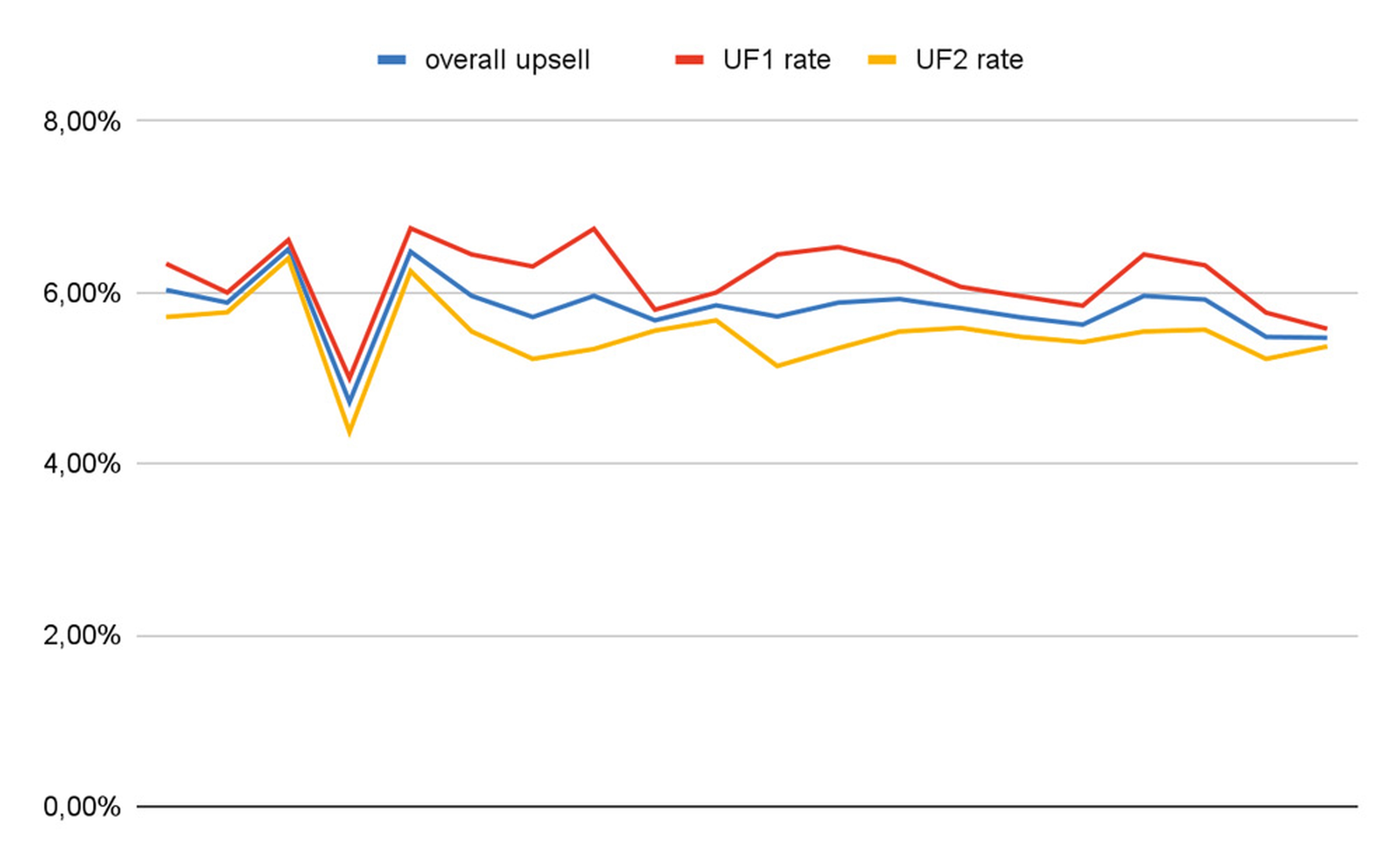
Abb. 2: Kurve zu Abb. 1 [ABT]
Aber Vorsicht, eine kurze Berechnung der Signifikanz ergibt, dass bei den gegebenen Daten das Konfidenzniveau 95 Prozent (siehe Tabelle 1) nicht erreicht wird [ABCalc, ABT].
| Chi-Quadrat p-Wert | 5,47 % | |
| alpha | 5 % | |
| Konfidenzniveau | 94,53 % |
Was bedeutet das? Der Schein trügt also, die angegebenen Daten reichen nicht aus, um mit dem Konfidenzniveau von 95 Prozent zu behaupten, dass eine der Lösungen besser als die andere ist. Ein signifikanter Unterschied besteht hier aktuell nicht. Die Versuchung ist jedoch groß, aus einer zufälligen Anhäufung von Ereignissen einen Trend abzulesen. Außerdem gibt es einen Bias dahin, nach langer Arbeit ein positives Ergebnis sehen zu wollen. Beides ist gefährlich und kann zum Irrtum führen. Als Betreiber von naschwerk.de entscheiden wir, die Tests einfach etwas weiter laufen zu lassen, immerhin gibt es aktuell auch keinen Hinweis darauf, dass eine der Varianten signifikant schlechter ist als die andere.
Generelles zur Methodik – Voraussetzungen für Erfolg
Damit A/B-Tests erfolgreich sind, müssen sie einige Voraussetzungen erfüllen. Dazu gehören die folgenden:
- unabhängige Testkandidaten: Die zu vergleichenden Produkte müssen unabhängig voneinander sein. Nur so kann ein statistischer A/B-Test überhaupt ein sinnvolles Ergebnis erbringen. Die beiden Upsell-Seiten aus dem naschwerk-Beispiel können unabhängig voneinander Benutzergruppen angezeigt werden. Ein Beispiel für abhängige Testkandidaten wären etwa zwei Produkte, die dem Nutzer nebeneinander zur Auswahl angezeigt werden, nicht zufällig. In diesem Fall kann beispielsweise die Position des ersten Produkts prominenter als die des zweiten sein.
- Zufällige Auswahl der Test-Proban- den: Wem die Optionen A oder B angezeigt werden, zu welcher Tageszeit und in welchem Kontext, muss zufällig erfolgen. Nur so kann ausgeschlossen werden, dass es zu einem ungewollten Bias kommt.
- Statistische Signifikanz: Für den A/B-Test muss eine ausreichende Menge an Daten gesammelt werden. Je signifikanter der Test sein soll und je kleiner der Unterschied der beiden Produktvarianten A/B ist, desto länger müssen Daten gesammelt werden. Achtung, über die Menge der zu sammelnden Daten sollte man sich vorab Gedanken machen. Denn wenn man nicht gerade den Traffic von Google oder Netflix hat, dann kann es sehr lange dauern, bis es ein signifikantes Ergebnis gibt. Zur Berechnung gibt es helfende Webseiten, wie den AB Testing Sample Size-Rechner (conversiongod.de) [ConG].
- Kurze Zyklen: Durch kurze Zyklen kann die Produktentwicklung schneller lernen. Dauern die A/B-Tests zu lange, so blockieren sie in der Regel die Weiterentwicklung des Produkts.
- Gute Vergleichsprodukte: Da A/B-Tests nicht selten mit höheren Aufwänden verbunden sind, können sie in der Regel nur an wenigen Seiten eines Produkts ausprobiert werden. Es lohnt sich auf jeden Fall, die gleiche Menge Aufwand auch in die Entwicklung der eigentlichen Produktvariante zu stecken. Oder andersherum ausgedrückt, es wäre Verschwendung, sich schlampig ausgearbeitete Produktideen vom Kunden als „schlechte Variante” bestätigen zu lassen.
- Klares Erwartungsmanagement zum Test: Gute A/B-Tests haben vorab formulierte Hypothesen. Insbesondere dazu, was die erwartete Verbesserung in Prozent gegenüber dem gegenwärtigen Prozess ist. Daraus kann ermittelt werden, wie viele Samples gebraucht werden und womit und wie lange der Test dauern wird.
- Gesamtprozess beachten: Nicht immer ist die Optimierung einer lokalen Größe gut für das Unternehmensergebnis. So kann beispielsweise eine Optimierung der Suche allein dazu führen, dass zwar viel gefunden wird. Sind die Such-Ergebnisse allerdings qualitativ schlecht, so kann das negativ für das gesamte Ergebnis sein. Beispiel: Eine E-Commerce-Suche findet viele Ergebnisse, die dann allerdings aktuell nicht verfügbar sind. Das frustriert Nutzer und der gesamte Shop leidet.
- Fehlende Nachbetrachtung von Tests und Ergebnissen: Unternehmen haben A/B-Testing oft als Standardinstrument eingeführt. Allerdings fehlt häufig eine kritische und systematische Nachbetrachtung. Im Ergebnis finden wir immer wieder die in Kasten 1 zusammengefassten Antipatterns – auch und gerade in Organisationen, die sich schon lange mit A/B- und multivarianten Tests beschäftigen.
Beispiel eines erfolgreichen A/B-Tests
Koautor Andreas Stephan berichtet hier von Klingel.de.
Ausgangssituation
Die Kernfrage bei Klingel.de war: „Was ist die optimale Sortierung einer Produktliste aus Kunden- und aus Business Sicht?” Die Produktliste ist das Ergebnis einer Suche nach Produkten.
Das Produktentwicklungsteam von Klingel verantwortet unter anderem die Produktlisten einer Multimandanten-E-Commerce-Plattform. Diese Produktlisten (siehe Abbildung 3) zeigen das Sortiment des Shops, zum Beispiel in der Kategorie „Abendkleider”.

Abb. 3: Klingel.de, mobile Ansicht
Das Ranking, also die Reihenfolge der Produkte, ist hier einer der zentralen Hebel für den Business-Erfolg. Was oben in der Liste steht, wird von den KundInnen häufiger angeklickt. Unsere bisherige Sortierung basierte auf einer Kombination von Kunden- und Business-Faktoren wie Produktverkäufen, Lieferbarkeit, Anzahl Produktdetailseitenaufrufe (folgend bez. als PDP-Aufrufe) sowie der Marge des Produkts. Wir hatten allerdings einige Indikatoren dafür, dass diese Sortierung insgesamt zu teils unattraktiven Listen, somit zu unnötig häufigen Absprüngen und schlussendlich zu weniger Verläufen als möglich führte, unter anderem weil ein Teil der Verkäufe aus Printprodukten induziert wurde und die Print- und Online-Zielgruppe unterschiedliche Vorlieben haben.
Wir stellten uns daher die Frage, was aus reiner (Online-)Kundensicht eine möglichst interessante Liste ausmacht.
Hypothese
Wir stellten die These auf, dass die beste Indikation dafür zunächst die Klicks auf die Produkte (Click Through Rate = CTR) und nicht primär die Verkäufe sein könnten, die im Anschluss damit erzielt werden, ähnlich wie in einem Geschäft die Produkte im Schaufenster zunächst einmal das Interesse der Kunden wecken sollen, um sie in den Laden zu ziehen. Zudem waren wir uns recht sicher, dass es auch weiterhin sinnvoll wäre, die Lieferbarkeit der Produkte zu berücksichtigen, da sich dies nicht direkt auf der Liste erkennen lässt und wir schon wissen, dass Kunden abspringen, wenn sie feststellen, dass das Produkt, das sie angeklickt haben, in ihrer Größe nicht erhältlich ist.
Die anstehende Optimierung der Produktliste sollte somit erreichen, dass auf den ersten Plätzen mehr Produkte stehen, die aus Kundensicht interessant und auch kaufbar sind. Am Ende erwarteten wir gegenüber dem alten Modell mehr Produktdetail-Seitenaufrufe und schlussendlich auch mehr Verkäufe, ohne dass dabei die Marge zu stark sänke oder die Retourenquote so anstiege, dass am Ende das Ergebnis aus Händlersicht negativ wäre.
Das neue Modell
Das neue Modell setzte somit auf eine Kombination von möglichst vielen Klicks auf gesehene Produkte und die Lieferbarkeit der Größen. Händlerspezifische Interessen (Marge) entfernten wir. Mittels einer Offline-Simulation erhielten wir vorab ausreichend Sicherheit, dass es sich lohnen könnte, dieses Modell in einem A/B-Test zu verproben.
Der A/B-Test
Wir zeigten den KundInnen nun zufällig verteilt zu je 50 Prozent die alte und die neue Sortierung an. Der A/B-Test benötigte 6 Tage, um ein signifikantes Ergebnis zu erzielen. Das Signifikanzniveau war 95 Prozent. Im Ergebnis zeigte sich folgendes Bild:
- + 3 Prozent mehr PDP-Aufrufe über alle Kundensegmente
- + 3 Prozent mehr Bestellungen
- + - 0 Konstante absolute Marge trotz relativ erhöhtem Sale-Anteil
- - 1,2 Prozent Retouren
- Die Gesehen/Gekauft-Quote sank, aber die deutlich erhöhten Views überkompensieren diesen Effekt, Interne CR ist gesunken
- + Signifikanter Anstieg der Views von Sale-Produkten, aber nicht bei den Verkäufen
- + 2,5 Prozent höherer durchschnittlicher Warenkorbwert (unerwartet). Vermutung: Die Produkte auf den vorderen Plätzen sind etwas teurer als vorher, KundInnen sind nun insgesamt zufriedener mit der Liste und legen diese Produkte etwas häufiger in den Warenkorb
Learnings
Das Resultat übertraf die Erwartungen, die wir durch die vorherige Simulation prognostiziert hatten, deutlich. Der Umsatz und das Ergebnis wurden deutlich gesteigert. Vor allem aber zeigte der A/B-Test, dass unsere Hypothese richtig war, dass der Business-Erfolg auch dann eintritt, wenn wir die Listen ausschließlich aus Kundengesichtspunkten optimieren, und dass es innerhalb unserer Organisation wichtig ist, nicht nur die Rille, in diesem Fall die CTR als Kern-KPI des Produktlisten-Teams, zu optimieren, sondern immer auch den gesamten Einkaufsprozess im Blick zu haben.
Stop when you stop learning!
Weitere Iterationen auf dem Modell brachten bei mehr Invest weniger Ergebnis. Hier hätten wir weitere A/B-Tests und damit verbundene Kosten und Aufwände vermeiden können. Und aus diesen folgenden Tests haben wir deutlich weniger gelernt.
Beispiele schlechter A/B-Tests
Unsinnig ist es beispielsweise, wenn Tests oft abgebrochen werden müssen, weil in einem sinnvollen Beobachtungszeitraum nicht genügend Daten für ein signifikantes Ergebnis gesammelt werden konnten. Auch bei signifikanten Ergebnissen muss die Frage erlaubt sein, ob das Ergebnis nicht vorab schon klar hätte sein müssen. Das nennen wir das „Brett-vorm-Kopf”-Pattern.
Beispiel schlechte Vorbereitung
Wenn es eine Hypothese gibt, dass das neue zu vergleichende Produkt x Prozent besser als das alte sein soll, dann lässt sich anhand des zu erwartenden Traffics ausrechnen, wie viele Daten genommen werden müssen, bis diese These signifikant bestätigt werden kann. Im Beispiel naschwerk.de hätten wir die Frage stellen können, wie viel Upsells wir brauchen, um einen Unterschied von 10 Prozent signifikant sehen zu können. Die Antwort lautet, dass bei ca. 600 Seitenaufrufen pro Tag, 10 Prozent Konversionsrate und einer erwarteten Verbesserung von 10 Prozent der A/B-Test mehr als 20 Tage laufen müsste, um ein signifikantes Ergebnis zu erzielen [ConvDauer]. Damit kann zumindest prognostiziert werden, wie lange bei gegebenen Verhältnissen die Zyklen sind, bevor entweder etwas gelernt oder verbessert werden kann. Um die Unabhängigkeit von Testszenarien zu gewährleisten, kann in diesem Bereich in der gleichen Zeit kein weiterer Test erfolgen.
Die Autoren haben es unabhängig voneinander mehrfach erlebt, dass Tests nach langer Zeit ohne signifikantes Ergebnis abgebrochen wurden. Das kann in Organisationen ein Zeichen schlechter Vorbereitung und Entscheidung zu A/B-Tests sein.
Beispiel Rillenoptimierung – Much ado about nothing
Ein E-Commerce-Unternehmen, vormals Katalogversender, prüfte vor einigen Jahren nach recht hitzigen Diskussionen im Marketing, ob die Gestaltung einer Produktdetailseite als zwei- oder dreispaltige Seite besser konvertierte. Das beauftragte Team musste dafür recht aufwendig eine komplett neue Produktdetailseite bauen und den A/B-Test vorbereiten. Die dafür vorgesehene Projektdauer von drei Monaten musste dann zur Sammlung von ausreichender Statistik noch einmal verlängert werden. Im Endergebnis kam heraus, dass 6 Monate nach der These bewiesen war, es macht keinen Unterschied, die Nutzer kaufen auf beiden Seiten gleich ein. Um mit Shakespeare zu sprechen: „Much ado about nothing”.
Beispiel Brett-vorm-Kopf
Hierzu folgendes Beispiel aus dem realen Leben vor ca. 10 Jahren. Ein soziales Netzwerk untersucht, ob es die Premium-Abo-Angebote auf der Upsell-Seite wie bislang in der Reihenfolge 3, 12 oder 24 Monate anbieten solle, oder besser in einer anderen Reihenfolge. Für die Firma war der Verkauf von 12- beziehungsweise 24-Monats-Abos viel besser als die kurze 3-Monats-Mitgliedschaft. In einem aufwendigen multivariaten Test kam heraus, dass die Reihenfolge 12, 24, 3 Monate besser ist als die bisher verwendete Monatsfolge 3, 12, 24.
Hier kann man schon fragen, ob nicht jeder Tankstellen-Verkäufer hätte wissen können, dass es immer sinnvoll ist, das zu verkaufende Produkt ganz nach vorne zu stellen. Know-how über Nutzer und Kaufverhalten kann nie schaden und manchmal braucht man für schlaue Lösungen keinen A/B-Test.
Voraussetzungen für gute A/B-Tests
Um A/B-Tests sinnvoll und effektiv in Organisationen einzusetzen und um zu vermeiden, dass blinde A/B-Test-Gläubigkeit zur Verlangsamung und Entscheidungsunfreudigkeit in der Produktentwicklung führt, sollten die folgenden Dinge beachtet werden:
- A/B-Tests sollten weniger als vier Wochen dauern. Aus Sicht der Autoren sollten aufwendige und langwierige A/B-Tests vermieden werden. Wird innerhalb von vier Wochen kein Ergebnis erwartet oder erzielt, deutet das auf einen Fehler in Setup oder der Hypothese hin.
- Mehrfache A/B-Tests ohne signifikantes Ergebnis sollten deren Abschaffung zur Folge haben. Führt eine Organisation A/B-Tests durch, die häufig ohne signifikantes Ergebnis enden, so ist zu fragen, warum für kein Ergebnis so viel Aufwand erzeugt wird. Das kann ein Zeichen für Ängstlichkeit in der Produktentwicklung sein, etwa wenn Neues nicht ohne Tests eingeführt wird, oder für Rillenoptimierung.
- Ohne große Statistik keine A/B-Tests. In Umfeldern, wo keine ausreichend hohen Statistiken zu erwarten sind. Und immer, wenn schnelle Änderungen nötig sind. Daher sind A/B-Tests im B2B-Umfeld auch meist sinnlos.
- Mit guten Testkandidaten starten. A/B-Tests sind aufwendig, daher sollte nicht mindestens so viel Aufwand in herausragendes Design der zu testenden Vergleichsobjekte investiert werden.
Alternativen zu A/B-Tests
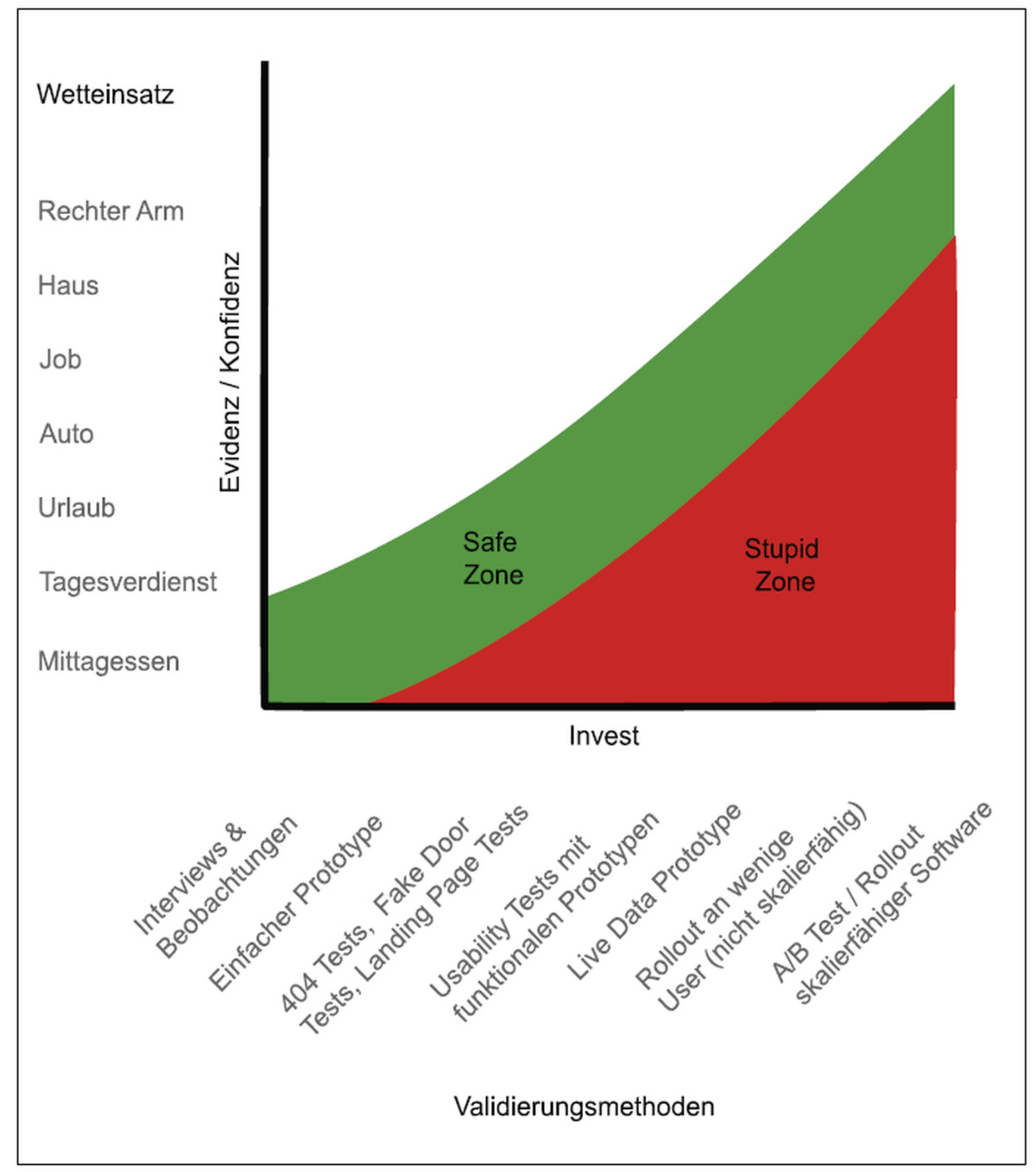
Abb. 4: Truth Curve, © Jeff Patton, free to use under CC
A/B-Tests sind eine sehr teure Methode, eine Hypothese zu validieren, weil hierfür zwei fertige Varianten in produktivem Code erstellt werden müssen. Insbesondere für Tests unterschiedlicher Business-Logiken ist der dafür entstehende Aufwand oft immens. Die Zeit, die für diese Entwicklung draufgeht, fehlt dann an anderer Stelle. Bevor man eine Hypothese über einen A/B-Test validieren möchte, sollte man also schon recht sicher sein, dass diese neue Variante auch wirklich besser ist als die alte.
“If you want to have good ideas you must have many ideas. Most of them will be wrong, and what you have to learn is which ones to throw away“ – Linus Pauling
Es muss also darum gehen, die meisten seiner Ideen so früh wie möglich zu invalidieren, sodass am Ende nur die übrig bleiben, die mit hoher Wahrscheinlichkeit mit einem guten Kosten/Nutzen-Verhältnis umgesetzt werden können. Dafür stehen verschiedene Methoden (Benutzerbefragung, Hotline-Befragung, Oma-Test …) zur Verfügung, die deutlich günstiger als A/B-Tests sind. Jeff Patton hat hier mit seiner Interpretation der Truth Curve eine gute Guideline entwickelt, die einen davon abhält, eine Idee zu früh in skalierbare Software zu gießen (siehe Abbildung 4). Die Frage, die man sich stellen kann, ist: „Wie viel wäre ich bereit, auf meine Hypothese zu wetten” und wie viel Evidenz habe ich dafür bereits? Je nach Evidenzniveau sollten Methoden mit einem passenden niedrigen Investment genutzt werden. A/B-Tests stehen hier ganz rechts – auf der teuren Seite. Die Truth Curve bezieht sich auf die Entwicklung kompletter Produkte, aber lässt sich in kleinerem Maßstab auch gut auf Features übertragen. Wer nur auf Basis einer ersten Idee sofort in einen A/B-Test startet, befindet sich definitiv in der roten „Stupid Zone”. Die Autoren würden persönlich erst dann einen A/B-Test starten, wenn sie ihren Freelancer-Tagessatz auf die neue Variante eines Features verwetten würden.
Fazit und Ausblick
Es bleibt die Frage, ob große, innovative Sprünge mit A/B-Tests überhaupt möglich sind oder ob mit A/B-Tests oft nur lokale Optima im Raum der Möglichkeiten gefunden werden. Erfolgreiche A/B-Tests sind schnell, aussagekräftig und starten mit klar formulierten Hypothesen. Leider werden A/B-Tests oft überbewertet und können ganze Organisationen in ihrer Produktentwicklung lähmen.
Weitere Informationen
[ABCalc]
https://abtestguide.com/calc/
[ABT]
https://docs.google.com/spreadsheets/d/1lKQyV67fEQN4E4TLf9rGsWyx17qZLKOxAcLay6O-oZQ/edit#gid=0
[Boj20] I. Bojinov, G. Saint-Jacques, M. Tingley, Avoid the Pitfalls of A/B Testing. Make sure your experiments recognize customers’ varying needs, siehe:
https://hbr.org/2020/03/avoid-the-pitfalls-of-a-b-testing
[ConvDauer] Testdauer-Rechner für A/B-Tests, siehe:
https://converlytics.com/tools/dauer-rechner-ab-test/
[ConG] Sample Size-Rechner für A/B-Tests, siehe:
https://conversiongod.de/sample-size-rechner
[ConSig] Signifikanz-Rechner, siehe:
https://converlytics.com/tools/signifikanz-rechner-ab-test/
[Kel18] T. Kelsey, Why A/B testing is overrated, siehe:
https://www.prontomarketing.com/blog/why-ab-testing-is-overrated/
[Wiki]
https://en.wikipedia.org/wiki/Statistical_significance