

Wie bekommt man Machine Learning (ML)-Modelle aus einer Laufzeitumgebung wie Jupyter Notebooks in Produktion? Unsere Erfahrung: oft gar nicht. Data Scientists nutzen die quelloffene Webanwendung, um mühelos Code miteinander zu teilen. Sie eignet sich nach unseren Erfahrungen nur für experimentelles Vorgehen, aber nicht für hochkomplexe Softwaresysteme.
Viele ML-Projekte scheitern
Schon 2018 stellten die Analysten von Gartner fest: 85 Prozent aller KI-Projekte scheitern und 47 Prozent von ihnen schaffen nicht den Schritt vom Proof of Concept (PoC) zum Minimum Viable Product (MVP). Kürzlich räumte ein Manager eines Automobilkonzerns ein, dass nur fünf von 600 KI-Projekten in den vergangenen zehn Jahren auch produktiv gingen. Gleichzeitig ordnet der C-Level, also die CEO, CIO, CTO, COO, CDO ..., Künstliche Intelligenz als Mainstream-Technologie ein, so eine Studie des Beratungsunternehmens pwc. Die Sub-Domänen von Machine Learning, etwa generative KI, autonomes Fahren oder Zeitserien-Vorhersagen, sind mit unterschiedlichen Herausforderungen verbunden. In sämtlichen Domänen und Branchen sind die Erfolgsquoten von ML-Vorhaben bislang gering. Deshalb lassen sich diese Zahlen in zwei allgemeingültige Hürden zusammenfassen, die einem erfolgreichen ML-Projekt im Weg stehen stehen (siehe Abbildung 1):
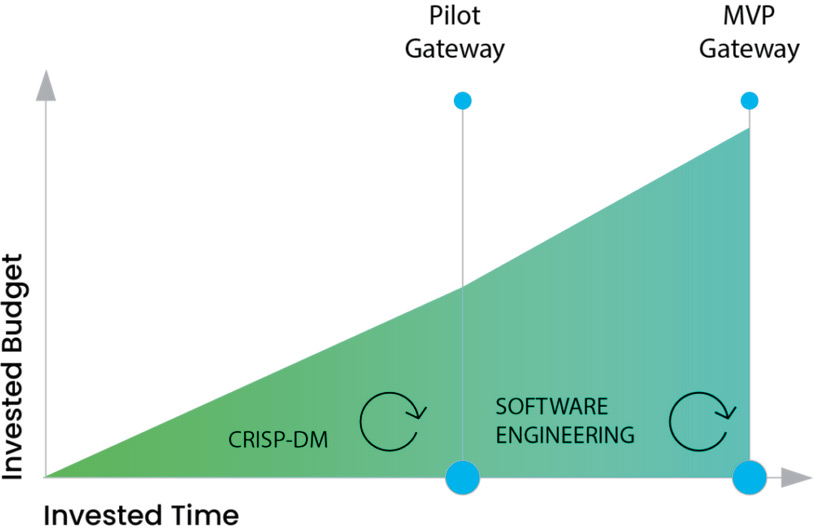
Abb. 1: Budget/Zeit
- Die PoC-Hürde: Beim Machine Learning ist es wichtig, eng mit dem Fach bereich zusammenzuarbeiten. Oft ist anfangs unklar: Wo will man hin? Zudem können sich Anforderungen mehrmals ändern – oft durch Erkenntnisse, die während der Modellierung gewonnen werden. In dieser von Unsicherheit und hoher Dynamik geprägten Umgebung gilt es, im engen Austausch und iterativ vorzugehen, um ein ML-Projekt erfolgreich abzuschließen. Andernfalls wird eine Lösung gebaut, die nicht zum Problem des Fachbereichs passt.
- Die MVP-Hürde: Die Ergebnisse der Experimente (= Modelle) müssen in produktive Softwaresysteme eingebunden werden. Damit kann man sie dann dem Fachbereich verfügbar machen. Die besten ML-Modelle nutzen nichts, wenn sie nicht leicht zu verwenden sind. Darum ist es wichtig, den produktiven Anteil von ML-Projekten so früh wie möglich mitzudenken und Machine Learning analog zur Softwareentwicklung als Engineering-Disziplin zu begreifen.
Mit CRISP-ML(Q) ML-Projekte meistern
Um diese Hürden zu überwinden, bietet sich CRISP-ML(Q) an: Cross-Industry Standard Process for the development of Machine Learning applications with Quality assurance methodology. Diese Weiterentwicklung des aus den 90er Jahren stammenden CRISP-DM (Cross-industry standard process for data mining) standardisiert das Vorgehen und dient als Blaupause für die Strukturierung von ML-Projekten. Der Prozess besteht aus den drei Phasen Business & Data Understanding, Model Development und Model Operations (siehe Abbildung 2).
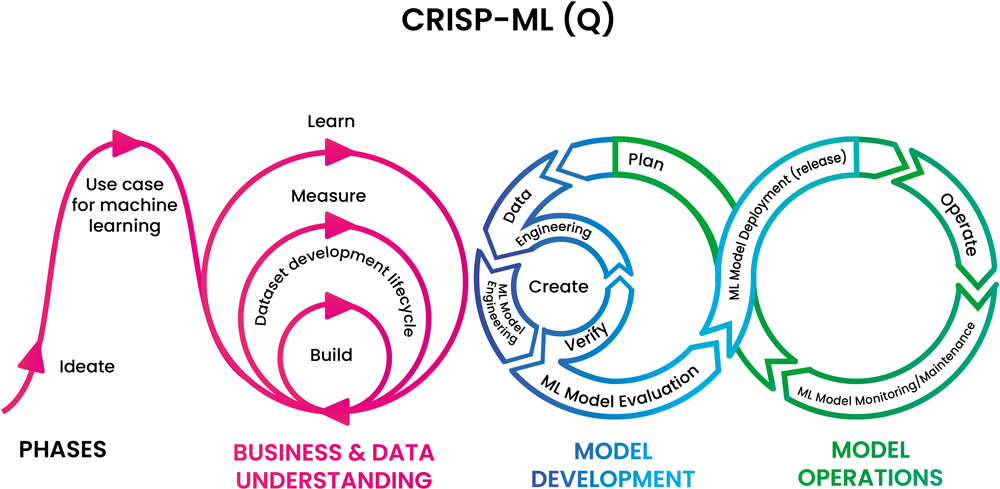
Abb. 2: Lebenszyklusprozess für maschinelles Lernen, Figure 1 aus: https://ml-ops.org/content/crisp-ml
Business & Data Unterstanding
In der ersten Phase ist es essenziell, dass Data Scientists im Sinne eines Requirement Engineering agieren und mit den Fachbereichen die fachlichen Anforderungen an die ML-Lösung erarbeiten. So lassen sich früh die Erwartungen an den Nutzen des Projekts erheben. Es geht darum, potenzielle Anwendungsfälle für Machine Learning zu identifizieren, das Business-Problem zu verstehen und zu überprüfen, wie die bestehenden Daten dieses Problem widerspiegeln. Mit Prototypen und PoCs lassen sich mögliche Lösungen testen und validieren. Diese Pilotphase sollte nicht zu lange laufen oder im Konzeptionellen verharren. Die Machbarkeit eines Datenprodukts muss engmaschig und in der minimal möglichen Zeit bewertet werden. Die gemeinsam erarbeiteten Erwartungen sowie die Ergebnisse der PoCs bilden eine wichtige Entscheidungsgrundlage, ob es Sinn ergibt, auch ein MVP zu entwickeln.
Model Development
Entscheidet man sich für den MVP, geht man in die nächsten Phasen über. „Model Development“ umfasst alle Schritte, um ein ML-Modell zu bauen:
- Data Engineering: Die verfügbaren Daten liegen oft in unterschiedlichen Datenquellen. Diese müssen zusammengeführt und dem gewählten ML-Algorithmus entsprechend aufbereitet werden.
- ML Model Engineering: Der in der PoC-Phase erfolgreich verprobte ML-Algorithmus muss optimiert und an die Datengrundlage angepasst werden. Dies beinhaltet auch, das trainierte Modell zu validieren.
- Model Evaluation: Mit Metriken und Test-Läufen wird die Güte des Modells evaluiert. Wird das Modell – abhängig vom Use Case – als „gut genug“ eingestuft, ist es bereit für den Release.
- Model Release: Das trainierte Modell wird für die Nutzung freigegeben. Oft bedeutet das, das Modell als Endpunkt in ein produktives System einzubinden.
Model Operations
Hier muss der erfolgreiche Betrieb des veröffentlichten Modells sichergestellt werden:
- Operate: Das Modell muss erreichbar sein, um dessen Vorhersagen in einem bestehenden Produktivsystem nutzen zu können.
- Model Monitoring/Maintenance: Das Verhalten des Modells in Produktion muss überwacht werden.
- Plan: Aus den Erkenntnissen des Modell-Betriebs werden nächste Entwicklungsstufen des Modells abgeleitet.
„Model Development“ und „Model Operations“ sind ineinander verschränkt, kontinuierlich und zyklisch: Der Release eines Modells ist – anders als in der Eingangsfrage suggeriert – kein One-Hit-Wonder.
Vertrauen in KI durch Monitoring
Die Performance muss im Betrieb überwacht werden, um zu überprüfen, ob das Modell noch up to date ist. Das Nutzerverhalten kann sich über die Zeit ändern, wodurch die Daten, die verwendet werden, um Vorhersagen mit dem Modell zu machen, stark von den Trainings-Daten abweichen. In dem Fall muss das Modell neu trainiert und an die neue Datengrundlage angepasst werden. „Vertrauen in KI kann man nur durch Monitoring und Automatisierung gewinnen“, resümierte mein Projektkollege und Lead Data Scientist Valentin Koch bei seinem Vortrag auf der DIGICON in München. „Begreifen Unternehmen KI als Engineering-Disziplin, brauchen sie crossfunktionale Teams, einen modernen und skalierbaren Tech Stack, agile Prozesse und Automatisierung.“
ML ist eine Engineering-Disziplin
Damit aus einem erfolgreichen ML-Experiment ein Produktivsystem wird, darf es nicht nur standalone funktionieren. Die Ein- und Anbindung des ML-Projekts in die Applikationslandschaft ist die große Kür. Das ML-System muss an die produktiven Datenquellen angebunden, das trainierte Modell als Endpunkt oder eigener Microservice verfügbar gemacht oder in Datenverarbeitungsstrecken integriert werden. Die Art der Einbindung hängt vom Use Case ab. Wichtig ist, dass die User Machine Learning einfach nutzen können – wie andere Applikationen auch. Es gilt, ML-Vorhaben als datengetriebene Softwareprojekte zu begreifen und anzugehen. Jedem ML-Projekt liegt der Dev-Ops-Ansatz zugrunde – wer Abbildung 2 genauer studiert, erkennt auf der rechten Seite die liegende Acht, die sich auch in diversen DevOps-Grafiken findet. Zum einen muss der Betrieb durch engmaschiges Monitoring gesichert werden. Zum anderen muss der Entwicklungs-Workflow darauf ausgelegt sein, Änderungen schnell in Produktion zu bringen, um auf neue Anforderungen oder Erkenntnisse aus dem Betrieb reagieren zu können.
Der Entwicklungs-Workflow im automatisierten MLOps-Prozess
Unser MLOps-Ansatz verfolgt das Ziel, über klassischen Applikationscode in Python die ML-Prozesse zu steuern. Um einen hohen Automatisierungsgrad zu erreichen, ist es nötig, Best Practices aus dem Softwareengineering in den Entwicklungsprozess von ML-Applikationen einzubringen:
- Staging: Zwei getrennte Laufzeitumgebungen helfen, die Entwicklung vom produktiven Betrieb zu trennen. Die Entwicklungsumgebung wird verwendet, um neuen Code oder Anpassungen manuell zu testen. Sie lässt sich zusätzlich für Integrationstests nutzen. Es können nach Bedarf des Use Cases auch mehr als zwei Stages verwendet werden. So kann eine dedizierte Integrations-Umgebung in den Prozess integriert werden.
- Testing: Unit-Tests gewährleisten, dass einzelne Komponenten des ML-Systems funktional korrekt sind. Zusätzlich stellen Integrationstests sicher, dass das Zusammenspiel dieser Komponenten funktioniert. Auf diese Weise sind die Bugs so früh wie möglich identifiziert. Nur stabiler Code gelangt in die Produktion.
- Dokumentation: Um Wartbarkeit und Zusammenarbeit innerhalb eines Teams zu gewährleisten, ist es wichtig, den Code zu dokumentieren.
- CI/CD: Das Überprüfen der Code-Qualität, das Deployment von Code-Anpassungen in das Produktivsystem und auch der Release von neuen Modellen werden über CI/CD-Prozesse automatisiert. Hier gilt es, je nach Use Case die richtige Balance zwischen voller Automatisierung und der Kontrolle durch das Data-Science-Team zu finden.
Der Code wandert aus der Laufzeitumgebung Jupyter Notebooks in Python-Skripte. Es gibt zwei Arten von Code:
- Der Orchestrierungs-Code wird verwendet, um die Ressourcen zu erstellen und die Schritte des ML-Workflows zu orchestrieren. Durch das Einbinden in CI/CD-Pipelines werden diese automatisiert, damit Änderungen schnellstmöglich im Produktiv-System verfügbar sind und fehleranfällige manuelle Prozesse vermieden werden.
- Der Runtime-Code beschreibt die Schritte des ML-Workflows, etwa das Aufbereiten der Daten, das Modell-Training und die Evaluierung des trainierten Modells. Er wird verwendet, um neue Experimente zu starten oder automatisierte ML-Trainings umzusetzen.
ML in der industriellen Produktionsplanung
Wie man diese Konzepte in der Praxis umsetzen kann, erläutern wir anhand einer Zeitserien-Vorhersage (Timeseries Forecasting), die einer unserer Industriekunden in der Produktionsplanung verwirklicht. Am Anfang stand eine Vision: Das Industrieunternehmen wollte eine Plattform bauen, über die sich die künftige Nachfrage nach ihren Produkten vorhersagen und so die Produktion darauf ausrichten beziehungsweise optimieren lässt. Ziel war es, in einem ersten Werk für zunächst 100 unterschiedliche Produkte valide Vorhersagen treffen zu können. Funktioniert das, soll Schritt für Schritt die gesamte Produkt-Palette berücksichtigt und schließlich weitere Werke des Konzerns aufgegleist werden. Eine komplexe Herausforderung, zumal jedes Produkt für sich gesehen eine eigene Zeitserie darstellt. Zusätzlich zu starken Unterschieden am Bedarf der einzelnen Produkte können neue Produkte hinzukommen oder bestehende Produkte auslaufen. Da es in diesem Umfeld schwer ist, einen Algorithmus auf die Problemstellung zu optimieren, haben wir uns für Automated Machine Learning (AutoML) entschieden.
Profil MLOps Engineer
Aufgaben der MLOps Engineers sind es, geeignete ML-Plattformen und KI-Services auszuwählen, Data-Science- Workflows mit versionierten Modellen, Daten und Umgebungen zu automatisieren sowie die DevOps-Integration in der Unternehmens-IT reproduzierbar zu machen. Dementsprechend ist die Disziplin MLOps eine Schnittmenge aus bereits bestehenden Disziplinen (siehe Abbildung 3):
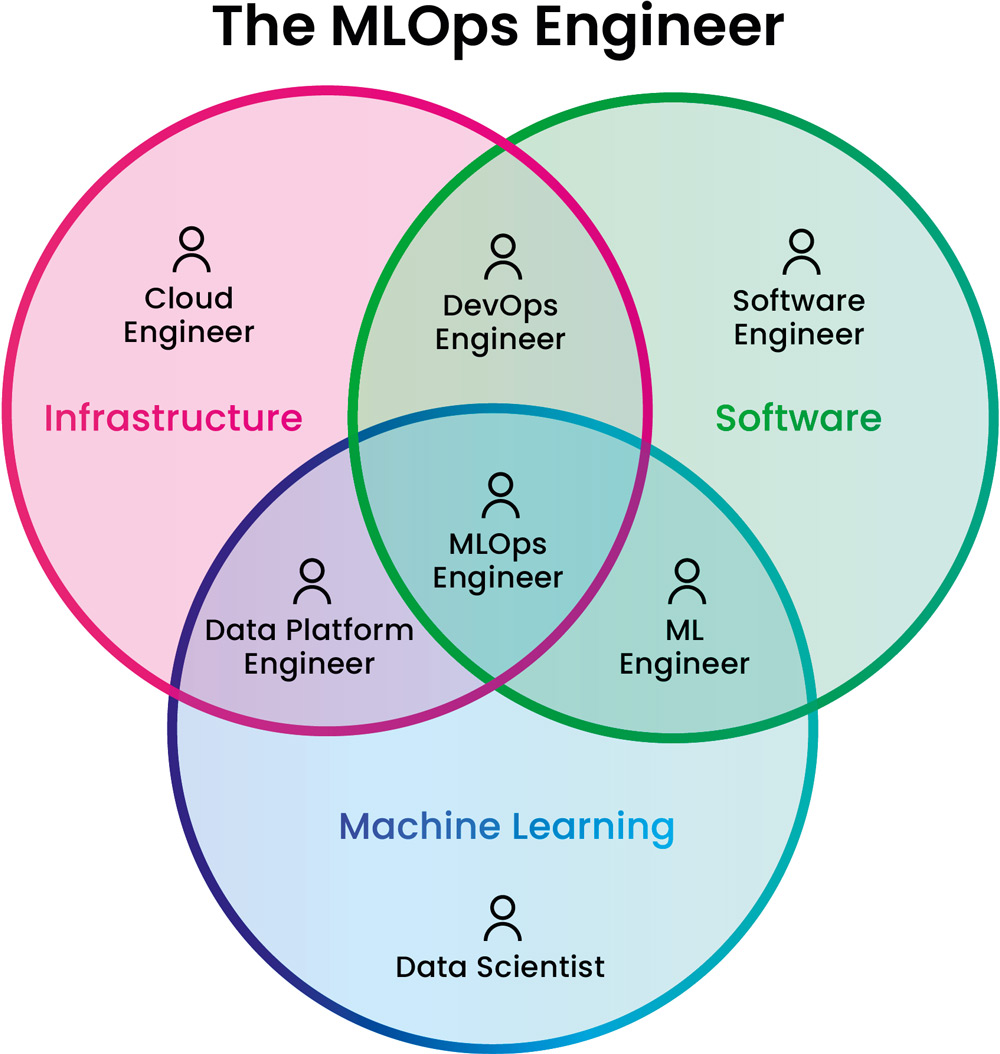
Abb. 3: MLOps Engineer, Quelle: Aurimas Griciunas https://www.linkedin.com/posts/aurimas-griciunas_mlops-machinelearning-dataengineeringactivity-7021068436831129600-JwIS?utm_source=share&utm_medium=member_desktop
- Infrastructure Management: Bereitstellen und Betreiben von Infrastruktur wie Compute-Ressourcen und Datenspeichern. Die benötigte Infrastruktur wird meist bei Cloud- Anbietern provisioniert.
- Softwareengineering: Schreiben und Pflegen von Applikations-Code. Beim Machine Learning hilft eine saubere Code-Struktur, die gebaute Lösung schnell zu erweitern und leicht zu warten.
- Machine Learning: Der korrekte Einsatz von ML-Algorithmen ermöglicht es, entscheidende Informationen aus großen Datenmengen zu extrahieren.
Durch Abhängigkeiten in die verschiedenen Felder entsteht im Bereich MLOps eine hohe Komplexität.
Um mit diesen Abhängigkeiten umzugehen, brauchen MLOps Engineers eine breit gefächerte Expertise. Gleichzeitig müssen sie auch tief greifendes Expertenwissen in mindestens einem der Felder aufweisen, um einen unabhängigen Mehrwert in cross-funktionalen Teams liefern zu können. MLOps Engineers brauchen ein T-Shaped Skillset. Eines von vielen möglichen Skillsets ist in Abbildung 4 dargestellt.
Wer MLOps Engineer werden will, sollte sich zuerst in einem Teilbereich spezialisieren, um Teil eines erfolgreichen MLOps-Teams zu werden. Im weiteren Verlauf der Karriere muss man in die Breite gehen, um das gewünschte Skillset zu vervollständigen.
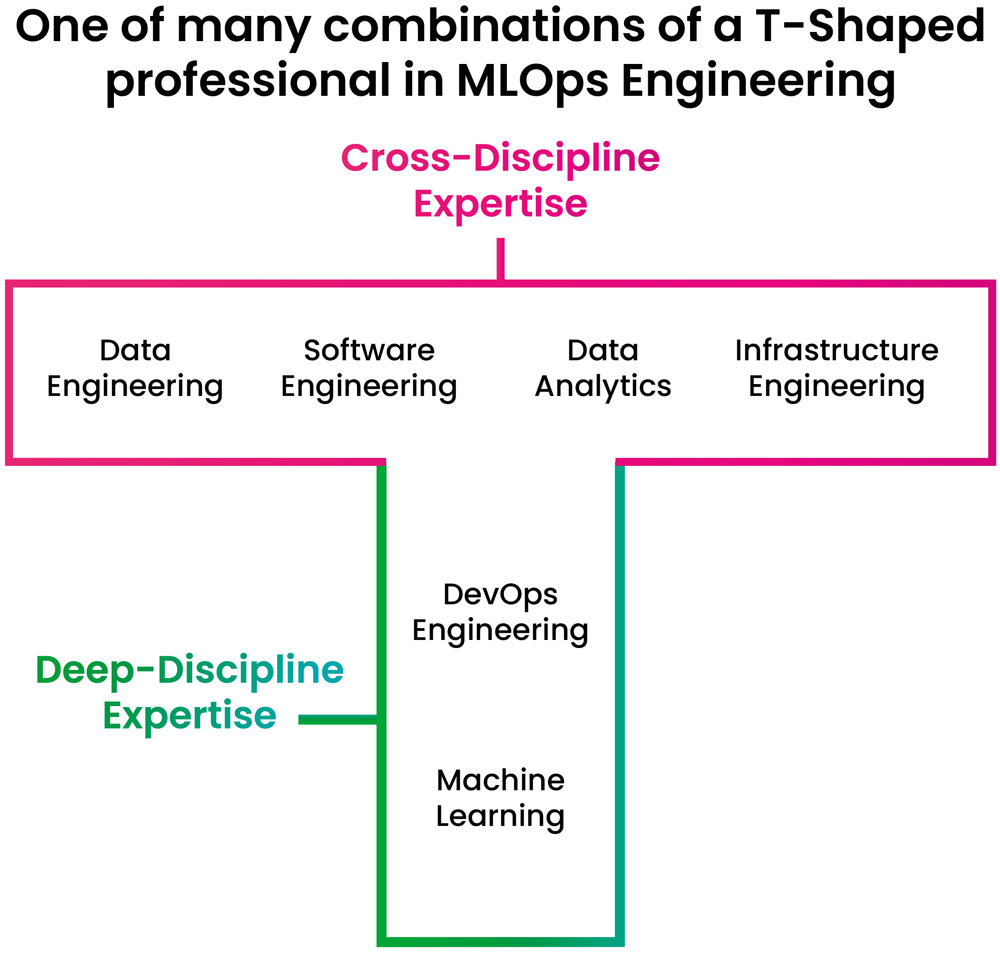
Abb. 4: T-shapes MLOps Engineering, Quelle: Aurimas Griciunas https://www.linkedin.com/posts/aurimas-griciunas_mlops-machinelearning-dataengineering-activity-7023221960767635456-LbFy?utm_source=share&utm_medium=member_desktop
AutoML als Kernbaustein für Erfolg im Kundenprojekt
Bei AutoML wird das Experimentieren mit ML-Algorithmen abstrahiert und dadurch beschleunigt. Meist enthalten bestehende AutoML-Lösungen eine Auswahl an ML-Algorithmen und Feature-Engineering-Verfahren, die automatisiert auf den Daten getestet werden. So findet AutoML für jeden Datensatz das passende Modell. Das hat in unserem Kundenprojekt den Vorteil, dass wir für jedes Produkt das passende Modell finden und auch neue Produkte direkt in die Plattform integrieren können.
AutoML ermöglicht Fokus auf produktives ML
Dank AutoML haben wir die PoC-Phase des Projekts auf einige Wochen verkürzt. Wir haben schnell erste und fachlich gute Ergebnisse geliefert. Dadurch haben wir großes Vertrauen auf der Kundenseite gewonnen und Begeisterung für das Projekt geweckt. Das ermöglichte es uns, die angesprochenen Automatisierungsthemen zu bearbeiten und dafür ausreichend Zeit zu bekommen.
Aktueller Stand der Plattform
In der Zwischenzeit wurde ein weiteres Werk, das über 2000 Produkte produziert, in die Plattform integriert. Parallel dazu wurden ML-Algorithmen, die die Fachbereiche entwickelten, als mögliche Lösung eingebunden. Dadurch werden diese Lösungen auch zwischen den Fachbereichen geteilt. Mit AutoML in Kombination mit den selbst entwickelten Algorithmen lassen sich pro Zeitserie 50 Modelle trainieren und das jeweils Beste daraus für die Vorhersage auswählen. Dadurch wird der bestmögliche Algorithmus pro Zeitserie identifiziert und die Vorhersage-Qualität verbessert. Durch einen hohen Parallelisierungsgrad und effektives Skalieren von Compute-Ressourcen werden wöchentlich 100.000 ML-Modelle in weniger als fünf Stunden und zu Cloud-Kosten von weniger als 500 Euro trainiert. Durch die Einbindung in die IT-Landschaft des Kunden lassen sich neue Modelle automatisiert trainieren, sobald es die Datengrundlage erfordert. Vorhersagen werden direkt in die Datenstrecken der Fachbereiche eingespeist. Die Integration weiterer Werke ist in Planung.
Zusammenfassung
Um mit einem ML-Vorhaben erfolgreich zu sein, benötigt es die richtige Struktur im Projekt: CRISP-ML(Q) bietet eine erfolgreiche und erprobte Blaupause, um die PoC- und MVP-Hürden zu meistern. Zusätzlich bedarf es eines Engineering Mindsets in cross-funktionalen Teams, der Beachtung der DevOps-Konzepte und eines hohen Grads an Automatisierung. AutoML kann helfen, ein Projekt zu kickstarten, die PoC-Phase zu verkürzen und den Fokus auf den produktiven Anteil von ML-Projekten zu setzen. All das sind Voraussetzungen für den MLOps-Zyklus. Und wie es der Name Zyklus schon impliziert: Machine Learning ist wie die Daten selbst immer im Fluss und nie zu Ende!









