

Machine Learning Operations, kurz MLOps, ist notwendig, um Machine-Learning-Modelle verlässlich zu entwickeln, bereitzustellen und zu monitoren. Damit sorgt MLOps beim Bearbeiten konkreter Anwendungsfälle nicht nur für Verlässlichkeit und Tempo – ein guter Prozess stellt auch sicher, dass Unternehmen ihre Daten letztendlich überhaupt gewinnbringend nutzen können [Scu15].
Der eigentliche MLOps-Prozess beginnt, wenn die Experimentier- bzw. Lab-Phase endet und eine konkrete Umsetzung eines ML-Modells erarbeitet wurde, um ein spezifisches Business-Problem zu lösen. Wie in Abbildung 1 dargestellt, beinhaltet der MLOps-Prozess folgende Komponenten:
- Entwicklung des ML-Systems
- Deployment und Test des ML-Systems
- Monitoring des ML-Systems
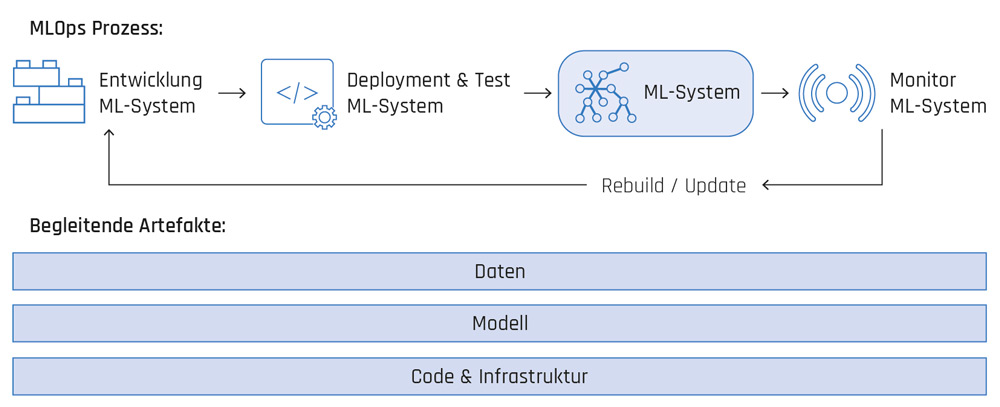
Abb. 1: MLOps-Prozess
Während des gesamten Prozesses spielen das Managen von Daten und Modellen eine wesentliche Rolle [Tre21]. Auch wenn Code und Infrastruktur eine ebenso große Bedeutung zukommt, sind diese keine neuen Komponenten und werden bereits im Zuge von DevOps ausgiebig behandelt.
Weil ein ganzheitlicher Ansatz zum Managen von Daten und Modellen notwendig ist und weil Training und Inferenz orchestriert werden müssen, sprechen wir hier nicht vom „Deployment eines Modells“, sondern vom Betrieb eines gesamten ML-Systems. Das ML-System vereint Daten, Modelle, Code und Infrastruktur in einem geschlossenen System. Bisher wurden häufig nur einzelne Komponenten des MLOps-Prozesses diskutiert. In diesem Beitrag liegt der Fokus auf einem integrierten Ansatz und wie dieser mit Hilfe von Azure implementiert werden kann.
Umsetzung auf Azure: eine Referenzarchitektur
Die Referenzarchitektur stellen wir am Beispiel der Nachfragevorhersage (englisch: Demand Forecasting) vor. In diesem Szenario werden jede Woche Batch-Vorhersagen generiert und für konsumierende Systeme bereitgestellt. Abbildung 2 bildet die vollständige Referenzarchitektur ab, deren Komponenten im Folgenden detaillierter beschrieben werden.
1. ML-System
Der Kern des ML-Systems besteht aus zwei Azure-Machine-Learning-(AML-)Pipelines: einer Trainings- Pipeline, mit der ein Modell trainiert und abgespeichert wird, und einer Inferenz-Pipeline, die ein bestehendes Modell verwendet, um Vorhersagen zu erstellen. AML-Pipelines werden verwendet, um alle Schritte beim Erstellen des Modells und der Vorhersage zu kapseln und abhängig voneinander auszuführen. Ein wesentlicher Vorteil von Pipelines ist, dass für jeden Schritt eine eigene Umgebung verwendet werden kann. Im Beispiel für die Nachfragevorhersage wird der Data Preparation Step in der Trainings-Pipeline auf einem Databricks-Cluster ausgeführt, um der aufwendigen Datenaufbereitung Rechnung zu tragen. Der Trainings-Step wird auf einem größeren AML-Compute-Cluster ausgeführt, um gewohnte Implementierungen von Algorithmen verwenden zu können und gleichzeitig über mehr Rechenkapazität für das Training zu verfügen [Gay22].
Beide Pipelines haben einen eigenen versionierten Datensatz als Input definiert. Der Trainingsdatensatz enthält historische Rohdaten, die durch die Pipeline aufbereitet und für das Training des Modells verwendet werden. Der Output der Trainings-Pipeline ist zum einen ein trainiertes Modell, das in einer AML Model Registry abgelegt wird. Zum anderen werden für jeden Pipeline-Run in der AML-Arbeitsumgebung der verwendete Code, die Metadaten sowie die benutzerdefinierten Logs – beispielsweise Evaluationsmetriken – gespeichert. So ist eine vollständige Überprüfung und Lineage des Trainingsvorgangs von den Rohdaten bis zum trainierten Modell möglich [McK20].
Der Inferenz-Datensatz enthält Rohdaten, die für die Vorhersage benötigt werden. In unserem Fallbeispiel sind das Input-Daten für die nächsten zwölf Wochen, zum Beispiel Wettervorhersagen oder Ferienzeiten. In der Inferenz-Pipeline werden diese Daten so aufbereitet, wie sie das trainierte Modell erwartet. Der letzte Schritt ist, das trainierte Modell aus der AML Model Registry zu laden und die Vorhersagen zu erstellen, die dann im Azure Data Lake abgelegt werden. Dort stehen die Vorhersagen für konsumierende Systeme bereit.
Das ML-System wird komplettiert, indem die AML-Pipelines über die Azure Data Factory orchestriert werden. Die ML-Pipelines werden in regelmäßigen Abständen getriggert, um neue Vorhersagen bereitzustellen und, wenn nötig, ein neues Modell zu trainieren. Dabei hängt das Retraining davon ab, ob ein Data oder Model Drift festgestellt wird [McK20]. Ist dem so, wird mit der Trainings-Pipeline ein neues Modell trainiert und in der Registry abgelegt.
Bevor das Modell für Vorhersagen verwendet werden kann, wird die Performance geprüft (Quality Gate). Nur bei Erreichen bestimmter Schwellenwerte wird das Modell in der Registry mit dem Tag „production“ versehen. Die Inferenz-Pipeline wiederum verwendet ausschließlich das Modell mit diesem Tag. Ist die Performance nicht ausreichend, wird dieser Tag nicht gesetzt und zusätzlich eine Benachrichtigung an ein ML-Engineering oder Betriebsteam versendet. Diese müssen dann gegebenenfalls die Modellarchitektur anpassen.
2. Versionierung von Modellen
Die Versionierung von Modellen des maschinellen Lernens verfolgt zwei Ziele: die Reproduzierbarkeit von Ergebnissen sicherzustellen und die Model Governance durch eine Dokumentation der Modellkonfiguration zu erhöhen. Versionierte Modelle werden im AML-Arbeitsbereich als eine Sammlung von Dateien abgespeichert. Zur Versionierung der Modelle wird ein Azure Storage Account verwendet, der beim Erstellen des Dienstes miterstellt wird. Jedes Modell wird dabei mit einem sprechenden Namen und einer Version im Arbeitsbereich registriert. Sollte ein Modell mit dem gleichen Namen nochmals registriert werden, wird die Version für das betreffende Modell inkrementiert.
Zur Erhöhung der Modell-Governance werden Metadaten in Form von Tags verwendet. Die Tags können verschiedenen Kategorien zugeordnet werden:
- AML-Pipeline-spezifische Metadaten
- Modellspezifische Metadaten
- Anwendungsfallspezifische Metadaten
AML-Pipeline-spezifische Metadaten enthalten Informationen zur einzigartigen Run ID, Dataset Version und zur Art der AML-Pipeline, die verwendet wurde, um das Modell zu erstellen [Sch17]. Als modellspezifische Metadaten werden Modellart, verwendete Hyperparameter und Evaluationsmetriken durch Tags dokumentiert. Des Weiteren können fachbezogene Metadaten an das Modell gehängt werden. Dieses Anreichern des gespeicherten Modells mit Metadaten erlaubt eine effiziente Systematisierung und Suche der gespeicherten Modelle.
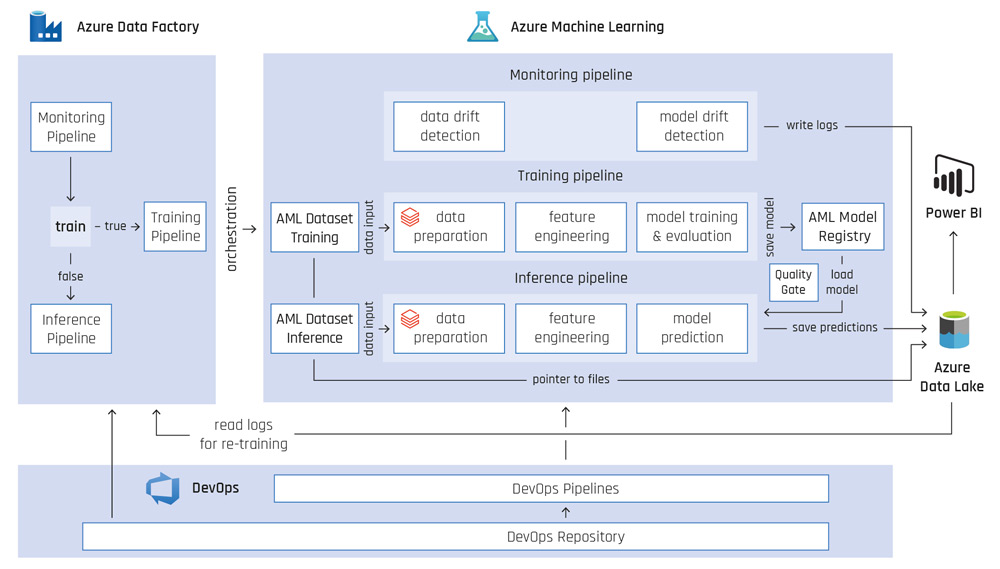
Abb. 2: Referenzarchitektur MLOps auf Azure
3. Managen von Daten
Mit dem Managen von Daten ist das Versionieren von Input-Daten gemeint, die für das Training des ML-Modells verwendet werden. Im Azure Data Lake liegen sowohl Trainings- als auch Inferenz-Datensätze, die in der Rohform von externen Systemen dort bereitgestellt werden. Um eine Historie aufzubauen, werden Zeitstempel verwendet, die Partitionen beziehungsweise Unterordner im Azure Data Lake darstellen und jeweils vollständige Datensätze für das Training und die Inferenz zu einem Zeitpunkt repräsentieren. Im AML-Arbeitsbereich zeigen die registrierten Datensätze auf einen eindeutigen Ordner im Data Lake. Dieser Ordner wird nachträglich nicht mehr modifiziert. Sollten Daten im Data Lake aktualisiert werden, wird ein neuer Datensatz registriert, der auf diese aktuelle Version verweist (siehe Abbildung 3).
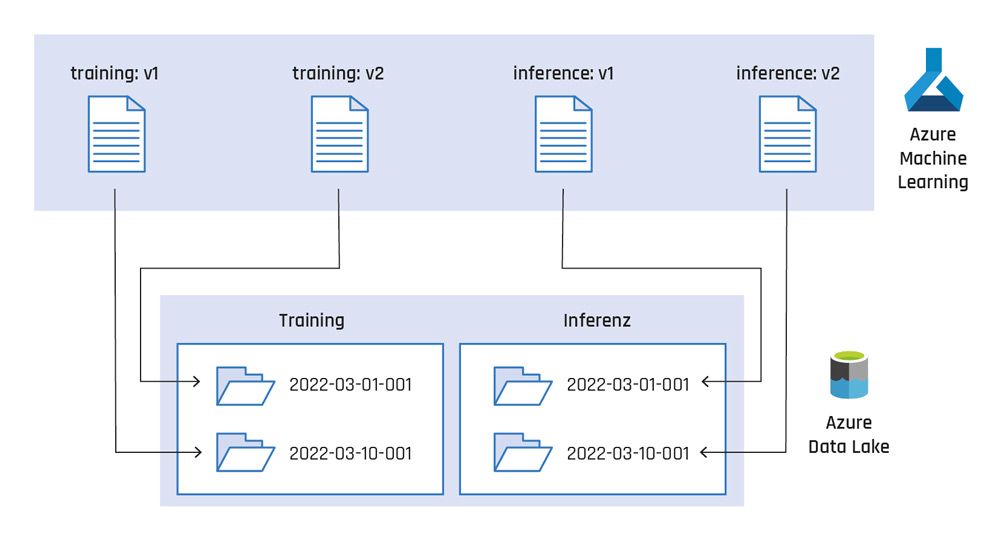
Abb. 3: Datenversionierung in Azure Machine Learning
4. Deployment und Testing des ML-Systems
Wie in einem klassischen Softwaresystem wird auch hier jede Änderung am ML-System automatisiert deployed und getestet, bevor sie ins Produktivsystem übernommen wird. Abbildung 4 stellt den implementierten Deployment-Prozess schematisch dar. Dafür werden die Azure-DevOps-Services Repos und Pipelines eingesetzt. In unserem Fallbeispiel werden drei Umgebungen verwendet, repräsentiert durch die drei Ressourcengruppen RG-Dev, RG-Test und RG-Prod. Diese enthalten jeweils die für das ML-System notwendigen Haupt-Services Azure Data Factory (ADF), Azure Machine Learning und Azure Data Lake.
In der Entwicklungsumgebung wird das ML-System mit seinen Komponenten entwickelt. Die Entwicklung der AML-Pipelines sowie die Erstellung der dazugehörigen Assets, wie Datasets, Compute-Ressourcen und Umgebungen, werden mit Hilfe eines Python-Frameworks entwickelt, das auf dem Azure-ML SDK beruht. Die Orchestrierungs-Pipelines dagegen werden direkt in der ADF entwickelt. Sowohl die AML-Pipelines als auch die ADF-Pipelines werden im Git Repository als Code versioniert. Ist ein bestimmter Entwicklungsstand erreicht, wird der Code vom Develop-Branch in den Test-Branch übertragen. Dieser Merge triggert eine CI/CD-Pipeline, die das ML-System automatisch in die Testumgebung deployed und anschließend Tests ausführt; ein manuelles Deployment wird durch entsprechende Berechtigungen ausgeschlossen. Die Tests decken das komplette ML-System ab und testen den Code in Form von klassischen Unit- und Integrationstests. Außerdem werden die Input-Daten (Training und Inferenz) auf Vollständigkeit, Datentypen sowie statistische Verteilung und Ausreißer geprüft. Das Modell wird getestet, indem es auf einem kleinen, bekannten Datensatz Vorhersagen generiert, die dann auf Plausibilität überprüft werden.
Sind die Tests erfolgreich, wird das ML-System einmal im Testsystem vollständig auf allen Produktivdaten ausgeführt, um Vorhersagen zu erstellen. Diese werden abschließend in Form von User-Acceptance-Tests von Data Scientists und vom Fachbereich auf Plausibilität geprüft. Liegt deren OK vor, wird der Test-Branch in den Master- Branch übertragen. Dieser Merge triggert wiederum automatisch das Deployment ins Produktivsystem.
Im Produktivsystem kann das ML-Modell automatisch auf neuen Daten trainiert werden. Ist hingegen eine strukturelle Anpassung der Modellarchitektur notwendig, muss dies in der Entwicklungsumgebung geschehen und der oben beschriebene Prozess wird erneut durchlaufen.
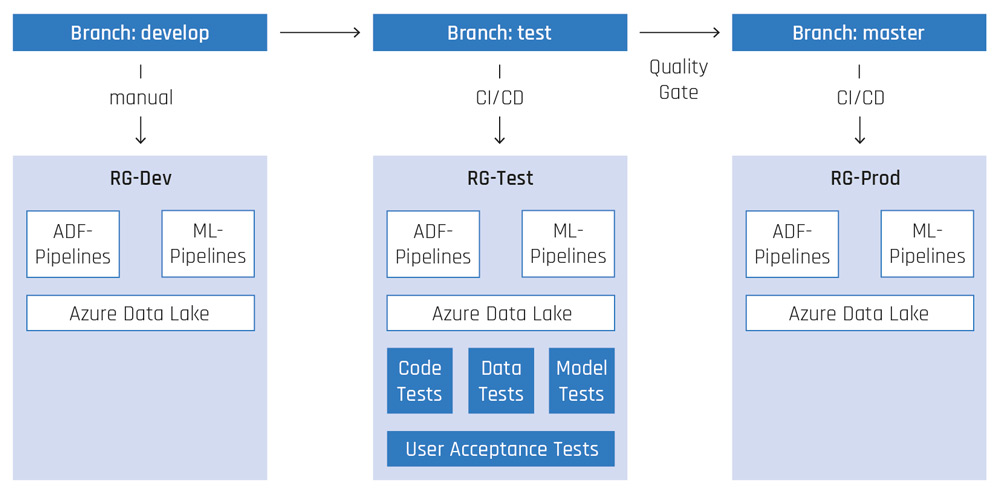
Abb. 4: Deployment-Prozess des ML-Systems
5. Monitoring des ML-Systems
Die probabilistischen Eigenschaften von ML-Modellen und die damit verbundene Unmöglichkeit, für jeden denkbaren Testfall einen Test zu konstruieren, bedeuten zusätzliche Herausforderungen für den Betrieb und für das Monitoring von ML-Modellen in der Produktionsumgebung. Neben klassischen Metriken wie Trainingszeit werden auch Model Drift und Data Drift kontinuierlich überwacht, weil sie dazu führen können, dass die Modellgüte mit der Zeit abnimmt. Data Drift beschreibt, wie sich die Verteilung der Trainingsdaten im Zeitverlauf ändert. Model Drift beschreibt die Veränderung der Modellgüte über die Zeit. Obwohl Data Drift und Model Drift häufig zusammen auftreten, kann auch nur eines der beiden eintreten und einen Indikator für ein Retraining darstellen.
Data Drift und Model Drift werden im Rahmen der Architektur überwacht, im Beispiel der Nachfragevorhersage in einer eigenen Monitoring-Pipeline (siehe Abbildung 2). In dieser Monitoring-Pipeline werden zum Testen auf Data Drift statistische Methoden implementiert. Diese vergleichen, ob den Trainingsdaten und den Inferenzdaten für die Vorhersage die gleiche statische Verteilung zugrunde liegt. Beim Model Drift werden die Metriken, die zur Modellevaluation verwendet werden, im Zeitverlauf überwacht und gespeichert. Die Monitoring-Pipeline speichert diese Metriken als Logs im Azure Data Lake, wo sie der Orchestrierungs-Pipeline sowie weiteren Monitoring-Systemen zur Verfügung stehen.
Darüber hinaus wird ein kontinuierliches Monitoring mit Power-BI umgesetzt. Hierbei werden zum einen die Modellgüte über die Zeit visualisiert und zum anderen die generierten Vorhersagen des Modells den wahren Werten gegenübergestellt. Basierend auf den im Monitoring Dashboard dargestellten Graphen werden Alarme und Benachrichtigungen zur Information an ein ML-Engineering oder ein Betriebsteam versendet. In diesem Fall kann zunächst ein Retraining angestoßen werden. Wenn dies nicht ausreicht, um das Modell zu verbessern, muss die Modellarchitektur angepasst und das ML-System mit der neuen Modellarchitektur neu deployed werden.
Fazit
Auf die hier beschriebene Weise kann der MLOps-Prozess mit allen relevanten Komponenten als integrativer Prozess umgesetzt werden. Azure bietet sich für einen solchen ganzheitlichen Ansatz an, weil in den relevanten Komponenten Services eingesetzt werden können, die dafür bestens geeignet sind. Insbesondere der Azure Machine Learning Service bietet umfangreiche Funktionalitäten zum modularen Entwickeln robuster ML-Systeme, zur Datenversionierung und zur Modellregistrierung, die eine hohe Governance sowie Lineage ermöglichen – ein Kernbestandteil guter MLOps-Lösungen.
Veranschaulicht haben wir diesen Prozess im Rahmen einer Referenzarchitektur auf der Cloud-Plattform Microsoft Azure mit Best Practices, die wir in Kundenprojekten entwickelt haben. Selbstverständlich ist die hier skizzierte Lösung für den Demand Forecast nicht in allen Details vollständig, vor allem ist es je nach Anwendungsfall erforderlich, die Architektur anzupassen. Für eine Lösung, die abgestimmt ist auf die spezifischen Anforderungen eines Unternehmens, sind jedoch neben einer umfassenden Kenntnis von Technologien und Methoden außerdem die Organisation sowie definierte Prozesse essenziell. Denn nur ein sauber aufeinander abgestimmtes Zusammenspiel aller Faktoren erlaubt es Unternehmen, den größtmöglichen Nutzen aus ihren Daten zu ziehen.
Weitere Informationen
[BBS19] Bergh, C./ Benghiat, G. / Strod, E.: The DataOps Cookbook. DataKitchen 2019
[Gay22] Gayhardt, L. et al.: What are Azure Machine Learning pipelines?, Oktober 2022,https://learn.microsoft.com/en-us/azure/machine-learning/concept-ml-pipelines, abgerufen am 4.11.2022
[McK20] McKnight, W.: Delivering on the Vision of MLOps. Knowingly 2020
[Sch17] Schelter, S. et al.: Automatically Tracking Metadata and Provenance of Machine Learning Experiments. Long Beach 2017
[Scu15] Sculley, D. et al.: Hidden technical debt in Machine learning systems. Montreal 2015
[Tre21] Treveil, M.: Introducing MLOps. O’Reilly 2021









