

Das Anwendungsspektrum von ML ist enorm. Es reicht von Assistenzsystemen für Fahrer und Methoden des autonomen Fahrens in der Lagerhalle über Methoden der Sprach-, Bildund Mustererkennung für die Unterstützung z. B. der Kommissionierer sowie Methoden für prädikative Wartung bis hin zum prädikativen Qualitätsmanagement in den Produktionsprozessen. Selbst in Supportprozessen wie z. B. Finanzen, Controlling, Human Resources oder Auftragsmanagement haben ML-Algorithmen bereits Einzug gehalten.
Andererseits wird das ML-Umfeld immer noch als sehr komplexe Elfenbeinturm-Disziplin angesehen, zu der Institute und Fakultäten, geschweige denn die oft mittelständischen Unternehmen nur selten den richtigen Zugang finden. Insbesondere kleine und mittelständische Betriebe scheuen Investitionen in diesem Bereich, da ML in der Breite kaum bekannt ist und für Implementierungen meist auf teure Experten zurückgegriffen werden muss.
Angehende Wirtschaftsingenieure zum Beispiel werden in Bachelor- und Master-Programmen als „Generalisten“ ausgebildet und befassen sich meistens gar nicht mit ML-Algorithmen. Vielmehr sind sie auf der Anwenderseite tätig und müssen einerseits Voraussetzungen, Folgen und Nutzen solcher Technologien abschätzen, andererseits auch Projekte leiten, in denen ML zur Optimierung von Unternehmensprozessen genutzt werden soll.
Die Cloud-Plattform DataRobot
In diesem Bereich von KI und ML soll nun eine neue Klasse von Cloud-Plattformen Abhilfe schaffen. Eine dieser neuen Plattformen ist „DataRobot“[1]. Mithilfe dieser Plattform zum „Automatisierten Maschinellen Lernen“ können Wirtschaftsingenieure problemspezifisch mit ein bis zwei Mausklicks verschiedenste ML-Modelle automatisiert erstellen, berechnen, auswerten und umfassend dokumentieren.
Benötigte in der Vergangenheit ein teurer Experte zwei bis drei Monate für die Erstellung eines spezifischen ML-Modells, werden nun in einer Stunde 60 bis 70 unterschiedlichste Modelle automatisiert erstellt. Am Beispiel von Data-Robot wollen wir zeigen, was solche Plattformen heute bereits leisten – und inwieweit die Phasen der „Knowledge Discovery in Databases“ (KDD) zur Abwicklung von Data-Mining-Projekten damit umgesetzt werden können.
Knowledge-Discovery in Datenbanken
Der KDD-Prozess beschreibt das Vorgehen bei Data-Mining- und ML-Projekten. Bereits Mitte der Neunzigerjahre wurden hierzu grundlegende Arbeiten veröffentlicht – in einer Zeit also, als die Methoden des Maschinellen Lernens bei Weitem nicht so umfassend behandelt und für die gesamte Industrie fit gemacht waren, wie das im Jahr 2020 der Fall ist.
In einem der grundlegenden Beiträge von R. Brachmann und T. Anand[2] wird der KDD-Prozess in neun wesentliche Schritte eingeteilt, die hier nochmal kurz erläutert werden (siehe Abbildung 1):
- Verstehen: Detailliertes Analysieren und Verstehen der Anwendungsdomäne und des Vorabwissens sowie Identifikation des Ziels eines neuen Data-Mining- bzw. ML-Projektes
- Zieldaten: Analyse und Erstellung eines Datensatzes mit dem Fokus auf relevante Attribute, mit dessen Hilfe die Analyse durch das KDD-Projekt angegangen werden soll
- Datenbereinigung: Behandlung von Rauschen, fehlenden Daten, Messwerten und Zeitabhängigkeiten
- Datenreduktion: Auffinden der wesentlichen Features (Variablen) in Bezug auf das Ziel. Reduktion der Dimensionen, ggfs. nützliche Transformationen der Daten
- Methodenselektion: Auswahl der speziellen Data-Mining-Methode (Klassifikation, Regression, Clustering, etc.)
- Algorithmusselektion: Auswahl eines spezifischen Algorithmus zur Behandlung der Daten entsprechend der ausgesuchten Methode und des angestrebten Ziels
- Data-Mining: Aufsuchen von relevanten Mustern, Klassifizierungsregeln etc. Mit zusätzlichem Wissen und iterativem Ausführen der vorherigen sechs Schritte kann der Anwender die Datenanalyse enorm verbessern oder vereinfachen.
- Visualisierung: Dieser Schritt bezieht sich insbesondere auf die Auswertung gefundener Muster und Modelle.
- Deployment: Extraktion und Dokumentation des Wissens sowie Überführung und Implementierung in andere Systeme
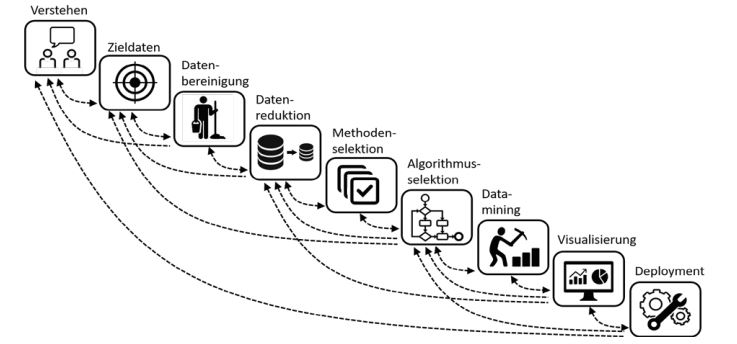
Abb. 1: KDD als Iterativer Prozess, nach R. Brachmann und T. Anand[2]
Diese wesentlichen Schritte sind für die Durchführung eines ML-Projektes nach wie vor relevant. Auch wenn andere KDD-Modelle mit teilweise weniger Schritten beschrieben werden (siehe hierzu z. B. die Zusammenfassung von A. Sharafi[3]), bleiben die Inhalte in allen KDD-Modellen sehr ähnlich. Sie beschreiben immer einen sehr iterativen Prozess, der unter Umständen aufwendig mehrmals durchlaufen werden muss.
KDD in der Plattform „DataRobot“
Wesentliche Gründe zur Untersuchung der Plattform „DataRobot“ der gleichnamigen Firma aus Boston (USA) waren die einfache Bedienung, der gute Zugang zu Schulungsunterlagen, die Dokumentation sowie angemessene Kosten für akademische Lizenzen. Im Rahmen erster Abschlussarbeiten wurde die Unterstützung der neun KDD-Prozessschritte untersucht. Das erfolgte zunächst mit bekannten Beispielen und Problemstellungen, um den Resultaten auch Referenzmodelle und Benchmarks gegenüberstellen zu können.
Die Ergebnisse der bisherigen Anwendungsbeispiele waren sehr zufriedenstellend.
Beispiele und entsprechende Daten wurden z. B. auf dem Portal www.kaggle.com eruiert und geladen. Mit DataRobot konnten vergleichbare und zum Teil auch bessere Ergebnisse erzielt werden als in den Kaggle-Ausschreibungen.
Einsatz von „DataRobot“ in Forschung & Lehre
Neben dem ersten Schritt, also der Analyse und Strukturierung der Problemstellung eines ML-Projektes sowie der ersten Vorgabe für die Zieldaten, unterstützt und automatisiert DataRobot den gesamten Zyklus eines ML-Projektes. Die Plattform lässt sich sehr intuitiv bedienen und erlaubt es dem Anwender, auch ohne Hintergrundwissen zur expliziten Funktionsweise der ML-Algorithmen professionelle ML-Projekte durchzuführen.
DataRobot ist aber auch eine spannende Plattform für absolute Experten – wegen der umfangreichen Analysewerkzeuge für die Algorithmik, der guten Performanz (um in kurzer Zeit viele Modelle für eine Problemstellung evaluieren zu können), der Möglichkeiten, in alle Details der Algorithmen und Einstellungen zur Modellbildung einzugreifen sowie der Deployment-Workbench.
Für Forschung und Lehre bietet DataRobot somit ideale Voraussetzungen, insbesondere für Wirtschaftsingenieure. Im Vordergrund steht dabei die angewandte Forschung in Industrie, Supply Chain und Logistik. In enger Zusammenarbeit, gerade mit kleinen und mittelständischen Unternehmen, können Studenten in spannenden Projekten und Abschlussarbeiten ML-Verfahren zur breiten Anwendung führen.
Literatur & Links
[2] Brachmann, R. & Anand, T. 1996, The Process of Knowledge Discovery of Databases, A Human Centered Approach, in AKDDM, AAAI/MIT Press, 37-58.
[3] Sharafi, A. 2013, Knowledge Discovery in Databases, Springer Gabler.









