

Über viele Jahre hinweg wurden große Investitionen in den Aufbau umfassender Data-Warehouse-Landschaften getätigt, um einen Einblick in vergangene Geschäftsereignisse zu erhalten. Prägend für derartige Systeme sind aufwendige nächtliche Batch-Prozesse, um eine Vielzahl komplexer Kennzahlen in seitenlangen Tabellenstrukturen auszugeben. Die für den Entscheidungsträger in seiner jeweiligen Situation relevanten Informationen lassen sich aus derartig umfassenden Berichtsergebnissen oftmals nur nach zeitaufwendigem und korrektem Interpretieren des Zahlenwerks ermitteln.
Im Zuge der Modernisierung vieler Analytics-Landschaften wurden insbesondere in den letzten Jahren schlankere DWH-Architekturen (zum Beispiel auf Basis von In-Memory-Datenbanken) umgesetzt und zugleich um Big-Data-Konzepte (zum Beispiel Hadoop) erweitert. Technisch gesehen konnten somit Daten in nahezu beliebigem Format (polystrukturiert) deutlich schneller nach ihrer Entstehung in die täglichen Entscheidungsaufgaben integriert werden.
Jedoch verlieren Mitarbeiter auch heute noch wertvolle Zeit mit der Überführung des bereitstehenden Datenschatzes in wertstiftende Maßnahmen für ihr Unternehmen. Zusammen mit dem kontinuierlich wachsenden Druck des Marktwettbewerbs und dem gleichzeitigen stetigen Werteverlust von Daten (zum Beispiel Sensordaten) wird dies zu einem der kritischsten Erfolgsfaktoren eines Unternehmens. Um den Nutzern analytischer Systeme in diesem Kontext eine weitere, stetige Verbesserung in der Unterstützung ihrer Arbeit zu geben, ist die Integration von KI ein vielversprechender Ansatz, um analytische Systeme zu befähigen, eigenständig zu lernen und die für ein Individuum passenden Informationen automatisiert sowie situations- und zeitgerecht bereitzustellen. Im Folgenden werden Vorboten aus dem weiten Spektrum der KI vorgestellt, die heute und zukünftig die klassische BI-Welt mit Blick auf das skizzierte Ziel revolutionieren werden.
KI und Analytics
Alle reden von KI, doch was genau verstehen wir unter KI im Zusammenhang mit BI? KI ermöglicht eine weitere Evolution in der Art und Weise, wie wir Analysen durchführen. Aus dem Feld analytischer Lösungen, die bekannten Konzepten folgen, wie deskriptiv (Was ist passiert?), prediktiv (Was wird wahrscheinlich passieren?) und preskriptiv (Was ist die empfohlene Aktion und was ist ihre Auswirkung?), bewegen wir uns nun in die Bereiche kognitiver Intelligenz (Wie werden Aufgabenerledigungen durch selbstlernende Algorithmen verbessert?) und Künstlicher Intelligenz (Wie kann menschliches Verhalten nachgeahmt und menschliche Interaktionen repliziert werden?). Für weitere Details und Unterscheidungen der verschiedenen Arten von KI wird auf [Fel18, S. 6ff.] verwiesen.
Lassen Sie uns nun einen genaueren Blick auf eine Auswahl der Ansätze und Technologien von KI werfen, in die gemäß [DLS17] viele Organisationen heute investieren und die sie sich zu Nutze machen (siehe dazu auch [LDS18]).
- Maschinelles Lernen (ML) verwendet Algorithmen und mathematische Modelle, um Muster in Datensätzen zu identifizieren, die Maschinen unterstützen, Probleme autonom zu lösen und ihre Lösungsansätze schrittweise zu verbessern. Um dies zu erreichen, werden verschiedene Lern- und Trainingsmethoden für die Modelle angewandt (zum Beispiel (halb-)überwacht, unbewacht). ML hat sich bereits heute in verschiedenen Anwendungsbereichen wie Suchalgorithmen, Marketingkampagnen, Betrugsermittlung oder Kundenprofilierung etabliert. Eine gute Einordnung sowie Erläuterungen zu ML sind in [Fel18] nachzulesen.
- Deep Learning (DL) ist eine Form von ML. Die Besonderheit des Lernansatzes besteht darin, dass Repräsentationen für komplexe Konzepte eingeführt werden, die wiederum auf Repräsentationen basieren, die in ihrer Struktur einfacher sind. Dabei verwendet DL eine Reihe von hierarchischen und miteinander verbundenen Schichten (unter Verwendung neuronaler Netzwerke), um maschinelles Lernen durchzuführen. Die erste Ebene dient als Eingabeebene und liefert die entsprechenden Variablen [GBC16]. Im Vergleich zu ML ist DL schwerer zu interpretieren, zu verwalten und in seiner Ausführung langsamer. Seine Stärke ist jedoch die Genauigkeit der Ergebnisse, zum Beispiel bei der Bilderkennung.
- Natural Language Processing (NLP) umfasst Methoden und Techniken zur Verarbeitung und Analyse von Daten in natürlicher Sprache, die auf eine direkte, natürliche und sprachbasierte Kommunikation zwischen Mensch und Maschine abzielen. Neben der Kommunikation durch Sprachbefehle (zum Beispiel virtuelle Assistenten) sind in diesem Kontext vor allem auch die Interpretation großer Mengen unstrukturierten Textes, zum Beispiel für Dokument-Klassifikationen oder Sentiment-Analyse, zu nennen. Die Erzeugung natürlicher Sprache ist unter dem Begriff Natural Language Generation (NLG) ein aktuelles Forschungsfeld. Einen Überblick über NLP/NLG finden Sie im Blog von [Don18].
In der Deloitte State of Cognitive Study [DLS17] wird empirisch dargelegt, dass KI-Technologien das Geschäft von Unternehmen signifikant verändern werden. Wie nun KI-Technologien helfen, die heutige BI-Landschaft zu revolutionieren, betrachten wir in den folgenden Abschnitten.
BI revolutioniert durch KI
Um den nachfolgenden Abschnitten einen Orientierungsrahmen zu geben, wird eine etablierte, aber vereinfachte Schichtenstruktur eines BI-Systems zugrunde gelegt, die aus einer Datenaufnahmeschicht, einer Datenverarbeitungsschicht und einer Datenzugriffsebene besteht:
- Die Datenaufnahmeschicht befasst sich mit Methoden des Datentransfers und der Datenspeicherung, um jegliche Art von Daten (in ihrem Rohformat) in die angegebene Analyseumgebung zu bringen. Es ist die erste (persistente) Schicht in unserer Analyselandschaft.
- Die Datenverarbeitungsebene ist verantwortlich für die Vorbereitung der Daten für ihren Analysezweck (zum Beispiel Datentransformation, -harmonisierung, -anreicherung).
- Die Datenzugriffsschicht bietet Zugriff auf die aufbereiteten Daten, um mit den Daten zu arbeiten, die in der Datenverarbeitungsschicht verfügbar sind (zum Beispiel Datenvisualisierung).
Wie Analyselandschaften zukünftig architektonisch strukturiert sind, hängt wie auch heute schon von den konkreten Anwendungsfällen ab. Bis zum möglichen Erreichen der Stufe einer Artificial General Intelligence (AGI) ist davon auszugehen, dass auch morgen noch eine zumindest grundsätzliche Governance und Strukturierung der Analyselandschaften erforderlich sein wird. Abbildung 1 orientiert sich an dem grundsätzlichen Aufbau moderner Daten- und Analytics-Ökosysteme, wie in [HTZ18, S. 20ff.] beschrieben. Zudem legt sie den eben eingeführten Architekturrahmen neben die Darstellung. An konkreten Beispielen wird dieser Ansatz nachstehend erörtert und aufgezeigt, dass KI auf unterschiedlichen Ebenen Einfluss auf die Elemente und Bausteine heutiger BI-Architekturen nimmt.
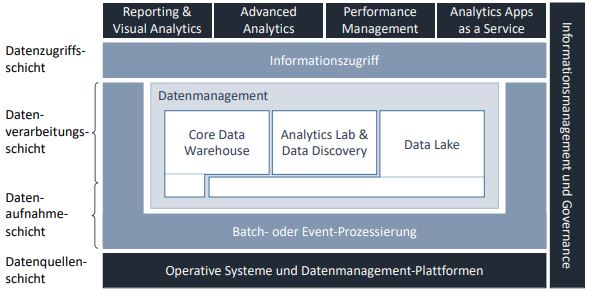
Abb. 1: Aufbau eines modernen Daten- und Analytics-Ökosystems als Basis für die Integration von KI
Datenaufnahmeschicht
Die Datenaufnahme ist eine der ersten Herausforderungen, um die gewünschten Daten aufzuspüren und an Bord eines analytischen Systems zu bringen. Dabei scheinen sich einige Fragestellungen bei jeder Datenquelle erneut zu stellen (zum Beispiel: Welche Datenfelder enthalten die gesuchten Werte? In welchem Format und in welcher Qualität liegen die Daten vor?). Nachstehend werden zwei Ansätze aufgezeigt, wie mit ML diese Fragen beantwortet und die zugrunde liegenden Verfahren (teil-)automatisiert werden können.
Automatisierung des Datenimports: ML ermöglicht es, Modelle zu trainieren, um gesuchte und für ein Analyseszenario erforderliche Felder in heterogenen Quellen zu identifizieren, semantisch zu kennzeichnen und sie gegebenenfalls einer gemeinsamen Zielstruktur zuzuordnen. Metadaten und Informationsmodelle sind dabei ein wesentlicher Schlüssel zum Verständnis der Quellen. Dieses Wissen gepaart mit Erkenntnissen aus historischen Datenintegrationsprojekten bildet die Grundlage für das Training der jeweiligen Modelle. Darüber hinaus hilft dieser Ansatz, alle erforderlichen Datenfelder zu finden, um das Bild einer ausgewählten Entität (zum Beispiel Geschäftspartner, Abschlüsse) zu vervollständigen. Mit derartigen Modellen profitieren insbesondere (globale) Datenintegrationsprojekte durch automatisch generierte Vorschläge für die eigentliche Implementierung bis hin zur automatisierten Generierung der Skripte für den Datentransfer.
Steigerung der Datenqualität: Bisher wurden qualitativ notwendige Datenanpassungen oft mit Hilfe regelbasierter Systeme (RBS) realisiert. Die große Menge entstehender Regeln und ihrer Abhängigkeiten untereinander generiert jedoch eine schwer zu verwaltende Komplexität. Schon heute wird ML erfolgreich eingesetzt, um Datenqualität automatisiert zu verbessern (zum Beispiel bei der Stammdatenverwaltung). Ausgebildete Modelle stehen zur Validierung, Ergänzung und Korrektur von Datensätzen zur Verfügung. Ein einfaches und allgemeines Beispiel ist die Verbesserung von Adress- oder Geschäftspartnerinformationen (siehe Abbildung 2). Dabei illustriert Kennziffer 1 eine automatisiert korrigierte Falschschreibung des Vornamens Jan basierend auf gelernten Erfahrungswerten, Kennziffer 2 die Vervollständigung einer Adresse durch Stammdatenabgleich der referenzierten Firma (fehlender Straßenname) sowie Kennziffer 3 eine Datenzuweisung des fehlenden Namens des zugewiesenen Coaches, beispielsweise aus verfügbaren Transaktionsdaten eines operativen Systems. Auf maschinelle Lernalgorithmen und entsprechend trainierte Modelle kann per Service-API zugegriffen werden, sie können auf diese Weise direkt in Datenaufnahmeprozesse integriert werden. Datenqualität ist somit definitiv nicht mehr eine Frage und Aufgabenstellung des Quellsystems.

Abb. 2: Beispiel einer ML-basierten Datenqualitätsverbesserung
Datenverarbeitungsschicht
Die Aufbereitung und Anreicherung der Daten für Analysezwecke ist das Herzstück jedes BI-Systems. Wie KI an dieser zentralen Stelle neue Impulse setzen kann, wird an zwei Beispielen illustriert.
Gruppierung und Klassifizierung unstrukturierter Texte: Dank Big-Data-Technologien können heute problemlos Textdokumente massenhaft prozessiert und gespeichert werden. Für deren Interpretation ist NLP die Disziplin der Wahl. Betrachten wir NLP nun als aktiven Teil der Datenverarbeitungsebene, erlauben uns die inhärenten Standardfunktionen ein Clustering und die Kategorisierung von Dokumenten bereits vor deren analytischer Nutzung. Die automatisierte Verknüpfung der erkannten Inhalte mit unternehmenseigenen Daten erfolgt modellgestützt (zum Beispiel Zuordnung zu einem Stammdatum eines Produkts). Darüber hinaus können proaktiv Hinweise mit dem Inhalt des als relevant erkannten Textabschnitts an die Datenzugriffsschicht (zum Beispiel den Endanwender) weitergereicht werden. NLP baut somit eine Brücke zwischen externen, unstrukturierten Daten und den internen, strukturierten Daten einer Organisation.
Einhaltung der Datenschutzbestimmungen: Ein weiterer NLP-basierter Anwendungsfall ergibt sich aus der neuen Datenschutz-Grundverordnung (DSGVO). Durch die Verwendung und Kombination von Ansätzen wie regulären Ausdrücken oder Named-Entity Recognitions (NER) können KI-Algorithmen trainiert werden, um Merkmale in den Dokumenten zu finden, die möglicherweise zu schützen sind. Durch das direkte Anonymisieren dieser Textpassagen (zum Beispiel Geburtstage, E-Mail-Adressen) ist es leicht möglich, Daten in der Analyselandschaft in Übereinstimmung mit den geltenden Bestimmungen zu halten.
Integration von Bild- und Videoinformationen:
Ähnlich wie beim Verschmelzen strukturierter und unstrukturierter Daten können wertvolle Erkenntnisse automatisiert aus Bild- und Videodaten extrahiert werden. ML und DL finden hierzu Anwendung. Der erste Schritt besteht in der korrekten Klassifizierung und Zuordnung dieser binären Daten zu anderen semantisch verwandten Daten, der zweite in der Ableitung der enthaltenen, relevanten Information. Diese wird dann im Datenverarbeitungsschritt mit vorhandenen, strukturierten Daten zusammengeführt (zum Beispiel Bilder eines beschädigten Produkts, die einem Versicherungsanspruch zugeordnet werden sollen).
Datenzugriffsschicht
Auf der Datenzugriffsebene kommen die Mehrwerte einer KI-gestützten Datenaufbereitung und -nutzung zum Vorschein. Dies bezieht sich insbesondere auf die Interaktion mit den Daten.
Nutzung von Sprachkommandos: Bereits heute gibt es produktive Analyselösungen, die Sprachbefehle nutzen, um Informationen abzurufen, aufzubereiten und in einem vordefinierten Dashboard auszugeben („Zeige mir die Umsatzzahlen für Süddeutschland im Jahr 2018“). Dabei funktionieren Sprachbefehle unabhängig vom Standort und dem benutzten Eingabegerät (zum Beispiel Smartphone, eigenständige Sprachmodule, Multimedia-Geräte in Fahrzeugen). In diesem Zusammenhang werden virtuelle Assistenten als Berater der Anwender eine Schlüsselrolle spielen, um die Nutzer gezielt zu den eigentlich benötigten Informationen zu führen. Rückmeldungen von den Anwendern zu analytischen Ergebnissen helfen den virtuellen Assistenten mittels ML, sich kontinuierlich zu verbessern und proaktiv sowie personalisiert Analyseergebnisse und Entscheidungsoptionen vorzuschlagen. Das aufwendige Erstellen individualisierter Berichte wird somit zu einem Relikt der Vergangenheit.
Verwendung von Multimediadaten als Eingabevariablen: In der Datenverarbeitungsschicht wurde dargelegt, dass Bilder und Videodaten zu einem festen Bestandteil der Analytics-Landschaft werden. Anstelle zahlreicher, beschreibender Eingabevariablen ist es technisch möglich, Bilder und Videos als Eingabe für die Abfrage von analytischen Informationen zu nutzen (zum Beispiel Eingabe eines Produktbilds zur Abfrage der Umsatzzahlen).
Ausblick
KI hält schon heute Einzug in die klassische BI-Welt und hebt diese auf eine neue Evolutionsstufe. Auf allen Ebenen eines BI-Systems können durch ML, DL, NLP oder weitere KI-verwandte Disziplinen zum einen Mehrwerte zur Automatisierung und damit zur Effizienzsteigerung sowie zum anderen neue Formen der Interaktion mit und Nutzung der verfügbaren Daten realisiert werden.
Literatur
[DLS17]
Davenport, T. / Loucks, J. / Schatsky, D.: Bullish on the business value of cognitive.
https://www2.deloitte.com/us/en/pages/deloitte-analytics/articles/cognitive-technology-adoption-survey.html, abgerufen am 26.4.2019
[Don18]
Donges, N.: Introduction to NLP.
https://towardsdatascience.com/introduction-to-nlp-5bff2b2a7170?gi=9196aada0f4c, abgerufen am 26.4.2019
[Fel18]
Felden, C.: Artificial Intelligence – Zusammenspiel des Maschinellen Lernens mit Künstlicher Intelligenz. TDWI E-Book 2018,
https://www.tdwi.eu/fileadmin/tdwi/1.0_Wissen/eBook/TDWI_E-Book_Artificial_Intelligence.pdf, abgerufen am 26.4.2019
[GBC16]
Goodfellow, I. / Bengio, Y. / Courville A.: Deep Learning. MIT Press 2018,
http://www.deeplearningbook.org/, abgerufen am 26.4.2019
[HTZ18]
Haneke, U. / Trahasch, S. / Zimmer, M.: Data Science – Organisation, Methoden, Architekturen, A nwendungen. TDWI E-Book 2018,
https://www.tdwi.eu/wissen/studien-buecher/e-books/wissen-titel/tdwi-e-book-data-science.html, abgerufen am 26.4.2019
[LDS18]
Loucks, J. / Davenport, T. / Schatsky, D.: State of AI in the Enterprise. 2nd Edition,
https://www2.deloitte.com/insights/us/en/focus/cognitive-technologies/state-of-ai-and-intelligent-automation-in-business-survey.html, abgerufen am 26.4.2019









