

Eine bekannte Herausforderung in jeder großen Organisation: Eine schwer überschaubare Menge an Daten, wertvoll, aber teilweise inkonsistent, mitunter unvollständig, manchmal unnötig schwer zugänglich.
Was wollen die Mitarbeiter?
Im Angesicht der Datenmenge ist es verständlich, dass Mitarbeiter sich für die Erledigung bestimmter Aufgaben eine Art Google wünschen. Mit einer derartigen Suchmaschine wollen sie genau und schnell die richtigen Antworten finden auf ihre jeweils gerade wichtigsten Fragen an die Daten und nicht etwa eine bemühte 42, wie jene von Deep Thought für Reisende durch die Datengalaxis [Ada79]. Nötig ist ein System, das verschiedene Datenbanken und Dokumente durchsucht, zusammengehörende Daten bündelt und dann genau die Ausschnitte ermittelt, die Mitarbeiter für die nächsten Arbeitsschritte benötigen. Was Google fertig bringt, kann doch nicht so schwer sein für ein Unternehmen, das Kraftwerke weltweit mit modernster Technologie erfolgreich ausstattet. Oder etwa doch? Um das zu klären, betrachten wir den folgenden Fall etwas genauer.
Das will ein Bauleiter
Ein Bauleiter auf der Baustelle will im Überblick wissen, welche Komponenten für die anstehenden Bauarbeiten benötigt werden und welche davon bereits auf die Baustelle geliefert wurden.
Althergebrachtes passt nicht auf moderne Baustellen
Dieser Fall ist stark vereinfacht. Dadurch aber ist er verständlich und gibt die Sicht frei auf das Problem, das wir in diesem Beitrag besprechen. Ein Bauleiter benötigt Daten aus verschiedenen Fachbereichen des Unternehmens, in diesem Fall:
- Daten aus dem Engineering: „Welche technischen Komponenten benötige ich auf der Baustelle?“ und
- Daten aus der Logistik: „Welche technischen Komponenten sind bereits auf der Baustelle?“
Andere Aufgaben brauchen andere Daten, die oft aus mehr als zwei Fachbereichen stammen. Wir bleiben bei dem vereinfachten Fall und betrachten zwei Ansätze zur Beantwortung der Fragen genauer. Zum einen kann der Bauleiter sich die Daten aus dem Backoffice holen. Das funktioniert gut mit definierten Prozessen, ist aber aufwendig und braucht mehr Zeit als nötig, besonders dann, wenn Baustelle und Backoffice in verschiedenen Zeitzonen liegen. Zum anderen kann der Bauleiter sich die Daten holen, indem er aus der Ferne direkt auf die Werkzeuge der Fachabteilungen zugreift, vorausgesetzt die Fachwerkzeuge (Datenquellen) unterstützen das im notwendigen Umfang. Naturgemäß unterscheiden sich aber mit den Fachaufgaben auch die Fachwerkzeuge. Ein Werkzeug aus einem anderen Fachbereich kann schnell wie ein Expertensystem erscheinen, das um wertvolle Daten herum technische Barrieren errichtet. Das erschwert die Arbeit des Bauleiters. Und dann gibt es ja auch mehr als eine Baustelle, mehr als einen Bauleiter und mehr als ein Backoffice. Es gibt bessere Ansätze.
Frischer Wind durch alle Fachbereiche, von Baustelle bis Backoffice
Hilfreich wäre ein leicht zugängliches System, das im Kern Daten integriert, die aus unterschiedlichen Fachbereichen und unterschiedlichen Datenquellen (Quellsystemen) stammen. Ein kompletter Ersatz der Quellsysteme durch ein neues System kommt jedoch aus zeitlichen und finanziellen Gründen nicht infrage. Auch müssen Betrieb und Baustellen reibungslos weiterarbeiten und dürfen nicht unterbrochen werden durch die Einführung eines neuen Systems, das Reibung verringern soll. In dieser Situation bietet sich die Entwicklung eines Systems an, das parallel zu den Quellsystemen entsteht und alternativ zu diesen im laufenden Betrieb genutzt werden kann. Der Data Integration Layer ist geboren.
Eine Datenbrücke für viele kurze Wege
Der Data Integration Layer soll Daten aus etwa 30 Quellsystemen unterschiedlicher Bauarten und Hersteller integrieren und Zugriffe und Sichten auf diese Daten harmonisieren und vereinfachen. Dadurch soll zum Beispiel ein Bauleiter die relevanten Daten für die oben genannte Aufgabe mit einer einzigen Anfrage erhalten. Neben verschiedenen Mitarbeitern mit unterschiedlichen Interessen und Aufgaben soll der Data Integration Layer auch Programmen Zugang zu den integrierten Daten geben, zum Beispiel für automatisierte Analysen und Berichte. Für Softwarearchitekten von besonderem Interesse sind die sogenannten nicht-funktionalen Systemanforderungen, da diese das „Wie“ und damit die Qualität eines Systems und seiner Architektur bestimmen (Tabelle 1).

Tabelle 1: Wichtige nicht-funktionale Anforderungen an den Data Integration Layer

Kasten 1: Datendemokratie
Die Stützpfeiler des Data Integration Layer
Unser System, das diese Anforderungen erfüllen soll, besteht im Kern aus den folgenden Komponenten (siehe Abbildung 1):
- Der ETL-Dienst (Extract, Transform, Load) extrahiert und verknüpft Daten aus den Quellsystemen und speichert sie als Datenpunkte in einer semantischen Datenbank.
- Der QS-Dienst (Qualitätssicherung) überprüft die Datenpunkte auf Aktualität und Vollständigkeit, bevor diese für Anwender freigegeben werden.
- Der API-Dienst offeriert für die Kraftwerksdomäne maßgeschneiderte REST-Schnittstellen zum Zugriff auf die semantische Datenbank. Diese Schnittstellen können datenkonsumierende Programme organisationsweit nutzen und damit fachbereichsspezifische oder fachbereichsübergreifende Aufgaben lösen.
- Der Data Picker offeriert eine einfache und mächtige Nutzerschnittstelle zum interaktiven Zugriff auf die semantische Datenbank. Alle Mitarbeiter können den Data Picker organisationsweit und ortsunabhängig für Informationsrecherchen nutzen.
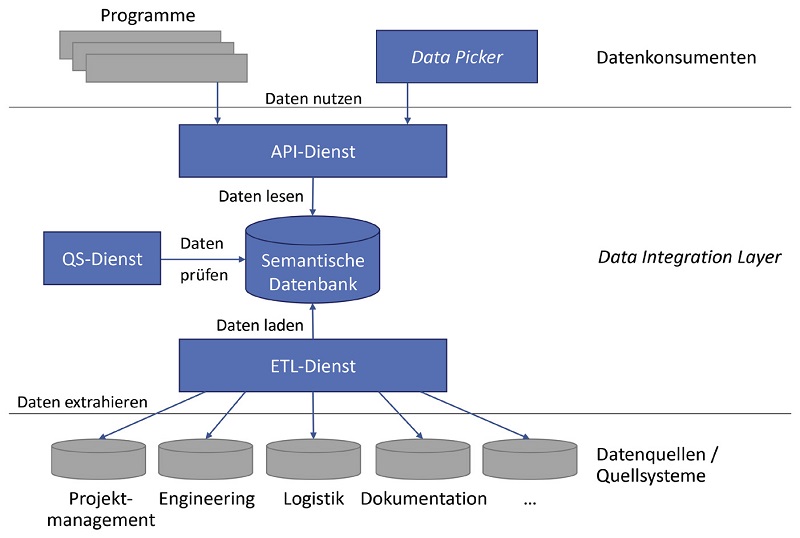
Abb. 1: Die Systemarchitektur im Überblick aus Teilen unserer Lösung (blau) und benachbarte Systeme (grau)
Der Zentralpfeiler: Die semantische Datenbank
Die semantische Datenbank ist der Zentralpfeiler der Systemarchitektur. Die semantische Datenbank enthält Daten aus den Quellsystemen, angereichert mit ihrer Bedeutung, und verknüpft diese mit bedeutungsgleichen Daten aus anderen Quellsystemen. Dabei kommen Knowledge- Graphen (siehe Abbildung 2) zum Einsatz, eine Technik, die auch Datenunternehmen wie Google oder Facebook einsetzen. Ein Knowledge-Graph repräsentiert komplexes, vernetztes Wissen als Menge von Datenpunkten. Als Datenpunkte bezeichnen wir Subjekt–Prädikat–Objekt-Relationen (SPO) und Subjekt–Attribut–Wert-Relationen (SAW). Damit lässt sich der Knowledge-Graph aus Abbildung 2 wie in Listing 1 darstellen. In Abbildung 2 dargestellte Datenpunkte zum Ventil entstammen den Quellsystemen Engineering und Dokumentation. Der Knowledge-Graph kann diese Datenpunkte über einen gemeinsamen Objektknoten (über einen speziellen Datenpunkt) verknüpfen, da das Ventil in beiden Quellsystemen nach dem Kraftwerkskennzeichnungssystem benannt ist. Die einfache Bauweise verleiht Knowledge-Graphen äußerste Flexibilität. Damit eignen sie sich für die schrittweise Integration großer Mengen an heterogenen, veränderlichen Daten. Verknüpfungen zwischen den Daten müssen nicht vollständig bekannt sein, insbesondere nicht zu Beginn der Integration einer neuen Datenquelle. Datenverknüpfungen können mit der Zeit erstellt werden. Das ist der entscheidende Vorteil, der es uns ermöglicht, ein Quellsystem innerhalb von drei Wochen zu integrieren.
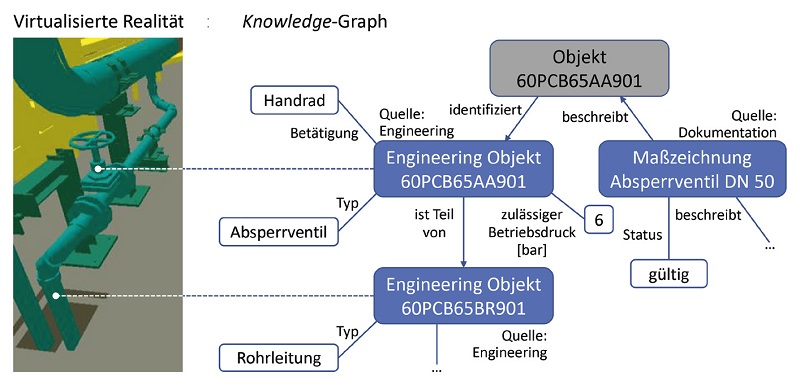
Abb. 2: Knowledge-Graph rund um ein Absperrventil (Engineering mit COMOS [COM], Visualisierung mit AVEVA E3D [AVE])

Listing 1: Knowledge-Graph als Menge von Relationen der Form Subjekt-Prädikat-Objekt (SPO) oder Subjekt-Attribut-Wert (SAW)
Ein dreischichtiges Fundament für den Zentralpfeiler
Obwohl in der Grundanlage äußerst flexibel, dürfen Knowledge-Graphen, die Daten integrieren sollen, nicht beliebige Daten aufnehmen. Über das Verständnis bestimmter Konzepte und deren Beziehungen muss in einer Gruppe von Mitarbeitern und über mehrere Datenquellen hinweg Einigkeit bestehen oder hergestellt werden. Hier kommen Ontologien zum Einsatz (Kasten 2).
Zu Beginn unseres Projekts versuchten wir, eine möglichst umfassende Ontologie zu definieren. Damit hatten wir keinen Erfolg. Daraus lernten wir und änderten den Ansatz. Im zweiten Anlauf verwendeten wir eine leichtgewichtige Ontologie und semistrukturierte Daten. Diese erweiterten wir nach und nach, was eben auch bedeutet, dass wir bestimmte Bereiche nicht in die gemeinsame Ontologie einschließen, aber trotzdem in den Knowledge-Graphen bringen. Wir gehen in Schritten vor. Diese spiegeln sich in Ontologie-Schichten wider (Abbildung 3). Im ersten Schritt (Phase 1) entstehen fachbereichsspezifische Ontologien. Wir erstellen für jede Datenquelle eine minimale Ontologie, die wir, zum Beispiel im Falle einer Datenbank, direkt aus dem Datenbankschema ableiten. Aus einer Spalte „zulässiger Betriebsdruck“ einer Datenbanktabelle mit Angaben über Ventile wird das gleichnamige Attribut für Ventile im Knowledge-Graphen (Abbildung 2). So überführen wir physisch oder konzeptionell in Form von Tabellen vorliegende Daten in einen Knowledge-Graphen. Dieser lokalisiert die Daten an einem Ort, verknüpft sie aber noch nicht fachbereichsübergreifend. Es entsteht ein Data Lake. Der bringt bereits beträchtlichen Mehrwert, da er Daten unternehmensweit viel schneller zur Verfügung stellt als zuvor. Allerdings obliegt den Mitarbeitern die Interpretation von fachbereichsübergreifenden Zusammenhängen zwischen den Daten. Im zweiten Schritt (Phase 2) integrieren wir Daten aus unterschiedlichen Quellsystemen. Dazu verwenden wir eine fachbereichsübergreifende Ontologie. Diese definiert die Identifikationssysteme, anhand derer wir Datensätze aus verschiedenen Datenquellen verknüpfen. Abbildung 2 zeigt, wie für ein Ventil die Engineering- und Dokumentationsdaten über das Kraftwerkskennzeichnungssystem im Knowledge-Graphen verknüpft sind. In einem weiteren Schritt kann die Bedeutung der Daten mit standardisierten Ontologien beschrieben werden, zum Beispiel mit der ISO 15926 [ISO04] für die Prozessindustrie.

Kasten 2: Ontologien und Knowledge-Graphen, wie wir sie verwenden
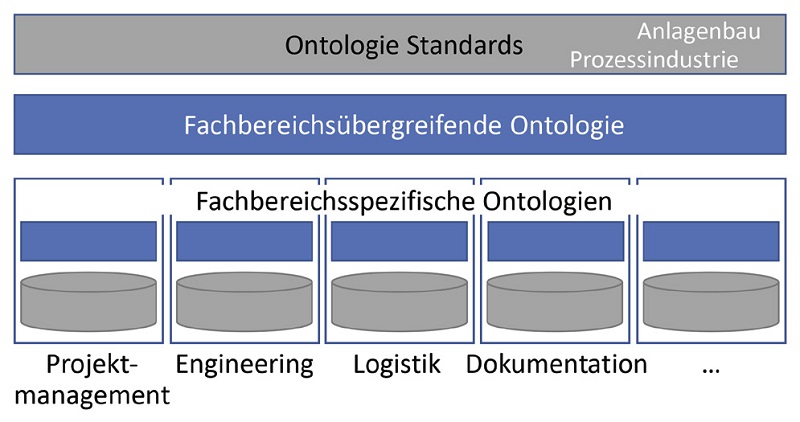
Abb. 3: Ontologie-Schichten mit Teilen in (blau) und außerhalb (grau) unserer Verantwortung
Zum Aufbau des Knowledge-Graphen mit dem ETL-Dienst
Wir können den Knowledge-Graphen in einer von zwei Varianten aufbauen. In der einen Variante bleiben die Datensätze in den Quellsystemen. Das ist die sogenannte virtuelle Datenintegration. In der anderen Variante werden auch die Datensätze in den Knowledge-Graphen überführt. Das ist die klassische Datenintegration mittels ETL. Bei der Entscheidung zwischen diesen Varianten geht es um eine geeignete Balance zwischen Qualitätsattributen wie Verfügbarkeit, Konsistenz und Performanz (Speicherplatz und Rechenzeit). Bei der virtuellen Datenintegration enthält das integrierende System lediglich Datenschemata der Quellsysteme und einen Knowledge-Graphen mit Quellsystem-übergreifenden Datenverknüpfungen. Fragt ein Mitarbeiter zum Beispiel Durchmesser und zulässigen Betriebsdruck eines bestimmten Ventils an, dann holt sich das integrierende System die Daten im Moment der Anfrage aus dem Quellsystem, das von der Anfrage betroffen ist. Was konzeptionell einfach klingt, stellt in unserem Fall einige technische und organisatorische Herausforderungen. Einige Quellsysteme erlauben direkte Zugriffe auf ihre Daten, andere stellen nur regelmäßig exportierte Dateien zur Verfügung, zum Beispiel in den Formaten CSV und XML. Wir haben uns daher für einen klassischen Ansatz mittels ETL entschieden. Ein ETL-Lauf erstellt den Knowledge-Graphen komplett neu aus den Datensätzen der Quellsysteme. Das passt zur geforderten Verfügbarkeit eines Systems, das den Bau von Anlagen für Kraftwerke unterstützt (Tabelle 1): Schnelle Antworten für Fragen an die integrierten Daten sind nötig, jedoch nicht die Integration und Nutzung der Daten in „Echtzeit“.
Unser Knowledge-Graph enthält aktuell rund 500.000.000 Datenpunkte, wobei wir bislang zwölf von 30 Quellsystemen integriert haben. Die Datenmenge wird in Zukunft also noch deutlich wachsen. Außerdem sollen Daten im Knowledge-Graphen nicht älter sein als 24h im Vergleich zu den Daten in den Quellsystemen. Der ETL-Dienst muss daher mindestens täglich laufen. Das erfordert eine robuste und performante Architektur, die bis zu den geforderten Grenzen inklusive Puffer skaliert.
Diverse kommerzielle und frei verfügbare Werkzeuge erlauben das Erstellen von ETL-Diensten. Zu Beginn des Projekts vor vier Jahren evaluierten wir einige davon. Wir fanden jedoch kein Werkzeug, das als Zielsystem eine semantische Datenbank unterstützt und unsere Anforderungen ausreichend erfüllt. Kommerzielle Werkzeuge, wie Alteryx, SnapLogic oder Talend, waren für relationale Datenbanken als Zielsystem ausgelegt. Daher entschieden wir uns, den ETL-Dienst selbst zu entwickeln. Für die Parallelisierung und Orchestrierung von Instanzen des ETL-Dienstes (ETL-Tasks) verwenden wir Airflow (Abbildung 4).
In Phase 1 laden ETL-Tasks fachbereichsspezifische Knowledge-Graphen und Ontologien in die semantische Datenbank. Dabei läuft für jede Kombination aus Kraftwerksprojekt und Quellsystem ein ETL-Task parallel zu anderen ETL-Tasks. Der zeitintensivste ETL-Task bestimmt die Laufzeit des ETL-Dienstes in dieser Phase, nicht jedoch die Anzahl der Projekte und Quellsysteme. In Phase 2 aktualisieren und erweitern ETL-Tasks den Knowledge-Graphen, sodass der Graph fachbereichsübergreifendes Wissen enthält. Die dafür nötige Information kommt von einem Domänenexperten. Der ETL-Dienst ist robust. Wenn ein ETL-Task scheitert, dann kann Airflow einen ETL-Lauf an dieser Stelle unterbrechen und nach der Fehlerbehandlung wiederaufsetzen. Eingabe-Dateien gescheiterter ETL-Tasks liegen unverändert vor. Somit wirkt sich ein gescheiterter ETL-Task auf nachlaufende ETL-Tasks aus, aber nicht auf vorlaufende und parallele ETL-Tasks. Das vermeidet einen teuren Neustart des gesamten ETL-Laufs.
Der ETL-Dienst läuft schnell genug, um die Systemanforderungen (Tabelle 1) zu erfüllen, ist aber teuer. Aktuell kostet ein fehlerfreier ETL-Lauf etwa 10 Stunden, 24 CPU-Kerne und 176 GB Hauptspeicher. Ein Grund dafür ist, dass die ETL-Tasks je einen Knowledge-Graphen aufbauen, um dessen Datenpunkte (Listing 1) in Form von Dateien im Turtle-Format [Tur] zu serialisieren. Die ETL-Tasks nutzen dafür die RDFLib [RDL]. Diese bietet viel mehr Funktionen an und baut dazu reichhaltige Strukturen auf. In unserem Fall kostet das mehr Laufzeit und mehr Ressourcen als nötig.
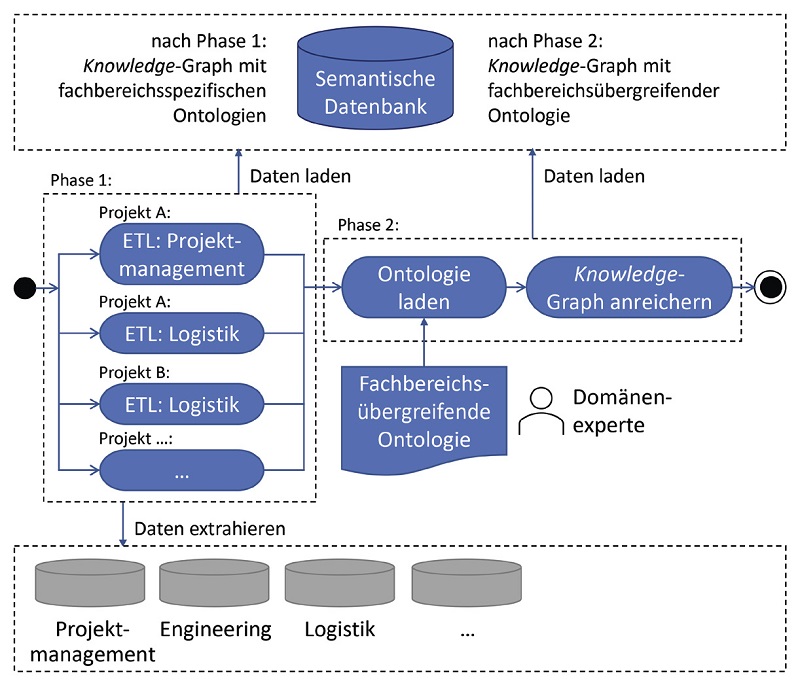
Abb. 4: ETL-Dienst aus parallelen ETL-Tasks für die Projekte A, B … in Phase 1 und sequenziellen ETL-Tasks in Phase 2
Zur Pflege des Knowledge- Graphen mit dem QS-Dienst
Der Knowledge-Graph muss korrekte und konsistente Daten enthalten, nicht älter als gefordert. Unterstützung kommt vom QS-Dienst nach jedem ETL-Lauf. Zum einen prüft der QS-Dienst die Korrektheit und Integrität der Daten mithilfe von Schlüsselfragen. Deren Antworten werden mit erwarteten und bekannten Antworten verglichen. Zum anderen berechnet der QS-Dienst Kennzahlen, die zeigen, ob der Knowledge-Graph alle Daten enthält. Beispiele für Kennzahlen sind die Anzahl der Datenpunkte im Knowledge-Graphen pro Projekt und pro Quellsystem und die Anzahl der Verknüpfungen über Quellsysteme hinweg.
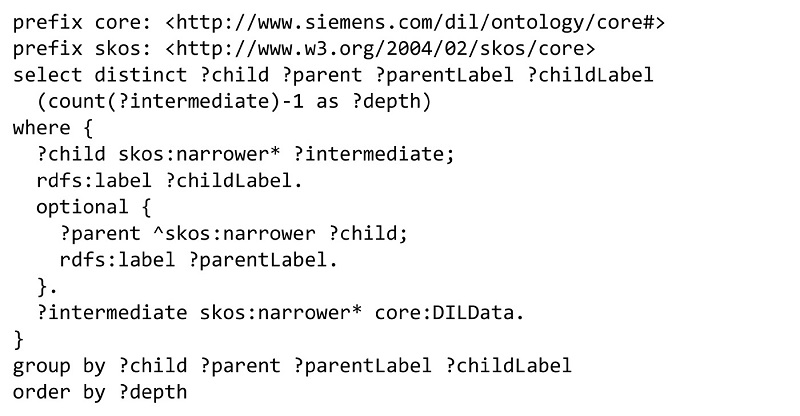
Listing 2: Vom API-Dienst vermittelte Funktion „Hierarchy“ liefert das Datenmodell des Knowledge-Graphen
Zum Nutzen des Knowledge-Graphen mit dem API-Dienst
Der API-Dienst gibt Programmen komfortablen Zugriff auf den Knowledge-Graphen über ein paar wenige Funktionen mit einfachen REST-Schnittstellen, die mit der Zeit eine vorteilhafte Stabilität erreicht haben. Die Schnittstellen erlauben uns, das semantische Datenmodell zu entwickeln, ohne Anwendungsprogramme zu brechen. Aus der Sicht der Anwendungsprogramme verbergen die Schnittstellen die Komplexität und Dynamik des Knowledge-Graphen.
Listing 2 zeigt beispielhaft die SPARQL-Implementierung einer Funktion des API-Dienstes, die die Konzepthierarchie des Knowledge-Graphen liefert (GET /api/hierarchy). Abbildung 6 zeigt das Ergebnis in der Tree View des Data Picker bei der strukturierten Suche nach dem Ventil aus Abbildung 2. Suchanfragen sollen schnell Ergebnisse liefern, spätestens nach einer Minute (Tabelle 1). Daher optimieren wir den API-Dienst nach der Laufzeit. Aktuell reichen bekannte Optimierungstechniken, um im geforderten Zeitlimit zu bleiben. Zum Beispiel weisen SPARQL-Anfragen den Query-Prozessor an, Datenfilter mit der größeren Selektionskraft vorrangig auszuführen, um den Suchraum einzuschränken. Im oben genannten Fall des Bauleiters, der den Lieferstatus von Komponenten erfragt, selektiert die Anfrage zunächst die Menge relevanter Komponenten, zum Beispiel in seinem Kraftwerksprojekt alle Ventile, die mit einer bestimmten Rohrleitung verbunden sind. Erst danach selektiert die Anfrage in der Menge der verbleibenden Komponenten deren Lieferstatus. Ein anderes Beispiel sind Indexstrukturen, die der ETL-Dienst zusammen mit dem Knowledge-Graphen erzeugt und die der Query-Prozessor für Direktzugriffe zur Beschleunigung häufiger Suchanfragen verwendet.
Mehrere Anwendungsprogramme generieren Mehrwert über den API-Dienst. Beispielsweise erstellt ein Programm für das Projektmanagement Berichte, die Fortschritt und Kosten eines Projekts gegenüberstellen. Ein anderes Programm aus der Business Intelligence offenbart Inkonsistenzen zwischen Datenbeständen unterschiedlicher Quellsysteme. Ein weiteres Anwendungsprogramm ist der Data Picker.
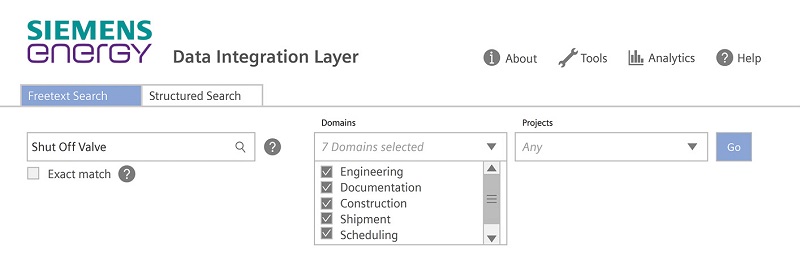
Abb. 5: Freitextsuche mit dem Data Picker à la Google
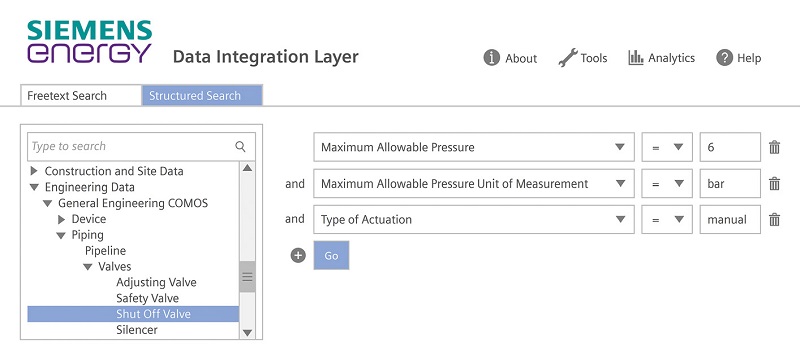
Abb. 6: Strukturierte Suche mit dem Data Picker
Zum Nutzen des Knowledge-Graphen mit dem Data Picker
An der Nutzerschnittstelle entscheidet sich der Erfolg des Data Integration Layer und damit der Nutzen des datendemokratischen Ansatzes für Unternehmen und Mitarbeiter. Der Data Picker ist der zentrale, offene und interaktive Zugang für alle Mitarbeiter des Unternehmens zu allen Daten. Nur sensible Daten sind verschlüsselt. Suchergebnisse können als Tabellen exportiert werden. Der Data Picker ist eine Webapplikation, implementiert in Angular und läuft unmittelbar in unterschiedlichen Webbrowsern. Die Nutzerschnittstelle ist einfach und selbsterklärend. Die Freitextsuche (Abbildung 5) erinnert in Erscheinung und Funktion an die Google-Suchmaschine, erweitert um häufig verwendete Filter, zum Beispiel nach Kraftwerksprojekten. Über die strukturierte Suche (Abbildung 6) können Nutzer komplexe Fragen stellen. Dazu stellt der Data Picker das hierarchische Datenmodell des Knowledge-Graphen zur Verfügung sowie einen Ontologie-gestützten Filtereditor. Mehr ist nicht nötig.
Fazit
Der Data Integration Layer auf Basis eines Knowledge-Graphen hat sich bewährt. Knowledge-Graphen sind tatsächlich leicht erweiterbar. Mittlerweile haben wir 50 Kraftwerksprojekte und zwölf Quellsysteme integriert. Mitarbeiter wünschen die Integration weiterer Projekte. Ontologien eignen sich zur Integration von Daten aus unterschiedlichen Quellsystemen. Wir empfehlen, die Ontologie ausgehend von den existierenden Datenmodellen zu entwickeln und die Quellsysteme inkrementell zu integrieren. Der ETL-Dienst ist der Engpass des Data Integration Layer. Daten aus den Quellsystemen täglich zu extrahieren und Duplikate anzureichern, braucht einige Rechenressourcen. Hier lohnen sich die maximale Parallelisierung von ETL-Tasks und Performanz-optimierter ETL-Code. Zum Beispiel können ETL-Tasks Datenpunkte in Turtle-Dateien direkt erzeugen, anstatt dafür den bequemen, aber ressourcenintensiven Umweg über die RDFLib und temporärere Knowledge-Graphen zu gehen. Außerdem evaluieren wir (erneut) Ansätze zur virtuellen Datenintegration und zur Fokussierung der ETL- und QS-Dienste auf die Integration geänderter Daten. Die Mitarbeiter haben die einfache, Google-artige Benutzerschnittstelle gut angenommen. Das zeigen die mittlerweile über 1000 Nutzer sowie die Rückmeldungen unserer Nutzerbefragungen.
Nach über vier Jahren Arbeit können wir sagen: Ein Knowledge-Graph in einer semantischen Datenbank, eingebettet in ein flexibles, servicebasiertes System ist geeignet, um typische Datenintegrationsprobleme eines großen Konzerns zu lösen. Zusammen mit intuitiven Schnittstellen für Nutzer und Programmierer ebnet der Ansatz den Weg hin zu einer datendemokratischen Unternehmenskultur.
Weitere Informationen
[Ada79]
D. Adams, The Hitchhiker’s Guide to the Galaxy, Macmillan, 1979
[AVE]
siehe:
https://www.aveva.com/de-de/products/e3d-design/
[COM]
COMOS, siehe:
https://new.siemens.com/global/de/produkte/automatisierung/industrie-software/plant-engineering-software-comos.html
[Cor06]
O. Corcho, M. Fernández-López, A. Gómez-Pérez, Ontological Engineering: Principles, Methods, Tools and Languages, Springer 2006
[Gru95],
T. R. Gruber, Toward Principles for the Design of Ontologies Used for Knowledge Sharing, in: Int. J. Human-Computer Studies 43, 5/6, 1995
[Gut21]
C. Gutierrez, J.F. Sequeda, Knowledge Graphs, CACM, 64(3), 2021
[ISO04]
ISO 15926, Industrial automation systems – Integration of life-cycle data for process plants including oil and gas production facilities, 2004
[Kle17]
M. Kleppmann, Designing Data-Intensive Applications, Ch. 2 Data Models and Query Languages, O’Reilly, 2017
[Mck]
siehe:
https://www.mckinsey.com/business-functions/mckinsey-digital/our-insights/the-need-to-lead-in-data-and-analytics
[RDL]
siehe:
https://github.com/RDFLib/rdflib
[Tur]
siehe:
https://www.w3.org/TR/turtle/









