

In der Vergangenheit haben wir brav und fleißig einen Login-Screen und den dazugehörigen Validierungsmechanismus in unsere monolithische Anwendung eingebaut. In einem verteilten System können und wollen wir das aber nicht mehr. Auch die Anwender werden es wohl kaum akzeptieren, dass sie sich, nur um im firmeneignen ERP-System auf den Lagerbestand und die Kundendaten blicken zu wollen, zweimal (oder sogar noch öfter) anmelden müssen. Zudem ist ein doppelt implementierter Anmeldemechanismus ein Risiko für doppelte, weil kopierte Fehlerquellen. Wäre es nicht schön, wenn wir das alles etwas komfortabler lösen könnten? An dieser Stelle kommen die Schlagworte Identity-Management (IDM) und Single Sign-on (SSO) ins Spiel.
SSO wörtlich genommen
SSO ist als Begriff schon recht weit verbreitet, doch verstehen viele Unternehmen und Entwickler unterschiedliche Dinge darunter.
Das geht von „jeder Login greift auf unsere AD- oder LDAP-Daten zurück“ bis zu „die Login-Daten werden von Anwendung zu Anwendung weitergegeben“. Beides Szenarien, die kein SSO darstellen. SSO bedeutet auch nicht primär, dass die Anwender sich nur ein einziges Mal anmelden müssen, um verschiedene Systeme nutzen zu können. Bestenfalls sogar nur einmal am Tag zu Arbeitsbeginn am Windows-System, und dann haben sie den ganzen Tag „Ruhe“ vor dieser „nervigen Anmelderei“.
Das ist eine schöne Nebenwirkung eines richtig implementierten und angewendeten SSO- und IDM-Systems. Denn Single Sign-on heißt im eigentlichen Sinne, dass der Anmeldeprozess, die Validierung der Anmeldedaten (wie Benutzername und Kennwort), nur in einem einzigen System stattfindet. Dieses System kann zwar für eine bessere Verfügbarkeit und Lastverteilung redundant und geclustert betrieben werden, die logische Einheit dieses Systems ist aber immer 1.
Es kommt letztendlich also nur ein einziges System mit den sensiblen Authentifizierungsdaten der Anwender in Kontakt. Nur dieses eine System muss auf diese Daten zugreifen und sie verstehen. Es muss entsprechend sicher ausgelegt werden, damit es so wenig wie möglich Angriffsvektoren bietet. Damit ist auch gleichzeitig das Potenzial, einen Fehler oder eine Schwachstelle im System zu betreiben, auch so gering wie möglich gehalten, da sich ein einziger Fehler nicht durch Copy&Paste zu vielen, irgendwann nicht mehr überschaubaren Fehlern und Angriffsvektoren potenzieren kann.
Identitäten verwalten
Zusätzlich zu einem System, welches die Anmeldedaten kennt und validieren kann, benötigen wir aber auch noch ein System, welches die eigentlichen Identitätsdaten der Anwender beinhaltet und dem wir vertrauen können, dass der Anwender, der gerade angemeldet ist, auch wirklich Hans Müller ist. Ein solches System ist ein Identity-Management-System, welches diese Informationen für uns vorhält und sicher zugreifbar macht.
Vereinfacht gesagt kennt das System die Zuordnung vom zuvor validierten Benutzernamen hmueller zu den weiteren Identitätsmerkmalen der Person Hans Müller, wie eben zum Beispiel der Name, die E-Mail-Adresse, eine Anschrift, oder auch andere Attribute. Identitäten sind dabei aber nicht nur auf Personen beschränkt, auch Geräte oder Systeme und Anwendungen können eine Identität darstellen. Gerade im Bereich IoT ist eine Identität jedes beteiligten „Things“, also jeden Gerätes, eine wichtige Sache. Aber auch wenn ein System A ohne Benutzerkontext auf System B zugreifen möchte, um beispielsweise Daten periodisch zu aktualisieren, muss System B wissen, „wer“ da gerade zugreift, dass es System A ist, einen Service darstellt und keine natürliche Person.
IDM-Systeme genießen per se eine besondere Vertrauensstellung, da wir davon ausgehen müssen, dass die Daten, die uns vom IDM zur Verfügung gestellt werden, korrekt sind. Aus diesem Grund muss auch ein IDM besonders sicher implementiert und betrieben werden, sodass Angreifer dort möglichst keine Daten manipulieren können und somit einen Identitätsklau begehen können.
Neben den eigentlichen Identitätsinformationen kann ein IDM auch Gruppen und Rollen verwalten. Dies ist je nach IDM unterschiedlich ausgeprägt und für das eigentliche Identitätsmanagement nicht wirklich von Belang, kann jedoch für die Steuerung, welche Aktionen ein Anwender in einem System ausführen kann oder auf welche Daten er Zugriff haben soll, also der Autorisierung, hilfreich sein.
Auth-was?
In den obigen Zeilen war bereits von den Begriffen „Authentifizierung“, kurz AuthN, und „Autorisierung“, kurz AuthZ, die Rede. Zwei Begriffe, die sehr ähnlich aussehen, da sie beide mit dem Präfix Auth beginnen. Aus diesem Grund verwechseln viele Menschen diese Begriffe immer wieder, obwohl sie unterschiedliche Bedeutung haben.
Bei der Authentifizierung geht es darum, zu erkennen, wer – welche Identität – eine Anfrage stellt. Die anfragende Partei muss sich dabei ausweisen – authentifizieren. Ohne Authentifizierung können wir in unserem System nicht feststellen, wer die Anfrage gerade ausführt, und somit maximal öffentliche, nicht-authentifizierte Zugriffe zulassen.
Die Autorisierung sagt, ob die anfragende Partei berechtigt ist, das zu tun, was sie möchte, also das was. Eine Autorisierung kann beispielsweise über Gruppenzugehörigkeiten (Group-based Access Control, GBAC), Rollen (Role-based Access Control, RBAC), Richtlinien (Policy-based Access Control, PBAC) oder andere Attribute (Attribute-based Access Control, ABAC) ermittelt werden.
Auch die HTTP-Statuscode-Spezifikation [HTTPSC] nimmt die Definition nicht ganz korrekt vor. Der Statuscode 401, der dann gesendet wird, wenn keine Authentifizierungsdaten vorliegen, hat die Bezeichnung Unauthorized, müsste aber eigentlich Unauthenticated heißen. Beim Statuscode 403, der gesendet wird, wenn die Anwendung einen authentifizierten Request erhalten hat, die anfragende Partei aber keine Rechte hat, die Aktion auszuführen, heißt Forbidden, was eigentlich einem Unauthorized entsprechen würde.
Token als Währung
Die Herausforderung ist nun, die Authentifizierungs- und Autorisierungsdaten in einem verteilten System mit zentralem SSO und IDM an die einzelnen Anwendungen und Services weiterzugeben, sodass die komplette Kommunikation weiterhin sicher und vertrauenswürdig bleibt.
Diese Herausforderung ist ebenfalls bereits gelöst – die Lösung heißt Token. Das Prinzip des Tokens ist nicht neu, bereits Anfang der 2000er Jahre wurde mit dem SAML-Standard [SAML] ein XML-basiertes Token eingeführt, um eben genau diese Informationen zwischen Anwendungen transportieren zu können.
SAML an sich ist nicht schlecht, aber dennoch kein einfach zu verstehendes und leichtgewichtiges Protokoll. Zudem ist XML ein von heute modernen Webanwendungen auch oftmals nur schwer zu verarbeitendes Format. Diese kommen mit dem modernen JSON-Format deutlich besser zurecht. Zusammen mit modernen Authentifizierungsmechanismen wie OAuth2 und OpenID-Connect (siehe nächster Abschnitt) hat sich für Token das JWT-Format [JWTio] – JSON Web Token – etabliert und wurde auch entsprechend standardisiert [JWT].
Damit ein JWT problemlos zwischen verschiedenen Systemen wie Anwendungen, Server, Services und Browsern über das Web übertragen werden kann, wird es Base64 codiert. Base64 ist wohlgemerkt nur eine Codierung einer Zeichenfolge in eine reine, zeichensatzunabhängige ASCII-Zeichenfolge, die keine problematischen Sonderzeichen mehr enthält. Base64 ist keine Verschlüsselung, der Algorithmus zum Maskieren der Zeichen sowie zum Demaskieren ist öffentlich und enthält keinerlei Secrets oder Salts, die für die Konvertierung benötigt werden. Ein maskiertes JWT sieht dann in etwa wie in Listing 1 aus.
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.
XbPfbIHMI6arZ3Y922BhjWgQzWXcXNrz0ogtVhfEd2oWenn man diese Zeichenfolge genauer unter die Lupe nimmt, fallen die zwei Punkte auf, mit denen die Zeichenfolge in drei einzelne Teile geteilt wird. Das sind die drei Bestandteile eines JWT:
- der Header mit Kopf-, Meta- und Steuerdaten,
- der Payload mit den eigentlichen Nutzdaten und
- die Signatur des Tokens.
Mithilfe der Signatur ist das Token self-contained – es beinhaltet also bereits alles, um die Unversehrtheit des Tokens selbst zu überprüfen; es ist kein weiteres System zur Laufzeit notwendig, welches verfügbar sein muss, um das Token zu validieren. Das JWT aus Listing 1 sieht decodiert wie in Listing 2 aus.
Header:
{
"alg": "HS256",
"typ": "JWT"
}
Payload:
{
"sub": "1234567890",
"name": "John Doe",
"iat": 1516239022
}
Signature:
HMACSHA256(
base64UrlEncode(header) + "." +
base64UrlEncode(payload),
"secret"
)Die Attribute eines JWT werden, wie bei SAML auch, „Claims“ genannt und sollen, so die Empfehlung, möglichst kurz gehalten werden, da das Token bei einem Request mitgesendet wird und somit die Gesamtgröße des Requests beeinflusst. Kurze Claim-Namen bedeuten weniger Zeichen und damit ein kleineres Token. Im Header steht meist nur der Typ des Tokens, also „JWT“, und mit welchem Algorithmus die Signatur erstellt wurde.
Etabliert haben sich HS256 (HMAC mit SHA-256) für eine synchrone Verschlüsselung mittels eines Secrets und RS256 (RSA mit SHA-256) für eine asynchrone Verschlüsselung mittels Public-/ Private-Keypair. Aber es gibt noch weitere Algorithmen, die eingesetzt werden können, Details hierzu finden sich in der Spezifikation der JSON Web Signature [JWS]. In offenen Umgebungen sollte dabei nur ein asynchrones Verfahren zum Einsatz kommen, denn wer in den Besitz des Schlüssels eines synchronen Verfahrens kommt, kann das Token mitsamt Payload und Signatur verändern.
Der Payload eines JWT kann beliebige Informationen enthalten, sollte aber, wie bereits gesagt, möglichst kurz gehalten werden, um die Requestgröße nicht unnötig aufzublähen. Es gibt ein paar Standard-Claims, die in der JWT-Spezifikation [JWT] im Abschnitt 4.1 (Registered Claim Names) aufgeführt sind (s. Tabelle 1).
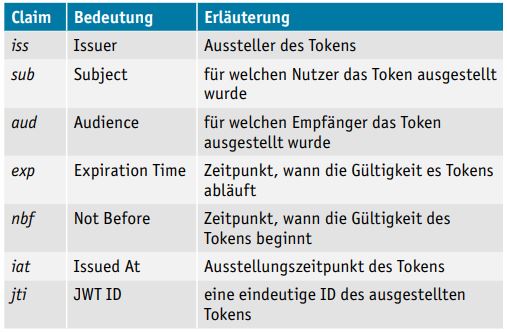
Tabelle 1: Standard-Claims, s. JWT-Spezifikation, Abschnitt 4.1 (Registered Claim Names)
Die Nutzung dieser registrierten und damit auch reservierten Claims ist zwar optional, wenn sie verwendet werden, müssen sie aber so, wie in der Spezifikation beschrieben, verwendet werden. So muss zum Beispiel ein Token mit einem abgelaufenen Gültigkeitszeitpunkt zwingend abgelehnt und darf nicht verwendet werden. Neben den registrierten Claims gibt es auch noch „Public Claim Names“ und „Private Claim Names“, die beliebig definiert werden können.
Das Token selbst ist nicht unbedingt verschlüsselt, sollte also keine sensiblen Daten enthalten. Sollen dennoch vertrauenswürdige Daten mittels JWT übertragen werden, so kann auch der Payload selbst verschlüsselt werden. Dies geschieht dann mit dem Standard JSON Web Encryption [JWE].
OAuth2 und OpenID-Connect Protokolle
Das Protokoll, das die Überprüfung einer anfragenden Partei, zum Beispiel eines Benutzers, vornimmt und dann letztendlich das Token ausstellt, heißt OAuth 2.0 [OAuth]. Dabei steht das Auth in OAuth für Authorization, nicht für Authentication. OAuth 2.0 erlaubt letztendlich einem fremden System (3rd party) den Zugriff auf einen HTTP-Service im Namen eines Benutzers oder im Kontext des fremden Systems selbst.
Das klingt jetzt vielleicht erst mal verwirrend, ist aber doch recht einfach: Stellen wir uns vor, Twitter ist der HTTP-Service, der einen Zugriff über OAuth 2.0 anbietet. (Twitter steht hier jetzt nur als Platzhalter eines beliebigen OAuth 2.0-Systems, es erleichtert es für den Anfang, einen bekannten Namen zu verwenden.) Das „fremde“ System ist unsere eigene Anwendung. Über OAuth 2.0 „erlaubt“ jetzt Twitter also, dass unsere Anwendung, entweder im Kontext der Anwendung selbst (aka. „technischer Benutzer“) oder eines Benutzers, der gerade die Anwendung bedient, auf Twitter zugreifen und dort Tweets lesen und gegebenenfalls auch posten darf. Twitter erhält dabei keinen Zugriff auf unser System oder unsere Daten (zumindest nicht, so lange wir Twitter keine Daten aktiv senden). Der Benutzer muss sich, um die Autorisierung vorzunehmen, zuvor an Twitter anmelden, also authentifizieren.
Damit das alles so reibungslos und so sicher wie möglich funktioniert, stellt OAuth 2.0 verschiedene Kommunikationsabläufe, sogenannte „Grant Flows“ zur Verfügung, die je nach Anwendungsfall (Web- oder Mobile-Anwendung, Benutzer- oder Systemkontext usw.) zum Einsatz kommen: Authorization Code Grant, Implicit Grant, Resource Owner Password Credentials Grant, Client Credentials Grant und Refresh Grant. Details hierzu liefert die Spezifikation [OAuth].
Findige Architekten und Entwickler nutzen nun einfach den Authentifizierungsmechanismus aus dem OAuth 2.0-HTTP-Service (Twitter) als Anmeldung, auch für die eigene Anwendung. Das OAuth 2.0-System gibt nämlich nach erfolgreicher Authentifizierung ein entsprechendes Token, auch AccessToken genannt, zurück. Auch Daten des gerade angemeldeten Benutzers können dabei an das aufrufende System zurückgegeben werden. Ein eigener Login-Vorgang ist dann nicht mehr unbedingt notwendig, wenn man dem OAuth 2.0-System vertraut und es gleichzeitig als IDM (s. o.) akzeptiert.
Zusätzlich zum AcessToken gibt es noch das RefreshToken, mit welchem ein abgelaufenes AccessToken erneuert werden kann, denn AccessTokens sollten nur eine kurze Gültigkeitsdauer aufweisen, sodass sie, falls sie in falsche Hände geraten, möglichst nur einen kurzen Zeitraum für einen Missbrauch verwendet werden können. Eine Gültigkeitsdauer im unteren einstelligen Minutenbereich bis hin zu nur Sekunden hat sich hier bewährt. Das RefreshToken hat hingegen eine längere Gültigkeit und stellt quasi die „Session-Idle“-Zeit dar, also die Zeit, die ein Nutzer keine Aktivität in der Anwendung vornehmen kann, ohne dass er sich neu anmelden muss. Erneuert wird das AccessToken dann mithilfe des RefreshTokens über den Refresh Grant Flow (s. o.).
Leider ist in der OAuth 2.0-Spezifikation weder standardisiert, wie die Daten des aktuellen Nutzers zurückgegeben werden, noch wie so ein Token aussieht. Ein OAuth2-Token kann einfach nur eine nichtssagende Zeichenfolge sein, die dann der Aufrufer jedes Mal, wenn er Informationen über den Nutzer benötigt, beim OAuth2-Service anfragen und abrufen muss. Detailinformationen über den Nutzer, die in der Antwort der Autorisierungsanfrage enthalten sein können, sind weder vorgeschrieben noch ist deren Struktur vereinheitlicht.
An dieser Stelle kommt nun OpenID-Connect [OIDC] ins Spiel. OIDC basiert in den Kommunikations-Flows vollständig auf OAuth 2.0, bringt aber eine Standardisierung der Authentifizierung mit ins Spiel. Identitätsinformationen eines Nutzers werden im JWT-Format übertragen und mit festgelegten Claims ([OIDCSpec], Kapitel 5) strukturiert. OIDC vereinheitlicht also, in welchem Format und in welcher Struktur die Profildaten eines Nutzers übertragen und zur Verfügung gestellt werden, und es erweitert OAuth2 noch um ein paar zusätzliche Endpunkte, um Profildaten gesondert abrufen und überprüfen zu können.
Da OAuth2 das Format des AccessTokens nicht standardisiert hat, bringt OIDC zusätzlich das IdentityToken ins Spiel, das also ein JWT sein muss, um die Informationen zu übertragen. In der Praxis hat sich aber bewährt, dass zusätzlich zum IdentityToken auch alle anderen Tokens als JWT formatiert übertragen werden, sodass keine Unterscheidung in der Behandlung vorgenommen werden muss. Das AccessToken kann dann direkt bereits alle nötigen Informationen über die Zugriffssteuerung, wie Rollen, Gruppen oder andere Attribute, enthalten, ohne dass der Empfänger erneut beim Aussteller nachfragen muss, was auch die Performanz des Gesamtsystems positiv beeinflussen kann.
Die Identitätsinformationen eines Nutzers können ebenso in das AccessToken verpackt werden und müssen nicht zwingend nur im IdentityToken abgelegt werden. Wenn, dann aber bitte nur in der von OIDC vorgegebenen Struktur, ansonsten ergibt die Verwendung des Standards wenig Sinn.
Fazit und Ausblick
Mit den besprochenen Standards OAuth 2.0, OpenID-Connect und JWT ist ein zuverlässiges und den heutigen Sicherheitsstandards und -ansprüchen entsprechendes SSO-System sehr gut realisierbar. Die Informationen über einen Nutzer, egal ob ein menschlicher Anwender oder ein technisches System, liegen nur noch in einem System vor, dem IDM, auf welches nur der OAuth2-Service Zugriff hat, beziehungsweise das IDM selbst den OAuth2-Service darstellt. Ein Nutzer gibt auch nur am OAuth2-System seine Authentifizierungsdaten ein, sodass keine Drittapplikation auf diese zugreifen kann. Der OAuth2-Service gibt nach erfolgreicher Authentifizierung und Autorisierung des aufrufenden Kontexts Access- und IdentityTokens zurück, welche die Zugriffs- und Profilinformationen des Nutzers beinhalten. Alle beteiligten Systeme, die Empfänger der Tokens, können mit diesen Artefakten arbeiten und ihrerseits wieder den Nutzer eindeutig identifizieren und für bestimmte Aktionen und Aufrufe zulassen oder eben ablehnen.
Der Umgang mit Nutzerdaten, Identitäten und anderen sicherheitsrelevanten und schützenswerten Daten erfordert, nicht nur in der Anwendungsentwicklung, eine erhöhte Sensibilität und Aufmerksamkeit. Aus diesem Grund sei allen Architekten, Entwicklern und anderen Beteiligten das Studium der Spezifikationen zu OAuth 2.0 [OAuth], OpenID-Connect [OIDC] und JWT [JWT] wärmstens ans Herz gelegt. Der bloße Einsatz und das blinde Verlassen auf ein System, das „das schon erledigt“, reicht nicht aus. Hat es in der Vergangenheit nie und wird es in der Zukunft erst recht nicht mehr. Einige Unternehmen kommen leider immer noch auf die Idee, solche komplexen Systeme selbst implementieren zu wollen. Dies stellt sich in der Praxis immer wieder als eine komplizierte und letztendlich falsche Entscheidung heraus, da es einzelnen Entwicklern und Teams, die sich nicht ausschließlich mit dem Thema Security beschäftigen, schwerfällt, in einer angemessenen Zeit ein hohes Schutzniveau zu implementieren. Der bessere Weg kann also nur sein, sich einer am Markt erhältlichen Lösung zu bedienen, die die besprochenen Anforderungen und Technologien abdeckt und implementiert und dennoch an die eigenen Bedürfnisse so gut wie möglich anpassbar ist.
Eine dieser derzeit flexibelsten, leistungsfähigsten und dennoch sichersten Lösungen ist Keycloak [KC] von JBoss/Red Hat. Keycloak basiert auf dem Server JBoss Wildfly, ist vollständig OAuth2 und OIDC zertifiziert, implementiert zusätzlich auch das SAML-Protokoll und ist als Community-Version frei erhältlich/einsetzbar. Wer eine supportete Version möchte oder benötigt, kann von Red Hat Support für das Produkt „RH-SSO“ beziehen, welches auf Keycloak basiert. Das System ist sehr umfangreich an eigene Bedürfnisse anpassbar, ohne dass es seine Upgradefähigkeit verliert (über eine Service-Provider-Interface-Architektur). Ebenso können Daten aus unternehmenseigenen LDAP- und AD-Verzeichnissen angebunden und das Look'n'Feel an das eigene Design angepasst werden.
Für die Integration in die eigenen Anwendungen stehen verschiedene Adapter bereit, sodass von der JavaScript-basierten Single-Page Application bis hin zu serverseitigen Anwendungen mit Java EE/Jakarta EE und Spring (Boot/Security) und sogar OS-Gi-Anwendungen alles möglich ist.
Sicherheit muss nicht immer kompliziert sein. Aber einen gewissen Aufwand muss es uns Wert sein. Sicherheit ist eine nicht-funktionale Anforderung im Anwendungsdesign und der Architektur, die an Tag 0 beginnt. Haarsträubende Geschichten wie „Wir brauche nur noch schnell eine Login-Seite“ kennen wir alle zur Genüge. Lassen wir das ab heute sein und sind sicher von Anfang an!
Literatur und Links
[HTTPSC]
RFC2616, Sec. 10: Status Code Definition, HTTP/1, https://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
[JWE]
RFC 7516, JSON Web Encryption, Internet Engineering Task Force, https://tools.ietf.org/html/rfc7516
[JWS]
RFC 7515, JSON Web Signature, IETF, https://tools.ietf.org/html/rfc7515
[JWT]
RFC 7519, JSON Web Token, IETF, https://tools.ietf.org/html/rfc7519
[JWTio]
https://jwt.io
[KC]
https://www.keycloak.org
[OAuth]
RFC 6749, The OAuth 2.0 Authorization Framework, IETF, https://tools.ietf.org/html/rfc6749
[OIDC]
OpenID Connect, https://openid.net/connect/
[OIDCSpec]
https://openid.net/specs/openid-connect-core-1_0.html
[SAML]
Security Assertion Markup Language, http://saml.xml.org









