

Das klassische Testvorgehen nach ISTQB [Spi12] verläuft nach einem Phasenplan mit genau festgelegten Aktivitäten. Diese sind
- Testplanung und Steuerung,
- Testanalyse und Testdesign,
- Testrealisierung und Testdurchführung,
- Testauswertung und Bericht sowie
- Abschluss der Testaktivitäten.
In Testanalyse und Testdesign wird die angestrebte Testabdeckung zum Beispiel in Form einer Testabdeckungsmatrix festgelegt. Daraus werden die abstrakten Testfälle abgeleitet, um in der anschließenden Testrealisierung in konkrete Testfälle überführt zu werden. Die konkreten Testfälle enthalten auch die Referenzergebnisse. Das Durchführen der konkreten Testfälle ergibt ein Testergebnis. Dieser Ablauf ist in Abbildung 1 (durchgezogene Pfeile) dargestellt.
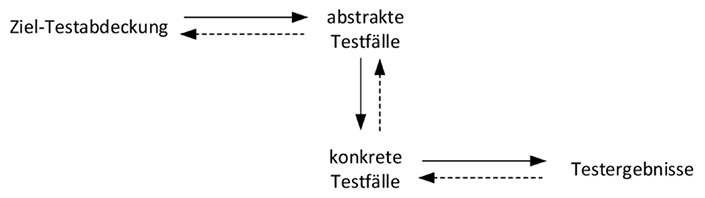
Abb. 1: Testfallerstellung und Ermittlung der Testfallabdeckung im klassischen Testvorgehen
In Kasten 1 ist ein einfaches Beispielsystem skizziert, welches im Folgenden als SUT = System Under Test bezeichnet wird. Das Beispielsystem sei so beschaffen, dass neben dem Geschäftsvorfall auch die Wahl des Produktes unterschiedliche Aktivitäten in der Anwendung auslöst. Für den Test dieses Systems wird die in Kasten 2 definierte Testabdeckung gefordert.
|
Bei dem fiktiven zu testenden System soll es sich um eine Anwendung zur Bestellung von Produkten handeln. Sie sieht diese 4 Geschäftsvorfälle (GeVos) vor: ■ GeVo 1 ■ GeVo 2 ■ GeVo 3 ■ GeVo 4 Folgende 5 Produkte können bestellt werden: ■ P1 ■ P2 ■ P3 ■ P4 ■ P5 Schließlich sei noch die Anzahl der Bestellungen für ein Produkt relevant. Aufgrund der fachlichen Anforderungen können hierfür folgende Äquivalenzklassen gebildet werden: ■ 0 ■ 1 – 10 ■ 11 – 100 ■ Größer als 100 |
|---|
Nach Ermittlung der Einflussgrößen für den Test werden diese einer Äquivalenzklassenanalyse unterzogen (siehe auch Kasten 3). Die für die einzelnen Parameter möglichen Wertebereiche werden in Gruppen eingeteilt, innerhalb derer die Anwendung sich gleichartig verhalten sollte. Anschließend bestimmt man die abstrakten Testfälle und überführt diese in konkrete Testfälle (siehe Tabellen 1 und 2). Im Beispiel sind diese so gewählt, dass die angestrebte Testabdeckung mit möglichst wenigen Testfällen erreicht wird.
|
■ Jeder Geschäftsvorfall muss mindestens einmal durchgeführt werden. ■ Jedes Produkt muss mindestens einmal getestet werden (unabhängig vom Geschäftsvorfall). ■ GeVo 1 und GeVo 2 müssen für alle Bereiche der Anzahl der Bestellungen durchgeführt werden. |
|---|
|
■ Äquivalenzklasse: Ein Teil des Wertebereichs eines mit dem Testobjekt verbundenen Datenelements, in dem aufgrund der Spezifikation erwartet wird, dass das Testobjekt alle Werte gleichartig behandelt. ■ Abstrakter Testfall: Ein Testfall ohne konkrete Werte für Eingabedaten und erwartete Ergebnisse. (Statt abstrakter Testfall ist auch die Bezeichnung logischer Testfall gebräuchlich.) ■ Konkreter Testfall: Ein Testfall mit konkreten Werten für Eingaben und vorausgesagte Ergebnisse. |
|---|
Abgesehen von sehr einfachen Systemen ist die Anzahl der benötigten Testfälle üblicherweise sehr hoch. Man kommt schnell auf mehrere Hundert oder Tausend Testfälle. Entsprechend groß ist der Aufwand für die Erstellung und Wartung dieser Testfälle.
Die Wahl der Testfälle hängt eng von der Analyse der für das System relevanten Einflussgrößen und der Bestimmung deren Äquivalenzklassen ab. Hätte diese für das Beispielsystem ergeben, dass alle Produkte fachlich gleiche Aktionen auslösen, dürfte das Produkt nicht im abstrakten Testfall, sondern erst im konkreten Testfall spezifiziert werden. In der Praxis ist es allerdings manchmal schwierig, vor Testbeginn alle Einflussgrößen zu ermitteln und für diese eine vollständige und fehlerfreie Äquivalenzklassenanalyse durchzuführen. Nicht immer liegt zu diesem Zeitpunkt schon eine vollständige Systemspezifikation vor, und in Wartungsprojekten ist eine solche manchmal auch gar nicht vorgesehen.
Wir schlagen daher vor, den Fokus bei der Ermittlung der Testabdeckung vom Testdesign auf die Testauswertung zu verlagern.
Testabdeckung als zentrale Zielgröße von Softwaretests
Zunächst soll aber das klassische Testvorgehen noch etwas weiter betrachtet werden.
Um die erreichte Testabdeckung mit der angestrebten Testabdeckung zu vergleichen, wird der oben beschriebene, aus mehreren Schritten bestehende Weg rückwärts durchlaufen (gestrichelten Pfeile in Abbildung 1). Die Ergebnisse der konkreten Testfälle werden auf die zugehörigen abstrakten Testfälle übertragen. Daraus ergibt sich die im Test erzielte Testabdeckung.
Üblicherweise verwendet man zur Beschreibung der angestrebten Testabdeckung sowie der abstrakten Testfälle eine fachliche Sprache, wie es auch im Beispiel in den Kästen 1 und 2 sowie den Tabellen 1 und 2 der Fall ist. Dabei sollte man aber die folgenden Punkte bedenken:
- In vielen Fällen ist die Zahl der fachlich relevanten Parameter groß, und damit sind die Testfälle kaum in übersichtlichen Formaten darstellbar. In der Praxis beschränkt man sich daher oft auf weniger, besonders wichtige Parameter.
- Manchmal ist es schwer zu entscheiden, ob ein bestimmtes Feld ein für den Test fachlich relevanter Parameter ist.
- Neben den fachlichen Parametern können auch technische Größen sowohl für das Testergebnis als auch für die Testabdeckung eine Rolle spielen. Dies sind beispielsweise Laufzeitumgebungen, verwendete Browser, die Netzwerkausstattung in der Testumgebung oder die Anzahl gleichzeitig angemeldeter Nutzer.
Der Raum möglicher Konfigurationen und fachlicher Konstellationen ist hoch-dimensional. Eine Segmentierung und Auswahl der relevanten Konstellationen ist schwierig und erfolgt in der Praxis daher im Allgemeinen nur ausschnittsweise.
Unter diesem Blickwinkel stellt sich das zu Beginn dieses Artikels dargestellte Verfahren als zu statisch heraus, weil es keine unmittelbare Antwort auf Fragestellungen, die sich erst aus der Testphase heraus ergeben, gestattet. Zum Beispiel stellte sich in obigem Beispiel im Testverlauf die Adresse des bestellenden Kunden als für den Preis relevantes Kriterium heraus. Die Beschreibung der angestrebten Testabdeckung (Kasten 1) ist relativ leicht anzupassen.
Anders verhält es sich mit den abstrakten Testfällen (Tabelle 1), in denen der neue Parameter bisher keine Rolle spielt und die daher umzustellen sind. Dies kann sich als aufwendig erweisen, da man ja nicht einfach jeden Testfall für alle Äquivalenzklassen des zusätzlichen Parameters vervielfachen möchte. Stattdessen wird es erforderlich werden, die Testparameter neu zu kombinieren, um die Anzahl der abstrakten Testfälle zu begrenzen. In der Folge sind dann auch die konkreten Testfälle (siehe Tabelle 2) umzustellen.
In diesem Bild ist die Ziel-Testabdeckung keine statische Information („Kreuze in der Testfallabdeckungsmatrix“), sondern eine dynamische Antwort auf ganz unterschiedliche, situationsbezogene Fragen, beispielsweise:
- Wurden alle relevanten Geschäftsvorfälle für alle Regionen ausgeführt?
- Für welche Produkte wurde ein bestimmtes Druckstück noch nicht erstellt?
- Für welche Produkte wurden Testfälle ab der Einspielung eines bestimmten Hotfixes durchgeführt?
Im Idealfall sollten dem Testmanagement Antworten auf solche Fragen „auf Knopfdruck“ zur Verfügung stehen, um in einem agilen Umfeld schnell reagieren und die weiteren Tests steuern zu können.
| Abstrakter Testfall | GeVo | Produkt | Anzahl |
|---|---|---|---|
| Testfall 1 | GeVo 1 | P1 | 0 |
| Testfall 2 | GeVo 2 | P2 | 0 |
| Testfall 3 | GeVo 3 | P3 | 1-10 |
| Testfall 4 | GeVo 4 | P4 | 1-10 |
| Testfall 5 | GeVo 1 | P5 | 1-10 |
| Testfall 6 | GeVo 1 | P1 | 11-100 |
| Testfall 7 | GeVo 1 | P1 | >100 |
| Testfall 8 | GeVo 2 | P1 | 1-10 |
| Testfall 9 | GeVo 2 | P1 | 11-100 |
| Testfall 10 | GeVo 2 | P1 | >100 |
| Konkreter Testfall | GeVo | Produkt | Anzahl | Kunde | Erwartetes Ergebnis |
|---|---|---|---|---|---|
| Testfall 1 | GeVo 1 | P1 | 0 | Huber, München | 0,00 |
| Testfall 2 | GeVo 2 | P2 | 0 | Müller, Augsburg | 0,00 |
| Testfall 3 | GeVo 3 | P3 | 1 | Meier, Köln | 3,50 |
| Testfall 4 | GeVo 4 | P4 | 5 | Schneider, Hamburg | 4,50 |
| Testfall 5 | GeVo 1 | P5 | 10 | Fritzle, Stuttgart | 6,50 |
| Testfall 6 | GeVo 1 | P1 | 65 | Färber, Berlin | 953,20 |
| Testfall 7 | GeVo 1 | P1 | 2.500 | Wedel, Dresden | 30.000,00 |
| Testfall 8 | GeVo 2 | P1 | 8 | Bauer, Münster | 120,00 |
| Testfall 9 | GeVo 2 | P1 | 11 | Bäcker, Frankfurt | 165,00 |
| Testfall 10 | GeVo 2 | P1 | 150 | Meier, Köln | 2.200,00 |
Testergebnisdaten
Die vorangehenden Überlegungen haben sich auf die Testabdeckung fokussiert, also auf die Eingangsparameter der Testfälle. Darüber hinaus benötigt eine Testauswertung auch die Testergebnisse. Im klassischen Testvorgehen versteht man hierunter die Information, ob ein Testfall erfolgreich durchgeführt wurde sowie ob und welche Abweichungen gegenüber den Referenzergebnissen aufgetreten sind.
Bei der hier vorgeschlagenen Vorgehensweise wird der Begriff Testergebnisse umfassender verstanden, indem alle bei der Testausführung im SUT entstandenen Datenspuren einbezogen werden. Dies können sein
- alle Einträge in der Datenbank, welche die Anwendung im Testzeitraum schreibt,
- Schnittstellenbelieferungen,
- protokollierte SQL-Statements und
- Laufzeitparameter der Systembestandteile (z. B. verfügbarer Speicher des Anwendungsservers).
Damit werden Informationen unabhängig davon, ob sie in der Testfallbeschreibung schon erwähnt werden, Teil des Testergebnisses.
Nutzung der Testergebnisdaten
Für das Beispiel aus Kasten 1 kann man die Testergebnisdaten durch Zugriff auf die Tabelleninhalte der Backend-Datenbank des SUT auswerten. Wir gehen von der in Kasten 4 dargestellten einfachen Tabellenstruktur aus. Die beispielhaften Tabelleninhalte ergeben sich nach Durchführung der Testfälle 1 und 4 aus Tabelle 2.
Das Datum in der Tabelle VORGAENGE zeigt an, wann ein Vorgang im System durchgeführt wurde.
Die folgenden Beispiele zeigen, wie die während einer Testphase erreichte Testabdeckung mittels einfacher SQL-Abfragen ermittelt und mit der in Kasten 2 festgelegten Soll-Testabdeckung verglichen wird.
„Jeder Geschäftsvorfall muss mindestens einmal durchgeführt werden“
SELECT DISTINCT(GeVo) FROM
VORGAENGE
WHERE Datum BETWEEN
<Testbeginn> AND <Testende>
Diese Abfrage liefert einer Liste aller zwischen <Testbeginn> and <Testende> ausgeführten Geschäftsvorfälle. Sie wird mit der GeVo-Liste in Kasten 1 verglichen.
„Jedes Produkt muss mindestens einmal getestet werden“
SELECT DISTINCT(Produkt)
FROM VERTRAEGE, VORGAENGE
WHERE VERTRAEGE.Vertragsnummer=
VORGAENGE.Vertragsnummer
AND Datum BETWEEN
<Testbeginn> AND <Testende>
Das Ergebnis dieser Abfrage wird mit der Produkt-Liste in Kasten 1 verglichen.
„GeVo 1 und GeVo 2 müssen für alle Bereiche der Anzahl durchgeführt werden“
SELECT DISTINCT(GeVo)
FROM VERTRAEGE, VORGAENGE
WHERE VERTRAEGE.Vertragsnummer
= VORGAENGE.Vertragsnummer
AND Datum BETWEEN
<Testbeginn> AND <Testende>
AND anzahl > 100
Diese Abfrage ergibt eine Liste durchgeführter Geschäftsvorfälle für Bestellungen mit einer Anzahl größer 100. Zur Überprüfung der erreichten Testabdeckung wird festgestellt, ob das Ergebnis dieser Abfrage die Vorgänge GeVo 1 und GeVo 2 enthält.
Bei diesem Vorgehen ist kein Rückgriff auf die konkreten oder abstrakten Testfälle erforderlich, um die erreichte mit der geforderten Testabdeckung zu vergleichen.
Auch weitergehende Fragen über die Testabdeckung lassen sich beantworten, zum Beispiel:
- Wurde ein bestimmtes Produkt seit Einspielen eines bestimmten Patches in das Testsystem bestellt?
Hierfür muss lediglich die Datumseinschränkung in den oben beschriebenen SQL-Abfragen angepasst werden.
- Wurden Bestellungen für Kunden aus allen Postleitzahlbereichen getestet?
Hierfür wird die Tabelle KUNDE in die Auswertungen einbezogen.
Datenermittlung direkt aus den Testsystemen
Die Praxistauglichkeit dieses Verfahren steigt erheblich, wenn ein benutzerfreundlicher Zugriff auf die technischen Datenformate des Testsystems eingerichtet wird. Aus den folgenden Datenformaten müssen die fachlichen und technischen Informationen leicht zu extrahieren sein (siehe Abbildung 2):
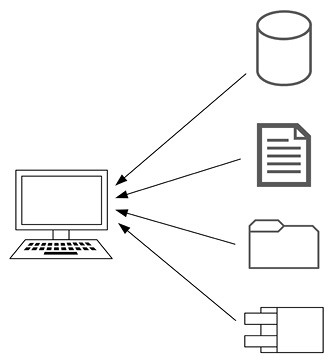
Abb. 2: Direktzugriff auf Datenbestände des Testsystems (Datenspuren)
- Datenbanken,
- Schnittstellendateien,
- Logdateien und
- Systeminformationen.
Für den Datenzugriff auf textbasierte Formate wird ein flexibler Parser benötigt, der die zur Ermittlung der erreichten Testabdeckung relevanten Informationen auslesen kann. Für Log-Dateien zum Beispiel sind die Informationen vom „Rauschen“ zu trennen und strukturiert aufzubereiten. Entsprechende Zugriffe sind für die übrigen Datenformate erforderlich.
Die ausgelesenen Datenspuren müssen auf die abdeckungsrelevanten Informationen verdichtet werden. Die auf diesem Weg ermittelte Testabdeckung wird schließlich mit der gewünschten Testabdeckung verglichen. Dies wird durch ein leistungsfähiges Vergleichswerkzeug erheblich vereinfacht.
Eine Werkzeuglandschaft zum Auslesen, Aufbereiten und Vergleichen der genannten Daten befindet sich derzeit im Aufbau.
Vorgehen beim retrospektiven Testen
Zusammenfassend sieht das Verfahren des retrospektiven Testens wie in Abbildung 3 dargestellt aus. Die wesentlichen Merkmale sind:
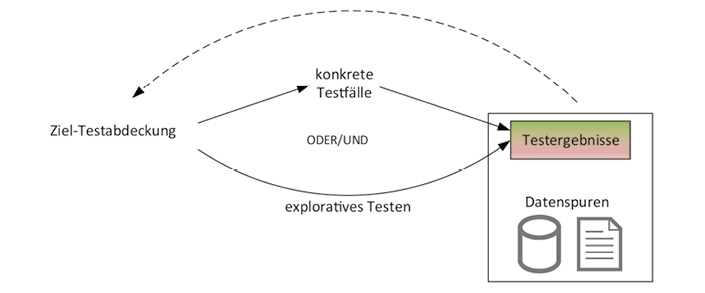
Abb. 3: Retrospektives Testen
- Abstrakte Testfälle sind nicht erforderlich, es werden nur konkrete Testfälle verwendet.
- Explorative Tests werden nahtlos miteinbezogen (siehe Kasten 4).
- Die Testabdeckung wird anhand der Spuren der Tests in den Testsystemen ermittelt.
- Die Testergebnisse („Datenspuren“) unterschiedlicher Datenquellen werden miteinander verknüpft.
Kasten 4: Tabelleninhalte der Beispielanwendung während einer Testphase
Zum einen bringt der Verzicht auf abstrakte Testfälle eine Aufwandsersparnis mit sich: Sie müssen weder erstellt werden noch fallen in der Folge Wartungsaufwände hierfür an. Auch der Vorlauf bis zum Testbeginn wird kürzer.
Der explorative Ansatz nutzt das Wissen der Fachtester effizienter. Diese müssen sich nicht in das enge Korsett niedergeschriebener Testfälle begeben, sondern können ihre Kenntnisse über Häufigkeit und Kritikalität der fachlichen Konstellationen unmittelbar in ausgeführte Tests übersetzen – ohne dass dem Testmanager die Übersicht über Testabdeckung und Teststatus verloren geht.
Alle Testaktivitäten werden in einheitlicher Weise reportet, unabhängig davon, ob diese testfallgebunden oder explorativ erfolgten (siehe Abbildung 3). Das Test-Reporting setzt direkt auf den Datenspuren im SUT auf.
Aussagen über die Testabdeckung sind nicht auf die in der initial definierten Testabdeckung berücksichtigten Einflussgrößen beschränkt. Mit einer geeigneten Werkzeugbox finden auch unvorhergesehene Analysefragen eine Antwort (wie in obigem Beispiel für die Postleitzahl gezeigt).
Damit kann auch der laufende Test sehr effizient gesteuert werden. Man beachte auch [Jür18], wo eine ähnliche Teststeuerung anhand von retrospektiven Auswertungen der Code-Überdeckung vorgeschlagen wird.
Beispiel Performanzanalyse
Das oben vorgeschlagene Vorgehen zur Nutzung der von Tests im SUT erzeugten Datenspuren fokussierte sich auf die Testabdeckung. Dies ist eine sehr wichtige, aber natürlich nicht die einzige testrelevante Größe.
Hat man einmal die technischen Mechanismen geschaffen, auf die Datenspuren effizient zuzugreifen, können diese Informationen für weitere Analysen genutzt werden. Diese können sowohl funktionale als auch nicht-funktionale Qualitätsmerkmale betreffen. Im folgenden Beispiel soll aus der Gruppe der nicht-funktionalen Qualitätsmerkmale das Last- und Performanzverhalten betrachtet werden.
Hierzu müssen, zum Beispiel in Datenbankeinträgen oder Log-Dateien, die Laufzeitinformationen zur Verfügung stehen. Diese werden dann zusätzlich zu den fachlichen Attributen ausgelesen und ausgewertet.
In [Mei19] wurde dies anhand des in Abbildung 4 schematisch dargestellten Aufbaus einer versicherungsfachlichen Anwendung durchgeführt: Eine Clientanwendung schickt eine Anfrage an einen Webserver (Request in Abbildung 4). Dieser leitet die Anfrage an einen Anwendungsserver weiter (Transmit). Die dort laufende Anwendung verarbeitet die Anfrage fachlich und liefert dem Webserver das Ergebnis (Result), der das Ergebnis an den Client zurückliefert (Response).
Abb. 4: Schematischer Aufbau des Testsystems
Die gemessenen Antwortzeiten in Abbildung 5 (Transaction Response Time) entsprechen der Dauer einer Anfrage vom Client zum Applikationsserver. Das Beispiel zeigt die Antwortzeiten für den Login, aufgezeichnet über einen Testzeitraum von ca. 4 Stunden. In dieser Darstellung fallen lediglich einige Ausreißer (sehr lange Login-Zeiten) auf, ansonsten lässt sich kein Trend oder eine anders geartete Regelmäßigkeit erkennen.
Für die weitere Auswertung ist es hilfreich, die beiden Aspekte
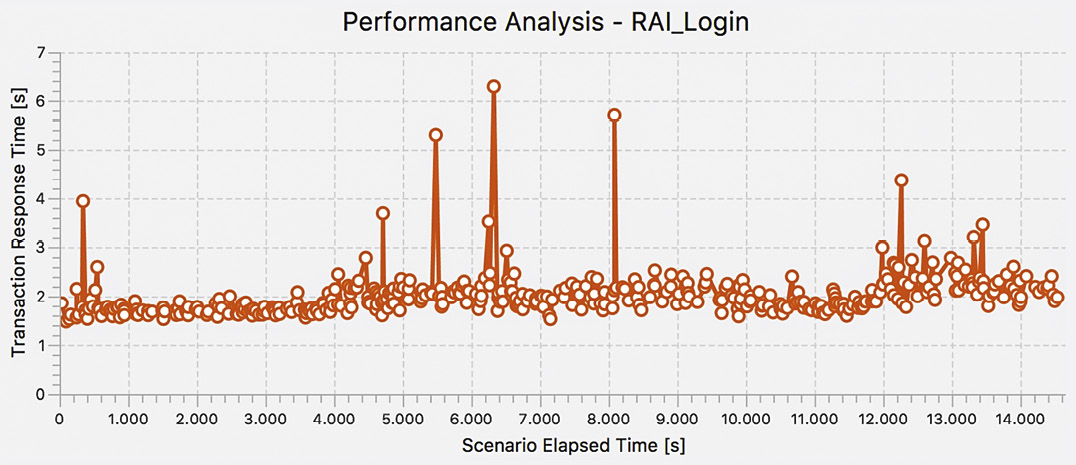
Abb. 5: Antwortzeiten für den Login eines versicherungsfachlichen Systems
- langfristiger Trend der Antwortzeiten und
- Analyse der Ausreißer
voneinander zu trennen. Im Folgenden wird nur der erste Aspekt untersucht. Der Einfluss der Ausreißer soll daher begrenzt werden. Dies erfolgte mithilfe einer Cluster-Analyse [Mei19]. Anschließend wurden die Daten durch eine Z-Transformation [Urb18] standardisiert. Nun lässt sich eine Tendenz, nämlich ein ansteigender Verlauf, erkennen (siehe Abbildung 6).
Weitere statistische Analysen können die Art des Verlaufs (linearer Anstieg, stufenweiser Anstieg usw.) genauer qualifizieren, was hier nicht weiter ausgeführt werden soll.
Ebenso könnte man die Ausreißer selbst mittels datenanalytischer Verfahren untersuchen, um Regelmäßigkeiten für ihr Auftreten zu erkennen und mit fachlichen oder technischen Informationen aus den Datenspuren (siehe auch Abbildung 2) zu korrelieren.
In diesem Beispiel wurde ein expliziter Lasttest durchgeführt, das heißt, es wurde zum Zweck der dargestellten Messung eine künstliche Last auf dem SUT erzeugt. Die Laufzeitdaten fallen aber auch dann an, wenn andere Arten von Tests ausgeführt werden, zum Beispiel rein funktionale Tests. Sofern die Tests über einen genügend langen Zeitraum laufen, können auch deren Ergebnisse verwendet werden, um Laufzeitauffälligkeiten zu erkennen und ihre Abhängigkeit zu fachlichen Konstellationen und weiteren Systemparametern zu analysieren.
Das Verfahren trägt genauso für weitere fachliche Transaktionen, siehe auch [Mei19].
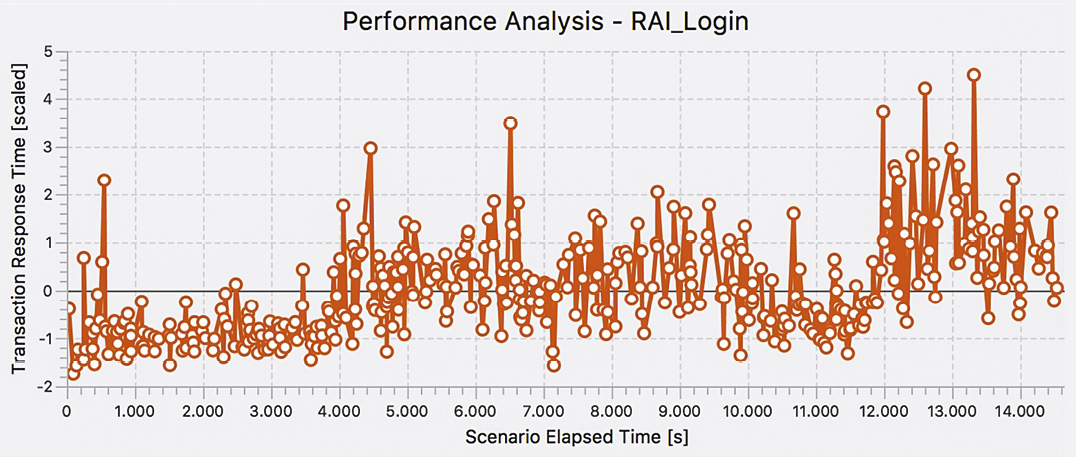
Abb. 6: Antwortzeiten für den Login eines versicherungsfachlichen Systems, nach Bereinigung und Standardisierung auf eine mittelwertfreie Größe
Fazit
Dieser Artikel zeigt auf, dass das klassische Vorgehen bei der Testfallerstellung und Testauswertung in dynamischen Kontexten an seine Grenzen stößt. Insbesondere Fragen zur erreichten Testabdeckung lassen sich nicht immer umfassend beantworten.
Wir schlagen daher vor, die Testabdeckung direkt aus den persistenten Wirkungen der zu testenden Anwendung zu ermitteln. Damit können weitere Testergebnisdaten sowie technische Informationen ausgelesen und dem Testmanager zur Verfügung gestellt werden. Mithilfe geeigneter Auswertungen ermöglicht dies zeitnah tiefe Einsichten in die Essenz eines Testergebnisses, welche zur Steuerung des weiteren Testvorgehens verwendet werden können.
Das Verfahren eignet sich insbesondere für Testprojekte mit starken explorativen Anteilen, kann umgekehrt aber auch das explorative Testen in klassischen Testprojekten stärken.
Als nächste Schritte möchten wir die Werkzeuglandschaft für retrospektive Tests ausbauen und weitere Analyseverfahren, wie fortgeschrittene statistische Methoden, Mustererkennung und Methoden der Künstlichen Intelligenz, einsetzen.
Weitere Informationen
[GTB] German Testing Board, Glossar.
[Jür18] E. Jürgens, D. Pagano, Haben wir das Richtige getestet?, in: OBJEKTspektrum, 02/2018
[Mei19] F. Meisinger, Hochschule für angewandte Wissenschaften München, „Automatisiertes frühzeitiges Erkennen und Bewerten der Performanzveränderungen von Software“, März 2019, Bachelorarbeit des Studiengangs Elektro- und Informationstechnik
[Spi12] A. Spillner, Th. Linz, Basiswissen Softwaretest, dpunkt.verlag GmbH, 2012
[Urb18] D. Urban, J. Mayerl, Angewandte Regressionsanalyse, 5. Auflage, Springer Verlag, 2018, Seite 67, Standardisierung von Rohwerten









