

Eine Simulation von McKinsey [McK18] sagt voraus, dass der Einsatz von KI allein in der Privatwirtschaft bis 2030 um etwas mehr als 55 Prozent zunehmen wird. Dies würde bedeuten, dass weltweit rund 70 Prozent der Unternehmen KI in ihren Prozessen einsetzen werden. Daher gilt es, heute zu handeln, um für den Markt von morgen gerüstet zu sein.
Im Folgenden beleuchten wir den SDLC (Software Development Life Cycle) für ML und definieren, was jede seiner Phasen voraussetzt. Sobald wir dies verstanden haben, können wir überlegen, wie wir unseren Testprozess an diese neue, intelligente Welt anpassen können. Anhand meiner eigenen Erfahrungen, die ich beim Testen einer Gesichtserkennungs-App machen durfte, werde ich die Änderungen, die wir am Testprozess, im Vergleich zu herkömmlichen Anwendungen, vornehmen müssen, darlegen.
Der SDLC für ML-Anwendungen
Sowohl herkömmliche als auch ML-Anwendungen basieren auf Anforderungen, die von Entwicklern umgesetzt und von Testern geprüft werden. Bei der herkömmlichen Anwendungsentwicklung wird nach dem EVA-Prinzip vorgegangen: Eingabe, Verarbeitung und Ausgabe. Man definiert Schritt für Schritt den gesamten Prozess, den die Maschine durchlaufen muss, um das passende Ergebnis für die Eingabedaten zu berechnen und dann anzuzeigen.
Auch in ML-Anwendungen schreiben die Entwickler zunächst viele Prozesse und Prozeduren. Im Kern solcher Anwendungen steht jedoch ein Algorithmus, der nicht vollständig definiert ist, sondern mit verschiedenen Parametern bestmöglich abgestimmt wird und lernt, welche Regeln erforderlich sind, um aus den Eingabedaten oder den erlebten Zuständen die gewünschte Ausgabe zu erzeugen. Diese sogenannte Hyperparameter-Optimierung lässt sich gut mit dem Begriff „Tuning“ beschreiben und erfordert die Wahl der optimalen Hyperparameter (der Parameter, deren Wert die Lernfunktion steuert) für den jeweiligen Lernalgorithmus.
Abbildung 1 skizziert den SDLC für ML. Im Folgenden gehen wir auf jede der vier Hauptaktivitäten kurz ein und erklären, wie der Testprozess durch den SDLC für ML beeinflusst wird.
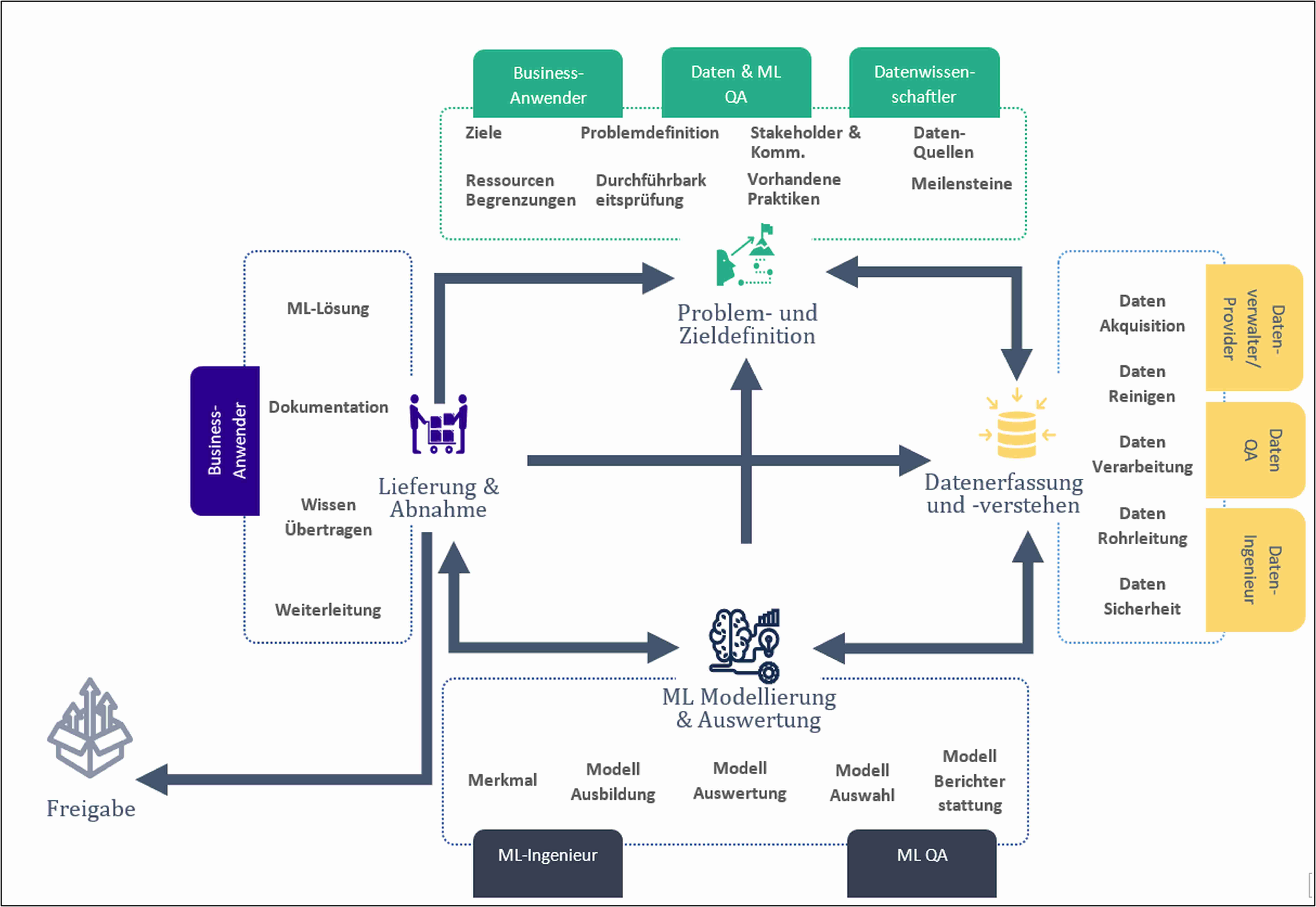
Abb. 1: Der Softwarelebenszyklus für ML-Anwendungen
Problem- und Zieldefinition
Die erste Aktivität kann mit der Phase der Anforderungsdefinition bei klassischen Anwendungen gleichgesetzt werden. Im Kern geht es darum, das Geschäftsproblem so zu formulieren, dass wir ein messbares Ziel identifizieren können, das dann zum Trainieren unserer ML-Algorithmen verwendet werden kann. Dies erfordert auch Konsens darüber, welche Daten verwendet werden sollen, woher sie kommen und wo sie gespeichert werden sollen. Es muss klar sein, welche Einschränkungen bei der Auswahl eines Algorithmus berücksichtigt werden müssen, beispielsweise, ob die ML-Lösung interpretierbar sein muss oder Belange des Datenschutzes beachtet werden.
Datenerfassung und -verständnis
Bei dieser Aktivität geht es um die Beschaffung der Daten, die wir für die verschiedenen in Frage kommenden Lernalgorithmen benötigen. Die Daten müssen zunächst aufbereitet werden, bevor sie in einem Algorithmus verwendet werden können. Dies kann zum Beispiel die Kombination verschiedener Datenquellen erfordern. In der Regel müssen die Daten zuerst bereinigt werden, da reale Daten oft aus verschiedenen Gründen verfälscht sein können. Auch die Datenexploration und -analyse ist in diesem Prozess hilfreich, um zunächst ein Verständnis für die Daten zu entwickeln. Schließlich müssen die Daten-Pipelines für Lernen, Testen, Abnahme und Produktion unterschieden und berücksichtigt werden.
ML Modellierung und Auswertung
Bei der dritten Aktivität werden die verfügbaren Algorithmen zunächst so eingegrenzt, dass sie für das Problem und die Daten geeignet sind. Zusätzlich zur Datenaufbereitung (dem sogenannten „Feature Engineering“) aus der vorherigen Phase werden die Daten dann so aufbereitet, dass sie auch von den ausgewählten Lernalgorithmen verarbeitet werden können. Dies kann eine entsprechende Erweiterung oder Anpassung der Daten-Pipelines erfordern. Ist dies abgeschlossen, geht es an die Abstimmung, Bewertung und Verfeinerung der Lernalgorithmen. Das Ergebnis dieses Schritts ist dann ein ML-Lösungsvorschlag für das gegebene Problem.
Lieferung und Abnahme
Bei der letzten Aktivität geht es darum, mit dem Kunden zu überprüfen, ob das Geschäftsproblem durch die vorgeschlagene Lösung tatsächlich gelöst wird. Ist dies der Fall, kann die Anwendung in Betrieb genommen werden. Dies ist auch der richtige Zeitpunkt, um die Dokumentation zu aktualisieren und den Wissenstransfer durchzuführen, damit die Endbenutzer das Produkt erfolgreich nutzen können. Diese Aktivität ist allerdings nie wirklich abgeschlossen, denn die Anwendung muss auch nach der Freigabe weiterhin überwacht, kontrolliert und gewartet werden.
Abbildung 1 zeigt, dass der SDLC für ML kein linearer, geradliniger Prozess ist. Die Entwicklung einer ML-Lösung für ein spezifisches Geschäftsproblem ist ein iterativer und explorativer Prozess. Es sind mehrere Iterationen durch die verschiedenen Phasen des SDLC erforderlich, bis die Anwendung freigegeben und produktiv genutzt werden kann.
Anpassung des Testprozesses an ML
Nun sehen wir uns an, wie der Testprozess angesichts der Eigenheiten der ML-Entwicklung angepasst werden muss. Als Beispiel verwende ich einen Gesichtserkennungs-PoC für den Zugang zu Unternehmenseinrichtungen.
Der normale Testprozess, unabhängig davon, ob es sich um eine agile oder eine Wasserfall-Entwicklung handelt, setzt voraus, dass die folgenden Schritte vor der Freigabe durchlaufen werden: Testplanung, -analyse, -entwurf, -implementierung, -durchführung, -abschluss und Gewährleistung der Überwachung sowie Kontrolle des gesamten Prozesses.
An diesen Kernkomponenten ändert sich im Grunde nichts, da sie alle ein Teil des ML-Testprozesses sein müssen. Aber die Reihenfolge unterscheidet sich, da wir die Testanalyse vor die Testplanung stellen, was im Folgenden näher erläutert wird. Außerdem zwingen uns die Eigenheiten von ML dazu, zwei separate Projekte zu bearbeiten: das Daten- und das Modellerstellungsprojekt.
Phase 1: Problem- und Zieldefinition
Hier müssen wir uns hauptsächlich mit der Testanalyse befassen. Das bedeutet, dass sich die QAs mit der Definition der Geschäfts- und Systemanforderungen beschäftigen müssen. Die Zielsetzung und die Datenquellen müssen von Anfang an sorgfältig geprüft und kritische Fehler umgehend erkannt werden, um frühzeitig reagieren und hohe Kosten vermeiden zu können.
In dieser Phase würden wir beim klassischen Testprozess die gewünschte Abdeckung definieren und uns genau ansehen, welche Verhaltensweisen wir überprüfen müssen. Eine Besonderheit der ML-Anwendung ist die Schwierigkeit, für das Modell die Codeabdeckung zu definieren, da es keine „geschriebene“ Logikschicht gibt. Die Logik des Modells ist die Ausgabe der Modellbildungsmethode und hat die Form einer Funktion mit mehreren Gewichten. Es reicht auch nicht aus, nur die Verhaltensbewertung zu planen. Wir müssen in dieser Phase überlegen, welche statistischen Auswertungen wir durchführen wollen, um das Modell zu validieren.
Diese Auswertungen sind sowohl für die Modellleistung als auch für die Bewertung der Datenqualität wichtig. Im Falle der Gesichtserkennung können wir zum Beispiel klassische Metriken wie Präzision, Recall und F1 verwenden. Zusätzlich können wir domänenspezifische Maße wie die echte Akzeptanzrate, die falsche Akzeptanzrate, die falsche Ablehnungsrate und die Rate der fehlgeschlagenen Anmeldungen berücksichtigen.
Nach Abschluss dieser Phase benötigt der Testmanager eine erste brauchbare Version des Testplans. Diese ist in der Regel nicht endgültig und kann im weiteren Projektverlauf überarbeitet werden. Ab diesem Zeitpunkt wird auch die Testüberwachung und -steuerung zu einer kontinuierlichen Aufgabe und hilft, den Testplan auf Kurs zu halten oder gegebenenfalls anzupassen.
Phase 2 + 3: Datenerfassung und -verständnis + ML Modellierung und Auswertung
Der Einfachheit halber können die zweite und dritte Phase des SDLC für ML als zwei getrennte Projekte betrachtet werden, wobei die zweite Phase von der ersten abhängig ist. Wenn man bedenkt, dass in der dritten Phase mit verschiedenen Lernalgorithmen experimentiert wird, gibt es mindestens zwei Möglichkeiten, die Arbeit aufzuteilen:
- Variante 1: Die Phase 2 wird zunächst für jeden Algorithmus separat durchgeführt, gefolgt von Phase 3.
- Variante 2: Die Phase 2 wird für alle Algorithmen durchgeführt, woraufhin die Aktivitäten aus der Phase 3 einen höheren Umfang an Datenaufbereitung beinhalten, um die Daten für jeden Algorithmus vorzubereiten.
Die Wahl der Variante wirkt sich zwar auf den Testplan aus, ändert aber nichts daran, dass sowohl Phase 1 als auch Phase 2 mindestens eine Leistung beinhalten. Daher sind Testentwurf, -implementierung, -durchführung und -abschluss in jeder Phase mindestens einmal enthalten.
Bei Variante 1 liegt der Schwerpunkt stärker auf Iterationen, daher haben wir es mit kleineren Ergebnissen zu tun. Dies ist für die Tester besser, da es die Anforderungen, die wir pro Release abdecken müssen, einschränkt. So können wir leichter den Überblick behalten, was wichtig ist, um Randfälle zu finden. In Variante 2 sind pro Release sehr viele Anforderungen zu testen. Das macht diese Variante etwas schwieriger, da wir sicherstellen müssen, dass nichts Wichtiges übersehen wird.
Bei der Datenaufbereitung sind häufig viele manuelle Anmerkungen erforderlich, um zu gewährleisten, dass die Daten und damit die Leistung des Modells nicht verzerrt werden. Am Beispiel der Gesichtserkennungs-App zeigt sich dies bei der Vermeidung von Diskriminierung hinsichtlich Rasse und Geschlecht. Studien zeigen, dass viele Gesichtserkennungs-Apps sehr gut weiße Männer erkennen, die Genauigkeit aber proportional mit der Intensivierung der weiblichen Gesichtsmerkmale und der Hautdunkelheit abnimmt [BuoGe18].
Wenn wir also die Qualität unserer Daten bewerten, müssen wir zunächst definieren, was für uns wichtig ist und eine Merkmalszuordnung vornehmen, bei der jedes Bild daraufhin überprüft wird, ob es ein bestimmtes Merkmal erfüllt oder nicht. Dies ist ein entscheidender Schritt bei der Testimplementierung, da wir sonst nicht die erforderlichen Testdaten generieren können, auf deren Grundlage wir die Datensatz- und Modellverzerrung bewerten. Klar definierte Merkmale werden später auch Dinge wie die Fehleranalyse ermöglichen.
Phase 4: Lieferung und Abnahme
Zu diesem Zeitpunkt führt der Kunde die endgültige Abnahmeprüfung durch. Wenn alles den Erwartungen entspricht, wird die App deployt. Von hier an dreht sich in dieser Phase alles um die Wartung. Solange die Anwendung in Produktion ist, muss es ein Team geben, das sich um alle unentdeckten Fehler kümmert, die sich in der Live-Umgebung offenbaren. Als Tester werden wir dort das tun, was wir schon immer getan haben: Wenn ein neuer Fehler entdeckt wird, müssen wir Regressionstests durchführen und sicherstellen, dass der Fehler nach der Fehlerbehebung nicht mehr auftaucht.
Der Schlüssel ist Prototyping
Die Komplexität und der experimentelle Charakter von ML-Projekten erfordern idealerweise einen zweigleisigen Ansatz: einmal für die Entwicklung und das Testen innerhalb der zweiten und dritten Phase und einmal für die Entwicklung und das Testen zwischen den Phasen. Für die erste Version des Testens innerhalb der Phasen ist eine iterative und inkrementelle Methodik wie Scrum oder Kanban gut geeignet. Für das Testen zwischen den Phasen ist ein Spiralmodell vorzuziehen, das beim Prototyping eingesetzt wird. In Anbetracht der Form des SDLC für ML können diese beiden Modelle sehr gut zusammen verwendet werden. Gemeinsam haben sie einen zusätzlichen positiven Effekt und wirken risikomindernd.
Angesichts der Eigenheiten von ML und des SDLC für ML ist Prototyping für die Entwicklung einer erfolgreichen Anwendung von entscheidender Bedeutung. Daher wechseln wir häufig zwischen der Problem- und Zieldefinition, der Datenerfassung und dem Verständnis sowie der Modellierung und Bewertung von ML. Jedes Mal, wenn wir ein funktionsfähiges System haben, welches das abdeckt, was in der Problem- und Zieldefinition festgelegt wurde, müssen wir dieses System als einen Prototyp betrachten. Sobald wir diesen Punkt erreicht haben, müssen wir eine weitere Runde von Tests durchführen, um das System gründlich zu prüfen. Die Testergebnisse werden dann an die entsprechenden Fachexperten weitergegeben, die entscheiden, ob der aktuelle Prototyp für den Zielkontext robust genug ist. Erst wenn die gewünschte Robustheit des Modells bestätigt wurde, sollte das Team damit beginnen, den Rest der Anwendung und der Prozesse um ein ML-Modell herum aufzubauen.
In unserer Gesichtserkennungs-App wollten wir fertige Modelle verwenden und nur einige Feineinstellungen vornehmen. Davor war es erforderlich, eine Reihe von Tests durchzuführen. Dabei haben wir unsere Auswahl auf einige Modelle eingegrenzt. Im Anschluss begannen wir mit der Arbeit an der Hardware und der Erstellung der erforderlichen Software, die einen reibungslosen Betrieb des Modells vor Ort ermöglichen wird. Diese Phase wurde mit einem Scrum-Ansatz durchgeführt. Parallel dazu nahmen wir eine Feineinstellung der ausgewählten Modelle vor, testeten sie und schränkten damit unsere Auswahl weiter ein. Nach Fertigstellung des Prototyps integrierten wir unsere Top-Modelle, um zu sehen, wie sie sich bei Live-Tests schlagen würden. Das Modell mit der besten Leistung wurde beibehalten, und wir fuhren erst dann mit der Entwicklung der Anwendung fort. Die Entwicklung folgte wieder einem Scrum-Ansatz.
Fazit
Ich möchte zwei wichtige Erkenntnisse in Bezug auf den Testprozess für eine eingebettete ML-Anwendungen herausstreichen:
- Wir folgen dem normalen Testprozess innerhalb der verschiedenen Schritte des SDLC, ggf. mit kleinen Abweichungen, je nachdem, wie Daten- und Modellphase kombiniert werden.
- Wir setzen Meilensteine an relevanten Stellen innerhalb der Entwicklung und betrachten diese als Prototypen. Diese Prototypen können dann gesondert getestet und gründlich geprüft werden, um somit eine belastbare Risikobewertung zu erhalten.
Wir Qualitätsverantwortlichen werden uns künftig sehr intensiv mit KI und ML auseinandersetzen müssen, um maßgeblich dazu beizutragen, in der neuen, intelligenten Welt einen Schritt voraus zu sein.
Weitere Informationen
[BuoGe18] J. Buolamwini, T. Gebru, Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification, in: Proc. of Machine Learning Research, 81:1–15, 2018, siehe:
https://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf
[McK18] McKinsey Global Institute, Notes from the AI frontier: Modeling the impact of AI on the world economy, September, 2018, siehe:
https://www.mckinsey.com/featured-insights/artificial-intelligence/notes-from-the-ai-frontier-modeling-the-impact-of-ai-on-the-world-economy









