

Die zu lösenden Aufgaben haben sich aber trotz aller Neuerungen seit der klassischen Data-Warehouse-Definition von Inmon nicht wirklich verändert: Die Daten sollten nicht einfach 1:1 von den operativen Systemen kopiert, sondern integriert und thematisch zusammengefasst werden. Der Datenbestand sollte stabil, Veränderungen über die Zeit sollten nachvollziehbar sein. Da liegt es nahe, bei der Verwirklichung neuer Architekturansätze weiterhin auf eine Modellierungstechnik zurückzugreifen, die schon so oft gezeigt hat, dass sie das alles kann: Data Vault.
So zahlreich und auf den ersten Blick durchaus unterschiedlich die neuen Architekturansätze im Bereich Datenmanagement und Analytics sind, eines haben sie eigentlich alle gemeinsam: die entscheidende Veränderungsachse ist Zentralisierung/Dezentralisierung. Das gilt für den organisatorischen Bereich ebenso wie für die technische Infrastruktur.
Neue Aufgaben für Quellen und Nutzer
Im organisatorischen Bereich geht der Trend dabei klar in Richtung Dezentralisierung. War bisher meist ein zentrales Datenteam (siehe Abbildung 1) der Hort der Datenkompetenz im Unternehmen (oder hielt sich zumindest dafür), daher für alle Datenthemen zuständig und dadurch meistens überlastet, soll es bei neuen Ansätzen in der Regel Aufgaben abgeben.
Werden Data Contracts mit Quellsystemen oder externen Datenlieferanten geschlossen, übergibt das Datenteam einen Teil seiner Aufgaben an die Datenquellen. Sie haben nun sicherzustellen, dass die Daten schnell, sauber und in der vereinbarten Struktur zur Verfügung stehen. Das Datenteam muss sich nun weniger Gedanken über den EL-Teil des ELT-Prozesses (Extract, Load, Transform) machen und vor allem seltener Feuerwehr spielen, wenn sich mal wieder eine Spalte im Quellsystem geändert hat.
Das Datenteam kann auch Aufgaben an die Datennutzer abgeben. Im Bereich der BI-Tools und der Datenvisualisierung passiert das schon länger (Stichwort Self-Service-BI), neuer ist die Entwicklung, auch den T-Teil des ELT-Prozesses zu delegieren. In diesem Bereich ist heute häufig Analytics Engineering angesagt, die Entwicklung von Datentransformationen durch Datenanalysten oder in die Fachteams gewechselte oder dorthin abgestellte (ehemalige) Datenteam-Mitglieder.
Oft gibt es auch hybride Ansätze, gerade in größeren Unternehmen. Mit manchen Datenquellen konnten Data Contracts geschlossen werden, bei vielen – gerade aus dem Software-as-a-Service-Bereich (SaaS) und generell bei zugekaufter Software – ging es aber auch nicht. Manche Fachbereiche (zum Beispiel Finance oder Marketing) haben bezüglich Datenkompetenz aufgerüstet, andere verlassen sich weiterhin auf das zentrale Datenteam. Und oft gibt es auch nicht mehr das eine Datenteam, sondern mehrere (siehe Abbildung 2), die jeweils für bestimmte Fachteams oder Anwendungsfälle zuständig sind.
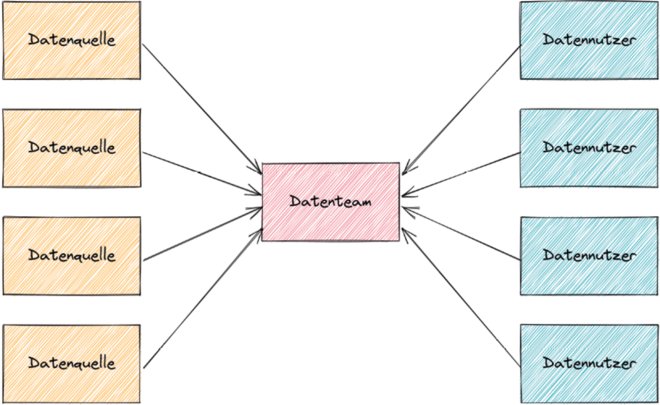
Abb. 1: Ganz klassisch: ein zentrales Datenteam
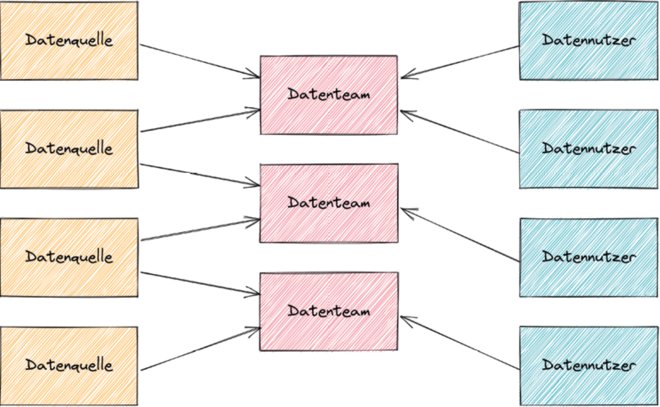
Abb. 2: Hybrid: mehrere Datenteams, die jeweils für bestimmte Datennutzer zuständig sind
Dezentralisierung extrem
Und schließlich gibt es auch radikal dezentrale Ansätze, bei denen vom zentralen Datenteam wenig bis nichts übrig bleibt. Momentan ist insbesondere Data Mesh in der Diskussion, ein Paradigma, bei dem die Verantwortung für analytische Daten komplett an sogenannte Domänenteams übergeht (siehe Abbildung 3) [Deh22; Bit22]. Diese Teams sind jeweils für ein bestimmtes Thema zuständig und ähneln je nach Verantwortungsbereich eher den bisherigen Betriebsteams für operative IT-Systeme oder den bisherigen Fachbereichen, jedoch jeweils mit Datenexperten als Teil des Teams.
Jedes Domänenteam ist bei diesem Ansatz für alle für seinen Bereich einschlägigen Data Products zuständig. Diese kapseln Rohdaten, Metadaten und die nötige Transformationslogik und stellen so den anderen Teams qualitativ hochwertige, ordentlich dokumentierte, sauber historisierte und gegebenenfalls auf unterschiedliche Arten (etwa per SQL oder mittels einer API) abfragbare Daten zu einem bestimmten Aspekt der Unternehmenstätigkeit zur Verfügung. Durch diese Kapselung und den Produktgedanken sollen komplexe Transformations-Pipelines der Vergangenheit angehören.
Vom klassischen Datenteam bleiben bei einem Data Mesh noch ein föderiertes Governance-Team und ein Plattform-Team übrig, das für den technischen Unterbau zuständig ist. Das Datenteam ist also nun nicht mehr der Flaschenhals, den alle Datenthemen passieren müssen. Allerdings steigt dadurch natürlich auch das Risiko, dass die verschiedenen Datenprodukte sehr unterschiedlich implementiert werden und nicht ausreichend interoperabel sind.
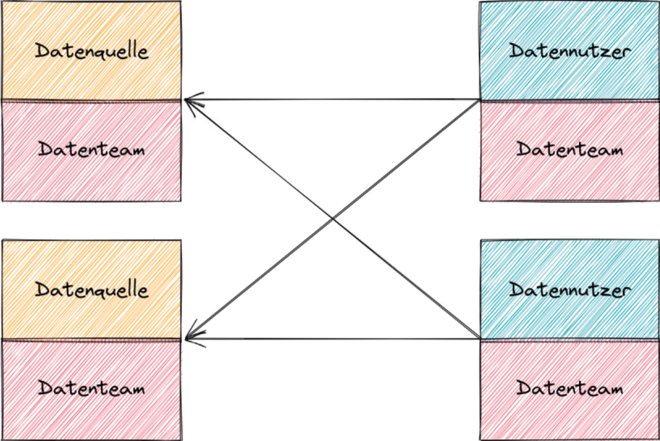
Abb. 3: Maximal dezentral: Data Mesh
Technik zwischen Zentralisierung und Dezentralisierung
Bei der Technik gibt es sowohl Trends in Richtung Zentralisierung als auch in Richtung Dezentralisierung. Die Cloud ist der große Zentralisierer: Während vorher jedes größere Unternehmen mindestens ein Rechenzentrum hatte, läuft heute mehr und mehr in der Cloud bei einem der großen Hyperscaler.
Im BI-Bereich hat uns diese Entwicklung gleich mehrere neue Schlagwörter beschert: Cloud Data Warehouse, Data Cloud, Data Lakehouse. Der Übergang zwischen Architekturansatz und Marketingbegriff ist dabei oft fließend, meist steht vor allem ein Anbieter hinter einem bestimmten Schlagwort.
Gleichzeitig gibt es auch Trends, die in die andere Richtung gehen. Viele Unternehmen gehen weg von der einen Universaldatenbank hin zu mehreren spezialisierten Datenbanken für unterschiedliche Anwendungsfälle. Neben auf analytische Anwendungen spezialisierten Cloud-Datenbanken, die mittlerweile oft irreführend ebenfalls als Data Warehouses bezeichnet werden, sind das etwa dokumentenbasierte, Key-Value- oder Wide-Column-Datenbanken.
Zudem hat sich unter dem Schlagwort Modern Data Stack eine kambrische Explosion in der Tool-Landschaft ereignet. Unbundling heißt die Prämisse – ähnlich wie im Hadoop-Umfeld ein Jahrzehnt zuvor gibt es für nahezu jede Aufgabe gleich mehrere Speziallösungen, die allerdings nun in der Regel als SaaS-Tools daherkommen und nicht mehr selbst gehostet werden müssen. Die Vielzahl der Anwendungen zur Zusammenarbeit zu überreden ist aber noch ähnlich schwierig wie zu Zeiten von Hadoop.
Und schließlich hat die Datenvirtualisierung eine weitere Häutung durchgemacht und wird nun von Gartner-Analysten und auch einigen Herstellern als Data Fabric vermarktet [Gar21]. Kernpunkt ist weiterhin eine zentrale Zugriffsschicht auf dezentral gespeicherte Daten, denen vermeidbares Herumkopieren zwischen verschiedenen Systemen erspart bleiben soll.
Was gleich bleibt
Bei all dieser Vielzahl von Trends und Schlagworten, die oft, wenn auch nicht immer auf Dezentralisierung abzielen, stellt sich natürlich die Frage, was das für Data Warehousing und Business Intelligence in den 2020er-Jahren bedeutet. Ist das klassische Data Warehouse jetzt endgültig tot? Können oder müssen wir sogar alles über Bord werfen, was sich zum Teil über Jahrzehnte bewährt hat?
Dieser Artikel steht unter der Überschrift „Alles muss sich ändern – oder?“, somit gilt Betteridges Gesetz der Überschriften: „Jede Überschrift, die mit einem Fragezeichen endet, kann mit einem Nein beantwortet werden.“ Natürlich müssen (und sollten!) wir nicht alles über Bord werfen, was sich bisher bewährt hat. Vieles gilt nahezu unverändert weiter und ist vielleicht sogar noch wichtiger geworden.
Bill Inmon, einer der Gründerväter des Data Warehousing, hat in den 1990er-Jahren die klassische Data-Warehouse-Definition geliefert [Wik22]: „A data warehouse is a subject-oriented, integrated, time-variant, nonvolatile collection of data in support of management’s decision-making process. – Ein Data Warehouse ist eine themenorientierte, integrierte, chronologisierte und persistente Sammlung von Daten, um das Management bei seinen Entscheidungsprozessen zu unterstützen.“
Inmon-Kriterien bleiben relevant
Schauen wir uns die einzelnen Punkte der Definition, die oft auch als Inmon-Kriterien bezeichnet werden, einmal aus heutiger Sicht etwas genauer an.
Kriterium 1 – subject-oriented (themenorientiert): Unternehmen haben es heute mit einer Vielzahl von Quellsystemen und externen Datenlieferanten zu tun. Oft handelt es sich dabei um SaaS-Angebote, deren Datenhaltung sich wenig bis nicht beeinflussen lässt. Um hier den Überblick zu behalten, ist eine themenorientierte Sicht auf die verschiedenen Datenbestände unerlässlich.
Ob die technische Plattform für BI und Analytics dabei in der Cloud läuft oder wie früher im eigenen Rechenzentrum, spielt dabei keine Rolle. Auch ob diese Plattform sich auf Hadoop zurückführt (Data Lakehouse) oder bewusst davon abgrenzt (Data Cloud), ist hier nicht relevant. Und sollten Sie tatsächlich auf dem Weg zum Data Mesh sein, ist die angestrebte Domänenorientierung nur mit sehr viel Mühe von der althergebrachten Themenorientierung zu unterscheiden.
Ähnliches gilt für Kriterium 2 – integrated (integriert): Lässt man die Daten aus all diesen Quellen einfach im ursprünglichen Format nebeneinander existieren, wie es ursprünglich beim Data Lake vorgesehen war, werden Datennutzer wenig Freude haben. Auch hier spielt es keine Rolle, wo die technische Plattform liegt und ob sie sich in der Tradition von Hadoop sieht oder nicht.
Wenn Sie sich dem Analytics Engineering verschrieben haben, gibt es in Ihrem Unternehmen sogar eine eigene Berufsgruppe, die sich explizit der Datenintegration widmen möchte. Auch beim Data-Fabric-Ansatz ist Integration hilfreich, die integrierten Daten werden nur nicht zwangsläufig persistiert. Und selbst Data Mesh kennt sogenannte Aggregate Data Products, die auf mehreren anderen Datenprodukten beruhen.
Interessante Zeiten
Kriterium 3 – time-variant (chronologisiert): Veränderungen über die Zeit zu verfolgen ist in diesen schnelllebigen, zunehmend turbulenten Zeiten eher noch wichtiger geworden. Das gilt für Near-Realtime-Anwendungen, die schnelle, vielleicht sogar automatisierte Reaktionen erfordern, ebenso wie für tiefergehende Analysen, die sich über längere Zeiträume erstrecken.
Extremereignisse treten mittlerweile mit einer erschreckenden Regelmäßigkeit auf und werfen mittel- und langfristige Planungen immer wieder über den Haufen. Oft hinkt die Datenerfassung und -übertragung den Ereignissen hinterher – die Corona-Inzidenzen sind nur das prominenteste Beispiel.
Idealerweise werden die Daten also auf eine Weise abgelegt, die eine saubere Historisierung erlaubt, wenn möglich entlang zweier Zeitdimensionen (bitemporal), um Korrekturen und Nachlieferungen problemlos handhaben zu können, ohne Kriterium 4 zu verletzen [Ted19]. Beim Data-Mesh-Ansatz wird bitemporale Datenhaltung sogar als Standard für Data Products empfohlen.
Auch Kriterium 4, nonvolatile (persistent), bleibt unverzichtbar. Angesichts sich oft überschlagender Entwicklungen ist es heute wichtiger denn je, alte Datenstände nicht einfach zu überschreiben, sondern weiterhin verfügbar zu halten. In vielen Fällen verlangen regulatorische Anforderungen das ohnehin. Oft ist es aber auch für Data-Science- oder Machine-Learning-Anwendungen hilfreich.
Wenn Sie nicht wollen, dass Ihre Anwender sich jeden Tag die Daten nach Excel abziehen, um stabile Reports zu haben, ist Kriterium 4 in Kombination mit Kriterium 3 sogar von ganz entscheidender Bedeutung. Nur wenn das Data Warehouse (oder mit welchem Schlagwort Sie Ihre Datenplattform auch immer bezeichnen wollen) diese Kriterien erfüllt, können sich die Anwender sicher sein, dass sie für dieselben Parameter auch nächste Woche dieselben Daten ausgegeben bekommen wie heute.
Daten, überall Daten
Nur das ohnehin mittlerweile oft weggelassene Kriterium 5, in support of management’s decisionmaking process (um das Management bei seinen Entscheidungsprozessen zu unterstützen), passt definitiv nicht mehr in die Zeit. Daten sind heute ein essenzieller Teil fast aller Geschäftsprozesse. Mitarbeiter kommen um den Umgang mit Daten kaum noch herum und sind oft auf verlässliche, vollständige und aktuelle Daten für die Erfüllung ihrer Aufgaben sogar dringend angewiesen.
Datenproduzenten und Datennutzer sind somit über das gesamte Unternehmen verteilt. Insbesondere bei dezentralen Ansätzen wie Data Mesh, Data Contracts und (je nach organisatorischer Umsetzung) Analytics Engineering sind zahlreiche Teams ganz oder teilweise mit Datenmanagement und Datentransformation befasst. Kriterium 5 ist somit das einzige der klassischen Inmon-Kriterien, das heute nicht mehr wirklich relevant ist.
Was nun?
Im Umkehrschluss heißt das aber, dass vier der fünf Inmon-Kriterien heute mindestens genauso wichtig, wenn nicht wichtiger sind als in den 1990er-Jahren. Was bedeutet das für die praktische Umsetzung der in diesem Artikel diskutierten neuen Architekturansätze? Wie können wir sicherstellen, dass trotz all dieser Veränderungen die ersten vier Inmon-Kriterien weiterhin erfüllt werden können?
Die Antwort auf diese Fragen ist gar nicht so schwer zu finden. Bill Inmon selbst hat Data Vault schon 2007 ausdrücklich als die perfekte Wahl für die Modellierung des Enterprise Data Warehouse bezeichnet. Ein Enterprise Data Warehouse ist natürlich ein System, das die Inmon-Kriterien erfüllt.
Es ist daher eigentlich nicht überraschend, dass Data Vault auch für neue und modernisierte Systeme, die weiterhin diese Kriterien erfüllen sollen, eine gute Wahl ist.
Selbst mit stark dezentralisierten Ansätzen kommt Data Vault hervorragend zurecht [Dat22; Wer22]. Da Beziehungen zwischen Geschäftskonzepten in eigene Link-Tabellen ausgelagert werden, ist es kein Problem, wenn jedes Geschäftskonzept von einem anderen Team betreut wird. Da die Attribute zu einem Geschäftskonzept auf mehrere Satelliten aufgeteilt werden können, ist es sogar möglich, dass mehrere Teams Aspekte desselben Geschäftskonzepts bearbeiten (siehe Abbildung 4). Wenn Sie also neuartige Datenarchitektur-Ansätze ausprobieren wollen und trotzdem Ihre Daten auf eine bewährte Art und Weise strukturieren wollen, mit der viele Datenexperten bereits Erfahrung haben, ist Data Vault weiterhin die erste Wahl.
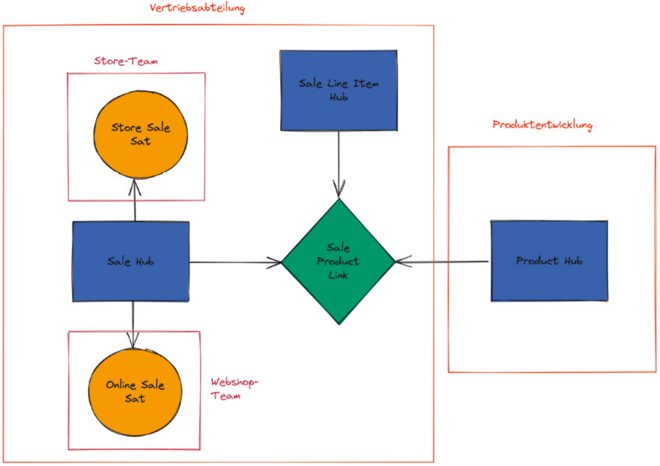
Abb. 4: Dezentral: Unterschiedliche Teams sind jeweils für Teile des Data- Vault-Modells zuständig
Weitere Informationen
[Bit22]
Bitkom: Leitfaden Data Mesh – Datenpotenziale finden und nutzen.
https://www.bitkom.org/Bitkom/Publikationen/Data-Mesh-Datenpotenziale-finden-und-nutzen, abgerufen am 1.9.2022
[Dat22]
Datavault Builder: Should I still do Data Vault if there is Data Mesh? 16.6.2022,
https://datavault-builder.com/2022/06/16/data-vault-vs-data-mesh/, abgerufen am 1.9.2022
[Deh22]
Dehghani, Z.: Data Mesh. Delivering Data-Driven Value at Scale. O’Reilly 2022
[Gar21]
Gartner: Data Fabric ist der Schlüssel zur Modernisierung von Datenmanagement und -integration. 11.5.2021,
https://www.gartner.de/de/artikel/data-fabric-architecture-zur-modernisierung-von-datenmanagement-und-integration, abgerufen am 1.9.2022
[Ted19]
Tedamoh: Bitempora Affront. 21.10.2019,
https://tedamoh.com/de/blog/69-bitemporal-data/118-bitemporal-affront, abgerufen am 1.9.2022
[Wer22]
Werschkull, R.: Data Product Thinking – Will ‘the Data Mesh’ save us from analytics history? 1.6.2022,
https://www.slideshare.net/RogierWerschkull/data-product-thinkingwill-the-data-mesh-save-us-from-analytics-history, abgerufen am 1.9.2022
[Wik22]
Wikipedia: Data Warehouse.
https://de.wikipedia.org/wiki/Data_Warehouse#Begriff, abgerufen am 1.9.2022









