

Momentan vergeht kaum ein Tag, an dem wir nichts von KI hören, entweder euphorisch fasziniert oder warnend vor einem unbeherrschbaren Gegner. Doch Tatsache ist, KI-basierte Algorithmen werden in vielen Bereichen unseres Lebens bereits eingesetzt. Wie aber bewertet man die Qualität einer KI, wenn manchmal Entwickler selbst deren Verhalten nicht mehr nachvollziehen können?
In der klassischen Softwareentwicklung haben sich Konzepte zur Qualitätssicherung von anfänglich sporadischem Ausprobieren zu stark methodisch geprägten hocheffektiven Testprozessen weiterentwickelt.
Wenn es hingegen um KI-Systeme geht, steht man scheinbar wieder am Anfang einer solchen Entwicklung. Viele Konzepte, die der klassische Test liefert, greifen nicht mehr, wie Anforderungen prüfbar und vollständig zu beschreiben. Um dieser Problematik zu begegnen, haben die Autoren im Rahmen eines Innovationsprojekts verschiedene KI-basierte Systeme untersucht und ausprobiert, wie unterschiedliche Anwendungen zur Qualitätssicherung angewendet werden können.
Learning by doing – ein Erfahrungsbericht
Anhand eines Beispielprojekts wollten wir Erfahrungen sammeln und aus Fehlern lernen, um herauszufinden, worauf es beim Testen einer KI ankommt. Und tatsächlich haben wir ein Kundenprojekt mit Bilderkennung gefunden, das sich augenscheinlich gut als KI-Anwendung eignet.
Unsere KI sollte auf einem Display zur Steuerung von Heizungsanlagen (ähnlich wie in Abbildung 1) zunächst nur die Temperatur erkennen und zusätzliche Symbole vernachlässigen. Durch den bisherigen Verlauf des Projekts waren bereits ca. 10 000 Bilder des Displays vorhanden – dem Anschein nach genug.

Abb. 1: Display einer Steuerung von Heizungsanlagen als Beispiel
Zu einem KI-Projekt gehört natürlich auch die passende Hardware. Wir haben uns für einen klassischen PC mit zwei CUDA-Karten (Compute Unified Device Architecture) von NVIDIA entschieden, die sich besonders gut für neuronale Netze eignen [Che12]. Außerdem verwendeten wir das für die datenstromorientierte Programmierung bekannte Framework TensorFlow und die Open-Source-Deep-Learning-Bibliothek Keras.
Nun konnte es losgehen und wir programmierten unser „erstes“ neuronales Netz. Die Daten haben wir, so wie häufig in der Literatur empfohlen, in 50 Prozent Lern-, 25 Prozent Test- und in weitere 25 Prozent Validierungsdaten aufgeteilt.
Obwohl wir auf ca. 10 000 Bilder zugreifen konnten, haben wir sehr schnell festgestellt, dass davon nur ungefähr 1000 für unser Vorhaben geeignet waren. Die anderen waren entweder schlecht aufgenommen oder redundant in der enthaltenen Information. 1000 Bilder waren allerdings nicht genug, um erste Lernergebnisse zu erhalten.
Um die Menge der Lerndaten zu vergrößern, nutzten wir Augmentation-Funktionen von TensorFlow, die der Bildmanipulation dienen.
Damit konnten wir unseren Datensatz künstlich erweitern. Auch wenn sich dieses Vorgehen für uns Tester zunächst nicht richtig anfühlte, konnten wir damit den Lernfortschritt merklich verbessern.
Erste Erkenntnis: Nicht nur die Menge, sondern vor allem die Qualität von Lern- und Testdaten spielt eine entscheidende Rolle. Bei der Qualitätssicherung einer KI müssen wir als Tester unsere gewohnten Umgebungen und Verhaltensweisen aufgeben und uns gegenüber neuen Methoden und Tools offen zeigen.
Trotz der durch Augmentation zusätzlich generierten Trainingsdaten erhielten wir zunächst nur eine Genauigkeit bei der Ziffernerkennung von gut 30 Prozent. Mithilfe eines Tools konnten wir die von der KI gelernten Merkmale im Bild hervorheben und hatten anschließend ein echtes Aha-Erlebnis: Unsere KI hatte den Timestamp des Bildes gelernt (vgl. Abbildung 2) und nicht die angezeigte Temperatur. Einen ähnlichen Fall kann man auch bei heise nachlesen [Fis18].

Abb. 2: Das neuronale Netz lernt fälschlicherweise den Timestamp statt der Temperaturanzeige aufgrund einer ungünstigen Korrelation
Die KI bewertet die Relevanz von Merkmalen allein anhand statistischer Korrelation mit den vorliegenden Daten. Aus einer Korrelation folgt jedoch nicht notwendigerweise eine Relevanz! Doch selbst wenn die Korrelationen relevant sind, heißt dies noch lange nicht, dass daraus abgeleitete Entscheidungen wirksam sind: Ob ein kausaler Zusammenhang besteht, kann eine rein statistische Betrachtung nicht erklären.
Zweite Erkenntnis: Wir als Qualitätssicherer müssen die Lerndaten und das Gelernte hinterfragen, auf Korrelationen zwischen Merkmalen innerhalb des Datensatzes achten, denn eine KI lernt nicht immer das, was wir Menschen als „sinnvoll“ erachten würden. Hier helfen Tools zur Visualisierung.
So mussten wir auch erkennen, dass unsere KI durch die vorliegenden Daten im Lernerfolg beschränkt wurde. Ein „Outsideof-the-Box“-Denken ist einem KI-Algorithmus nicht möglich, jedenfalls so lange wir es mit schwachen KIs zu tun haben [Uni-o]. Daher mussten die Lerndaten so aufbereitet werden, dass der Algorithmus nicht unnötig abgelenkt wird. Dazu gehört die zum Problem passende Aufbereitung der Lerndaten, zum Beispiel die Auswahl eines Bildausschnittes oder einer Bildrotation/-transformation.
Dritte Erkenntnis: Wir als Qualitätssicherer müssen die Art der von einem KI-Modell verarbeiteten Daten hinterfragen. Die gezielte Vorverarbeitung von Lerndaten kann helfen, die Effizienz einer KI zu erhöhen.
Der Werkzeugkasten des maschinellen Lernens stellt natürlich nicht nur neuronale Netze zur Verfügung, sondern eine Vielzahl verschiedener Algorithmen – jeder mit seinen Stärken und Schwächen. Beispielsweise ist ein neuronales Netz richtig gut in der Abstraktion: Katzen identifizieren, Muster wiedererkennen. Um die Qualität eines KI-Systems zu bewerten, muss nicht nur die Wahl des Modells hinterfragt werden, sondern auch dessen Komplexität. Der Verwendung eines Algorithmus muss ein umfassendes Verständnis des eigentlich zu lösenden Problems vorausgehen.
Im Allgemeinen gilt, dass ein komplexer Algorithmus mit zu vielen Parametern die Gefahr birgt, dass überflüssige oder gar falsche
Details gelernt werden. Dieser Sachverhalt kann einen unzuverlässigen Algorithmus zur Folge haben, dessen Schwächen erst nach einiger Zeit im Feldtest ans Licht kommen. Daher gilt die Regel, Algorithmen nicht unnötig komplex zu wählen [Kir17].
Dies kann sogar so weit gehen, dass man gegebenenfalls von einem selbstlernenden Algorithmus Abstand nehmen sollte, um ein zuverlässigeres System entwickeln zu können. Trotz der Stärken einer KI sollten wir nicht die Vorteile der klassischen Softwareentwicklung vergessen: Der Entwickler hat einen direkten Einfluss auf die Vorgänge in der Software. Diese Tatsache macht die Entscheidungsfindung nachvollziehbar und für den Menschen vertrauenswürdiger.
Vierte Erkenntnis: Wir als Tester dürfen die eigentliche Problemstellung nicht aus den Augen verlieren und müssen den Algorithmus verstehen und hinterfragen. KI-Modelle können als Lösungsansatz fehleranfälliger und unzuverlässiger sein als „herkömmliche“ deterministische Ansätze.
Bewertung, aber mit Verstand!
Ziel eines weiteren Beispielprojekts war es, anhand eines einfachen Strategiespiels eine KI zur Entscheidungsfindung zu untersuchen: Wie lernt ein solcher Algorithmus eine erfolgreiche Strategie, und wie schnell kann er diese an seine Umgebung anpassen?
Wir haben hierfür das einfache Strategiespiel Frozen Lake aus dem gym-Tooltik [Opena]
herangezogen: Auf dem 8x8 Felder großen Spielfeld steht in einer Ecke eine Figur. Um das Spiel zu gewinnen, muss auf die gegenüberliegende Ecke (ins Ziel) gezogen werden, ohne dabei in eines der versteckten Löcher zu fallen. Ansonsten ist das Spiel verloren.
Als Trainingsmethode für die KI haben wir uns für das Reinforcement Learning entschieden, das abhängig von Gewinn oder Verlust des Spiels die Entscheidungslogik des sogenannten Agenten anpasst, sodass die Entscheidungen, die einen Gewinn zur Folge hatten, bevorzugt und diejenigen, die zum Spielverlust führten, eher gemieden werden.
Das über das Spielfeld erlernte Wissen wird in Form von Gewinnwahrscheinlichkeiten zu jedem einzelnen Spielfeld abgelegt. Das Dilemma dabei ist: Eine optimale Strategie wird ihre Entscheidungen aus diesen Gewinnwahrscheinlichkeiten ableiten, selbst aber nur die Wege ins Ziel aufsuchen. Auf
diese Art würde man nur wenig über das Spielfeld als Ganzes erfahren.
Bedachte vs. voreilige KI
Das Training des Agenten bekommt damit zwei Strategiekonzepte: eine erkundende Strategie (Exploration), die möglichst viel der Umgebung erkundet und so Wissen um die Gewinnwahrscheinlichkeiten sammelt, und eine nutzende Strategie (Exploitation), die mit dem aufgebauten Wissen über die Gewinnwahrscheinlichkeiten zielstrebig das Spiel gewinnen will. Die Gewichtung dieser beiden Strategien haben wir über sogenannte Hyperparameter während des Trainings vermittelt.
Je stärker die Gewichtung auf der Erkundung lag, desto besser lernte der Agent seine Umgebung kennen, brauchte aber länger, um eine robuste Gewinnstrategie abzuleiten. Übernahm der Agent schneller die ersten Wahrscheinlichkeiten in eine Gewinnstrategie, lernte er schneller zu gewinnen. Hatten wir den Agenten aber zu sehr dazu angetrieben, aus den ersten explorativen Erfahrungen für eine Strategie zu ziehen, war das Ergebnis völlig unbrauchbar – der Agent hatte voreilig falsche Schlüsse gezogen und kam gar nicht mehr am Ziel an.
Besonders lehrreich war für uns zu erkennen, dass der Einblick in die innersten Lern-Zustände (z. B. die Gewinnwahrscheinlichkeiten) nicht getrennt werden kann von dem zu erreichenden Ziel, entweder einen behutsamen, aber präzisen Agenten zu trainieren oder einen, der sich schnell Situationen anpassen kann – gegebenenfalls mit reduzierter Erfolgsrate.
Fünfte Erkenntnis: Wir als Qualitätssicherer müssen in die KI hineinsehen. Wir müssen uns mit der Mathematik der Algorithmen beschäftigen und die ableitbaren Metriken verstehen. Wir müssen daher Wissen in neuen Themenfeldern wie Statistik, selbstlernenden Algorithmen und Datenqualität aufbauen und den intensiven Austausch mit ausgewiesenen Experten auf den Gebieten pflegen.
Fazit
Die Erkenntnis, Qualität schon zu Beginn von Entwicklungsprojekten zu bedenken, ist nicht neu. Doch verschiebt sich der Fokus der zu betrachtenden Aspekte sowohl thematisch wie technisch oft auf eine höhere Ebene. Aus unseren Erfahrungen haben wir die folgenden Ansatzpunkte in einem Entwicklungsprozess für KI-Systeme abgeleitet (vgl. Abbildung 3).
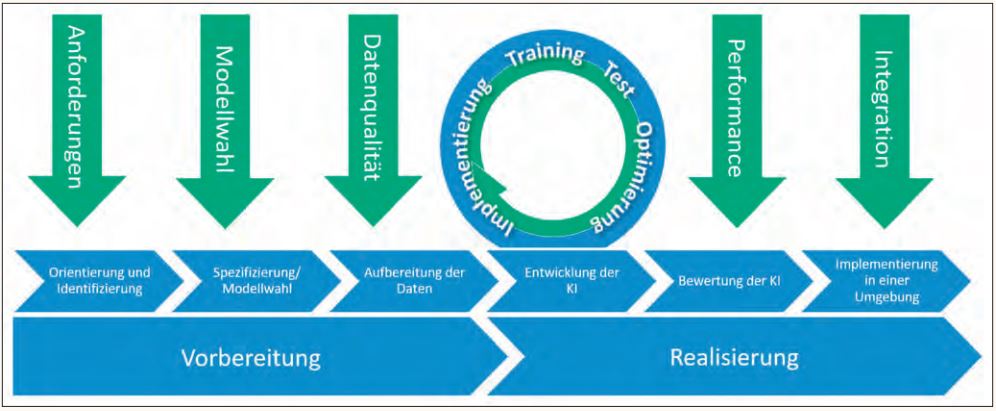
Abb. 3: Testaspekte im Entwicklungsprozess einer KI
Anforderungen: Ergebnis der Orientierungsund Identifizierungsphase sind hochwertige Anforderungen für messbare Eigenschaften. Die Grundlage dafür ist ein sicherer Umgang mit dem neuen Vokabular wie „Precision“ und „Recall“ sowie Verständnis für Begriffe, wie „Testdaten“, „Trainingsdaten“ und „Validierungsdaten“. Je weniger Einfluss der Entwickler auf die Fähigkeiten der Software am Ende hat, desto wichtiger ist es, früh die Ziele und Anforderungen zu definieren.
Modellwahl: Die Modellwahl stellt den Rahmen der KI dar. Eine KI mit einem Modell, das nicht zur Problemstellung passt, wird nie befriedigende Ergebnisse liefern. Ein Neuronales Netz ist nicht immer die richtige Wahl. Wurde ein passendes Modell bestimmt, muss zur Qualitätssicherung auch dessen Komplexität beziehungsweise die Anzahl der Parameter hinterfragt werden (siehe 4. Erkenntnis).
Datenqualität: Eine KI kann immer nur so gut sein, wie die Daten, die zur Verfügung gestellt werden. Korrelationen, Relevanz und Redundanz innerhalb von einem Datensatz beeinflussen die Lernqualität stark, wie auch die Abdeckung verschiedener Szenarien innerhalb der Lerndaten. Ein selbstfahrendes Auto wird einen Rollstuhlfahrer nicht als Mensch erkennen, wenn der Algorithmus nicht darauf trainiert ist. Eine kritische Qualitätsbewertung der Trainings- und Testdaten ist unumgänglich (siehe 2. und 3. Erkenntnis).
Trainingsfortschritt: Innerhalb der Trainingszyklen spielt der Test mit den Testdaten eine entscheidende Rolle, um die Leistung der KI zu bewerten und Schwächen zu identifizieren (etwa beim Over- oder Underfitting). In einem anschließenden Schritt kann das System optimiert werden, indem Hyperparameter angepasst werden oder die Menge der Trainingsdaten vergrößert wird. Als Tester müssen wir die verwendeten Metriken und deren Interpretation beherrschen. Zum Beispiel ist eine Vorhersagegenauigkeit von 92 Prozent völlig unzureichend, wenn über 90 Prozent der Testdaten zur vorhergesagten Kategorie gehören (siehe 5. Erkenntnis).
Performanz und Integration: Klassisches Test-Know-how bleibt gefragt: Bei Performanzoder Integrationstests spielt das System, in das eine KI eingebettet ist, eine fundamentale Rolle. Belastbarkeit, Schnittstellen und die Usability sind nur wenige Kriterien, die hier beleuchtet werden müssen. Bei kontinuierlich lernenden Algorithmen kommen weitere Aspekte dazu, wie Zuverlässigkeit und Erinnerungsvermögen der KI.
Auch wenn das Flussdiagramm in Abbildung 3 den Anschein erwecken mag, dass es sich hier um ein sequenzielles Vorgehen handelt, werden vor allem während des Trainings immer wieder davorliegende Schritte angepasst, um zum Beispiel die Datenqualität zu verbessern oder die Modellwahl anzupassen. Aber auch hier gilt, je später Fehler erkannt werden, desto aufwendiger ist es, die Änderungen umzusetzen.
Wie man sieht, geht es letztlich weniger um Tests im klassischen Sinne, sondern viel mehr um Qualitätssicherung, und zwar von Anfang an.
Referenzen
[Che12] D. S. Chevitarese, D. Szwarcman, M. Vellasco, Speeding Up the Training of Neural Networks with CUDA Technology, in: L. Rutkowski et al. (eds), Artificial Intelligence and Soft Computing. ICAISC 2012. LNCS, vol 7267. Springer, Berlin, Heidelberg., s. a. https://link.springer.com/chapter/10.1007/978-3-642-29347-4_4
[Fis18] M. Fischer, Künstliche Intelligenz als Gefahr: Menschheit muss sich auf Regeln einigen, heise-online News, 06/2018, siehe: https://www.heise.de/newsticker/meldung/Kuenstliche-Intelligenz-als-Gefahr-Menschheit-muss-sich-auf-Regeln-einigen-4077950.html
[Kir17] M. Kirk, Thoughtful Machine Learning with Python: A Test-driven Approach, O‘Reilly Media, 2017
[Opena] Homepage der “gym”-Bibliothek der OpenAI Forschungseinrichtung, siehe: https://gym.openai.com/
[Uni-o] Aus der Website des Teams „Informatik und Gesellschaft“ der Universität Oldenburg, siehe: http://www.informatik.uni-oldenburg.de/~iug08/ki/Grundlagen_Starke_KI_vs._Schwache_KI.html









