

Wer regelmäßig JavaSPEKTRUM liest, weiß, dass ich in meinen Artikeln gerne die eher unbekannten Seiten der Java SE beleuchte. Allerdings ist im Vorfeld noch keines jener „speziellen“ Themen so sehr ins Auge gesprungen wie das hier vorliegende. Das ist wohl den automatischen Code-Vervollständigungen moderner Java-IDEs zu verdanken, die bei Collections, Iteratoren und Streams immer wieder eine spliterator()-Methode aufblitzen lassen. Höchste Zeit also, diesen ominösen Spliteratoren einmal auf den Grund zu gehen.
Gleich vorneweg: Spliteratoren spielen – wie der Name bereits vermuten lässt – ihre wahren Vorteile natürlich erst in der parallelen Programmierung aus. Durch eigene Spliteratoren lässt sich vorgeben, wie genau eine Datenquelle bei einer Aufspaltung (engl. fork) sich selbst in zwei Teile zerlegt. Je nach Beschaffenheit der Daten mag eine rein hälftige Aufteilung nämlich nicht immer die effizienteste Lösung sein. Spliteratoren bieten aber auch Vorteile, wenn es nicht um parallele Programmierung geht. Fangen wir also zuerst mit den seriellen Aspekten an.
Spliteratoren erhalten
Die Methode spliterator() ist eine von lediglich drei Methoden des Interface Iterable<T> [JAPIIterable]. Damit bietet jede Datenstruktur, die mit einer for-each-Schleife durchlaufen werden kann, auch einen Spliterator an, namentlich alle Subtypen von Collection oder auch Path. Mit anderen Worten: Hat eine Datenstruktur iterator(), dann hat sie auch spliterator() (und forEach(…)).
Des Weiteren verfügt jeder Stream über eine terminale Operation spliterator(), genauso wie iterator() [JAPIBaseStream]. Im Gegensatz zu den Iteratoren enthalten die Spliteratoren aber zusätzliche Informationen (sogenannte Charakteristiken) ihrer zugrunde liegenden Datenquellen, wie wir gleich noch sehen werden.
Damit bei Arrays nicht extra der Umweg über Streams gegangen werden muss, bieten sowohl die Utility-Klasse Arrays als auch die Utility-Klasse Spliterators (beide mit ‚s‘ am Schluss) Möglichkeiten, Spliteratoren direkt aus Arrays zu erzeugen [JAPIArrays, JAPISpliterators]. Letztere erlaubt auch das Erzeugen von Spliteratoren aus Iteratoren heraus und umgekehrt.
Spliteratoren seriell anwenden
Listing 1 zeigt in der seriellen Anwendung den grundlegenden Unterschied zwischen Iteratoren und Spliteratoren. Eine Liste bestehend aus den Buchstaben "A" bis "F" soll traversiert und dabei nur jeder zweite Buchstabe auf der Konsole ausgegeben werden, also nur "A", "C" und "F". Eine for-each-Schleife könnte diese Arbeit ohne externe Logik nicht bewerkstelligen, weswegen das klassische Paar von hasNext() und next() zum Einsatz kommt. Wer wie ich mit ganz alten Java-Versionen groß geworden ist, weiß, dass dies bis und mit Java 1.4 die einzige Möglichkeit war, Collections zu iterieren (noch dazu ganz ohne Generics).
Ein Spliterator hingegen bietet kein solches Methodenpaar an, stattdessen im seriellen Kontext nur noch die einzelne Methode tryAdvance(Consumer). Wie der Name bereits impliziert, handelt es sich dabei um eine Compound-Methode, die sowohl das Überprüfen auf einen Nachfolger als auch dessen Verwendung gleich in einem Schritt vereint. Offensichtlich und komfortabel ist, dass diesem tryAdvance(…) ein Consumer mitgegeben wird, der dann jeweils direkt auf jenem Element angewendet wird. Gab es ein solches Element, dann retourniert tryAdvance(…) true, andernfalls false. Sinngemäß lässt sich Spliterator#tryAdvance(Consumer) also wie ein schrittweises Iterable#forEach(Consumer) verstehen und anwenden.
List<String> list = List.of("A", "B", "C", "D", "E", "F");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
if (iterator.hasNext()) {
iterator.next(); // Skip every 2nd element
}
}
Spliterator<String> spliterator = list.spliterator();
do {
spliterator.tryAdvance(System.out::println);
} while (spliterator.tryAdvance(s -> {})); // Skip every 2nd elementCharakteristiken auslesen
Jeder Spliterator erlaubt das Abfragen des Vorhandenseins acht verschiedener sogenannter Charakteristiken (engl. characteristics). Diese geben Eigenschaften der ihnen zugrunde liegenden Datenquellen an. Obwohl es Spliteratoren erst seit Java 8 gibt, wurden diese sinngemäß Booleschen Eigenschaften aus mir unerklärlichen Gründen aber nicht als Enums in einer EnumSet, sondern mithilfe von „Bit Flags“ realisiert. Letztere sollten in Java eigentlich schon seit über 17 Jahren (dem Zeitpunkt der Einführung von Enums mit Java 5) der Vergangenheit angehören [Blo36].
Listing 2 zeigt das Abfragen der Charakteristiken beispielhaft an einer unveränderbaren (engl. immutable) Liste, einer unsortierten sowie einer sortierten Menge (Set) und an einem parallelisierten, sortierten Stream mit eindeutigen (engl. distinct) Elementen.
Tabelle 1 enthält eine Kurzbeschreibung der jeweiligen Charakteristiken sowie die entsprechenden Werte aus list/set/sortedSet/stream.spliterator() des Demoprogramms aus Listing 2.
Der Großteil der aufgeführten Charakteristiken sollte selbsterklärend und einleuchtend sein. Dennoch enthalten sie ein paar Überraschungen oder in meinen Augen sogar Fehler. So ist mir bis heute kein Standard-Spliterator respektive keine zugrunde liegende
Datenstruktur begegnet, die eine der Charakteristiken NONNULL, IMMUTABLE oder CONCURRENT besitzt. Da die meisten Collections keine null-Einträge erlauben, müsste die entsprechende Charakteristik NONNULL in den Beispielen eigentlich true sein. Obwohl mit der Factory-Methode List.of(…), die seit Java 9 zur Verfügung steht, ganz klar eine Immutable Collection erstellt wurde, dringt die entsprechende Eigenschaft IMMUTABLE nicht bis zum Spliterator durch. Dass CONCURRENT nicht bedeutet, dass der zugrunde l iegende Stream parallel ist, leuchtet ein und war auch nie beabsichtigt. Dass aber selbst threadsichere Collections wie CopyOnWriteArrayList und ConcurrentSkipListSet diese Charakteristik nicht auf true bringen, überrascht doch sehr.
private void spliteratorCharacteristics() {
List<String> list = List.of("A", "B", "C", "D", "E", "F");
printCharacteristics("list", list.spliterator());
Set<String> set = new HashSet<>(list);
printCharacteristics("set", set.spliterator());
SortedSet<String> sortedSet = new TreeSet<>(list);
printCharacteristics("sortedSet", sortedSet.spliterator());
Stream<Integer> stream = Stream.of(1, 1, 2, 3, 5, 8, 13, 21)
.parallel().sorted().distinct();
printCharacteristics("spliterator", stream.spliterator());
}
private void printCharacteristics(
String sourceName, Spliterator<?> spliterator) {
System.out.println(sourceName);
System.out.format(" NONNULL: %b%n",
spliterator.hasCharacteristics(Spliterator.NONNULL));
System.out.format(" IMMUTABLE: %b%n",
spliterator.hasCharacteristics(Spliterator.IMMUTABLE));
System.out.format(" SIZED: %b%n",
spliterator.hasCharacteristics(Spliterator.SIZED));
System.out.format(" SUBSIZED: %b%n",
spliterator.hasCharacteristics(Spliterator.SUBSIZED));
System.out.format(" ORDERED: %b%n",
spliterator.hasCharacteristics(Spliterator.ORDERED));
System.out.format(" SORTED: %b%n",
spliterator.hasCharacteristics(Spliterator.SORTED));
System.out.format(" DISTINCT: %b%n",
spliterator.hasCharacteristics(Spliterator.DISTINCT));
System.out.format(" CONCURRENT: %b%n",
spliterator.hasCharacteristics(Spliterator.CONCURRENT));
}| Charakteristik | Kurzbeschreibung | list | set | sorted-Set | stream |
|---|---|---|---|---|---|
| NONNULL | Alle Elemente sind ungleich null. | false | false | false | false |
| IMMUTABLE | Die Datenstruktur kann sich während der Traversierung nicht ändern (z. B. durch Hinzufügen, Ersetzen oder Entfernen von Elementen). | false | false | false | false |
| SIZED |
Die Größe der zugrunde liegenden Datenstruktur ist genau bekannt und wird von estimateSize() auch so zurückgegeben. |
true | true | true | true |
| SUBSIZED | dito für die durch trySplit() neu erzeugten Spliteratoren | true | false | false | true |
| ORDERED | Die Elemente haben eine festgelegte Reihenfolge. | true | false | true | true |
| SORTED | Die Elemente sind sortiert. | false | false | true | true |
| DISTINCT | Alle Elemente sind verschieden. | false | true | true | true |
| CONCURRENT |
Die zugrunde liegende Datenstruktur lässt sich ohne externe Synchronisation durch andere Threads sicher verändern. |
false | false | false | false |
Die Beispielklasse FakeFile zur Berechnung aufwendiger Hashwerte
Spliteratoren spielen ihre Stärken vor allem in der parallelen Welt aus. Ich habe ein möglichst realistisches Anwendungsbeispiel ausgearbeitet und stelle es Ihnen, liebe Leserin und lieber Leser, gerne unter [Code] zur Verfügung. Das „Drumherum“ ist zu umfangreich, um es hier abzudrucken, von daher seien Sie auf den an den Schlüsselstellen ausführlich kommentierten, vollständigen Quellcode verwiesen.
Im vom mir präsentierten Szenario geht es darum, die SHA-256-Hashwerte vieler großer Dateien zu berechnen, was bekanntlich eine ziemlich rechenintensive Aufgabe ist [Hoo05]. Wir sprechen hier von einer Größenordnung von 1000 Dateien mit jeweils bis zu 100 MB Größe. Um den Dateiinhalt zu simulieren, ohne die Dateien tatsächlich vorbereitend zu erzeugen oder gar zu speichern, habe ich die Klasse FakeFile entworfen. Sie verwendet einen eindeutig geseedeten (also vorinitialisierten) Pseudozufallszahlengenerator, der beim Auslesen „on the fly“ Zufallsdaten zu erzeugt, welche sich wiederum mit jedem Durchlauf reproduzieren lassen. Mit anderen Worten, ausgehend von einem ID-String, der quasi als Dateiname fungiert, lässt sich immer wieder die gleiche Bytesequenz erzeugen, selbst wenn diese 100 Millionen Elemente umfasst. Warum und wie das funktioniert, habe ich vor drei Jahren in meinem JavaSPEKTRUM-Artikel [Hei19/2] beschrieben.
Im Beispielprogramm werden 1000 FakeFiles zufälliger Größe zwischen 0 und 100 MB erzeugt und sortiert in einer internen TreeSet gespeichert. Soll die Aufgabe parallel ausgeführt werden, dann muss diese Menge irgendwo zerschnitten werden, und zwar so, dass die Summe der Dateigrößen (und nicht etwa deren Anzahl) in beiden Teilen möglichst gleich ist. Nur so ist sichergestellt, dass die Hashwert-Berechnungen für beide Teile in etwa gleich lange brauchen. Würde die Dateimenge stattdessen einfach in der Mitte halbiert, so hätte die eine Hälfte 500 kleine Dateien, während die andere Hälfte die 500 größeren Dateien besäße. Ebenso asymmetrisch wären dann auch die Rechenzeiten der beiden Threads verteilt. Die Problemstellung schreit also geradezu nach einem Einsatz von Spliteratoren.
Eigene Spliteratoren schreiben
Die von mir realisierte Dateiablage namens StorageSplitarator (siehe Listing 3) inklusive größengleicher Teilungsfunktion implementiert einen Spliterator<FakeFile>. Für einen eigenen Spliterator gilt es, (mindestens) vier Methoden zu überschreiben:
boolean tryAdvance(Consumer)
Hier wird die Funktionalität für einen einzelnen Iterationsschritt implementiert. Im vorliegenden Beispiel ist es ausreichend, diesen Aufruf an den Spliterator der internen fileSet weiterzuleiten. Mit dem normalen Iterator der fileSet hätte es sehr ähnlich und ebenso einfach funktioniert.
XXXSpliterator trySplit()
Diese Methode enthält den Kern des Spliterators, nämlich die genaue Vorgehensweise, wie sich der Spliterator selbst in zwei Teile zerlegt. In der Regel wird der „vordere“ Teil (bezogen auf die iterierbaren Elemente) in Form eines neuen Spliterators zurückgegeben, während der „aktuelle“ Spliterator (also this) neu den „hinteren“ zu traversierenden Teil enthält.
Im vorliegenden Beispiel dient jeweils eine Datei als „Grenze“. Basierend auf diesem borderFile werden zwei Teilmengen head-FileSet und tailFileSet gebildet und ihre jeweiligen Gesamtgrößen bestimmt. Die Differenz dieser beiden Größen wird zunehmend kleiner werden, bis sie schließlich ein Minimum erreicht. Diese Konstellation stellt dann die optimale Zweiteilung der sortierten Dateimenge dar.
Der Algorithmus ist im Original ausführlich kommentiert. Seine Laufzeit ist quadratisch und damit nicht ideal. Er ließe sich auch mit linearer Laufzeit implementieren, was allerdings auf Kosten der Lesbarkeit gehen würde und damit für den vorliegenden Artikel nicht optimal wäre. Bei 1000 Dateien fällt die Laufzeit noch nicht merklich ins Gewicht, bei 10 000 dann allerdings schon.
long estimatedSize()
Diese Methode gibt – sofern möglich – die exakte Anzahl iterierbarer Elemente zurück, sonst eine Schätzung. Diese Zahl kann für den Aufrufer wichtig sein, um zu entscheiden, ob noch mal ein Split vorgenommen werden soll oder nicht. Im vorliegenden Beispiel entspricht fileSet.size() der exakten Größe und kann somit in einem Einzeiler zurückgegeben werden.
int characteristics()
Die im eigenen Spliterator beinhalteten Charakteristiken werden hier oder-verknüpft (oder einfach addiert) retourniert. In diesem Fall handelt es sich um SIZED, SUBSIZED, ORDERED, SORTED und DISTINCT.
Comparator<…> getComparator()
Ein Überschreiben dieser Methode ist zwar nicht immer zwingend, da für sie bereits eine Default-Implementierung existiert, diese aber lediglich eine IllegalStateException wirft. Eigene Spliteratoren, die über die SORTED-Charakteristik verfügen, müssen daher entweder den verwendeten Comparator zurückgegeben oder null, wenn die natürliche Ordnung der Elemente verwendet wird (so wie es hier der Fall ist).
publicclass StorageSpliterator implements Spliterator<FakeFile> {
private SortedSet<FakeFile> fileSet;
private Spliterator<FakeFile> fileSpliterator;
public StorageSpliterator(SortedSet<FakeFile> fileSet) {
this.fileSet = fileSet;
fileSpliterator = fileSet.spliterator();
}
@Override
public boolean tryAdvance(Consumer<? super FakeFile> action) {
return fileSpliterator.tryAdvance(action);
}
@Override
public StorageSpliterator trySplit() {
if (fileSet.size() <= 1) {
return null;
}
long minTotalFileSizeDifference = Long.MAX_VALUE;
SortedSet<FakeFile> minDifferenceHeadFileSet =
Collections.emptySortedSet();
SortedSet<FakeFile> minDifferenceTailFileSet =
Collections.emptySortedSet();
for (FakeFile borderFile : fileSet) {
SortedSet<FakeFile> headFileSet = fileSet.headSet(borderFile);
SortedSet<FakeFile> tailFileSet = fileSet.tailSet(borderFile);
long totalHeadFileSetFileSize =
calculateTotalFileSize(headFileSet);
long totalTailFileSetFileSize =
calculateTotalFileSize(tailFileSet);
long totalFileSizeDifference =
Math.abs(totalTailFileSetFileSize-totalHeadFileSetFileSize);
if (totalFileSizeDifference < minTotalFileSizeDifference) {
minTotalFileSizeDifference = totalFileSizeDifference;
minDifferenceHeadFileSet = headFileSet;
minDifferenceTailFileSet = tailFileSet;
} else {
break;
}
}
fileSet = minDifferenceTailFileSet;
fileSpliterator = fileSet.spliterator();
StorageSpliterator newSpliterator =
new StorageSpliterator(minDifferenceHeadFileSet);
return newSpliterator;
}
@Override
public long estimateSize() {
return fileSet.size();
}
@Override
public int characteristics() {
return SIZED | SUBSIZED | ORDERED | SORTED | DISTINCT;
}
@Override
public Comparator<? super FakeFile> getComparator() {
return null;
}
public int fileCount() {
return fileSet.size();
}
public long totalFileSize() {
return calculateTotalFileSize(fileSet);
}
private long calculateTotalFileSize(SortedSet<FakeFile> fileSet) {
return fileSet.stream().mapToLong(FakeFile::getSize).sum();
}
}Eigenen Spliterator anwenden
Listing 4 zeigt die rein serielle Anwendung des oben beschriebenen StorageSpliterators. Durch die Boolesche Konstante PRINT_FILES_AND_HASH_STRINGS lässt sich im Originalcode einstellen, ob die jeweiligen Dateien mit ihren Hashwerten auf der Konsole ausgegeben werden sollen oder nicht. Anstelle der expliziten do-while-Schleife mit tryAdvance(…) würde auch ein einzelner Aufruf von storageSpliterator. forEachRemaining(…) funktionieren. Jeder Spliterator stellt forEachRemaining(Consumer) zur Verfügung und ruft in seiner Default-Implementierung einfach tryAdvance(Consumer) in einer Schleife auf.
Auf meinem Rechner (MacBook Pro mit 2,4 GHz 8-Core Intel Core i9) dauert das beschriebene Szenario im besten einthreadigen Durchlauf 198,1 Sekunden. Eine rudimentäre Zeitmessung mit mehrfachen Durchläufen ist im Originalcode enthalten.
StorageSpliterator storageSpliterator
= new StorageSpliterator(fakeFileSet);
boolean success;
do {
success = storageSpliterator.tryAdvance(ff ->
ff.generateSha256HashString(PRINT_FILES_AND_HASH_STRINGS));
} while (success);In Listing 5 ist zu sehen, wie der StorageSpliterator durch insgesamt drei trySplit()-Aufrufe schlussendlich zu vier nahezu gleich großen Dateiablagen gelangt. Die vier mittels ExecutorService gleichzeitig gestarteten Worker-Threads arbeiten fast alle gleich lang, wie an der Echtzeit-CPU-Anzeige des Betriebssystems direkt zu erkennen ist. Die resultierende beste Gesamtlaufzeit von 54,4 Sekunden entspricht einem 3,64-tel der ursprünglichen rein seriellen Laufzeit und ist damit relativ nah am theoretischen Viertel. Abbildung 1, welche wir hier dankenswerterweise von [Het-Tra16] abdrucken dürfen, zeigt noch mal das Grundprinzip von try-Split. Die Abbildung unterscheidet sich vom hier präsentierten Anwendungsfall insofern, als dass die „Grenzen“ in den Dateiablagen nicht in der Mitte liegen, sondern jeweils weiter rechts, um die Dateigrößen-Balance statt der Dateianzahl-Balance zu wahren. Das Buch [HetTra16] ist neben der Java API übrigens die einzige mir bekannte populäre Quelle, die sich mit dem Thema Spliteratoren ausführlich und dazu noch sehr anschaulich auseinandersetzt.
StorageSpliterator spliterator4 =
new StorageSpliterator(fakeFileSet);
StorageSpliterator spliterator2 = spliterator4.trySplit();
StorageSpliterator spliterator1 =
spliterator2 != null ? spliterator2.trySplit() : null;
StorageSpliterator spliterator3 = spliterator4.trySplit();
ExecutorService service = Executors.newFixedThreadPool(4);
if (spliterator1 != null) {
service.execute(() -> spliterator1.forEachRemaining(ff ->
ff.generateSha256HashString(PRINT_FILES_AND_HASH_STRINGS)));
}
if (spliterator2 != null) {
service.execute(() -> spliterator2.forEachRemaining(ff ->
ff.generateSha256HashString(PRINT_FILES_AND_HASH_STRINGS)));
}
if (spliterator3 != null) {
service.execute(() -> spliterator3.forEachRemaining(ff ->
ff.generateSha256HashString(PRINT_FILES_AND_HASH_STRINGS)));
}
service.execute(() -> spliterator4.forEachRemaining(ff ->
ff.generateSha256HashString(PRINT_FILES_AND_HASH_STRINGS)));
/* [...] Shutdown procedure omitted. */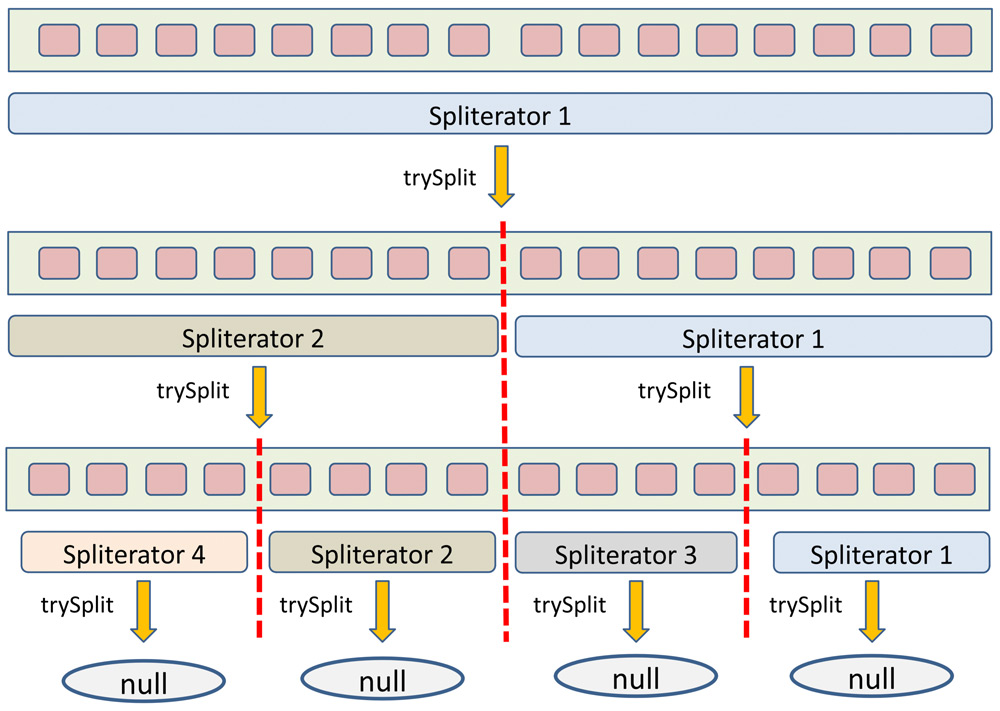
Abb. 1: Funktionsweise eines Spliterators [HetTra16]
Listing 6 zeigt eindrücklich, wie einfach sich aus einem (eigenen) Spliterator ein Stream erzeugen lässt. Hierzu bedarf es lediglich der Methode stream(Spliterator, boolean) aus der Klasse Stream-Support [JAPIStreamSupport]. Der boolean-Parameter gibt an, ob es sich um einen parallelen (true) oder sequenziellen (false) Stream handeln soll.
Parallele Streams werden im Common Fork-Join-Pool der Java Virtual Machine ausgeführt. Ihre Verwendung ist mit einigen Fallstricken versehen und erfüllt nicht immer die Erwartungen der Programmierer hinsichtlich Leistungssteigerung. Dies gilt vor allem dann, wenn die Datenquelle nicht aus einer Collection oder einem Array, sondern aus Stream.iterate(…) stammt oder mit limit beschränkt wird [Blo48]. Im vorliegenden Anwendungsbeispiel funktioniert die Parallelisierung hingegen völlig unproblematisch. Die beste Laufzeit betrug 26,6 Sekunden und war damit um den Faktor 2,05 schneller als die vierthreadige beziehungsweise um den Faktor 7,45 schneller als die rein serielle Variante. Vor dem Hintergrund, dass die Parallelisierung des Spliterators mit einem Zweizeiler erledigt ist, ist das doch ein sehr beachtliches Ergebnis.
StorageSpliterator spliterator = new StorageSpliterator(fakeFileSet);
StreamSupport.stream(spliterator, true).forEach(ff ->
ff.generateSha256HashString(PRINT_FILES_AND_HASH_STRINGS));Fazit
Es ist hilfreich zu verstehen, dass hinter den Kulissen automatischer Parallelisierung, wie es zum Beispiel bei parallelen Streams der Fall ist, Spliteratoren eine große Rolle spielen. Es ist ebenfalls nützlich zu wissen, dass Spliteratoren im rein seriellen Kontext eine kleine Stufe komfortabler anzuwenden sind als klassische Iteratoren.
Über diese Anwendungsfälle hinaus überzeugen mich Spliteratoren aber wenig. Zum einen mag das an ihrer – nach meiner Wahrnehmung – unbedachten und nicht ganz verlässlichen Implementierung vor allem ihrer Charakteristiken liegen. Zum anderen sehe ich in meinem präsentierten Anwendungsszenario rückblickend betrachtet effizientere Vorgehensweisen.
So führt bereits ein Mischen der Elemente der fakeFileSet mit anschließender, ganz normaler 50/50-Aufteilung (bzgl. der Anzahl Dateien) statistisch gesehen relativ sicher zu einer relativ gleichmäßigen Dateigrößenverteilung. Diese „zufällige“ Anordnung lässt sich bereits einfach dadurch erreichen, dass statt einer Tree-Set eine HashSet verwendet wird.
Eine weitere Lösungsmöglichkeit besteht in der Verwendung des Fork-Join-Frameworks, welches ich in [Hei19/5] auch einmal sehr ausführlich vorgestellt habe. Dies kann entweder explizit mithilfe eigener ForkJoinTasks oder bevorzugt implizit mithilfe paralleler Streams geschehen, wobei Letztere im Hintergrund ja selbst einen (Common) Fork-Join-Pool verwenden. Das Fork-Join-Framework ist gerade dazu da, asymmetrisch verteilte Aufgaben unter bestmöglicher Ausnutzung der Ressourcen zu erledigen. Von daher hätte der kurze Zweizeiler
fakeFileSet.parallelStream().forEach( FF -> FF.GENERATESHA256HASHSTRING(PRINT_FILES_AND_HASH_STRINGS));
genügt, um die Berechnungen ganz ohne eigene Spliteratoren ebenfalls in nahezu Bestzeit vorzunehmen.
Sofern Sie also nicht vorhaben, eigene Datenstrukturen von Grund auf neu zu implementieren, können Sie Spliteratoren in meinen Augen getrost ignorieren. Und wenn in Ihrer IDE die Methode spliterator() wieder mal als Code-Vervollständigungsvorschlag aufpoppt, dann wissen Sie ja jetzt bestens über sie Bescheid.
Weitere Informationen
[Blo36] J. Bloch, Effective Java, Item 36: Use EnumSet instead of bit fields, 3rd Edition, Addison-Wesley, 2018
[Blo48]
J. Bloch, Effective Java, Item 48: Use caution when making streams parallel, 3rd Edition, Addison-Wesley, 2018
[Code] Quellcode zum Herunterladen, https://link.simplexacode.ch/brc8
[Hei19/2] C. Heitzmann, Theorie und Praxis von Zufallszahlengeneratoren, in: JavaSPEKTRUM, 2/2019
[Hei19/5] C. Heitzmann, Das Fork-Join-Framework, IN: JAVASPEKTRUM, 5/2019
[HetTra16] J. Hettel, M. T. Tran, Nebenläufige Programmierung mit Java, dpunkt.verlag, 2016
[Hoo05] D. Hook, Beginning Cryptography with Java, Wiley, 2005
[JAPIArrays] Java Platform, Standard Edition & Java Development Kit Version 17 API Specification, Class Arrays, https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/Arrays.html
[JAPIBaseStream] Java Platform, Standard Edition & Java Development Kit Version 17 API Specification, Interface BaseStream<T,S extends BaseStream<T,S>>, https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/stream/BaseStream.html
[JAPIIterable] Java Platform, Standard Edition & Java Development Kit Version 17 API Specification, Interface Iterable<T>, https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/lang/Iterable.html
[JAPISpliterator] Java Platform, Standard Edition & Java Development Kit Version 17 API Specification, Class Spliterator, https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/Spliterator.html
[JAPISpliterators] Java Platform, Standard Edition & Java Development Kit Version 17 API Specification, Class Spliterators, https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/Spliterators.html
[JAPIStreamSupport] Java Platform, Standard Edition & Java Development Kit Version 17 API Specification, Class StreamSupport, https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/stream/StreamSupport.html









