

Ein fachlich getriebener Ansatz, wie ihn das Domain-Driven Design (DDD) bietet, ist mittlerweile zum Goldstandard im agilen Vorgehen geworden. Daraus lässt sich ein gut strukturierter Monolith entwickeln, oder aber ein lose gekoppeltes System von Microservices, der am besten geeignete Architektur für agile Organisationen.
Damit ist auch die Architekturarbeit eine andere geworden. Statt die Architektur top-down minutiös durchzuplanen, treffen Teams die taktischen Detailentscheidungen eigenständig. Wie schafft man es als Entwickler oder Team, sich nicht in der Unzahl von miteinander konkurrierenden Technologien und Einzelaspekten zu verlieren?
Organisationen brauchen ein „Big Picture“. Im Sinne einer strategischen Architektur sollten einige wenige Kernprinzipien teamübergreifend festgelegt und bestimmt werden. Diese stellen in gewisser Weise „Weggabelungen“ dar – wählt man die für die eigene Anwendung und Organisation weniger geeignete Variante, ist dies später nur sehr aufwendig zu korrigieren.
Im Folgenden geht der Artikel auf sieben dieser kritischen Entscheidungspunkte ein (s. Abb. 1). Wir stützen uns dabei auf Recherche, aber auch viele eigene Projekte, die wir mit Studierenden der TH Köln und Projektpartnern im Bereich moderner Architekturen durchführen.
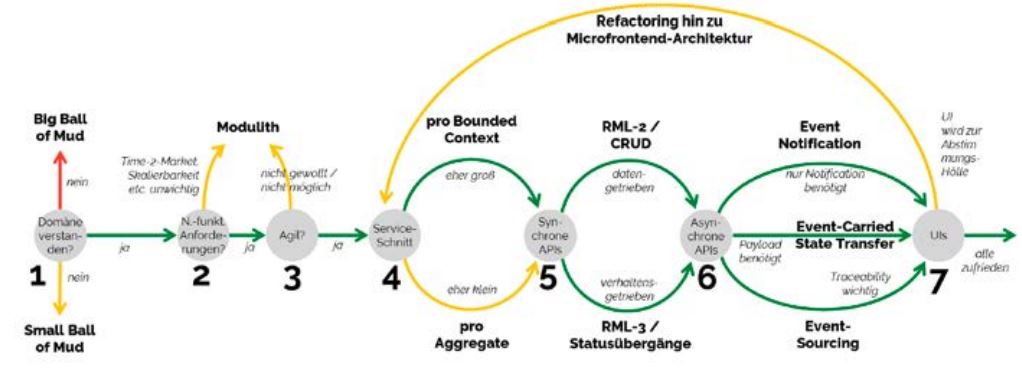
Abb. 1: Sieben Weggabelungen im Software-Design nach DDD
Weggabelung 1: Erkenne deine Domäne
Wenn man nach DDD vorgeht, beginnt man mit dem Verstehen der Domäne. Techniken wie Event Storming oder Domain Story Telling haben sich hier etabliert. Gegenüber dem klassischen Software-Engineering kann man als Faustregel festhalten: weniger UML, mehr Kommunikation.
Eine hohe Modellierungs-Präzision ist weniger wichtig. Hier genügt eine versimpelte UML-Klassendiagramm-Variante. Stattdessen sollte man für das Verständnis und die Pflege einer einheitlichen Begrifflichkeit (die Ubiquitous Language nach [Eva03] – man kann es auch altmodisch „Glossar” nennen) viel Zeit und Geduld einplanen. Ein einheitliches Begriffsverständnis der Fachdomäne ist die Grundvoraussetzung dafür, Fachseite und Nutzerschaft wirklich zu verstehen.
Eine der schwierigsten Herausforderungen ist die Bestimmung von sinnvollen (Sub-) Domänengrenzen. Klare Grenzen sind nötig, um sinnvolle Teamzuständigkeiten festzulegen. Wird dieser Schritt nicht sauber vollzogen (oder gar ganz übersprungen), landet man unweigerlich im „Ball of Mud“. Modulstrukturen bilden dann keine sinnvollen fachlichen Schnitte ab.
Mit einem „Small Ball of Mud“ kann man vielleicht leben, wenn es sich um ein kleines, eher kurzlebiges System wie etwa eine App handelt. Ein „Big Ball of Mud“ ist aber eine Belastung auf Jahre hinaus.
Weggabelung 2: Gibt es besondere nicht-funktionale Anforderungen?
Zum umfassenden Verständnis der Domäne gehört es auch, die nicht-funktionalen Anforderungen an das Projekt zu kennen. Eine schnelle Time-2-Market, Cloudfähigkeit, hohe Verfügbarkeit oder Skalierbarkeit werden durch die zugrunde liegende Architektur vereinfacht oder auch erschwert.
Wenn mindestens eine der genannten Anforderungen erfolgskritisch für das Projekt ist, so ist dies ein guter Grund für eine Microservice-Architektur. Microservices ermöglichen einen schnellen Release-Zyklus, da sie aus kleineren unabhängigen Einheiten bestehen. Wenn es in der Domäne Bereiche gibt, in denen eine hohe Verfügbarkeit oder dynamische Skalierbarkeit aufgrund stark schwankender Lastanforderungen nötig ist (etwa im Saisongeschäft bei einer E-Commerce-Plattform), spielt eine Microservice-Architektur ihre Vorteile aus.
Die betroffenen Teile der Domäne können als unabhängige Services in vielfachen Instanzen deployed werden. Diese Art der Skalierung ist Cloud-kompatibel und verhältnismäßig einfach umzusetzen. Je inhomogener die Notwendigkeit einer Skalierung in der Domäne verteilt ist, desto stärker kann die verteilte und lose gekoppelte Microservice-Landschaft ihre Flexibilität ausspielen [Sch18].
Eine Microservice-Architektur bindet aber auch viele Ressourcen. Die Anzahl der benötigten Technologien ist größer als beim klassischen Monolithen, der als Ganzes produktiv gesetzt wird. Das Entwicklungsteam hat eine viel umfassendere Verantwortung bei Konzeption und Umsetzung des Hostings. Eine organisatorische Trennung zwischen „Dev” und „Ops” funktioniert nicht mehr (s. auch die Weggabelung 3). Das Team braucht hier Kompetenzen, die durchschnittliche Softwareentwickler nicht immer automatisch mitbringen.
Daher kann es sinnvoll sein, auf einen domänenzentrierten Monolithen (auch „Modulith” genannt) zu setzen, wenn die genannten Anforderungen weniger erfolgskritisch sind. Durch ein System von fachlich (vertikal) geschnittenen und lose gekoppelten Modulen, die aber als Ganzes deployed werden, erspart man sich die sehr aufwendige Umstrukturierung der Hosting-Umgebung und Veränderungen in der Organisation. Trotzdem hält man sich mit der losen Kopplung den Weg zu Microservices offen [Fow15]. Daher sollte man sich kritisch auf „fomo” (fear of missing out) bezüglich des Microservice-Hypes prüfen und nüchtern entscheiden, ob man diese tatsächlich (jetzt schon) braucht.
Weggabelung 3: Können wir wirklich agil sein?
Agilität bedeutet für Entwicklungsteams in allererster Linie die Freiheit zur Selbstorganisation. Design- und Technologiefragen müssen vom Team (im Rahmen der Zielvorgaben und Infrastruktur-Randbedingungen) frei und selbstständig entschieden werden können. Dies bedeutet insbesondere eine weitgehende Freiheit von Absprachen mit anderen Teams und Organisationseinheiten, wenn es um neue Features geht.
Microservices, die nach dem DDD-Ansatz entwickelt werden, erlauben dies in besonderer Weise. Sie sind daher die ideale Architektur für agile Teams. Die lose Kopplung und das (weitestgehend) unabhängige Deployment geben dem Team Autarkie und ermöglichen einen eigenen Rhythmus für Entwicklung und Produktivsetzung.
In Weggabelung 2 wurde entschieden, ob eine solche Autarkie nötig ist. Wenn die Antwort „ja“ lautet, muss sich die gesamte Organisation prüfen, ob sie Agilität als Voraussetzung dafür auch wirklich beherrscht. Es gibt gut dokumentierte Anti-Patterns als Indiz für schlecht umgesetzte Agilität, wie etwa agile Rollen ohne echte Entscheidungskompetenz oder eine Betriebsorganisation, die sich gegen die Einmischung der Entwicklungsseite beim Dev-Ops wehrt.
Auch hier sollten sich Entscheider selbstkritisch fragen, ob die eigene Organisation schon reif für agile Teams und echtes DevOps ist. Wenn nein, dann sind Microservices ein unnötiger Mehraufwand mit Sprengpotenzial für das ganze Projekt. Dann wäre der oben beschriebene „Modulith” die bessere Wahl.
Weggabelung 4: Große oder kleine Services?
Wenn man sich in Weggabelung 2 und 3 für Microservices entschieden hat, stellt sich nun die Frage nach der richtigen Größe der Services. Besser fein- oder grobgranular? Die beiden gebräuchlichsten Ansätze zur Service-Dimensionierung lassen sich jeweils auf Kernkonzepte des DDD zurückführen.
Der „maximal feingranulare” Ansatz ist die Implementierung eines Service pro Aggregate (s. Abb. 2 links, Variante A). Ein Aggregate ist ein Geflecht von Entities (wesentlichen Geschäftsobjekten), die inhärent zusammenhängen. Ein Beispiel wäre etwa „Bestellung” und „Bestellposten”. Im Aggregate geschachtelte Entities (hier: Bestellposten) werden nach den DDD-Regeln ausschließlich über das Aggregate Root (das Hauptobjekt, hier: Bestellung) angesprochen. In der Praxis sind die meisten Aggregates nicht groß. Häufig bestehen sie nur aus dem Root-Entity und vielleicht noch eingeschachtelten Value Objects. Wenn man seine Services nach Ansatz A schneidet, erhält man also in erster Näherung etwa so viele Services wie Entities. Das können ganz schön viele Services werden.
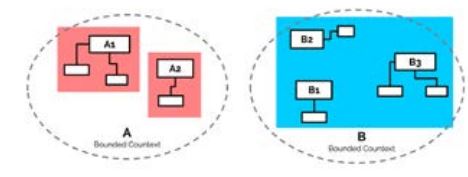
Abb. 2: Zwei Ansäte zur Dimensionierung von Services
Alternativ dazu kann man auch die Grenzen des Bounded Context als Servicegrenze nutzen (S. Abb. 2 rechts, Variante B). Ein Bounded Context ist der Ausschnitt aus einer Domäne, den Entwicklungsteam und zugehörige Fachexperten gemeinsam bearbeiten. In einer idealen Welt ist der Bounded Context eindeutig fachlich definiert und entspricht einer Subdomäne (z. B. Rechnungslegung, Logistik, Warenkorb). Im Normalfall bedeutet die Ausrichtung an Bounded-Context-Grenzen, dass ein Team genau einen Service bearbeitet. Bei der Ausrichtung an Aggregates (Variante A) sind es üblicherweise mehrere.
Meist ist es leichter zu erkennen, dass ein System zu groß ist, als dass es zu klein ist [New16, S. 2]. Das spricht im Allgemeinen eher für den grobgranularen Ansatz: Starte groß und teile den Service wenn nötig.
Weggabelung 5: Synchrone Kommunikation – daten- oder transaktionsgetrieben?
Microservices sind lose gekoppelt. Services kommunizieren am besten gar nicht, oder wenn, dann asynchron. Trotzdem braucht man auch synchrone APIs. Zum einen werden Clients im Allgemeinen synchron angebunden. Zum anderen sind synchrone Schnittstellen schlicht weniger aufwendig zu realisieren als asynchrone, bei denen eine Message Queue verwendet und vielleicht sogar von Grund auf konfiguriert werden muss.
Es gibt mehrere Optionen, synchrone APIs zu implementieren. Eine solche Entscheidung prägt die weitere Entwicklung sehr stark, denn APIs unterliegen einem Lifecycle-Management und sind nicht beliebig änderbar. REST ist hier der verbreitetste Architekturstil. Dabei werden Ressourcen in der Programmierschnittstelle durch eine URI verfügbar gemacht, um mittels HTTP-Verben und -Returncodes die dahinterliegenden Daten abzurufen oder zu modifizieren. Das Richardson Maturity Model [Fow10] hat sich als Klassifizierung für REST-APIs durchgesetzt. Ab Level 2 gehen APIs heute als „wohlgeformte” REST-APIs durch. Der augenfälligste Unterschied zwischen Level 2 und 3 besteht darin, dass in Level 3 die REST-Responses Hypermedia Controls enthalten – Links, die weiterführende Aktionen auf diesem API beschreiben.
Der Unterschied ist größer als auf den ersten Blick offensichtlich. Für ein eher datenorientiertes API, das CRUD (Create-Read-Update-Delete)-Funktionalität bereitstellt, bietet sich Level 2 an. Die nach außen verfügbar gemachten Ressourcen entsprechen den Aggregates nach DDD. Mit Frameworks wie Spring Data REST lassen sich mit wenigen Code-Zeilen komplette REST-APIs erzeugen. Die Hypermedia Controls von Level 3 wären hier ein eher wenig nützlicher Overhead.
Die weitergehende Geschäftslogik (Welche Prozesse kann ich mit meinen Daten ausführen?) wird so allerdings nicht sichtbar. Das führt dazu, dass ein Client diese Geschäftslogik noch einmal parallel zum Backend implementieren muss (vgl. [Dro16]). Ein Level-3-REST-API mit seinen Hypermedia Controls erlaubt im Gegensatz dazu die Abbildung von Transaktionen.
In Abbildung 3 ist ein idealisiertes Beispiel für eine Pizza-Bestellung zu sehen. Während in einer Level-2-Ausprägung immer gesamte Order-Objekte angelegt oder geändert würden, beschreibt das Level-3-API eine transaktionale Zustandsfolge. Die Hypermedia Controls stellen dabei einen Link zu einer verknüpften Ressource oder zu einem Zustandswechsel bereit. Die Links können vom Konsumenten des API genutzt werden, um durch das API zu navigieren.
Abb. 3: Idealisiertes Beispiel für ein transaktional ausgerichtetes REST-Level-3-API, abgewandelt nach https://dzone.com/articles/richardson-maturity-model-and-pizzas
Das API erhält so einen anderen Charakter als in Level 2. Im DDD-Sinne werden hier Services mit ihren Methoden nach außen angeboten. Ein DDD-Service (nicht mit einem Microservice zu verwechseln) bildet eine Transaktion in der Domäne ab, die nicht alleinige Verantwortung eines Entities ist.
Alternativen zu REST bieten sich in Spezialfällen an. Wenn etwa die Anzahl der Konsumenten vielfältig oder deren Zugriffe nicht uniform sind, so spricht dies für eine Nutzung von GraphQL. Für unterschiedliche Zugriffe werden die Daten dabei nach den Wünschen des Konsumenten zusammengestellt. Stehen hingegen hoher Durchsatz und performante Übertragung im Vordergrund, bietet sich das von Google entwickelte gRPC an.
Weggabelung 6: Asynchrone Kommunikation – wie viel Payload?
Nach den DDD-Prinzipien sollte jeder Bounded Context (realisiert durch einen oder mehrere Services, s. Weggabelung 4) möglichst autark sein. Daher ist die bevorzugte Kommunikation der asynchrone Nachrichtenaustausch per Events. Nur der Konsument entscheidet, welche Daten für ihn relevant sind und wie diese gegebenenfalls verarbeitet werden. In der Frage des „Payloads” (wie genau werden die geänderten Daten mitgeteilt?) lassen sich aber drei wesentliche Ansätze unterscheiden (vgl. [Fow17]), die das Gesamtsystem nachhaltig prägen. Man denke daran, dass auch Events APIs darstellen, die nicht einfach geändert werden können.
Event-Carried State Transfer bedeutet, dass bei jeder Statusänderung einer Entität das gesamte geänderte Datenobjekt innerhalb des Events verschickt wird. Der Konsument hat durch dieses Verfahren direkt alle nötigen Daten zur Verfügung – um den Preis einer hohen Redundanz und Datenbelastung des Gesamtsystems. E-Commerce-Plattformen wie etwa die von Rewe Digital nutzen diesen Ansatz [Gau19], kombinieren ihn aber mit einer Entfernung von „uninteressanten” Zuständen (wie etwa Zwischenzustände des Warenkorbs nach erfolgtem Checkout), um Ressourcen zu sparen.
Das Verfeinerung dieses Verfahren ist das Event-Sourcing. Hierbei baut sich ein Event immer aus der Differenz zwischen altem und neuem Entity-Zustand auf. Es beinhaltet somit die minimalen Daten, mit denen der Konsument einen Zustandsübergang ohne weitere Nachfrage nachstellen kann. Der Daten-Overhead ist hier kleiner, dafür können die Prozesse zum Wiederherstellen eines Zustands komplex sein. Mit diesem Ansatz wird die Message Queue als Eventspeicher manchmal auch als „Single Source of Truth” für den gesamten Systemzustand genutzt, da sich ja alle Service-Zustände durch erneutes Einspielen von Events wiederherstellen lassen.
Will man nur eine minimale Payload in den Events vorhalten, so bietet sich Event Notification an. Hier tragen die Events nur eine ID, eine Aktion (z. B. ein HTTP-Verb) und eine Request-URL für das veränderte Entity. Der Konsument muss dann selbst entscheiden, ob das Event relevant ist, und falls nötig per synchronem REST-Call weitere Details beim Event-Produzenten erfragen. Dieser Ansatz ist dann besonders sinnvoll, wenn im System sehr viele Events verschickt werden (von denen nur wenige jeweils von Interesse sind) oder die wesentliche Information schon aus der Aktion des Events deutlich wird.
Weggabelung 7: Im Backend lose gekoppelt, und im UI monolithisch?
Häufig findet man in der Praxis, dass lose gekoppelte Microservice-Backends mit einem monolithischen Frontend, oft in Form einer Single-Page Application (SPA), kombiniert werden. Dieses Frontend wird zumeist einem einzigen Frontendteam anvertraut. Damit geht die inhaltliche Bindung der Entwickler an einzelne Bounded Contexts und Domänen verloren. Die Folge sind sowohl mehr teamübergreifende Abstimmungen zwischen Frontend- und Microserviceteams als auch eine erhöhte teaminterne Kommunikation im zumeist recht großen Frontendteam. Die Anfälligkeit für Missverständnisse und Zielkonflikte steigt und die Skalierbarkeit des Entwicklungsprozesses leidet.
Die Entscheidung für ein monolithisches Frontend war in der Vergangenheit zumeist technisch begründet, da Entwicklungsmuster für lose Kopplung im Frontendbereich gefehlt haben. Zwar bieten SPA-Frameworks ein Modulkonzept, eine Trennung der Codebasen und ein separates Deployment sind damit aber kaum möglich.
Diese Lücke ist durch eine Anzahl an Entwicklungsmustern, die unter dem Begriff Microfrontends zusammengefasst werden (vgl. [Jac19]), geschlossen. Sie bilden das konzeptionelle Gegenstück zu Microservices und ermöglichen die Aufteilung des Frontends in separat deploybare kleinere Komponenten. Im Idealfall werden dann sowohl Microfrontends als auch zugehörige Microservices eines Bounded Context vom selben Team entwickelt und so die nötige Kommunikation zwischen verschiedenen Teams minimiert.
Zur Entwicklung von Microfrontends stehen hier verschiedene technische Lösungen zur Verfügung. Es gibt sowohl serverseitige Integrationslösungen (wie etwa Server Side Includes), aber es können auch clientseitige Lösungen wie die fast totgesagten iFrames oder aktuellere Lösungen wie der Web-Component-Standard genutzt werden. Alle diese Lösungen haben aber eine hohe Komplexität und sind technisch und konzeptuell noch nicht so ausgereift wie die Komponentenkonzepte im Backend.
Diese Komplexität kann ein Entwicklungsteam überfordern. Daher empfiehlt unser Ansatz (s. Abb. 1), durchaus erst einmal mit einem UI-Monolithen zu beginnen – zumindest, falls die Entwicklerschaft nicht über außergewöhnliche Kompetenzen im Web-Umfeld verfügt. Wenn sich dann der UI-Monolith als zu schmerzhaft herausstellt, kann man zu einem Refactoring übergehen, das aber vermutlich auch noch einmal die Servicestruktur (Weggabelung 4) auf den Prüfstand stellt und gegebenenfalls dort feingranularere Services erfordert.
Literatur und Links
[Dow19]
H. Dowalil, Modulith First! Der angemessene Weg zu Microservices, in: Informatik Aktuell,
https://www.informatik-aktuell.de/entwicklung/methoden/modulith-first-der-angemessene-weg-zu-microservices.html
[Dro16]
O. Drotbohm, olivergierke.de, The Benefits of Hypermedia APIs,
http://olivergierke.de/2016/04/benefits-of-hypermedia/
[Eva03]
E. J. Evans, Domain-Driven Design: Tackling Complexity in the Heart of Software, Addison-Wesley, 2003
[Fow10]
M. Fowler, Richardson Maturity Model,
https://martinfowler.com/articles/richardsonMaturityModel.html
[Fow15]
M. Fowler, Monolith First,
https://martinfowler.com/bliki/MonolithFirst.html
[Fow17]
M. Fowler, What do you mean by “Event-Driven”?,
https://martinfowler.com/articles/201701-event-driven.html
[Gau19]
S. Gauder, A competitive food retail architecture with microservice,
https://speakerdeck.com/rattakresch/microxchg-2019-a-competitive-food-retail-architecture-with-microservice
[Jac19] C. Jackson, Micro Frontends,
https://martinfowler.com/articles/micro-frontends.html
[New16]
S. Newman, Building Microservices, O’Reilly, 2016
[Sch18]
N. Schutta, “Should that be a Microservice?” Part 4: Independent Scalability. Pivotal Blogs, https://content.pivotal.io/blog/should-that-be-a-microservice-part-4-independent-scalability









