

Weithin bekannt und akzeptiert ist, welchen bedeutenden Wert eine solide Datengrundlage für Unternehmensentscheidungen hat. So entscheidet ein schneller Datenzugriff immer häufiger über Erfolg und Misserfolg eines Unternehmens. Eine schnelle Verfügbarkeit von Daten macht die Optimierung und Steuerung des Unternehmens auf der Grundlage von Fakten statt auf Basis von Vermutungen möglich.
Business-Intelligence-Analysen (BI) unterstützen das Erkennen von Trends und die Interpretation von Daten. Im Hinblick auf datengestützte Entscheidungen übernehmen diese Komponenten somit eine entscheidende Rolle. Eine Voraussetzung für den Einsatz von BI ist die ökonomische Verfügbarkeit beziehungsweise Bereitstellung der Daten. Hierin liegt auch das Problem, denn Rohdaten und deren Quellen befinden sich in größeren Mengen und unterschiedlichen Qualitäten an verschiedenen Speicherorten. Zudem ist davon auszugehen, dass es auch innerhalb eines Unternehmens in überschaubaren Zeiträumen ständige Veränderungen und Erweiterungen in der Datenstruktur gibt. Bei diesen Daten handelt es sich nicht ausschließlich um Daten aus ERP- und CRM-Systemen, vielmehr werden beispielsweise Maschinen-, Sensor- und Bewegungsdaten oder aber Such- und Zugriffszahlen in die Unternehmensbetrachtung einbezogen. Zu Analysezwecken werden die so erzeugten Daten in den überwiegenden Fällen repliziert, aufbereitet und an geeigneten Stellen gespeichert.
Durch die Aufbereitung der Daten entsteht eine homogene und strukturierte Datenquelle für alle Mitarbeiter des Unternehmens, ein sogenanntes Data Warehouse (DWH). Die User sollen die Daten im DWH ohne weitere Datenaufbereitung nutzen können [KiR13].
Obwohl es das Konzept des DWH schon seit vielen Jahren gibt und mittlerweile auch neue Technologien wie Big Data existieren, bleibt das DWH eine wichtige Komponente für Unternehmen [Kri13]. Im Laufe der Zeit haben sich allerdings die Anforderungen hin zu einem Modern Data Warehouse (MDW) geändert. Die wesentlichen Faktoren dieser Veränderungen sind Agilität, Kostenreduktion, Daten- und Dokumentationsqualität und Zuverlässigkeit sowie Wartbarkeit.
Um diese Ziele erreichen zu können, wurde die Technologie zur Data-Warehouse-Entwicklung weiter verfeinert. Wir sprechen heute von Low-Codeund No-Code-Plattformen sowie der DWH-Automatisierung.
Vom Custom Coding zu Low-Code- bzw. No-Code-Plattformen
Im klassischen Ansatz wird zur Erstellung eines Data Warehouse traditioneller Code verwendet. Hierbei handelt es sich um Programmierung mittels einer allgemeinen Programmiersprache, beispielsweise SQL, Java, Python oder C++.
Die individuelle Programmierung ermöglicht es zwar, die Entwicklung maximal zu kontrollieren und anzupassen, setzt aber eine gründliche Planung und gute Koordination des entsprechenden Entwicklerteams voraus. Auch sind der Aufwand und die Komplexität dafür nicht zu unterschätzen. Weiterhin muss davon ausgegangen werden, dass es zu Veränderungen in den Ursprungsdaten kommen kann und dadurch ein höherer Wartungsaufwand entsteht. Zudem gehört die notwendige Dokumentation in der Praxis eher zu den ungeliebten Themen.
Um allen zuvor angesprochenen Aspekten einer guten Data-Warehouse-Erstellung nachkommen zu können, ist das klassische Verfahren sehr zeit- und ressourcenaufwendig.
In einem nächsten Evolutionsschritt der Data-Warehouse-Entwicklung wurde das händische Programmieren durch Low-Code-Tools abgelöst (siehe Abbildung 1). Dabei wurden beispielhaft Tools für das Extrahieren, Transformieren und Laden der Daten, kurz ETL, entwickelt.
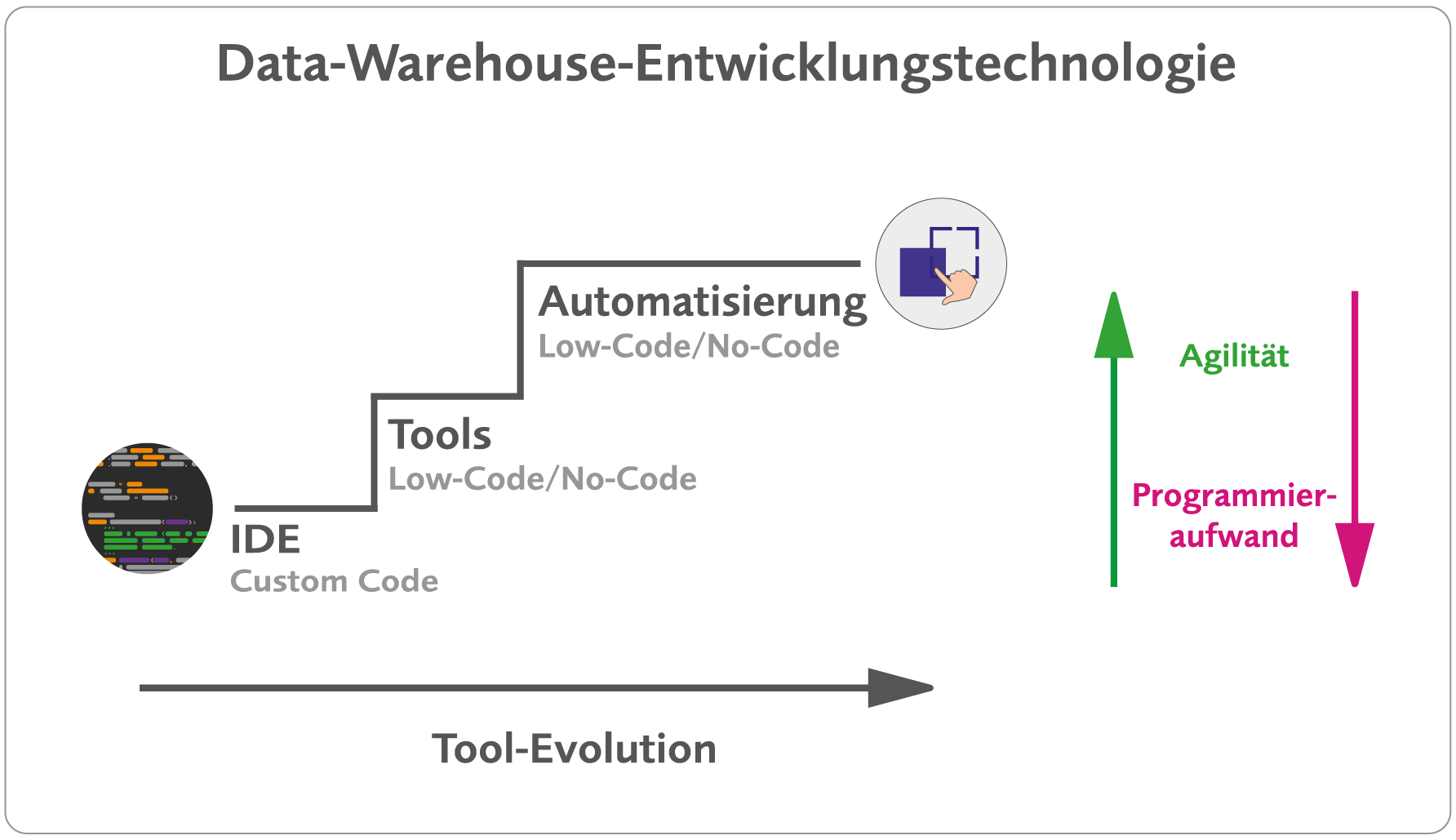
Abb. 1: Data-Warehouse-Entwicklungstechnologie
Hier sind unter anderem die Entwicklungsplattformen Talend open Studio ab 2006 oder SSIS (SQL Server Integration Services, zuvor Data Transformation Services (DTS), ab 1998 als Teil des Microsoft SQL Server 7.0) zu nennen. Bei diesen Plattformen handelt es sich um Anwendungen, die durch grafische Visualisierungen Aufgaben erfüllen, die zuvor ausschließlich von Entwicklern gelöst werden konnten. Tiefgreifende Programmierkenntnisse oder das Schreiben von Code sind zur Bedienung dieser Anwendungen nicht notwendig [Unt22].
Möchte man beispielsweise einen ETL-Prozess in SSIS erstellen, könnte dieser folgendermaßen aussehen:
Als Erstes legt man in der Entwicklungsumgebung Visual Studio oder SQL Server Data Tools (SSDT) ein neues Projekt und Paket an und wählt eine Data Flow Task zum Steuern des Datenflusses in der Datenaufbereitung. Per Drag-and-Drop fügt man nun die Datenquelle ein. Dies könnten Quellen wie Textdateien, Excel-Dateien, relationale Datenbanken oder andere Quellen sein. Im nächsten Schritt wird eine Transformationskomponente hinzugefügt und mit der vorherigen verbunden. Sie werden verwendet, um Transformationen wie Aggregationen, Lookups oder Sortierungen durchzuführen. Über die Zielkomponente werden die Daten in eine relationale Datenbank oder ein Data Warehouse geschrieben. Ergänzen lässt sich der Prozess um Fehlerbehandlungs- und Überwachungskomponenten, beispielsweise die Error-Output-Komponente.
Im Anschluss könnte das Paket in einem Versionskontrollsystem, zum Beispiel Git, versioniert werden. Das System ermöglicht die Verwaltung verschiedener Versionen des Projekts und seiner Komponenten, die Erstellung von Zweigen und die Zusammenarbeit mit anderen Entwicklern. Die Ausführung der Pakete erfolgt geplant und zeitgesteuert durch SQL Server Agent oder die Windows-Aufgabenplanung [Jun11].
Nun folgt die Dokumentation. Die einzelnen Komponenten ermöglichen eine Prozessdokumentation. Auch eine Protokollierung ist im SSIS-Paket möglich. Die Datenflüsse im SSIS-Paket lassen sich mit einem Datenflussdiagramm dokumentieren. Eine Dokumentation innerhalb der Versionierung sollte genutzt werden. Daneben bedarf es einer technischen und einer Benutzerdokumentation. Größtenteils werden diese Dokumentationen händisch erstellt.
Auf ähnliche Weise funktioniert auch Talend open Studio.
Im Hintergrund beider Programme wird der entsprechende Code automatisch generiert. Anpassungen im generierten Code selbst sind nicht möglich, wenn man die Drag-and-Drop-Funktionalität weiter nutzen möchte. Jedoch bieten einige Komponenten die Möglichkeit, individuellen Code zu schreiben.
Zum individuellen Anpassen des Codes bietet zum Beispiel Talend open Studio die tJava-Komponente, in der Änderungen oder Prozeduren in Java programmiert werden können. Sowohl SSIS als auch Talend ermöglichen die Ausführung von Custom-SQL-Code in ihren Integrationsschritten. Beide Tools erlauben zum Beispiel die Ausführung von Stored Procedures in einem Datenbankserver. Voraussetzung ist, dass die Datenquelle das unterstützt.
Des Weiteren gibt es zusätzliche umfangreiche Möglichkeiten, Standardaufgaben zu automatisieren.
Low-Code/No-Code bei der DWH-Automatisierung
In einem der nächsten Evolutionschritte wurde die DWH-Automatisierung eingeführt. Diese notwendige Weiterentwicklung zu einem Modern Data Warehouse ist unter anderem die Basis für agile Weiterentwicklung. Dabei steht die Anforderung im Mittelpunkt, die Daten schneller bereitzustellen (Time-to-Value) und die Komplexität von Datenintegrationsprozessen zu reduzieren.
Bestandteile dieser Automatisierungsplattformen sind unter anderem die Datenintegration, Transformation, Dokumentation und das Monitoring (Abbildung 2). Marktbekannte Vertreter sind zum Beispiel WhereScape, TimeXtender oder QDI. Um die Wirkungsweise von Low-Code und No-Code aufzuzeigen, konzentrieren sich die Ausführungen hier auf TimeXtender.
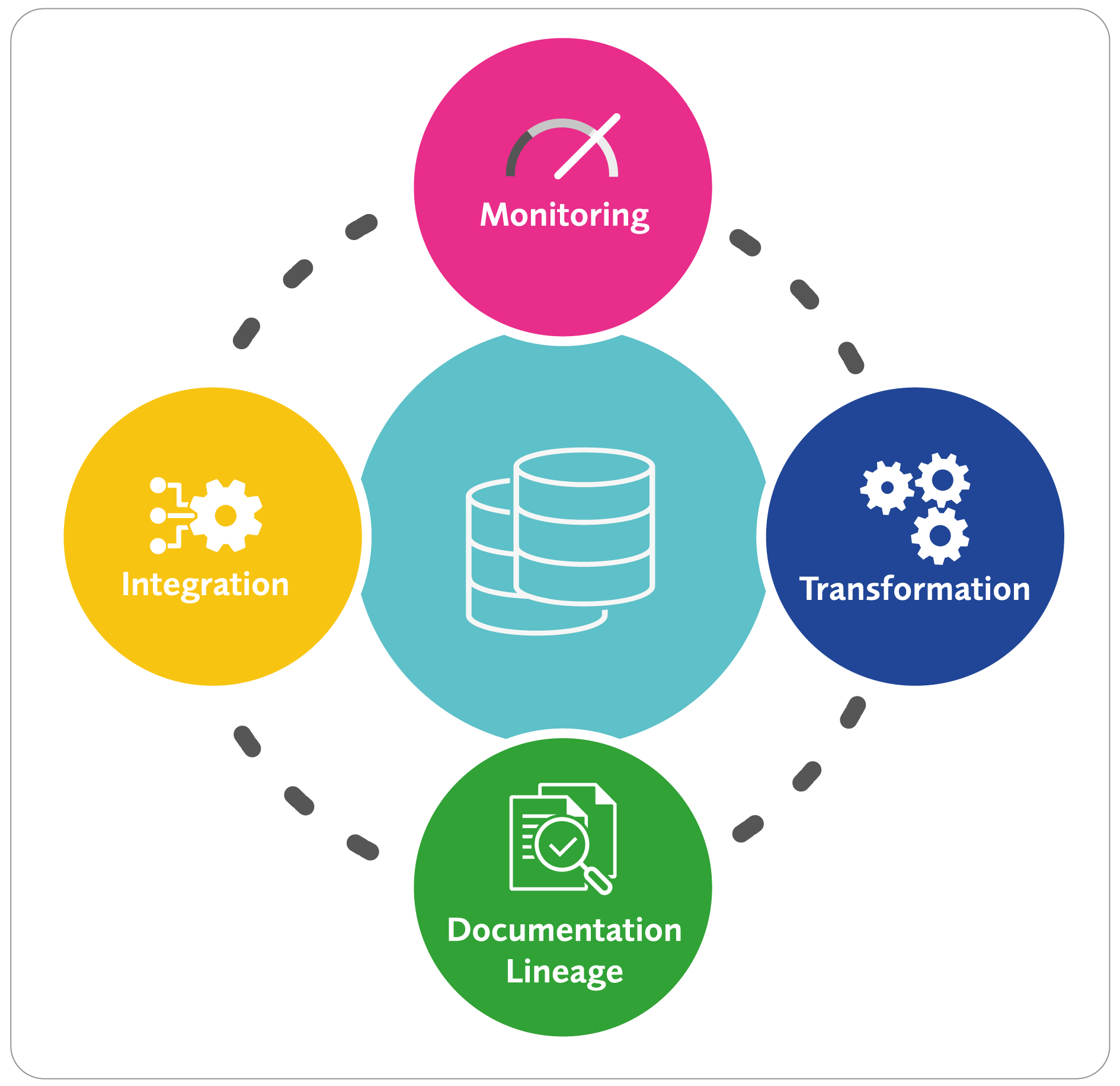
Abb. 2: Data-Warehouse-Automatisierung
TimeXtender entstand als Weiterentwicklung von SSIS zur Automatisierung wiederkehrender Prozesse und bietet zusätzlich Funktionalitäten zur Data-Warehouse-Automatisierung. Das Tool zeichnet sich besonders durch Funktionsbausteine aus, die viele – sonst händisch zu erledigende – Standardaufgaben automatisiert abbilden.
Anhand einiger Beispiele wird nun gezeigt, wie sich der Low-Code- und der No-Code-Ansatz in Abgrenzung zur klassischen Programmierung umsetzen lassen.
Historisierung
Es gibt verschiedene Konzepte zur Historisierung von Daten in einem DWH. Am häufigsten angewandt wird Slowly Changing Dimensions. Dieses Konzept setzt auf die Typisierung 0–3. Diese Typen geben Auskunft über die Art und Weise, wie Änderungen an den Daten verarbeitet und gespeichert werden, und regeln, wie mit einer Veränderung eines bestehenden Zelleninhalts umgegangen wird. Bei Typ 0 werden keine Daten historisiert gespeichert. Die vorhandenen Daten werden automatisch überschrieben, sobald sich Änderungen ergeben haben. Die Zuordnung eines Feldes zu Typ 1 regelt das Überschreiben der im Data Warehouse bereits gespeicherten Inhalte einer Zelle.
Die bestehenden Datensätze werden direkt geändert. Typ 2 beschreibt die Erstellung eines neuen Datensatzes. Typ 3 verwendet eine zusätzliche Spalte, um den vorherigen Zustand der Daten zu speichern [KiR13].
Diese Form der Historisierung lässt sich durchaus in SQL (klassischem Code) mit verschiedenen If- und Where-Bedingungen programmieren. Auch in einem ETL-Tool lassen sich diese Schritte mittels einiger Komponenten umsetzen. Veränderungen in den Ursprungsdaten können Anpassungen erfordern. Damit entsteht ein höherer Wartungsaufwand.
Sieht man sich jedoch die Funktionsweise der Historisierung in einer Data-Warehouse-Automatisierung an, ist der Unterschied augenscheinlich (siehe Abbildung 3): Es findet eine Kompetenzverlagerung statt. Die geforderten Fähigkeiten entwickeln sich weg von der Programmierung hin zu gutem Verständnis der gestellten Anforderungen und der Geschäftsprozesse.
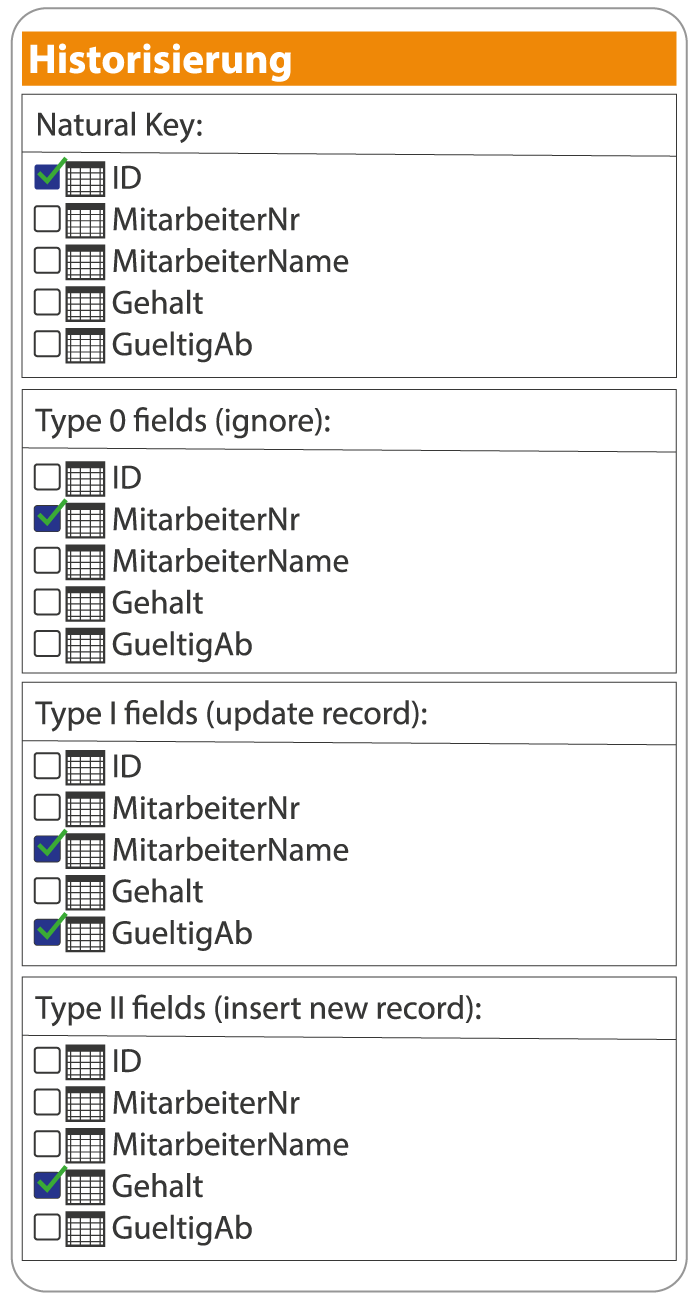
Abb. 3: Beispiel: Dialog zur Historisierung in Anlehnung an TimeXtender
Data Lineage und Protokollierung
Die Data-Warehouse-Automatisierungsplattform TimeXtender protokolliert die Veränderungen an den Daten. So ist es möglich nachzuvollziehen, welche Anpassungen und Transformationen an bestimmten Daten vollzogen wurden. Dieser Prozess wird als Data Lineage bezeichnet.
Ein letzter, aber nicht unwesentlicher Punkt ist, dass einige MDW-Automatisierungs-Tools von Haus aus eine automatisierte Dokumentation erzeugen. Damit reduziert sich eine lästige, aber dennoch wichtige Aufgabe, und der Entwickler kann sich auf andere Aufgaben konzentrieren.
Offenbar steigert der Einsatz von Data-Warehouse-Automatisierungsplattformen die Effizienz, verbessert die Datenqualität und führt zu einer besseren und beschleunigten Entscheidungshilfe. Für die Entwicklungsarbeit im Team bieten Automatisierungs-Tools (wie TimeXtender) Möglichkeiten der Kollaboration. Hierdurch kann das Entwickeln von Datenmodellen und Integrationsprozessen zeitgleich stattfinden.
Ein weiterer Vorteil in der Data-Warehouse-Automatisierung ist es, dass der Blueprint eines Data Warehouse unabhängig von der Speicherumgebung ist. Damit lässt sich eine Entscheidung – ganz gleich, ob sie im On-Premises-Data-Warehouse oder in der Cloud liegt – mit wenigen Klicks ändern. Das ist in einer klassischen Umgebung nur mit erheblichem Aufwand möglich.
Grenzen von Low-Code, No-Code und DWH-Automatisierung
Wie bei jeder Technologie gibt es auch bei Low-Code-Plattformen Grenzen. Sie sind für bestimmte Szenarien konzipiert, wie zum Beispiel die Datenmigration, die Extraktion, die Transformation und um das Laden von Daten zwischen verschiedenen Systemen schnell und einfach durchzuführen.
Allerdings setzen die vorhandene Datenkomplexität oder spezifische Anforderungen teilweise Grenzen, was die DWH-Erstellung betrifft. So erfordert die Erstellung komplexer Integrationspakete oft ein tiefes Verständnis von Datenbanken, ETL-Prozessen und Datenmodellierung. Daher müssen Anwender möglicherweise zusätzliche Programmierkenntnisse erwerben, um benutzerdefinierte Komponenten oder Skripte zur Erweiterung der Funktionalität schreiben zu können.
Zunehmende Komplexität schränkt zudem die Übersichtlichkeit ein. Daher können Erweiterungen ab einem bestimmten Zeitpunkt nur noch schwer und unter erheblichen Verzögerungen umgesetzt werden, was wiederum die Agilität beeinträchtigt. Was die MDW-Automatisierung angeht, kann sie viele Vorteile bieten, beispielsweise eine schnellere Implementierung, eine einfachere Wartung und eine reduzierte Abhängigkeit von IT-Experten. Trotzdem gibt es Grenzen. In der Regel sind Low-Code-Tools einfach zu bedienen. Sind die Daten allerdings unvollständig, ungenau oder inkonsistent, kann dies zu Problemen bei der Automatisierung mit Low-Code-Tools führen. Hierfür stellen alle modernen Plattformen die Möglichkeit zur Verfügung, die automatisierten Prozesse durch Custom Code und Custom Scripting zu erweitern oder zu ergänzen, um beispielsweise externe Prozesse wie PowerShell anzustoßen und zu überwachen.
Schwierig kann es auch werden, wenn vorgelagerte Arbeitsschritte stattfinden, auf die der ETL-Prozess Rücksicht nehmen muss, beispielsweise das Fertigstellen eines Rechnungslaufs aus einem anderen System. Außerdem kann es sein, dass spezielle Anforderungen an die Daten nicht mehr effizient mit den Standardverfahren erfüllt werden können. Handelt es sich zum Beispiel um extrem große Datenmengen, die auch nicht reduziert werden können, kann es notwendig sein, die Performance des Data Warehouse manuell anzupassen. Eine weitere Limitierung stellt sicherlich die Datenbank oder der Speicherort dar, sollte der Anbieter einer Data-Warehouse-Automatisierung die gewünschte Datenbank nicht als Data Warehouse Storage unterstützen. Daher ist im Vorfeld genau zu prüfen, welche Anforderungen an eine Data-Warehouse-Lösung gestellt werden.
Fazit
Die Frage, ob ein Anwender ohne tiefgreifende Programmierkenntnisse selbstständig mittels Low-Code- bzw. No-Code-Plattformen Daten aufbereiten und zur Verfügung stellen kann, kann mit einem eindeutigen „Jein“ beantwortet werden. Grundsätzlich ist vorstellbar, dass für einen Standardfall ein Anwender mittels Low-Code- bzw. No-Code-Plattformen Daten aufbereiten und zur Verfügung stellen kann. Voraussetzung sind grundsätzliche Kenntnisse über Datenmodellierung, Data Warehousing, die erforderlichen Geschäftskenntnisse und die Fähigkeit zur Bedienung der Plattform. In den immer wieder auftretenden Spezialfällen bedarf es jedoch der klassischen Programmierung.
Die ausschließlich klassische Programmierung ist sicherlich der Weg, mit dem sich fast alle Probleme lösen lassen. Zusätzlich hat man den größten Einfluss auf den entstehenden Code. Will man jedoch den Anforderungen an Agilität, Kostenreduktion, Qualität und Zuverlässigkeit sowie Wartbarkeit nachkommen, empfiehlt sich der Einsatz der DWH-Automatisierung mittels Low-Code-Plattformen. Die wiederkehrenden Aufgaben werden automatisiert, Wartungs- sowie Dokumentationsaufgaben erleichtert.
Auch bei der Data-Warehouse-Automatisierung lassen sich nicht alle Prozesse mittels Low-Code bzw. No-Code umsetzen. Jedoch werden bislang benötigte Kapazitäten für Standardaufgaben deutlich verringert. Dadurch entsteht Raum für schnelleres, agiles Reagieren auf Sonderfälle, die einer individuellen Programmierung bedürfen.
Auf diese Weise lässt sich die Time-to-Value als Beitrag zum Unternehmenserfolg deutlich reduzieren.
Literatur
[Jun11] Jungbluth , B.: Microsoft SQL Server Integration Services: Erstellen von Datenintegrations- und Datentransformationslösungen auf Unternehmensebene. Microsoft Press 2011
[KiR13] Kimball, R. / Ross, M.: The Data Warehouse Toolkit. Wiley 2013
[Kri13] Krishnan,K.: Data Warehousing in the Age of Big Data. Morgan Kaufmann 2013
[Unt22] unternehmer.de: Low-Code und No-Code: Definition, Beispiele und Anwendungen. 27.4.2022, https://unternehmer.de/it-technik/292568-low-code-und-no-code-2, abgerufen am 26.6.2023









