

Wir wollen gleich voranschicken: An diesem Artikel waren sowohl künstliche als auch menschliche Intelligenzen beteiligt. Beide verstanden sich erstaunlich gut.
Confluent basiert auf dem De-facto-Standard für Daten-Streaming – Apache Kafka – und ist so konzipiert und optimiert, dass es die Verteilung von Daten in Echtzeit unterstützt, sobald sie erstellt werden. Mit einem umfangreichen Ökosystem von Konnektoren können Unternehmen auf ihre bestehenden Datenbestände zugreifen – egal ob aus modernen Applikationen oder Legacy – und diese für die Nutzung durch KI-Tools aufbereiten. So können letztendlich verwertbare Erkenntnisse gewonnen werden.
Datenstreaming bietet KI-Anwendungen
- die Fähigkeit, Datenströme kontinuierlich zu trainieren,
- effiziente und konstante Datensynchronisation von Quellsystemen zu ML-Plattformen,
- Anwendung von KI-Modellen in Echtzeit
- Zugang zur Verarbeitung großer Datenmengen
KI sinnvoll im Unternehmen vorantreiben
Der Einsatz von KI auf Unternehmensebene beginnt mit der Erschließung der Datenquellen, die für das Training des Modells benötigt werden. Es ist nicht untypisch, dass der Eigentümer der Daten nicht im selben Team sitzt, das mit dem Aufbau und der Pflege der KI-Plattform betraut ist, und in vielen Fällen werden mehrere Datenquellen benötigt, um die durch KI unterstützten Zielsetzungen zu erreichen. Mehrere Datensätze aus unterschiedlichen Bereichen müssen zusammengeführt werden, um einen ausreichenden Kontext zu schaffen, der das Modelltraining und die Ergebnisse wirklich effektiv macht. Mit jeder weiteren KI-Maßnahme werden mehr und mehr Daten benötigt, was zu zusätzlichen Punkt-zu-Punkt-Integrationen führt und letztlich den Prozess verengt und die Komplexität, den Zeitaufwand und die Kosten erhöht.
Um den Wert von KI zu maximieren, müssen Unternehmen die Datenverfügbarkeit im großen Stil angehen. Der Aufbau eines Echtzeit-Data-Mesh demokratisiert die Daten im gesamten Unternehmen und ermöglicht es den KI-Teams, Datensätze zu finden und unkompliziert darauf zuzugreifen, ohne direkt mit dem Eigentümer arbeiten und eine Punkt-zu-Punkt-Integration einrichten zu müssen.
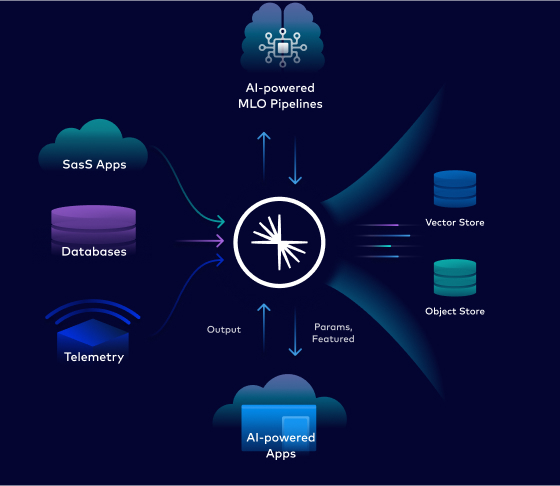
Abb. 1: Aufbau einer Echtzeit-Datenbasis für Künstliche Intelligenz
Sobald ein Modell entwickelt ist, können dieselben Datenströme durch das Modell laufen und die Erkenntnisse in konkrete Maßnahmen umgesetzt werden. Diese grundsätzliche Entkopplung der Datenproduktbesitzer von den KI-Konsumenten schafft fruchtbare Bedingungen, die den ROI von KI beschleunigen.
KI ja, aber bitte mit nutzbaren Ergebnissen
Daten werden zu Informationen, wenn sie in einen Kontext gestellt und für den menschlichen "Gebrauch" umgewandelt werden. Die Möglichkeit, Echtzeitdaten in KI-Systeme einzubringen, öffnet die Tür für neue Zusammenhänge und Verbindungen. Diese Verknüpfungen können helfen, Entscheidungen in kürzester Zeit zu treffen – aber nur, wenn die Daten in Echtzeit verfügbar sind.
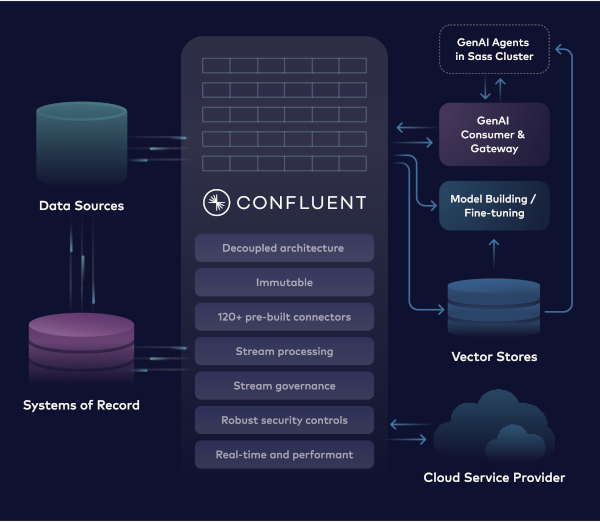
Abb. 2: Schaffung einer Echtzeitbrücke zwischen allen internen Daten und den KITools und -Anwendungen
Trotz der enormen Möglichkeiten, die der Zugang zu Daten in Verbindung mit KI haben kann, muss sichergestellt werden, dass die Daten geregelt genutzt und vor Missbrauch geschützt werden. Auch der Zugang zu den Daten muss sicher und vertrauenswürdig sein. Eine Daten-Streaming-Architektur mit Confluent wird mit rollenbasierter (RBAC) und attributbasierter Zugriffskontrolle (ABAC) auf granularer Ebene eingesetzt, um den Weg für einen reaktionsschnellen, sicheren und skalierbaren Ansatz zu ebnen, mit dem Daten durch KI nutzbar gemacht werden können. Confluent ist stolz darauf, Teil des KI-Ökosystems zu sein und Daten in verwertbare Intelligenz zu verwandeln.
Weitere Informationen zu den Themen Daten-Streaming und KI sind hier zu finden:
Daten-Streaming für künstliche Intelligenz in Echtzeit: https://www.confluent.io/de-de/use-case/artificial-intelligence/
Webinar mit einem Gastsprecher von IDC: The Data Streaming Platform – Key to AI Initiatives, https://us.resources.cio.com/resources/the-data-streaming-platform-key-to-ai-initiatives-4/
Confluent Germany GmbH
Nymphenburger Str. 4
80335 München
info-de@confluent.io
https://confluent.de









